九坤:LLM医疗推理模型Fleming-R1
如何实现具备专家级医疗推理能力且可验证的模型?论文提出了Fleming-R1模型,通过整合数据策略、冷启动推理与强化学习技术,以提升医疗推理的准确性和可验证性。

📖标题:Fleming-R1: Toward Expert-Level Medical Reasoning via Reinforcement Learning
🌐来源:arXiv, 2509.15279
🌟摘要
虽然大型语言模型在医疗应用中显示出了希望,但由于需要准确的答案和透明的推理过程,实现专家级临床推理仍然具有挑战性。为了应对这一挑战,我们引入了 Fleming-R1,这是一种通过三个互补创新为可验证医学推理而设计的模型。首先,我们的面向推理的数据策略 (RODS) 将策划的医学 QA 数据集与知识图谱引导的合成相结合,以提高代表性不足的疾病、药物和多跳推理链的覆盖范围。其次,我们采用思维链 (CoT) 冷启动从教师模型中提取高质量的推理轨迹,建立稳健的推理先验。第三,我们使用组相对策略优化从可验证奖励 (RLVR) 框架中实现了一个两阶段强化学习,该框架通过自适应硬样本挖掘巩固核心推理技能,同时针对持久故障模式。在不同的医学基准测试中,Fleming-R1 提供了显着的参数高效改进:7B 变体超过了更大的基线,而 32B 模型与 GPT-4o 实现了接近可比性,并且始终优于强大的开源替代方案。这些结果表明,结构化数据设计、面向推理的初始化和可验证强化学习可以在简单的精度优化之外推进临床推理。我们公开发布 Fleming-R1 以促进医学 AI 的透明、可重复性和可审计进展,从而在高风险的临床环境中实现更安全的部署。项目在https://github.com/UbiquantAI/Fleming-R1
🛎️文章简介
🔸研究问题:如何实现具备专家级医疗推理能力且可验证的模型?
🔸主要贡献:论文提出了Fleming-R1模型,通过整合数据策略、冷启动推理与强化学习技术,以提升医疗推理的准确性和可验证性。
📝重点思路
🔸引入了推理导向的数据策略,通过多种来源的数据整合,生成丰富的医疗问答数据集。
🔸采用Chain-of-Thought(CoT)冷启动方法,从高容量的教师模型中提炼高级推理轨迹,以增强基础模型的推理能力。
🔸推出复杂推理增强阶段,通过强化学习动态调整训练策略,逐步提升模型在挑战性的医疗推理任务中的表现。
🔎分析总结
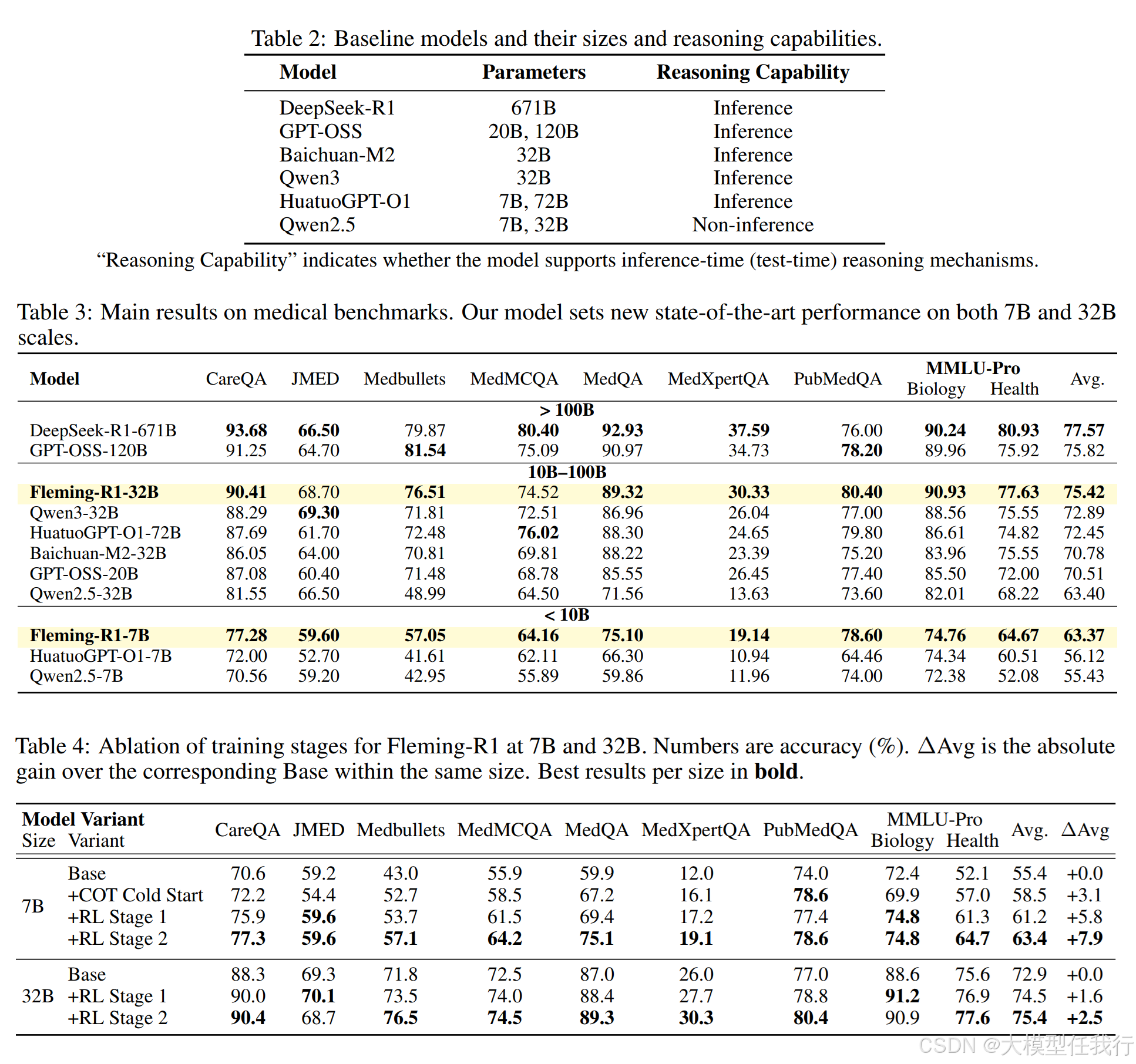
🔸实验表明,Fleming-R1模型在MedXpertQA基准测试中达到了比现有医疗问答模型更高的准确性(7B模型优于72B基线),展示了较强的参数效率。
🔸通过推理导向的数据策略,该模型成功提升了在复杂医疗问题中的表现,表明数据多样性对于模型学习至关重要。
🔸冷启动推理有效建立了多元化推理先验,结合课程学习进一步提高了推理的深度与可靠性,显著减少了持续的错误模式。
💡个人观点
论文通过综合运用推理导向的数据策略、CoT冷启动和强化学习的双阶段训练框架,不仅提升了医疗问题的推理能力,而且强调了推理过程的可验证性。
🧩附录

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献305条内容
已为社区贡献305条内容

所有评论(0)