【AI】AI评测入门(一):先搞懂你的数据集
摘要: 本文探讨了AI评测项目中数据集的关键作用,强调“输入决定输出”的核心逻辑。作者将数据集分为三部分: 知识库(标签体系)——需人工审查确保结构清晰,避免模型幻觉; 自测数据集——用于探索Prompt边界,需覆盖真实场景的多样性; 评测数据集——聚焦发现模型缺陷,需保留基准数据防止“简单错误”。 文章指出,高质量的数据集比Prompt设计更基础,并演示了如何用Langfuse结构化导入数据。最
“不理解输入,如何控制输出?”
——这是我做第一个 AI 评测项目时,最深刻的体会。
我最近用 AI 实现了一个功能:基于标准标签体系,对某垂类产品评价内容自动打标签。
这是我第一次接触 AI 评测、第一次做标签分类、甚至第一次系统分析用户评价。
但正因“零经验”,反而让我更聚焦于最本质的问题:如何让 AI 输出符合预期?
我计划用三篇文章,完整复盘这个“从零上手 AI 评测”的过程(全程使用 Langfuse Cloud):
- AI 评测入门(一):评价打标签 —— Data Set ← 本文
- AI 评测入门(二):评价打标签 —— Prompt 设计
- AI 评测入门(三):评价打标签 —— Evaluation 与迭代
有趣的是,虽然我最初是从 Prompt 入手的,但在测试过程中,我意识到:数据集的质量和结构,比 Prompt 本身更重要。
你不了解你的**“输入”,就不可能稳定控制“输出”**。
所以,第一篇,我们先聊最基础、也最容易被忽视的部分 —— Data Set。
数据集的三大组成部分
在这个项目中,我将数据集拆分为三类:
- 知识库(标签体系) —— 模型打标的“标准答案库”
- 自测数据集(范例集) —— 用于探索 Prompt 设计边界
- 评测数据集(Test Set) —— 用于量化模型表现,发现 Bad Case
一、知识库(标签体系)
为什么标签体系是“数据集”?
因为它是模型推理时的关键输入依据。它可能来自外部采购、历史积累、跨部门协作 —— 不一定由你生成,但必须由你负责。
它决定了模型“能输出什么”、“不能输出什么”,是 Prompt 的“知识锚点”。
我的标签体系共 128 个标签,结构为三级分类(一级 > 二级 > 三级)。规模不大,正好适合人工全量审查。
⚠️ 如果你的标签体系更大(比如上千标签),建议按模块抽样审查,至少明确:
- 有几个大维度?
- 各维度之间是否互斥?
- 是否存在模糊、冗余、交叉的标签?
为什么要“人工过一遍”?
- 避免“脏标签”污染输出
测试中我们发现,模型输出中频繁出现 “其他”、“等等”、“未分类” 等模糊标签。需提前清洗,能极大提升输出质量。
- 建立“标签直觉”,识别模型幻觉
熟悉标签体系后,你能在测试时快速判断:
- “这个标签是我们体系里的吗?”
- “这三个标签能同时出现吗?”
- “它们是否属于同一逻辑维度?”
📌 真实踩坑案例:
模型输出了三个“三级标签”,描述得头头是道,但细看发现——它们分别来自三个互不关联的一级分类。大模型的“流畅包装”极具迷惑性,只有你熟悉标签结构,才能一眼识破。
- 知识库不一定用 RAG —— Prompt 内嵌也很香
很多人一提“知识库”就想到 RAG(检索增强生成),但对结构化、小规模的知识(如 128 个标签),直接写入 Prompt 效果更稳定、调试更简单。
我会在下一篇详细分享如何迭代 Prompt,这里先埋个钩子 👇
✍️ 下期预告:《AI 评测入门(二):Prompt 迭代实战从“能跑通”到“能落地” 》
什么时候做这件事?
写 Prompt 之前!
这是地基。地基不稳,Prompt 写得再漂亮,输出也会跑偏。
二、自测数据集(范例集)
自测数据集不是随便找几个例子,而是有目的地构建 Prompt 的“需求说明书”。
构建方法
从真实用户评价中抽取样本,持续观察,直到“新东西不再出现”。
什么是“新东西”?
- 从“单标签” → 出现“多标签”需求
- 从“单一情绪” → 出现“同一标签 + 不同情绪”组合
- 从“简单句式” → 出现“长文本、复合语义、反讽表达”
这些“新东西”,就是你 Prompt 需要覆盖的边界条件。
关键洞察
不要在 Prompt 里要求“输出多标签”,除非真实数据里存在多标签场景。
否则,你就是在让模型“无中生有”,徒增幻觉风险。
当然,一个人视野有限。建议设定一个“收敛阈值”——比如连续 10 条评价未发现新特征,即可暂停收集,进入 Prompt 设计阶段。
三、评测数据集
评测数据集的核心目的:发现模型失败的场景,而非证明它有多强。
构建原则
- 与自测集无交集 —— 避免“见过的数据”影响评估公正性
- 多维度、有代表性 —— 覆盖不同情绪、长度、语义复杂度、标签组合
- 动态扩展 —— 在测试和生产中持续补充新 Bad Case,不要追求“大而全”
重要提醒:保留“基准数据”
即使模型准确率达到 80%+,也不要移除那些“简单、稳定”的样本。
为什么?
因为它们是“基准数据”——用来确保模型不犯低级错误。当前大模型最大的问题不是“不会难的”,而是不定时地“会错简单的”。
基准数据 = 安全网 = 防止模型“突然变傻”
警惕“无效评测样本”
评测数据集可能是别人准备的。强烈建议在测试前,亲自过一遍每一条数据。
不同角色(产品、技术、运营)对“好结果”的定义不同,可能导致评测维度偏差。
📌 真实踩坑案例:
评测集中有一条样本,内容是“客服处理太慢”——这根本不是产品评价,而是服务反馈。用它测试“产品标签体系”,毫无意义。
四、Langfuse Dataset
整理好评测数据集后,下一步是将其结构化导入 Langfuse,便于后续自动化评测(Evaluation)。
导入方式
- 通过 CSV 文件上传
- 通过 Langfuse API 编程写入(推荐,更灵活)
这个项目先在 Excel 中整理数据,包含以下字段:
- input
- expectedOutput
- ID
- MultiDimension
- OveallSentiment
- RobotType
- BelongFile
✅ 关键建议:所有写入 Langfuse Dataset 的数据,务必使用 key-value 结构。
这样在跑 Evaluation 时,可通过 key 精准绑定参数,实现自动化评分。
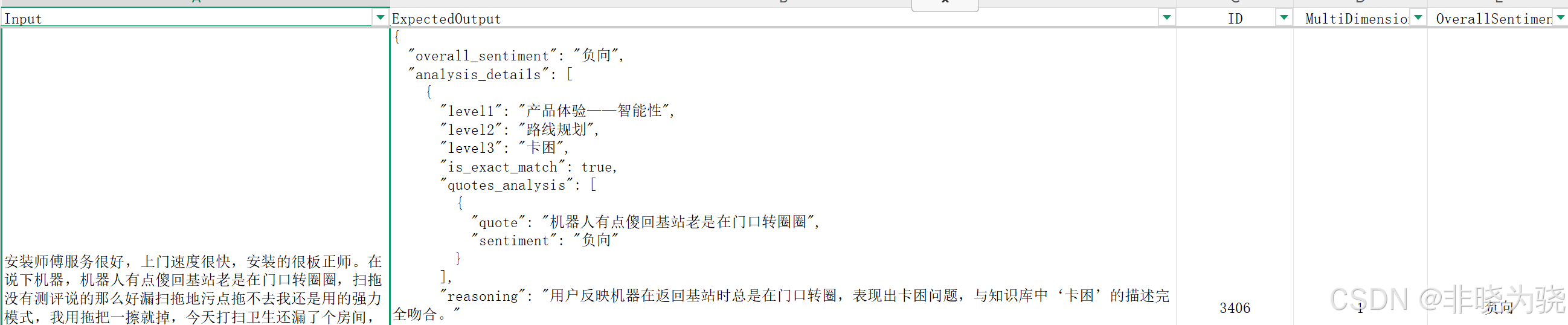
上图是我 excel 表格的数据,下图是我写入 langfuse dataset 的数据,都是以 key -value 的形式。

如何用代码写入 Langfuse?
你可以使用任何 Python 环境(如 Jupyter、Google Colab、Cursor),让 AI 帮你生成代码。
这是我的提示词模板:
我有一个excel表格存储的是某个数据集的数据,表头有:Input 是string
ExpectedOutput 是一个 json
ID 是 string 表示评论 id,放在 metadata
MultiDimension 是 int,1是多维,0是单维,放在 metadata
OverallSentiment 是 string,表示评论的情绪,放在 metadata
RobotType 是 string, 产品型号,放在 metadata
BelongFile 是 string,所属哪个标注文件,放在 metadata
需要你实现langfuse的create dataset item的代码,来遍历excel数据,然后创建新的item
我会在下第三篇分享一个 data set run 的坑,把 data set run 跑起来浪费了我 1天的时间,这里先埋个钩子 👇
✍️ 《AI 评测入门(三):Evaluation 跑起来》
总结:数据集是 AI 评测的“第一性原理”
- 知识库(标签体系):是模型的“知识源”,必须干净、结构清晰、人工审查
- 自测集:是 Prompt 的“需求说明书”,从真实数据中萃取边界条件
- 评测集:是模型的“体检报告”,目标是发现失败,而非证明成功
不了解输入,就别谈控制输出。
🔖 关键词:#AI评测 #大模型应用 #Prompt工程 #标签体系 #Langfuse #AI产品经理 #AI落地实践

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)