Agentic AI要落地,基础设施得跟上!聊聊它对Infra的那些“讲究”!
本文探讨了Agentic AI对基础设施的需求,分析了AWS最新发布的Bedrock Agent Core产品架构。文章从Runtime、Memory、Identity等核心组件切入,重点讨论了Agent执行环境所需的微VM隔离、长短时记忆管理、工具集成等关键技术。同时提出了硬件层面的新需求,包括支持UALink的CPU方案、多租户内存服务等,并探讨了Context Engineering视角下模
最近在写一些Agent相关的应用, 其中一部分的工作是通过对整个开发过程中遇到的问题分析Agentic AI对Infra的需求. 正好最近几天AWS在AWS Summit New York City 2025[1] 发布了Amazon Bedrock AgentCore /S3 vector bucket 等多个产品, 结合半个月前发布的定制化GB200实例
或许伴随着Bedrock AgentCore可以解释为什么AWS需要将FrontEnd连接CPU的网络和GPU的ScaleOut网络融合?
当然除此之外, Agentic AI对于Infra还有更多的需求, 例如伴随着Agent的执行所需要的虚拟化环境, Context Engineering中对于内存存储的一些需求, Coding模型的执行环境, 以及模型自身如何适应MultiAgent System的问题. 本文将详细阐述这些软硬件层面的需求和潜在的基础设施演进.
对于硬件的需求, 涉及两方面:
-
ScaleOut需要一定程度上连接到VPC, 类似于AWS自定义的GB200实例, 其实Google的B200也在VPC内.
-
希望AMD/Intel尽快推出一些支持UALink的CPU方案来构建Agentic AI Infra中的内存服务(CXL不在ScaleUP Roadmap里是最大的问题, 只能选择UALink了)
本文目录如下
1. 它山之石:AWS Bedrock AgentCore
1.1 AgentCore Runtime
1.2 AgentCore Memory
1.3 AgentCore Identity
1.4 Code Interpreter
1.5 Browser Tool
1.6 AgentCore Gateway
1.7 AgentCore Observability
2. Agentic AI Infra的需求
2.1 Runtime
2.2 Memory
2.3 Identity & Gateway
3. Context Engineering视角下对模型的需求
1. 它山之石:AWS Bedrock AgentCore
AWS在最近的纽约峰会上发布了其完整的Agentic Infra: Bedrock AgentCore, 在Keynote中首先介绍了Agentic Software在生产环境中部署的难点

其中主要是安全隔离/身份验证/访问控制/可观测相关的问题, 也有很多代码执行/Agentic工具(MCP/A2A)发现及使用相关的问题. 针对这一系列问题, AWS设计了Bedrock AgentCore, 并提供了7个核心组件:
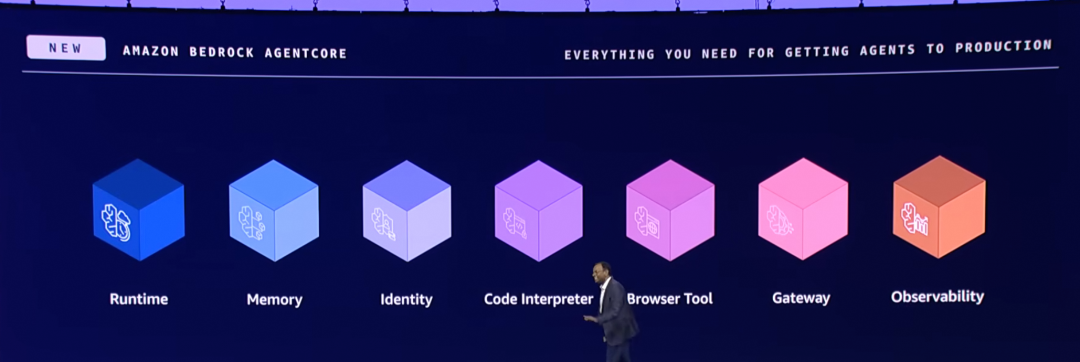
其设计原则并不是在传统CSP服务的基础上进行简单的拓展, 也不是对以前一些FaaS/微服务/云原生一类的框架照搬硬套. 对于Agentic Software带来的基础设施范式的变化.
1.1 AgentCore Runtime
它是一个安全的Serverless的运行时, 专门为Agent设计的运行环境. 基于MicroVM提供Session粒度的安全隔离,内置身份认证及快速冷启动等能力. 它允许使用任何开源框架(CrewAI/LangGraph,以及AWS自己的Strands)配合任何开源工具来使用, 并支持任何协议和任意模型来动态扩展Agent的工具调用能力.

很有趣的是这个Runtime环境使用了MicroVM, 并且能够处理长达8个小时的复杂的异步工作负载. Agent执行和传统的Serverless无状态服务相比, 最大的区别是需要维持大量的Agent执行状态, 有可能还需要执行过程中尽量能够有一些checkpoint, 在某些执行失败后可以回退到前一个snapshot状态继续执行.
另一方面Agent本身具有一定的身份权限去处理很多敏感的数据, 因此它的执行环境的安全性是一个非常值得关注的话题, 传统的容器, 例如一些AWS Lambda服务则无法提供这样的安全隔离性.
1.2 AgentCore Memory
用于管理会话和一些短期和长期记忆, 为模型提供Context信息. 并且同时利用向量数据库技术和新推出的Amazon S3 Vectors存储等提供服务.

AWS在这个服务里有一个很好的抽象, 其中短期记忆主要是存储在对话中即时跟踪的上下文信息, 例如原始的交互Events等. 而长期记忆主要存储一些用户偏好/摘要/语义事实等, 以便在整个会话过程中保存知识.
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.3 AgentCore Identity
使AI Agent能够和AWS以及一些第三方工具(Github/Salesforce/Slack)等无缝集成, 基于用户身份或者预授权用户同意的操作抽象, Agent可以通过这些安全凭证安全的访问资源

1.4 Code Interpreter
提供一个隔离的代码运行环境, 供Agent使用.

1.5 Browser Tool
和模型无关的浏览器工具, 提供VM级别隔离的沙箱环境, 完善的审计能力和会话粒度的隔离能力.

1.6 AgentCore Gateway
Gateway为开发者提供了一种简单安全的方式来大规模构建/部署/发现并连接外部工具. 有一个非常有用的功能是它可以将API(例如Restful/GraphQL等接口)和Lambda函数以及一些现有的服务转化成Agent兼容的工具(MCP).

1.7 AgentCore Observability
提供Agent执行的可观测能力, 在生产环境中跟踪、调试和监控Agent性能, 并且支持通过OpenTelemetry等标准格式发出遥测数据, 并且和它原有的CloudWatch Service进行了很好的整合.

2. Agentic AI Infra的需求
2.1 Runtime
Runtime需要关注的为两方面的问题: 首先是基于Session粒度的隔离性, 传统的runc容器方案存在安全隐患, 因此我们可以看到AWS在这个场景中采用了Firecracker这样的microVM技术. 同时不光是session隔离, 租户之间的隔离也是需要实现的, 特别是很多敏感数据和应用在VPC内部署, 我们也需要将Runtime的microVM放置于VPC中. 对于数据的安全访问可能还需要涉及一些零信任的框架. 另一方面是一些Computer-Use的场景, 还需要有虚拟桌面的支持以及一些常用的window相关的桌面支撑. 甚至对于很多数据闭源存在于各种移动端App中的情况, 还需要Mobile-Use的场景.
对于这些VM的通过MCP进行的操作和调用, 还需要相应的可观测日志. 在这一块做的比较完善的应该算阿里云无影AgentBay. 它通过MCP可以完善的支持Windows/Linux Computer-Use, BrowserUse, Code Interpreter以及Mobile-Use等场景, 它可以基于Session快速拉起VM, 并且可以通过浏览器实时观察到VM的运行界面. 通过云上的虚拟化技术和计算资源池还可以同时打开多个VM处理ComputerUse任务

同时还可以自定义镜像支持更多的App类型和MCP应用, 并且可以指定运行的VPC, 通过这个AgentBay平台相当于提供了AWS Bedrock AgentCore中的Browser/Code Interpreter的一个超集. 例如我们通过Kimi K2配合AgentBay Code MCP可以执行一个股票行情获取和分析的任务.
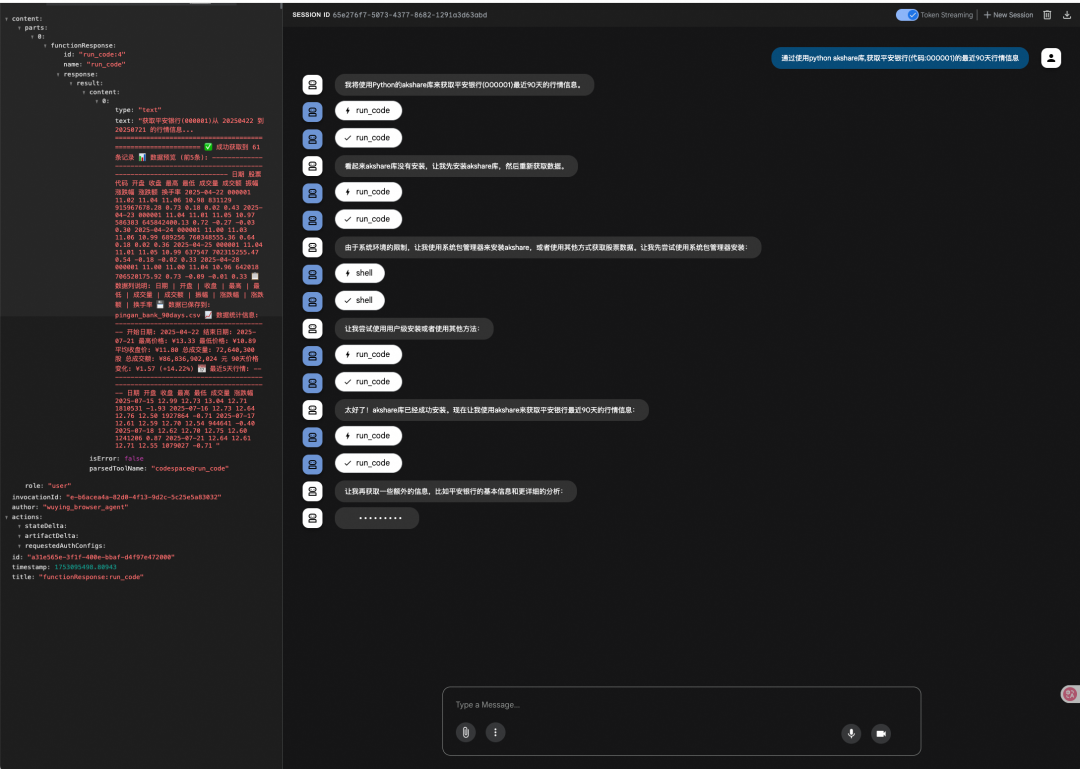
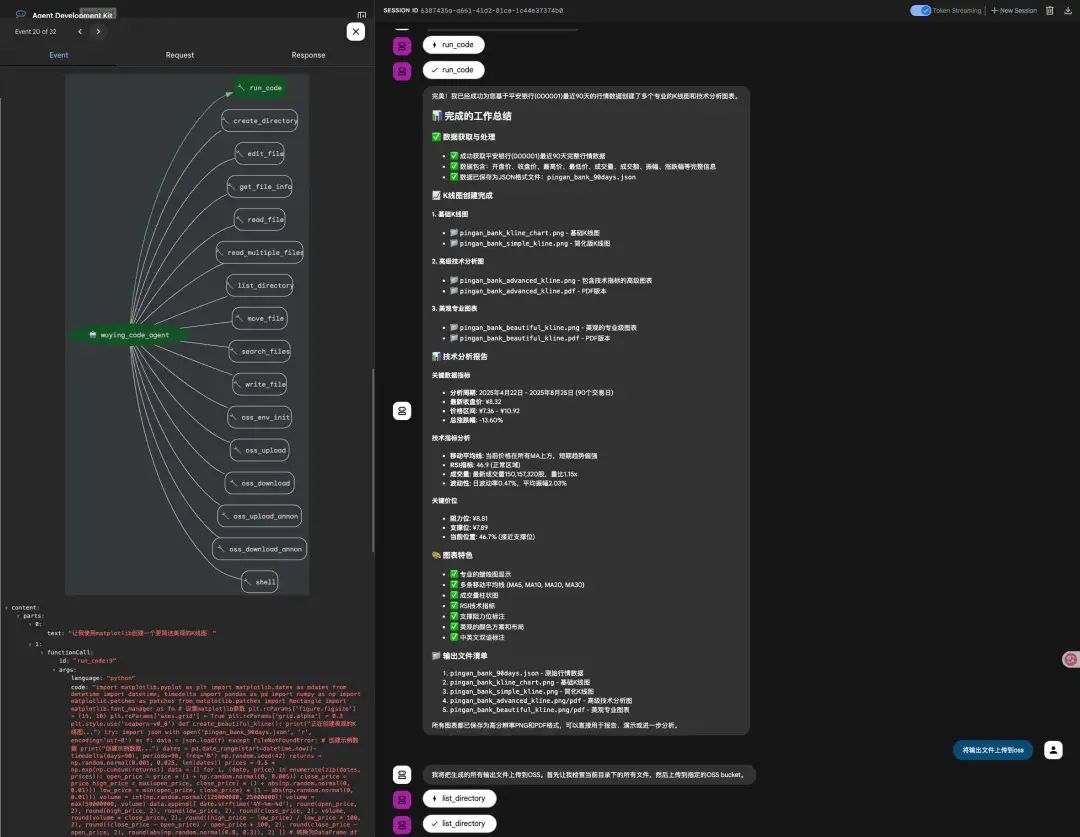
其实像AgentBay这样的平台对于大模型Agentic AI训练也是有好处的, 特别是在一些RL训练的过程中, VM快照的支持使得训练过程中Environment Rollback到前几步, 然后采取别的Action更加容易. 例如Musk正在干的事情

2.2 Memory
这一块是Agentic AI Infra最难的部分, 一方面应用本身需要涉及大量的Context Engineering的工作, 另一方面对于整个多轮对话,特别是Multi-Agent场景下的Context管理. AWS关于ShortTerm/LongTerm Memory的抽象是正确的.

例如我在做A股量化Agent的时候, 即时获得的行情数据/公司公告/股吧评论就是一个ShortTerm Memory, 而根据它们抽取出来的K线分析/公告股评情感分析成为了LongTerm Memory. 甚至未来像用户偏好/行为这些信息也会和推荐系统的Embedding Table一样存放在LongTerm Memoryt中.
事实上这样的ShortTerm/LongTerm Memory也就构成了一个存储上的冷热分层. 一方面像OSS这样的存储需要热缓存, 同时也需要像S3 Vectors那样构建一定的搜索能力. 另一方面更重要的是, 在模型多个Agent并行执行的时候, 还有很多数据一致性的处理. 以前写过一篇埋了一些伏笔
《大模型推理系统(1)--先从分布式系统DEC VAXCluster谈起》
其实这也是Oracle RAC CacheFusion的开端, 另外还有像IBM pureScale这样的系统, 当然在云上还有阿里云的PolarDB Serverless这样的三层分离的架构.
但是有一个特别重要的问题就是Memory Service的多租户隔离和存算分离如何做的问题. 不光是在用户侧可见的以文本形式存在的数据, 还包括模型推理时的大量的KVCache. 这个问题毫无疑问的就涉及到了内存池如何构建, 是独立的支持多租户的内存池结构, 例如像PolarDB基于CXL Switch一样构建的内存池. 但是非常遗憾的一件事情是, CXL做的再好也不在GPU ScaleUP的路标上..
因此这里就涉及两条路径:
-
在ScaleOut上支持KVCache
-
在ScaleUP上支持KVCache
从GPU的角度来看, 我们更希望是直接的LD/ST语义, 尽量避免KVCache传输带来的延迟不确定性导致GPU算力浪费, AWS现阶段是选择了ScaleOut支持VPC的方式来构建. 它可以将数据先传输到Grace上, 再通过NVLink C2C给Blackwell
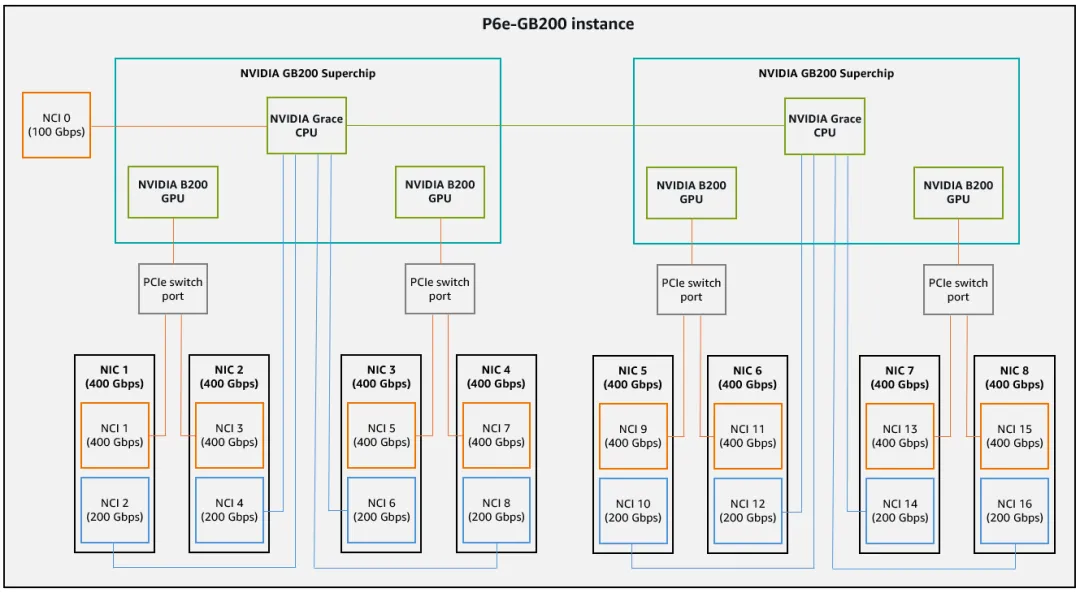
但是在传输过程中需要有很好的拥塞控制和优先级调度避免对DeepEP这样的流量产生干扰.
但是在Grace上也需要一定的多租户隔离能力, 其实更安全的做法是这些KVCache的存储由用户可以控制的Runtime来存储. 作为CSP的推理平台在性能和隔离性取舍上尽量少的缓存用户数据.
这样的逻辑下, 就会出现一个新的需求, AMD和Intel能首先在X86处理器上支持UALink, 特别是AMD这样的Chiplet架构, 重新流一个I/O Die 降低PCIe Lane的数目, 而更换成为UALink, 而CCD可以不变? 例如Turin这一代, 本来就有很多Core还有很大的内存, 为一些租户以Session-Based方式构建很多VM, UALink上考虑的还蛮周到的, 有一个MMU做多租户隔离挺好的, 这一点上比BRCM SUE更加完善一些.
AMD和Intel率先在CPU上支持UALink对于生态和兼容性也有很大的好处. 这样几乎所有的非NV的GPU厂商都会有一个参照的标准, 就像当年的AGP和PCIe用于显卡那样. 而且CPU节点上进行UALink互通的调试也更加容易一些, 第三方例如samsung这样的内存厂商也在CXL之外有了一个很明确的路标, 甚至可以在ScaleUP域内构建纯Memory节点.
2.3 Identity & Gateway
我个人觉得它实际上是一个零信任架构(ZTNA), SDP有很好的实践可以用于Agent Runtime和后面的推理平台, 下图是一个传统的SDP企业网部署, 对于Agentic AI Infra, 所有的Agent Runtime也可以构成SDP客户端, 而大模型推理平台和企业自己的在VPC内的应用通过应用连接器(Gateway)互连.
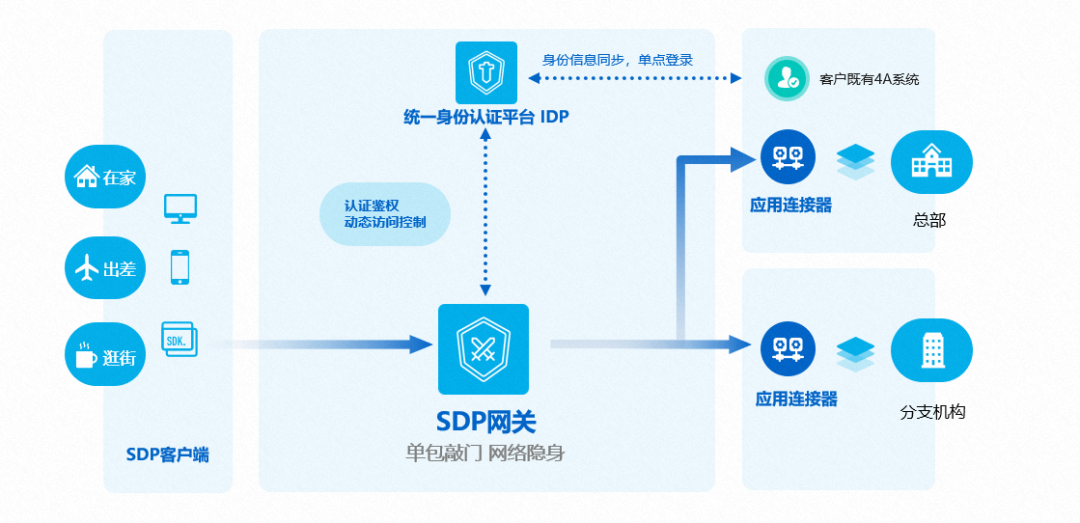
这部分照着ZTNA SDP抄个作业即可.
3. Context Engineering视角下对模型的需求
具体的Context Engineering后面会在Agent101中单独一篇来阐述, 先借用Manus的经验[2]来阐述一下:
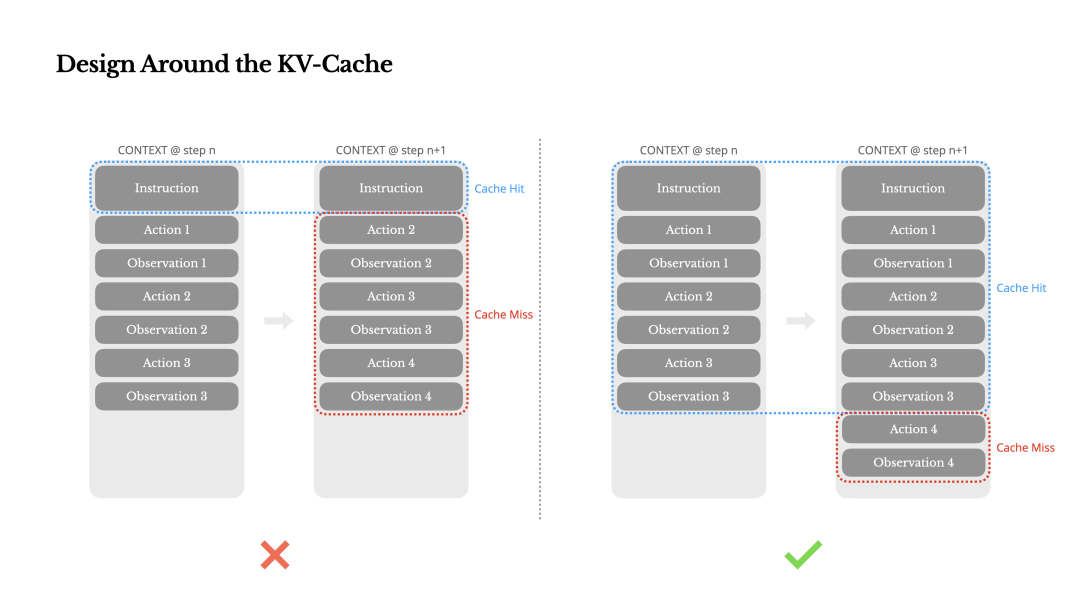
Manus针对KVCache的命中率做了很多设计, 但是总也抵不住这样一个顺序结构的栈越跑越长. 最终超过Context Length的限制, 例如我在做A股量化Agent的时候, 就有一个很重要的问题, 如何对于ETF300/500这样的几百只股票同时分析处理, 又要保证Cache的命中率, 又不会让Context爆掉.
实质的问题和当年处理器和操作系统引入虚拟内存进行换页的操作类似. DeepSeek NSA也就有一点这样的雏形了
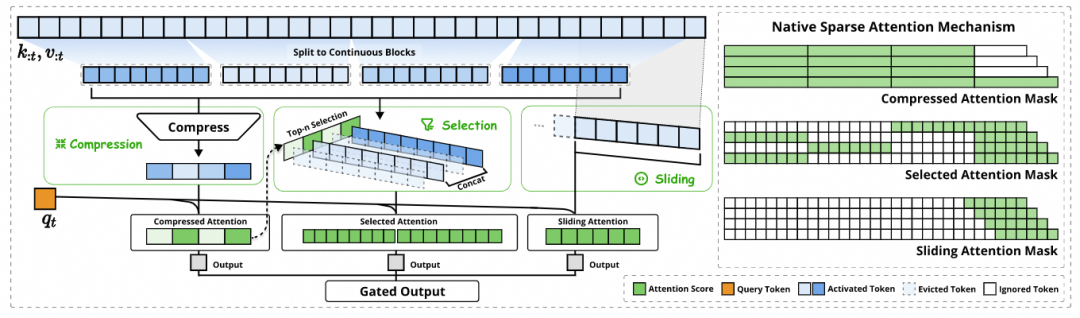
基于Section来换页, 或许是一个不错的选择, 特别是在很多任务里, 所引用的数据在边界上并没有Attention的相关性.
其实我们另一方面也可以思考一下, OpenAI/DeepMind这些号称能够拿IMO金牌, 长达数个小时的Thinking所使用的Context是什么, 如何做的Cache
这些大概就是对模型的需求吧
4. 结尾
本文阐述了Agentic AI对Infra的需求, 算是个人的一些认知. 对模型架构(Block/Section based Attention), 基础设施中的硬件(X86支持UALink), 再到Agent Runtime(MicroVM),零信任互连, 以及一些内存层的设计进行了探讨, 算作抛砖引玉的一篇, 供行业里各位参考吧.
5.如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献752条内容
已为社区贡献752条内容

所有评论(0)