ASR/TTS大型模型性能终极解密:微调、幻觉抑制与内核优化
原则技术支撑效果提升高效率 (High Efficiency)TensorRT/FlashAttention 内核优化,INT8/FP16 量化。吞吐量最大化,单请求延迟降至毫秒级。高可靠 (High Reliability)MBR 解码,动态 Logit 惩罚,LoRA 定向微调。输出质量稳定,消除幻觉,模型快速适配领域。高并发 (High Concurrency)Dynamic Batchin
核心关键词: LLM Inference, LoRA/QLoRA, MBR Decoding, TensorRT, FlashAttention, VITS Style Transfer, Dynamic Batching
摘要: 在将 Whisper (Large) 或 VITS/Bert-VITS2 等大型语音模型投入生产时,开发者面临的挑战已不再是模型精度,而是延迟、吞吐量和 VRAM 占用。本文将超越基础 API 调用,直击模型推理的底层内核,详细解析先进解码策略、针对性微调和GPU 调度优化,确保您的语音服务达到工业级的稳定性和效率。
一、 ASR大型模型(Whisper Large)的性能提升与解码优化
1. Large Model 的挑战与内核优化
挑战: Whisper Large 模型参数量巨大(15.5亿),导致其推理延迟高,且在 GPU 显存紧张时,并发能力极差。
优化手段 1.1:内核融合与加速(TensorRT / FlashAttention)
TensorRT 是 NVIDIA 专为深度学习推理设计的 SDK,它通过图优化(Graph Optimization)和内核融合(Kernel Fusion)来提升性能。
优势: 消除 Python 开销,将多个 CUDA 操作合并成一个,显著降低显存带宽压力和延迟。
优化代码 Demo:使用 TensorRT 转换模型
# 伪代码:将 HuggingFace/PyTorch 模型转换为 ONNX/TensorRT 格式
# 步骤 1: 导出 ONNX (通用格式)
python export_whisper_to_onnx.py \
--model_name "openai/whisper-large-v3" \
--output_path "whisper_large_v3.onnx"
# 步骤 2: 使用 TensorRT 优化并构建引擎 (Engine)
# fp16: 启用半精度加速
# best: 启用所有可能的图优化
# workspace: 预留工作空间
trtexec --onnx=whisper_large_v3.onnx \
--saveEngine=whisper_large_v3.trt \
--fp16 \
--best \
--workspace=8000FlashAttention 集成: 对于大型 Transformer 结构,FlashAttention 通过减少 HBM (High Bandwidth Memory) 访问次数来优化 Attention 机制,能进一步提高推理速度和降低 VRAM。在 Faster-Whisper/CTranslate2 的新版本中,通常已集成或可配置启用。
优化手段 1.2:先进解码策略(MBR Decoding)
在生产环境中,Beam Search 并非终点。
痛点: Beam Search 找到的序列虽然在模型对数概率上最高,但其文本质量(可读性和语义准确性)可能不如其他候选项。
Minimum Bayes Risk (MBR) Decoding 介绍: MBR 解码器不直接选择概率最高的序列,而是选择一个能最小化预期损失的序列。它需要从 Beam Search 结果中抽样(比如 20 个候选项),然后根据一个风险函数(通常是 BLEU 或 WER 等评估指标)来选择最终输出。
优势: 牺牲微小的推理时间,换取大幅提升的最终文本质量和鲁棒性,特别是在嘈杂环境中。
优化代码 Demo:MBR 解码的伪代码实现
def mbr_decoding(model_outputs: list[tuple[str, float]], metric_func):
"""
基于 Minimum Bayes Risk 的解码策略
model_outputs: (text, log_probability) 列表
metric_func: 风险函数,如 Word Error Rate (WER)
返回:具有最低预期风险的文本
"""
best_candidate = None
min_expected_risk = float('inf')
# 1. 遍历所有候选项 (Hypotheses)
for i, (candidate_text, _) in enumerate(model_outputs):
expected_risk = 0
# 2. 计算候选者与其他候选项的平均距离 (作为风险)
for j, (reference_text, _) in enumerate(model_outputs):
if i == j:
continue
# 使用 WER 作为距离度量。距离越小,风险越低。
risk = metric_func(candidate_text, reference_text)
# 权重可以根据候选项的概率来设置,这里简化为平均距离
expected_risk += risk
# 3. 更新最佳候选
if expected_risk < min_expected_risk:
min_expected_risk = expected_risk
best_candidate = candidate_text
return best_candidate2. 大型模型的幻觉危机与定向微调
幻觉抑制 2.1:动态 Logit 惩罚与静音检测
除了上一篇提到的 repetition_penalty,更深层次的抑制需要进入模型输出的 Logits 层。
方法: Logit Bias / Token Suppression 在 Whisper 的解码器输出 Logits 时,强制给已知的“垃圾”或“幻觉” token(如 [UNK]、<|notext|>、以及训练数据中的常见复读句的 token)施加巨大的负偏差(Negative Bias)。
优势: 比简单的文本后处理更有效,因为它在生成过程中就切断了错误路径。
配置 Demo (Faster-Whisper/CTranslate2 级别)
# 假设我们知道这些 token ID 容易引发幻觉
BAD_TOKEN_IDS = [220, 50363, 50364] # 示例ID,如复读 token 或时间戳
segments, info = model.transcribe(
audio,
# ... 其他参数
# 核心优化: 强制抑制坏 Token
suppress_tokens=BAD_TOKEN_IDS,
# 可以通过 custom_logit_processor 实现更复杂的动态惩罚
# 例如:在静音长于 1s 时,将所有非 [EOT] (End of Text) Token 的 Logit 减去 100
)定向微调 2.2:LoRA / QLoRA 部署
痛点: 大型模型 (Large) 全量微调需要多块 A100 GPU 和数周时间。 优化目标: 以极低的 VRAM 和计算资源,将模型快速适配到特定领域(如金融、医疗)。
LoRA (Low-Rank Adaptation) 介绍: LoRA 不修改模型的原始权重,而是在 Transformer 的 Attention 矩阵旁注入低秩可训练矩阵。训练时只更新这些小矩阵,原始权重被冻结。
QLoRA (Quantized LoRA) 介绍: QLoRA 更进一步,将冻结的原始权重进行 4-bit 量化,从而将 VRAM 占用降至最低,甚至可以在消费级显卡上微调 Large 模型。
优势:
-
VRAM 效率: 只需训练不到 1% 的参数,微调 Whisper Large 仅需 10GB 左右 VRAM。
-
部署效率: 训练完成后,只需保存和加载极小的 LoRA 权重文件,大大简化部署。
LoRA 微调伪代码配置
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# 假设 model 是量化后的 Whisper Large 模型
# 1. 设置 LoRA 配置
config = LoraConfig(
r=8, # LoRA 秩 (Rank),决定了可训练参数量,通常 8 或 16
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 仅对 Query 和 Value 矩阵进行微调
lora_dropout=0.05,
bias="none",
)
# 2. 准备模型(QLoRA 步骤)
model = prepare_model_for_kbit_training(model)
# 3. 注入 LoRA 模块
model = get_peft_model(model, config)
# 现在 model.print_trainable_parameters() 将显示训练参数量极小
# 4. 训练循环 (使用 HuggingFace Trainer 或自定义 Loop)
# ... training code ...
# 5. 部署时,将 LoRA 权重与原始模型合并 (Merge and Push)二、 TTS大型模型(VITS/Bert-VITS2)的情感控制与流式优化
TTS 的生产级挑战在于音色一致性、情感表达和首字延迟。
1. VITS 架构深度分析与流式瓶颈
VITS 架构核心:Length Regulator(长度调节器)。它将声学特征(音素)拉伸到目标音频长度,实现时长可控。
流式瓶颈: 长度调节器必须知道所有音素和最终目标时长才能精确对齐。如果 TTS 服务需要实时响应,它必须在文本输入时就开始预测时长,导致延迟。
优化手段 2.1:分段 Length Regulator 与 FastSpeech2 融合
方法: 在 Bert-VITS2 等变体中,通过引入 Bert Encoder 提前提取全局语义信息,并结合 FastSpeech2 的时长预测器进行优化。
优势:
-
全局语义: Bert Embeddings 提供更稳定的情感和风格。
-
快速预测: 使用 FastSpeech2 的 Duration Predictor,可以更早且更准确地预测分段音素的时长,从而实现更可靠的流式分块合成。
优化代码 Demo:TTS 推理分块逻辑(伪代码)
def stream_vits_synthesis(text: str, model, style_embedding):
"""
流式合成生成器
"""
phonemes = text_to_phonemes(text) # Step 1: 文本转音素
# Step 2: 关键分块逻辑
# 找到音素流中的自然停顿点(如标点、分句)
phoneme_chunks = segment_phonemes(phonemes)
for chunk in phoneme_chunks:
# Step 3: 时长预测 (Bert-VITS2 核心优化)
# 针对当前块预测 Duration
duration_tensor = model.duration_predictor(chunk)
# Step 4: Length Regulator 使用预测的时长拉伸
aligned_features = model.length_regulator(chunk, duration_tensor)
# Step 5: 波形解码并立即 Yield
audio_chunk = model.decoder(aligned_features, style_embedding)
yield audio_chunk.tobytes() # 返回音频数据块优化手段 2.2:高保真情感和风格控制
痛点: 泛用型 TTS 模型难以准确表达特定的情感(生气、兴奋、疲惫)。
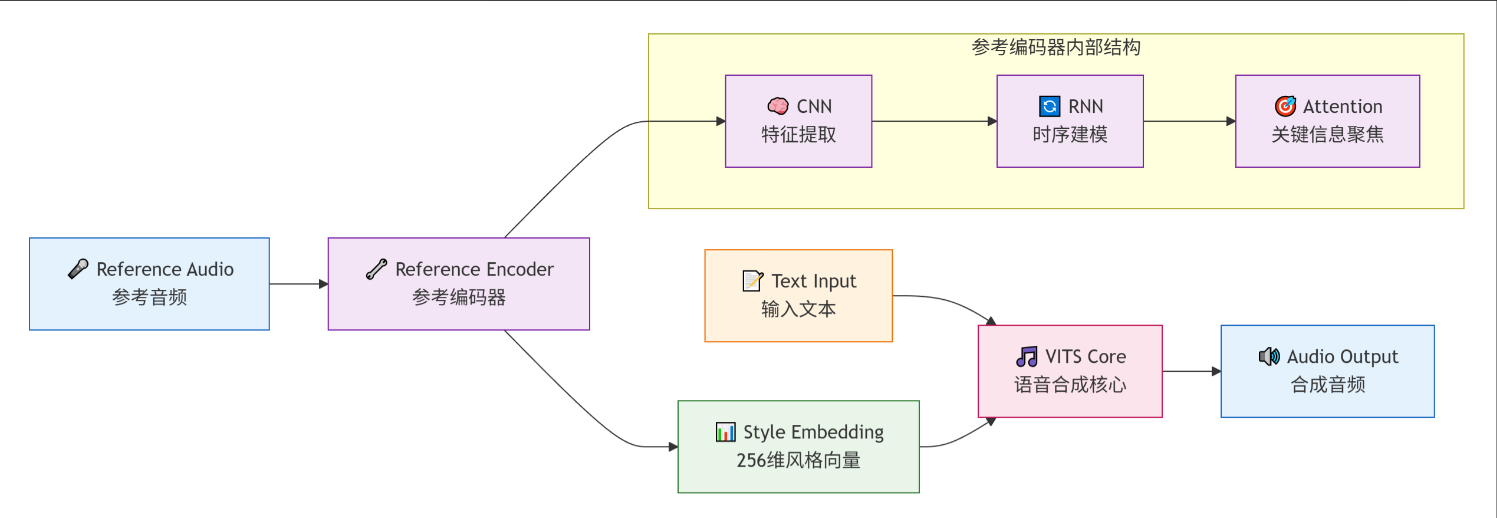
方法: Reference Encoder (参考编码器) 通过提供一段带有目标情感的参考音频(Reference Audio),Reference Encoder 可以从中提取出情感/风格 Embedding。这个 Embedding 会被注入到 VITS 的 Prior Encoder 和 Decoder 中,强制模型以目标情感合成。
优势: 实现真正的 Zero-Shot/Few-Shot 风格迁移,极大地提升了 TTS 的实用性和表现力。
架构组件 (概念图):
三、 高并发下的 GPU 调度与动态批处理
在生产环境中,多个用户同时发起请求,如何让 GPU 满载运行且不产生饥饿等待是核心。
1. 动态批处理 (Dynamic Batching)
痛点: 实时语音流的长度不固定(3秒、5秒、10秒),如果使用固定 Batch Size (e.g., 8),所有短请求都必须等待最长的请求完成,或使用大量 Padding,造成 GPU 浪费。
方法: Batching Manager 线程 + 请求时间窗 设置一个独立的 Manager 线程,它不立即执行推理,而是:
-
等待时间窗: 在 100ms 的时间窗内收集所有到达的 ASR 或 TTS 请求。
-
动态填充: 将收集到的请求填充(Pad)到当前批次中最长请求的长度。
-
提交批次: 将这个动态生成的批次提交给 GPU。
优势: 充分利用 GPU 并行能力,减少 Padding 浪费,大幅提升整体吞吐量。
动态批处理伪代码实现
import time
import threading
from concurrent.futures import Future
class DynamicBatchingManager:
def __init__(self, gpu_worker, max_batch_size=8, wait_time_ms=50):
self.gpu_worker = gpu_worker
self.max_batch_size = max_batch_size
self.wait_time = wait_time_ms / 1000
self.requests = []
self.lock = threading.Lock()
threading.Thread(target=self._batch_loop, daemon=True).start()
def submit(self, data):
"""用户提交请求的入口"""
future = Future()
with self.lock:
self.requests.append((data, future))
return future
def _batch_loop(self):
while True:
# 1. 核心等待和收集逻辑
time.sleep(self.wait_time)
with self.lock:
if not self.requests:
continue
# 2. 截取最大批次或所有请求
current_batch = self.requests[:self.max_batch_size]
self.requests = self.requests[self.max_batch_size:]
# 3. 准备数据:Pad 到当前批次最大长度
audio_data_list = [req[0] for req in current_batch]
futures = [req[1] for req in current_batch]
padded_batch = self._pad_data(audio_data_list)
# 4. 提交给 GPU Worker
results = self.gpu_worker.run_batch_inference(padded_batch)
# 5. 返回结果给对应的 Future
for res, future in zip(results, futures):
future.set_result(res)
def _pad_data(self, data_list):
"""实现数据填充逻辑 (将短音频 Pad 到最长音频的长度)"""
max_len = max(len(d) for d in data_list)
padded_list = [np.pad(d, (0, max_len - len(d))) for d in data_list]
return np.array(padded_list)2. GPU 资源隔离(Multi-Instance GPU - MIG)
对于部署在 A100/H100 等高端显卡上的大型模型,MIG (Multi-Instance GPU) 是终极解决方案。
介绍: MIG 允许将单个物理 GPU 硬件划分为多个完全隔离的、独立运行的 GPU 实例。每个实例拥有自己的 VRAM、流处理器和带宽。
优势:
-
真正的隔离: 一个模型的崩溃不会影响其他模型。
-
高 QoS (Quality of Service): 避免了大型模型之间的资源竞争和抢占,确保每个用户都能获得稳定的延迟。
-
细粒度资源分配: 可以将 Whisper Large 分配给 2个 MIG 实例,将 VITS 分配给 1个 MIG 实例。
总结:AI 语音架构的“三高”原则
|
原则 |
技术支撑 |
效果提升 |
|---|---|---|
|
高效率 (High Efficiency) |
TensorRT/FlashAttention 内核优化,INT8/FP16 量化。 |
吞吐量最大化,单请求延迟降至毫秒级。 |
|
高可靠 (High Reliability) |
MBR 解码,动态 Logit 惩罚,LoRA 定向微调。 |
输出质量稳定,消除幻觉,模型快速适配领域。 |
|
高并发 (High Concurrency) |
Dynamic Batching,MIG 资源隔离,FastAPI 异步 I/O。 |
GPU 利用率最大化,服务扩展性强,用户等待时间最短。 |
从基础模型到工业部署,每一次深度优化都是在向延迟极限和性能极限挑战。希望本文的详细拆解和代码思路能助您构建顶尖的生产级语音 AI 系统。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)