大模型-Layer Normalization 篇
有区别。Post LNa. 位置:layernorm 在残差链接之后b. 缺点:PostLN 在深层的梯度范式逐渐增大,导致使用 Post-LN 的深层 Transformer 容易出现训练不稳定的问题Pre-LNa. 位置:layernorm 在残差链接中b. 优点:相比于 Post-LN,Pre-LN 在深层的梯度范式近似相等,所以使用 Pre-LN 的深层 Transformer 训练更稳定
目录
一、LayerNorm 篇
1.1 LayerNorm 的计算公式写一下?
μ = E ( X ) = 1 H ∑ i = 1 H x i \mu = E(X) = \frac{1}{H} \sum_{i=1}^{H} x_i μ=E(X)=H1i=1∑Hxi
σ = Var ( x ) = 1 H ∑ i = 1 H ( x i − μ ) 2 + ϵ \sigma = \sqrt{\text{Var}(x)} = \sqrt{\frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 + \epsilon} σ=Var(x)=H1i=1∑H(xi−μ)2+ϵ
y = x − E ( x ) Var ( X ) + ϵ ⋅ γ + β y = \frac{x - E(x)}{\sqrt{\text{Var}(X) + \epsilon}} \cdot \gamma + \beta y=Var(X)+ϵx−E(x)⋅γ+β
γ \gamma γ: 可训练的再缩放参数
β \beta β: 可训练的再偏移参数
1.2 LayerNorm 的核心原理
LayerNorm 的核心思想是对单个样本内部的所有特征进行标准化。它的目的是解决内部协变量偏移(Internal Covariate Shift) 问题,即神经网络中间层输入分布的变化会减缓训练过程。通过将每一层的输入稳定在一个相似的分布(通常均值为0,方差为1),它允许使用更高的学习率,并具有一定的正则化效果,从而加速模型训练。
它的工作流程可以分解为三步,对于一个输入向量 x (例如,一个样本在某一层的激活输出):
-
计算均值和方差:在特征维度上计算该样本的均值(μ)和方差(σ²)。
- μ = 1 H ∑ i = 1 H x i \mu = \frac{1}{H} \sum_{i=1}^{H} x_i μ=H1∑i=1Hxi
- σ = 1 H ∑ i = 1 H ( x i − μ ) 2 + ϵ \sigma = \sqrt{\frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 + \epsilon} σ=H1∑i=1H(xi−μ)2+ϵ
- 这里 H 是特征维度的长度(例如,神经元的数量,或 Transformer 中隐藏层的大小)。
-
标准化:用刚才计算出的均值和方差对该样本进行“中心化”和“缩放”。
- x ^ i = x i − μ σ \hat{x}_i = \frac{x_i - \mu}{\sigma} x^i=σxi−μ
- 此时,新的向量 x ^ \hat{x} x^ 的均值为0,方差为1。
-
仿射变换:引入两个可学习的参数 γ(缩放因子)和 β(偏移因子)对标准化后的数据进行变换。
- y i = γ x ^ i + β y_i = \gamma \hat{x}_i + \beta yi=γx^i+β
- 这一步至关重要,它赋予了模型灵活性。如果标准化会损害模型的表达能力,模型可以通过学习将 γ 设置为原来计算的标准差,将 β 设置为原来的均值,来有效地恢复原始的激活分布。换句话说,模型可以自行决定在多大程度上使用标准化操作。
直观理解:你可以把 LayerNorm 想象成在“塑造”单个样本的分布。它不管其他样本是什么样子,只专注于让当前这个样本的特征分布变得稳定。
1.3 LayerNorm 与 BatchNorm 的对比
这是理解 LayerNorm 的关键。它们的计算公式一模一样,唯一的区别在于计算均值和方差所依赖的轴(维度)不同。
| 特性 | Batch Normalization (BN) | Layer Normalization (LN) |
|---|---|---|
| 核心思想 | 对一个Batch内所有样本的同一特征进行标准化。 | 对单个样本的所有特征进行标准化。 |
| 依赖对象 | 依赖当前Batch中其他样本的统计量。 | 仅依赖自身样本的统计量,独立于Batch中其他样本。 |
| 计算维度 | 在 (N, H, W, C) 格式下,在 N, H, W 维度上计算均值和方差(即对C这个通道维度做归一化)。 | 在 (N, H, W, C) 格式下,在 H, W, C 维度上计算均值和方差(即对N这个Batch维度不做归一化)。 |
| 对Batch Size的敏感性 | 非常敏感。效果高度依赖于Batch Size。 | 不敏感。即使Batch Size为1也能稳定工作。 |
| 大Batch:统计估计准确,效果好。 | ||
| 小Batch:统计估计不准,效果差。 | ||
| 训练与推理的区别 | 训练时使用当前Batch的均值和方差;推理时使用整个训练集估算的运行均值/方差。 | 训练和推理的计算方式完全一致,都使用当前样本的统计量,无需运行均值。 |
| 适用场景 | 卷积神经网络(CNN) | 循环神经网络(RNN)、Transformer、生成模型 |
| 图像数据,其中空间维度(H, W)提供了丰富的统计信息。 | 变长序列数据(如文本、语音),小批量或在线学习场景。 | |
| 一个形象的比喻 | 横向比较:老师批改一个班级(Batch)所有学生(样本)的同一道题(特征),然后根据全班这道题的成绩(均值和方差)来调整每个人的分数。 | 纵向比较:老师批改一个学生(样本)的全部试卷(所有特征),然后根据这个学生自己的总体成绩(均值和方差)来调整他各科的分数。 |
1.4 为什么 Transformer 和 RNN 使用 LayerNorm 而不是 BatchNorm?
- 序列长度可变性:RNN 处理的是变长序列,Batch 中每个样本的序列长度可能不同。BN 需要在固定维度上计算统计量,这在不规则序列上非常麻烦。而 LN 独立处理每个样本,完美适配变长序列。
- 对Batch Size不敏感:在训练语言模型等任务时,由于内存限制,Batch Size 往往很小。BN 在小 Batch 下表现糟糕,而 LN 不受影响。
- 性能的一致性:在推理时,RNN/Transformer 经常需要处理单个样本(例如,机器翻译逐句翻译,聊天机器人逐句回复)。BN 在推理时依赖训练阶段估算的运行均值,如果推理数据分布与训练数据有差异,性能会下降。而 LN 无论训练还是推理,其行为完全一致,更加稳定可靠。
- 并行计算的友好性:在 Transformer 的自注意力机制中,LN 被应用于每个子层(注意力层、FFN层)之前/后。它的计算不依赖于Batch内其他样本,非常适合现代大规模并行计算架构。
总之,
| 归一化方法 | 计算维度 | 主要特点 | 适用场景 |
|---|---|---|---|
| BatchNorm | Batch 维度 | 依赖Batch大小,训练推理不一致 | 固定尺寸输入的CNN(如图像分类) |
| LayerNorm | Feature 维度 | 与Batch大小无关,训练推理一致 | 变长序列模型(如RNN, Transformer) |
简单来说,BatchNorm 是“跨样本归一化”,而 LayerNorm 是“跨特征归一化”。正是这个根本性的区别,决定了它们各自的应用领域。LayerNorm 因其稳定性和对序列数据的天然亲和力,成为了现代深度学习模型(尤其是基于 Transformer 的模型)不可或缺的组成部分。
二、RMS Norm 篇(均方根 Norm)
2.1 RMS Norm 的计算公式写一下?
RMS Norm 的计算分为两步:
-
计算均方根值 (Root Mean Square):
RMS ( x ) = 1 n ∑ i = 1 n x i 2 + ϵ \text{RMS}(x) = \sqrt{\frac{1}{n} \sum_{i=1}^{n} x_i^2 + \epsilon} RMS(x)=n1i=1∑nxi2+ϵ
其中, n n n 是特征维度的大小(即向量 x x x 的元素个数), x i x_i xi 是向量的第 i i i个元素, ϵ \epsilon ϵ是一个很小的常数(例如 1 0 − 5 10^{-5} 10−5),用于防止除以零的情况,增加数值稳定性。 -
重新缩放:
y = x RMS ( x ) ⋅ γ y = \frac{x}{\text{RMS}(x)} \cdot \gamma y=RMS(x)x⋅γ
这里, γ \gamma γ是一个可学习的缩放参数(通常是一个与 (x) 维度相同的向量)。
完整公式:
y = x 1 n ∑ i = 1 n x i 2 + ϵ ⋅ γ y = \frac{x}{\sqrt{\frac{1}{n} \sum_{i=1}^{n} x_i^2 + \epsilon}} \cdot \gamma y=n1∑i=1nxi2+ϵx⋅γ
2.2 RMS Norm 相比于 Layer Norm 有什么特点?
1. 核心简化:去中心化 (No Mean Subtraction)
- LayerNorm 的核心操作是“去均值”(减去均值 μ \mu μ)和“除标准差”(除以标准差 σ \sigma σ)。这强制地将激活值的分布转换为均值为0、方差为1的标准正态分布。
- RMSNorm 移除了“去均值”这一步,只进行“重新缩放”。它仅使用均方根值来缩放输入,不再将分布的中心平移至零点。
2. 计算效率更高
- 由于省去了计算均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2(方差计算也需要先求均值)的步骤,RMSNorm 的计算量更小。
- 具体来说,计算均值需要 n n n 次加法,计算方差又需要 n n n 次加法和 n n n 次乘法(计算 ( x i − μ ) 2 (x_i - \mu)^2 (xi−μ)2)。RMSNorm 直接计算平方和,省去了这些操作,因此计算速度更快,尤其是在参数规模巨大的大语言模型中,这点微小的优化能带来可观的性能提升。
3. 理论基础:权重不变性 (Weight Invariance)
- RMSNorm 的作者从理论分析出发,认为 LayerNorm 的成功主要来自于其重新缩放不变性(Scale Invariance) 的特性,而不是其“去中心化”的特性。
- 重新缩放不变性是指:如果对输入向量进行缩放(乘以一个常数),其输出结果不会改变。这个特性有助于稳定网络的训练动态,允许使用更高的学习率。
- 论文通过实验证明,只要保留了这种缩放不变性,即使去掉“去中心化”部分,模型的表现也几乎不受影响。
4. 效果相当甚至更优
- 在多项自然语言处理和机器翻译任务的实验中,RMSNorm 的表现与 LayerNorm 基本相当,有时甚至略有提升。
- 这表明对于许多模型和任务来说,“去中心化”可能并非一个严格必要的操作,简化后的 RMSNorm 已经足够捕获归一化带来的大部分好处。
5. 数值稳定性
- 两者都包含一个小的常数 (\epsilon) 来确保分母不为零,保证数值稳定性。
总结对比表:
| 特性 | LayerNorm (LN) | RMSNorm |
|---|---|---|
| 核心操作 | 去均值 + 除标准差 | 仅除均方根值 |
| 计算公式 | y = x − μ σ ⋅ γ + β y = \frac{x - \mu}{\sigma} \cdot \gamma + \beta y=σx−μ⋅γ+β | y = x RMS ( x ) ⋅ γ y = \frac{x}{\text{RMS}(x)} \cdot \gamma y=RMS(x)x⋅γ |
| 计算复杂度 | 较高(需算μ和σ) | 较低(无需算μ) |
| 可学习参数 | 缩放参数 γ \gamma γ + 偏移参数 β \beta β | 仅缩放参数 γ \gamma γ |
| 理论重点 | 中心化 + 缩放不变性 | 缩放不变性 |
| 效果 | 业界金标准,效果稳定 | 与LN相当,有时更优 |
| 应用 | Transformer, BERT 等 | LLAMA, T5 等 |
额外补充 (面试方向):
-
为什么RMSNorm有效?
- 其有效性挑战了“必须将数据分布中心化到零点”的传统观念。它表明,对于使用激活函数(如ReLU、GELU)的网络,分布的缩放(方差)比分布的中心(均值)对训练稳定性的影响更大。
-
与BatchNorm的关系?
- RMSNorm 是对 LayerNorm 的简化,而 LayerNorm 本身是为了解决 BatchNorm 在序列模型(如RNN/Transformer)上的局限性而提出的。因此,RMSNorm 同样主要应用于NLP领域的模型,而不是CV领域的CNN。
-
偏移参数 β \beta β 的作用?
- 在LN中, β \beta β 的作用是在标准化后重新赋予模型改变分布中心的能力。RMSNorm 直接去掉了它,这反而证明了模型在许多情况下并不需要这个额外的自由度,简化操作同样有效。
三、Deep Norm 篇
3.1 Deep Norm 思路?
Deep Norm (DeepNet) 是一种旨在稳定极深层Transformer模型(如达到1000层以上)训练的方法。其核心思路包含两个部分:
-
Up-Scale 残差连接:在执行 Layer Normalization 之前,对残差连接的路径进行放大(乘以一个常数 α > 1 \alpha > 1 α>1)。
x l + 1 = LayerNorm ( α ⋅ x l + F ( x l ) ) x_{l+1} = \text{LayerNorm}( \alpha \cdot x_l + \mathcal{F}(x_l) ) xl+1=LayerNorm(α⋅xl+F(xl)) -
Down-Scale 参数初始化:在模型初始化阶段,对特定模块(如FFN、Value/Output投影)的参数进行缩小(乘以一个常数 β < 1 \beta < 1 β<1)。
这种“一扩一缩”的设计共同作用,旨在更好地控制信号在前向传播和反向传播过程中的尺度,从而缓解深层网络中的梯度爆炸/消失问题。
3.2 Deep Norm 代码实现?
import torch.nn as nn
import torch.nn.functional as F
class DeepNorm(nn.Module):
def __init__(self, d_model, alpha=1., beta=1.):
super().__init__()
self.alpha = alpha # Up-scale factor, typically >1 (e.g., 2.0 for Encoder, 3.0 for Decoder)
self.beta = beta # Down-scale factor for initialization, typically <1
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x, sublayer):
# sublayer is a function (e.g., attention or ffn)
# Up-scale the residual 'x' and add the down-scaled (via initialization) sublayer output
return self.layer_norm(x * self.alpha + sublayer(x))
# Example Initialization (Conceptual, often integrated into specific module init)
def deepnorm_init(weight, gain=1.0, deepnorm_beta=1.0):
# Down-scale the initial weights by 'deepnorm_beta'
nn.init.xavier_normal_(weight, gain=gain * deepnorm_beta) # gain=0 for some projections
更具体的初始化示例(针对Transformer模块):
def deepnorm_specific_init(module, layer_type, deepnorm_beta):
"""
module: the nn.Module to initialize
layer_type: string indicating type, e.g., 'ffn', 'v_proj', 'out_proj', 'q_proj', 'k_proj'
deepnorm_beta: the β factor (<1) for down-scaling
"""
if isinstance(module, (nn.Linear, nn.Conv1d)):
if layer_type in ['ffn', 'v_proj', 'out_proj']:
# Down-scale initial weights significantly (gain factor multiplied by β)
nn.init.xavier_normal_(module.weight, gain=0 * deepnorm_beta) # gain=0 * β ≈ 0
if module.bias is not None:
nn.init.constant_(module.bias, 0)
elif layer_type in ['q_proj', 'k_proj']:
# Down-scale less aggressively or not at all
nn.init.xavier_normal_(module.weight, gain=1.0 * deepnorm_beta) # gain=1 * β
if module.bias is not None:
nn.init.constant_(module.bias, 0)
# Other layers can be handled similarly
3.3 Deep Norm 有什么优点?
-
卓越的稳定性:Deep Norm 的核心优点是能有效稳定极深模型(>1000层)的训练。它通过up-scale残差和down-scale初始化,将模型的前向传播输出和反向传播的梯度幅度限制在一个常数范围内,有效避免了梯度爆炸或消失问题。
-
缓解模型更新爆炸:传统的Post-LN Transformer在深层网络中容易发生“模型更新爆炸”(即训练初期梯度巨大,导致优化不稳定)。Deep Norm 的机制将模型更新约束在一个可控的范围内,使得训练过程更加平滑和稳定。
-
性能提升:在保持训练稳定的前提下,得益于能够成功构建极深的模型,DeepNet 在机器翻译等任务上展现了比标准Transformer更优的性能。
-
对学习率不敏感:使用 Deep Norm 的模型对学习率超参数的选择鲁棒性更强,不容易因为学习率稍大而训练崩溃。
额外补充 (面试方向):
-
与Post-LN和Pre-LN的关系:
- Post-LN:
x = LayerNorm(x + Sublayer(x))。标准结构,但在深层网络中训练不稳定。 - Pre-LN:
x = x + Sublayer(LayerNorm(x))。更稳定,但有时性能略逊于Post-LN。 - Deep Norm:可以看作是 Post-LN 的增强和稳定版本。它通过引入缩放因子α和β,保留了Post-LN结构潜力的同时,解决了其不稳定的问题。
- Post-LN:
-
为何up-scale残差?
- 为了确保在深层网络中,原始信号(
x)在多次叠加后不至于衰减得太弱。放大残差路径相当于加强了信息高速公路,让底层信号更容易传播到高层。
- 为了确保在深层网络中,原始信号(
-
为何down-scale初始化?
- 为了补偿up-scale残差带来的潜在激活值增大的影响。如果只放大残差而不缩小新加入的激活值(
Sublayer(x)),前向传播的幅度可能会越来越大。通过在初始化时缩小参数,相当于控制了每个新加入信号的“音量”,使其与放大后的残差相匹配,保持总体幅度稳定。
- 为了补偿up-scale残差带来的潜在激活值增大的影响。如果只放大残差而不缩小新加入的激活值(
-
常用参数值:
- 在原始论文中,对于编码器,推荐 α = 2.0 , β = 0.87 \alpha = 2.0, \beta = 0.87 α=2.0,β=0.87;对于解码器,推荐 α = 3.0 , β = 0.81 \alpha = 3.0, \beta = 0.81 α=3.0,β=0.81。这些值是针对其模型深度和架构通过理论推导和实验得出的。
四、Layer normalization-位置篇
4.1 LN 在 LLMs 中的不同位置有什么区别么?如果有,能介绍一下区别么?
有区别。Layer Normalization (LN) 在大型语言模型 (LLMs) 中的主要位置有以下几种,其放置位置对训练稳定性、收敛速度和模型性能有显著影响: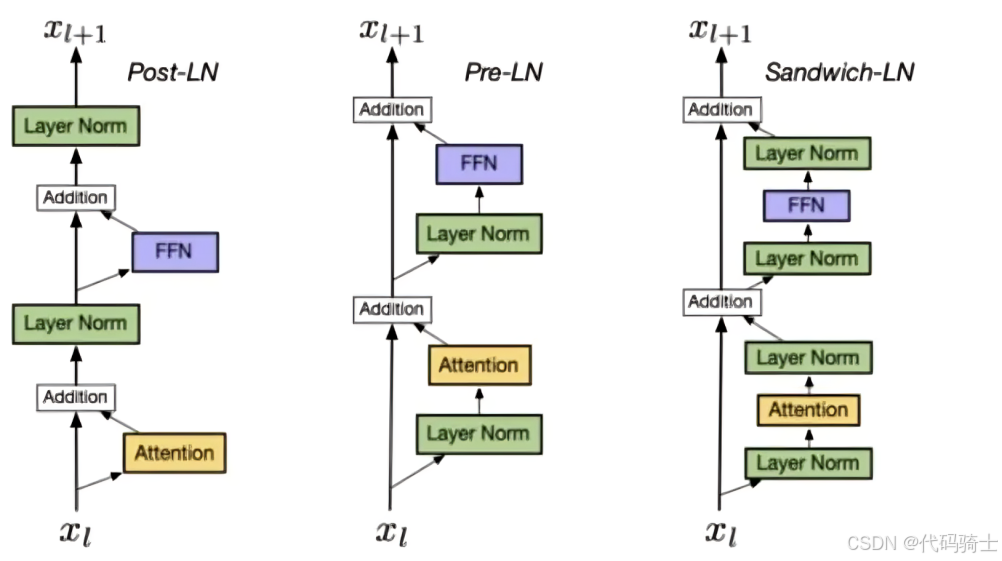
-
Post LN:
a. 位置:layernorm 在残差链接之后
b. 缺点:PostLN 在深层的梯度范式逐渐增大,导致使用 Post-LN 的深层 Transformer 容易出现训练不稳定的问题 -
Pre-LN:
a. 位置:layernorm 在残差链接中
b. 优点:相比于 Post-LN,Pre-LN 在深层的梯度范式近似相等,所以使用 Pre-LN 的深层 Transformer 训练更稳定,可以缓解训练不稳定问题
c. 缺点:相比于 Post-LN,Pre-LN 的模型效果略差 -
Sandwich-LN:
a. 位置:在 Pre-LN 的基础上,额外插入了一个 layernorm
b. 优点:Cogview 用来避免值爆炸的问题
c. 缺点:训练不稳定,可能会导致训练崩溃。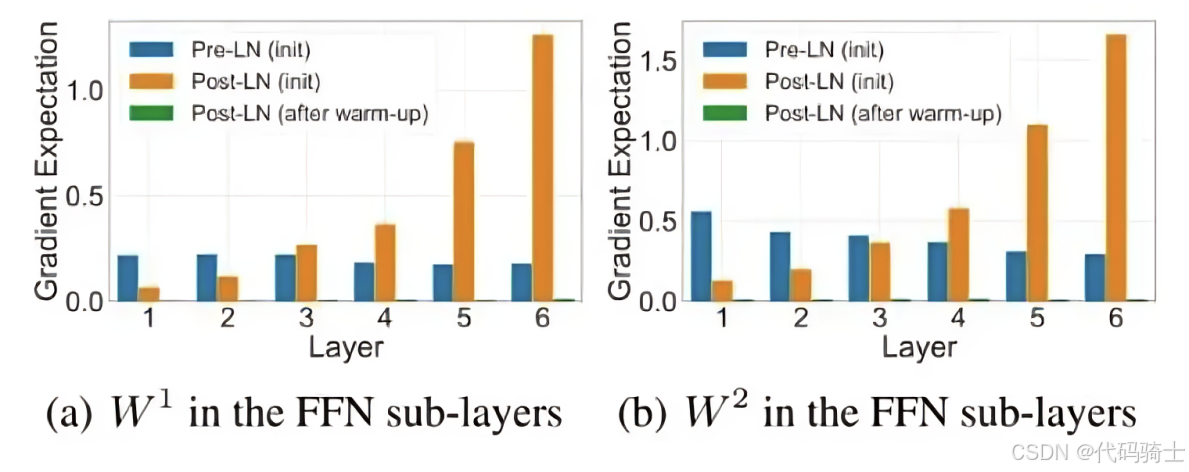
五、bLayer normalization 对比篇
5.1 LLMS 各模型分别用了 哪种 Layer normalization?
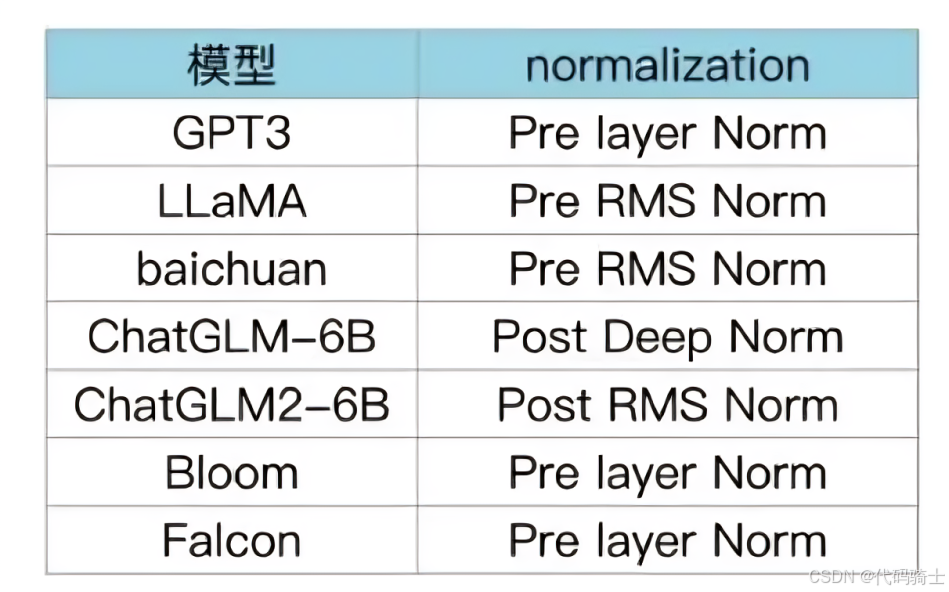
BLOOM在embedding层后添加layer normalization,有利于提升训练稳定性:但可能会带来很大的性能损失

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)