【论文解读】UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
无监督伪装目标检测(UCOD)因无需依赖大量像素级标注而受到关注。现有UCOD方法通常采用固定策略生成伪标签,并用1×1卷积层作为简单解码器,导致性能远低于全监督方法。我们发现这些方法存在两大缺陷:1)伪标签噪声大,易使模型拟合错误知识;2)简单解码器难以学习伪装目标的语义特征,尤其在处理小目标时,由于伪标签分辨率低、前景背景混淆严重,性能进一步下降。
论文信息
题目:UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
链接:https://arxiv.org/abs/2506.07087
代码:https://github.com/Heartfirey/UCOD-DPL
摘要
无监督伪装目标检测(UCOD)因无需依赖大量像素级标注而受到关注。现有UCOD方法通常采用固定策略生成伪标签,并用1×1卷积层作为简单解码器,导致性能远低于全监督方法。我们发现这些方法存在两大缺陷:1)伪标签噪声大,易使模型拟合错误知识;2)简单解码器难以学习伪装目标的语义特征,尤其在处理小目标时,由于伪标签分辨率低、前景背景混淆严重,性能进一步下降。为此,我们提出一种基于动态伪标签学习的UCOD方法——UCOD-DPL,采用师生框架,包含自适应伪标签模块(APM)、双分支对抗解码器(DBA)以及“再看一眼”(Look-Twice)机制。APM模块动态融合固定策略与教师模型生成的伪标签,防止模型过拟合错误知识,同时保留自纠正能力;DBA解码器通过前景-背景对抗学习目标,引导模型克服前景背景混淆;Look-Twice机制模拟人类对伪装目标的放大观察行为,对小目标进行二次精修。大量实验表明,该方法性能优异,甚至超越部分全监督方法。
Introduction
unsupervised camouflage object detection (UCOD)
现有的UCOD通常采用固定策略生成伪标签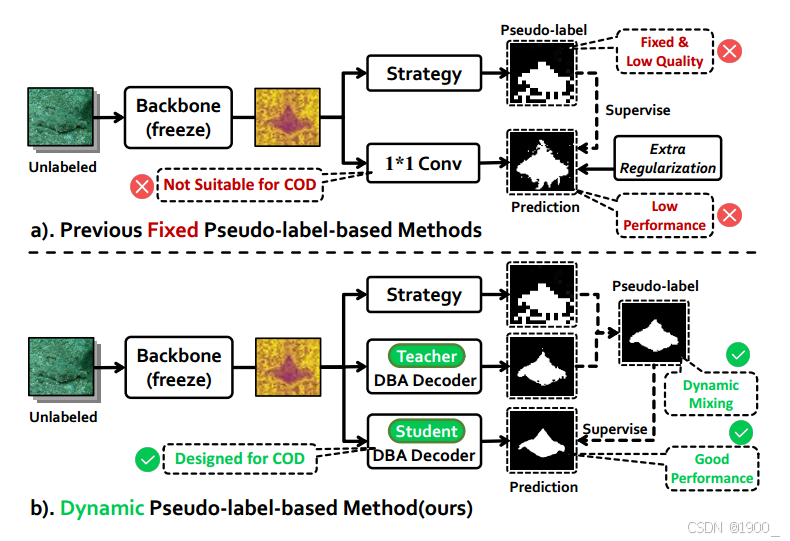
本文总结:
- 我们提出了一种新颖的 UCOD 模型——UCOD-DPL,大量实验表明,我们的方法表现出卓越性能,达到了某些全监督算法的性能水平。
- 我们引入了带有 APM 模块的师生框架。通过使用 APM,我们确保模型能够从伪标签中学习知识,同时保留识别并纠正错误的能力。
- 为了解决低分辨率伪标签和前景-背景混淆的问题,我们设计了一个 DBA 解码器,该解码器利用前景-背景对抗任务,使模型能够自适应地学习伪装前景的特征。
- 为了增强模型分割小尺寸目标的能力,我们设计了一个 Look-Twice 精修机制。该机制模仿人类行为,对较小的伪装目标进行二次分割,从而细化分割结果。
在本文中,我们提出了一种全新的模型——UCOD-DPL。我们引入了一个师生框架,该框架由自适应伪标签融合模块(APM)、双分支对抗解码器(DBA)以及Look-Twice精修策略组成。
基于固定策略生成的伪标签通常质量较低且包含大量噪声。为防止模型拟合伪标签中不可纠正的错误知识,我们设计了APM模块,该模块通过判别器和动态评分机制,自适应地融合固定策略与教师分支生成的伪标签。
为帮助模型克服前景与背景的混淆问题,我们提出了受“捕食者-猎物”动态启发的DBA解码器。该解码器通过不同的分割目标(前景与背景)以及特征正交损失,深入挖掘并学习前景与背景的判别特征。
此外,受文献[37, 38]启发,我们模拟人类在观察伪装图像时的放大行为,对尺寸较小的伪装目标进行二次精修,以提升模型对小目标的分割精度。
Related Works
介绍了无监督语义分割和伪装物体检测
然后是介绍自监督学习。
2.3 自监督学习
自监督学习(Self-Supervised Learning, SSL)彻底改变了模型利用无标注数据的方式。在当前的 SSL 方法中,一些工作采用对比学习来学习图像特征表示。MoCo 利用动态记忆库维护大量负样本;SimCLR 通过多种数据增强和投影头来最大化同一实例不同增强视图之间的相似度;BYOL 则构建了一个师生框架,其中教师模型的参数由学生模型的指数滑动平均(EMA)更新。继 BYOL 之后,DINO 采用了两个结构相同但参数集和更新策略不同的交互式编码器。受自然语言处理中自监督预训练技术的启发,另一些 SSL 方法在无标注图像上设计预文本任务(如图像着色、旋转预测和图像块重建)。BeiT 采用基于 Transformer 的架构来重建被掩膜的图像块;MAE 实现了掩膜自编码器,能够高效地重建图像缺失部分。本文中,我们使用 DINOv1 和 DINOv2 来提取鲁棒且泛化的图像特征。
Methodlolgy
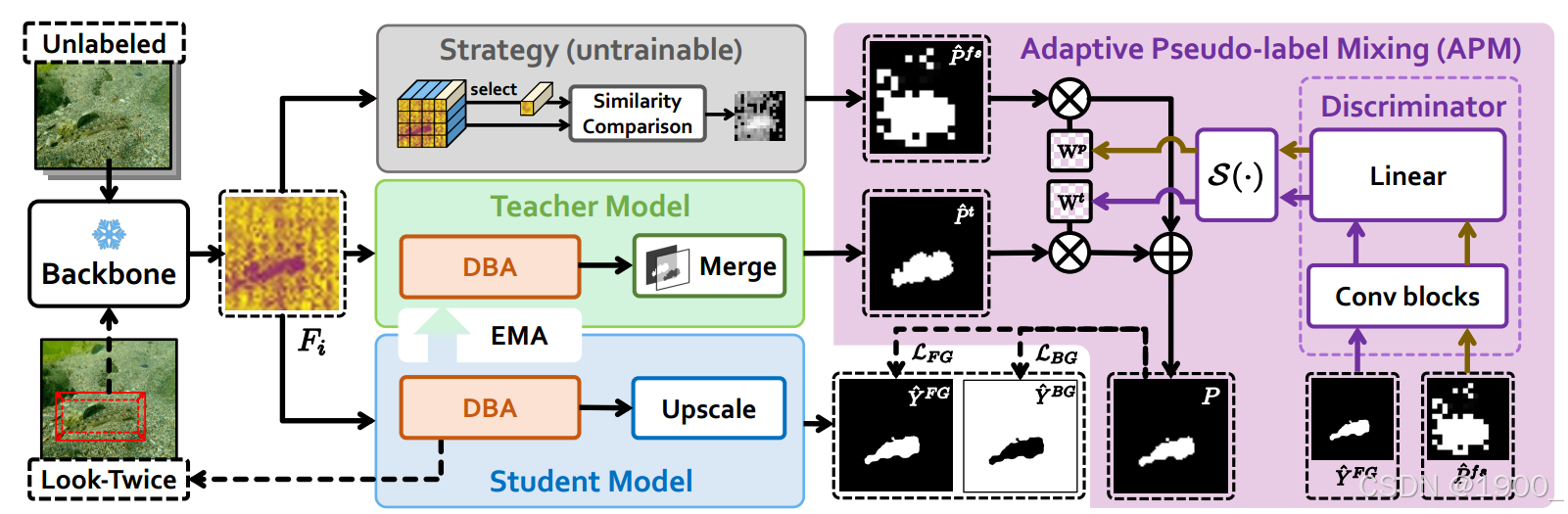
首先,第i个未标记的输入图像通过自监督预训练的骨干,以获得高级语义图像特征FiF_iFi。
然后,我们采用背景种子(background seed)方法来生成一个低分辨率的固定策略伪标签P^ifs\hat{P}^{fs}_iP^ifs,该方法在文献[44]中提出。
[44] Unsupervised object localization: Observing the background to discover objects. In The IEEE/CVF Computer Vision and Pattern Recognition Conference, pages 3176–3186, 2023.
FiF_iFi被送入师生模型中,教师模型会生成更高分辨率的伪标签P^it\hat{P}^{t}_iP^it,学生模型则生成前景和背景预测掩膜Y^iFG\hat{Y}^{FG}_iY^iFG,Y^iBG\hat{Y}^{BG}_iY^iBG。
随后将P^ifs\hat{P}^{fs}_iP^ifs和P^it\hat{P}^{t}_iP^it送入APM模块以构造混合动态伪标签PiP_iPi。
最后使用PiP_iPi来监督前景和背景预测掩膜Y^iFG\hat{Y}^{FG}_iY^iFG,Y^iBG\hat{Y}^{BG}_iY^iBG。
使用Look-Twice策略对小尺寸对象进行二次细化,以提高模型在小尺寸样本上的分割性能。
自适应伪标签融合模块(Adaptive Pseudo-Label Merging Module,APM)
现有的无监督语义分割方法通常使用固定策略( fixed-strategy )或者利用双分支模型结构,用于自监督学习以生成分割掩码。
相似性比较【32】【43】【53】
- Deep spectral methods: A surprisingly strong baseline for unsupervised semantic segmentation and localization. In The IEEE/CVF Computer Vision and Pattern Recognition Conference, pages 8364–8375, 2022
- Unsupervised salient object detection with spectral cluster voting. In The IEEE/CVF Computer Vision and Pattern Recognition Conference, pages 3971–3980, 2022
- Depth-aided camouflaged object detection. In Proceedings of the 31st ACM International Conference on Multimedia, page 3297–3306, 2023
固定策略或者可学习分支【44】【63】
- Unsupervised object localization: Observing the background to discover objects. In The IEEE/CVF Computer Vision and Pattern
Recognition Conference, pages 3176–3186, 2023- Unsupervised camouflaged object segmentation as domain adaptation. In The IEEE/CVF International Conference on Computer Vision, pages 4334–4344, 2023.
我们引入判别器 D,其输入为前景分割掩码(即固定策略伪标签 P^ifs\hat{P}^{fs}_iP^ifs 或学生模型的前景预测掩码 Y^iFG\hat{Y}^{FG}_iY^iFG),输出该掩码来源于固定策略分支的概率:
y^ip1=D(P^ifs), y^ip2=D(Y^iFG), (1) \hat{y}^{p1}_i = D( \hat{P}^{fs}_i ), \hat{y}^{p2}_i = D( \hat{Y}^{FG}_i ), (1) y^ip1=D(P^ifs), y^ip2=D(Y^iFG), (1)
其中y^ip1\hat{y}^{p1}_iy^ip1和y^ip1\hat{y}^{p1}_iy^ip1分别表示输入掩码属于固定策略分支的预测概率。我们进一步引入带时间约束的评分函数 S(·):
S(y^ip1,y^ip2)=CLIP[t/T+1/2(1+cos(π×∣y^ip1−y^ip2∣))]01 (2) S(\hat{y}^{p1}_i ,\hat{y}^{p2}_i ) = CLIP [ t/T + 1/2 (1 + cos(π × | \hat{y}^{p1}_i−\hat{y}^{p2}_i |))]^1_0 (2) S(y^ip1,y^ip2)=CLIP[t/T+1/2(1+cos(π×∣y^ip1−y^ip2∣))]01 (2)
其中 t 和 T 分别表示当前训练轮次和总轮次,CLIP(x)01CLIP(x)^1_0CLIP(x)01 表示将 x 截断,使其位于区间 [0, 1]。
训练初期,教师模型尚未具备足够定位和语义分割伪装目标的能力,难以有效指导学生模型。此时,固定策略伪标签 P^ifs\hat{P}^{fs}_iP^ifs与学生前景预测掩码Y^iFG\hat{Y}^{FG}_iY^iFG差异较大。为帮助模型学习基础的前景定位与分割任务,我们采用更高比例的 P^ifs\hat{P}^{fs}_iP^ifs监督训练。随着训练推进,Y^iFG\hat{Y}^{FG}_iY^iFG逐渐接近P^ifs\hat{P}^{fs}_iP^ifs,我们增加教师伪标签 P^it\hat{P}^t_iP^it 的比例,因其预测更稳定,有助于防止模型过拟合P^ifs\hat{P}^{fs}_iP^ifs中的噪声与错误知识。我们将所得评分作为融合权重 WitW^t_iWit 来组合固定策略伪标签 P^ifs\hat{P}^{fs}_iP^ifs和教师预测P^it\hat{P}^t_iP^it:
Wit=S(y^ip1,y^ip2),Pi=WitP^it+(1−Wit)P^ifs W^t_i = S(\hat{y}^{p1}_i ,\hat{y}^{p2}_i ) , P_i = W^t_i \hat{P}^t_i + (1 − W^t_i) \hat{P}^{fs}_i Wit=S(y^ip1,y^ip2),Pi=WitP^it+(1−Wit)P^ifs
其中PiP_iPi 表示融合后的动态伪标签。为训练判别器,我们设置二分类任务,以 P^ifs\hat{P}^{fs}_iP^ifs和Y^iFG\hat{Y}^{FG}_iY^iFG 为输入,并分别赋予标签 y^ip1=1\hat{y}^{p1}_i =1y^ip1=1 和y^ip2=0\hat{y}^{p2}_i =0y^ip2=0。随后采用交叉熵损失 L_BCE 训练判别器:
Ldis=LBCE(y^ipj,yipj), j∈1,2. (4) L_{dis} = L_{BCE}( \hat{y}^{pj}_i , y^{pj}_i ), j ∈ {1, 2}. (4) Ldis=LBCE(y^ipj,yipj), j∈1,2. (4)
训练过程中,我们将学生模型视为生成器,以类似 GAN 的方式交替训练解码器与判别器。
整个流程如下图所示: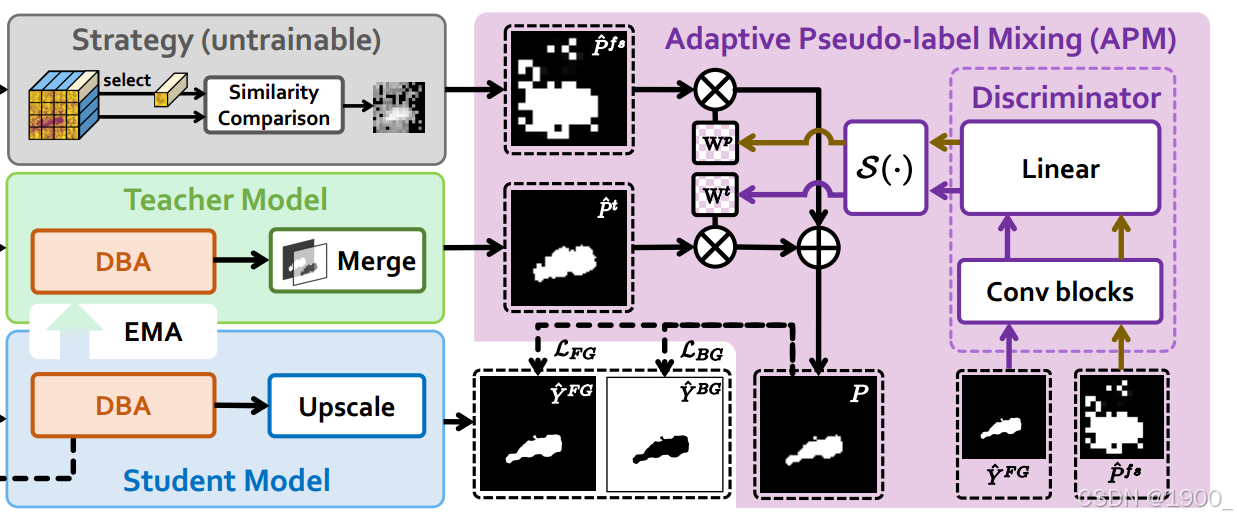
这块结合图再解释一下这个APM模块哈,原文可能说的比较简略
就是他有三个分支:固定策略分支、教师分支、学生分支
首先它有一个辨别器D,这个辨别器的输入是固定策略分支或者学生分支(一张前景分割掩码(尺寸 H×W×1,值在 0-1 之间)),经过几层卷积(或简单的 MLP)之后, 最后接一个 Sigmoid 输出层,得到一个 0-1 之间的标量,表示“这张掩码来自固定策略分支的概率”。
怎么训练这个判别器呢?把固定策略掩码标记为正样本(label=1),把学生模型当前输出的掩码标记为负样本(label=0),用二元交叉熵损失 LBCEL_{BCE}LBCE 更新判别器权重。
那么判别器学会了如何分辨掩码来自于哪个分支之后,我们输入两个掩码(固定策略分支和学生分支)会输出两个概率,这两个概率越接近,说明学生模型学得越像固定策略,这两个差的越远,那就说明学生分支还不靠谱,需要更多的依赖固定分支。
如何实现这个动态调整呢,就是这个S(·)函数。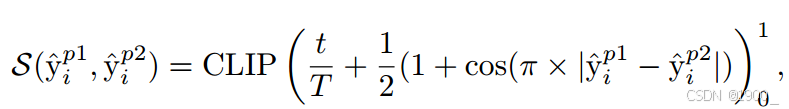
这个函数里面有t/T,意味着它会随着训练进度而变大,引入了时间约束,保证它随着训练进度,逐渐增大教师模型的比重。
另外一部分主要是用cos函数衡量,两个概率差异,差异越大,越不信任学生模型
这个函数图像是这个样子,显然两个概率做差,结果是0-1之间,那么这个函数在0-1之间是单调递减。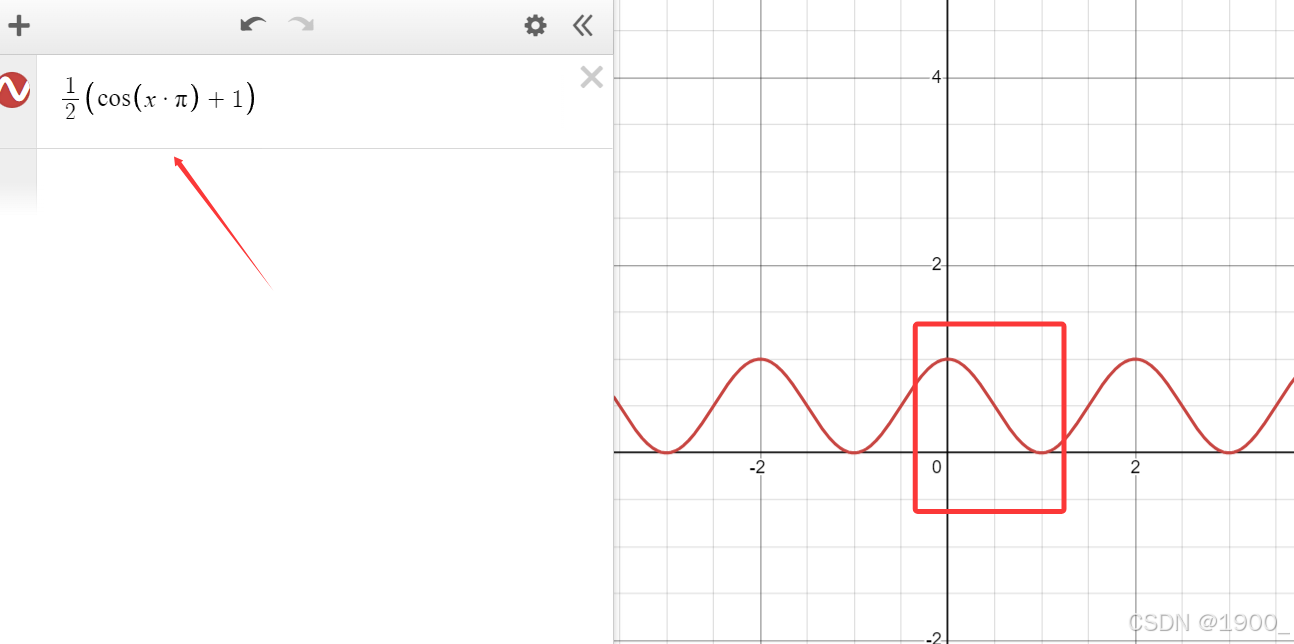
而随着学生分支越来越靠近固定分支,即差值逐渐变小,所以该函数结果逐渐增大。
我们举个例子,假设刚开始训练,那么t/T我们看作一个极小值,忽略不计,然后两个的概率应该是1和0,相减之后得到1,1与pai相乘还是pai,cos pai= -1 ,-1加上前面的1等于0,0除以2还是0. 加上前面t/T,那就是一个趋近于0的极小值。
这个CLIP代表将结果截断在[0,1]之间,CLIP(x,a,b)=max(a,min(x,b))CLIP(x,a,b)=max(a,min(x,b))CLIP(x,a,b)=max(a,min(x,b))
我们再看模型训练到最后,t/T就约等于1,假设学生分支的输出已经和固定策略很像了,则两个概率也十分接近,其差值我们看作0,则cos 0=1,1+1=2,2/2=1,后半部分等于1,前半部分也趋近于1,则结果趋近于2。
所以说这个S函数,会受到两方面影响:随着训练进度逐渐变大,随着学生分支与固定策略越来越像而变大。
那么学生分支输出的结果越来越好了,就能说明教师分支输出的结果越来越好了。
最终的标签由固定策略分支和教师分支组成,这个S函数得到的权重值,我们是用于调整教师分支的参与权重的,如下公式所示: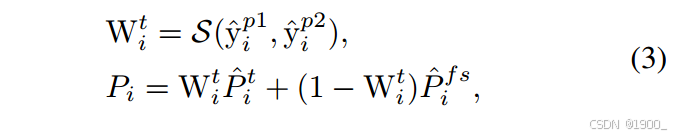
它不光会调整教师分支的比重,还会抑制固定策略分支的比重,这就是这个模块的核心:自适应
这个判别器和教师学生网络交替训练,作者在论文中说训练方式与GAN基本一致。
那么就是每 1 个训练迭代(mini-batch)就切换一次角色。
每个 batch 先做“判别器步”冻结教师 & 学生网络(包括 DBA 解码器)的全部参数,只让 判别器 D 可训练,把固定策略伪标签和学生当前预测的标签分别打上 1、0 标签,用 LdisL_{dis}Ldis 更新 D 的权重。然后接着做“生成器步”,冻结判别器 D 的权重;放开教师 & 学生网络(含 DBA 解码器)的参数;用融合后的伪标签更新师生网络。
双分支对抗解码器(DBA)
DBA由两个并行分支组成,一个负责分割前景预测掩码 Y^iFG\hat{Y}^{FG}_iY^iFG,另一个负责分割背景预测掩码Y^iBG\hat{Y}^{BG}_iY^iBG
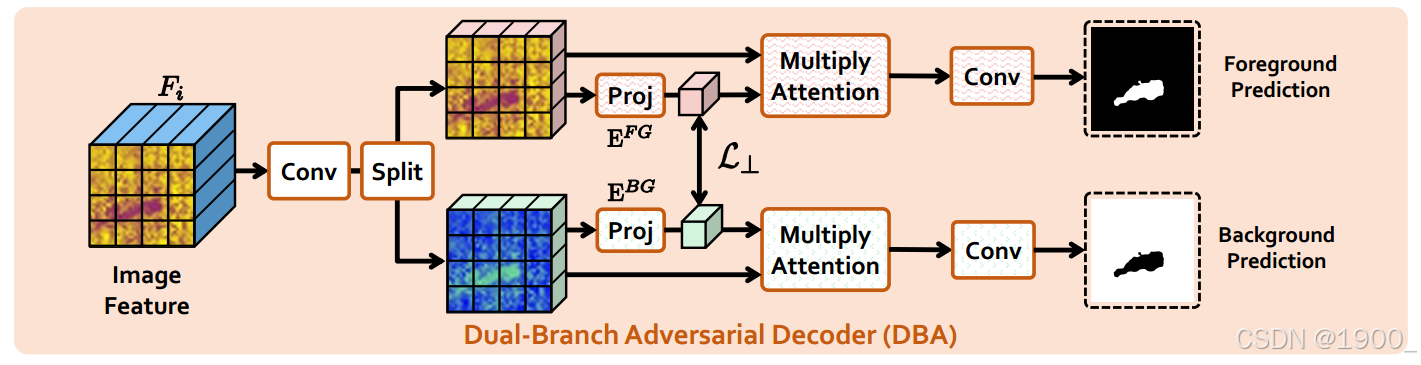
具体来说,首先从骨干网络中提取图像特征FiF_iFi,使用卷积层将其通道加倍,然后将其解耦为具有相同形状的前景和背景特征FiFGF^{FG}_iFiFG和FiBGF^{BG}_iFiBG。
然后使用两个可学习的嵌入特征EFGE^{FG}EFG和EBGE^{BG}EBG存储前景背景信息,使用这些embedding特征,与前景和背景进行注意力查询,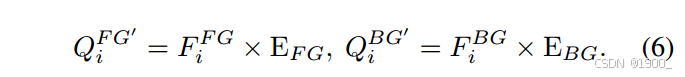
需要注意的是,这里引入了一个正交损失来对QiFG′Q^{FG'}_iQiFG′和QiBG′Q^{BG'}_iQiBG′进行规范化限制,目的是使其更加专注于独特的特征(focus on distinct features)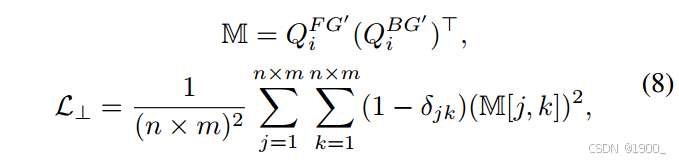
最后,用带有残差连接的乘法注意力来对特征进行加权,增强重要细节。然后将所得特征通过1 × 1卷积来输出前景预测掩模Y^iFG\hat{Y}^{FG}_iY^iFG和背景掩模Y^iBG\hat{Y}^{BG}_iY^iBG。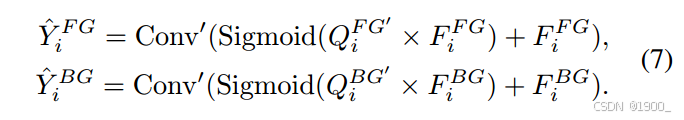
这两个掩膜使用LBCEL_{BCE}LBCE进行监督,其中背景掩膜在计算loss之前被反转。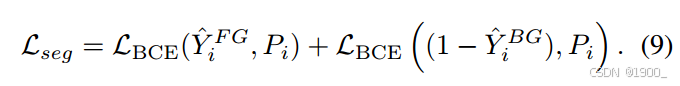
这个模块在学生分支和教师分支都用了,对于学生分支,我们得到前景掩膜和背景掩膜即可。
对于教师模型,我们进一步用两个掩膜组合来生成最终的伪标签PiP_iPi
Look-Twice Refinement
我们试图模仿观察小尺寸物体时的人类行为:首先在图像中粗略定位被遮挡的物体,然后放大以仔细检索其细节。
首先,通过模型处理输入图像以获得粗略的分割结果,使用DINOv2 作为主干
然后使用 connected components labelling algorithm(连通域算法)提取所有前景区域,就是把白色的像素连接成为区域。
将前景掩膜中提取出来的前景对象集合定义为CFGC _{FG}CFG,我们计算每个前景区域在整张图上的占比。
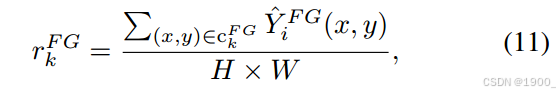
如果占比小于0.15,则认为该目标过小,需要Refinement
我们把这个“小目标”裁剪出来,但是裁剪的时候也不能不要背景,所以以检测到的每个小目标外接框为中心,按公式计算扩张比例,向外扩出一定背景上下文,裁剪出局部 patch。将 patch 重新缩放回网络输入尺寸,再次送入 同一网络 做二次分割。得到更精细的局部分割结果后,将其映射回原图坐标,替换掉对应粗掩码区域。
在训练过程中,这些patch被视为增强数据。在测试时,我们需要重新预测这些patch,将所得的前景预测掩码缩放回原始大小,并将其粘贴到粗预测图中作为细化结果。
然而,我们发现这种机制仍然存在一些弱点:对于对象被遮挡和注释碎片的情况,这种方法可能会错误地将对象的一部分放大为小对象。这可以作为我们未来工作的一个重点。
Loss
总的损失如下所示:
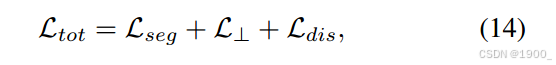
分割损失是学生和教师网络的损失
正交损失是学生分支和教师分支之间的一个约束
dis损失是判别器的损失
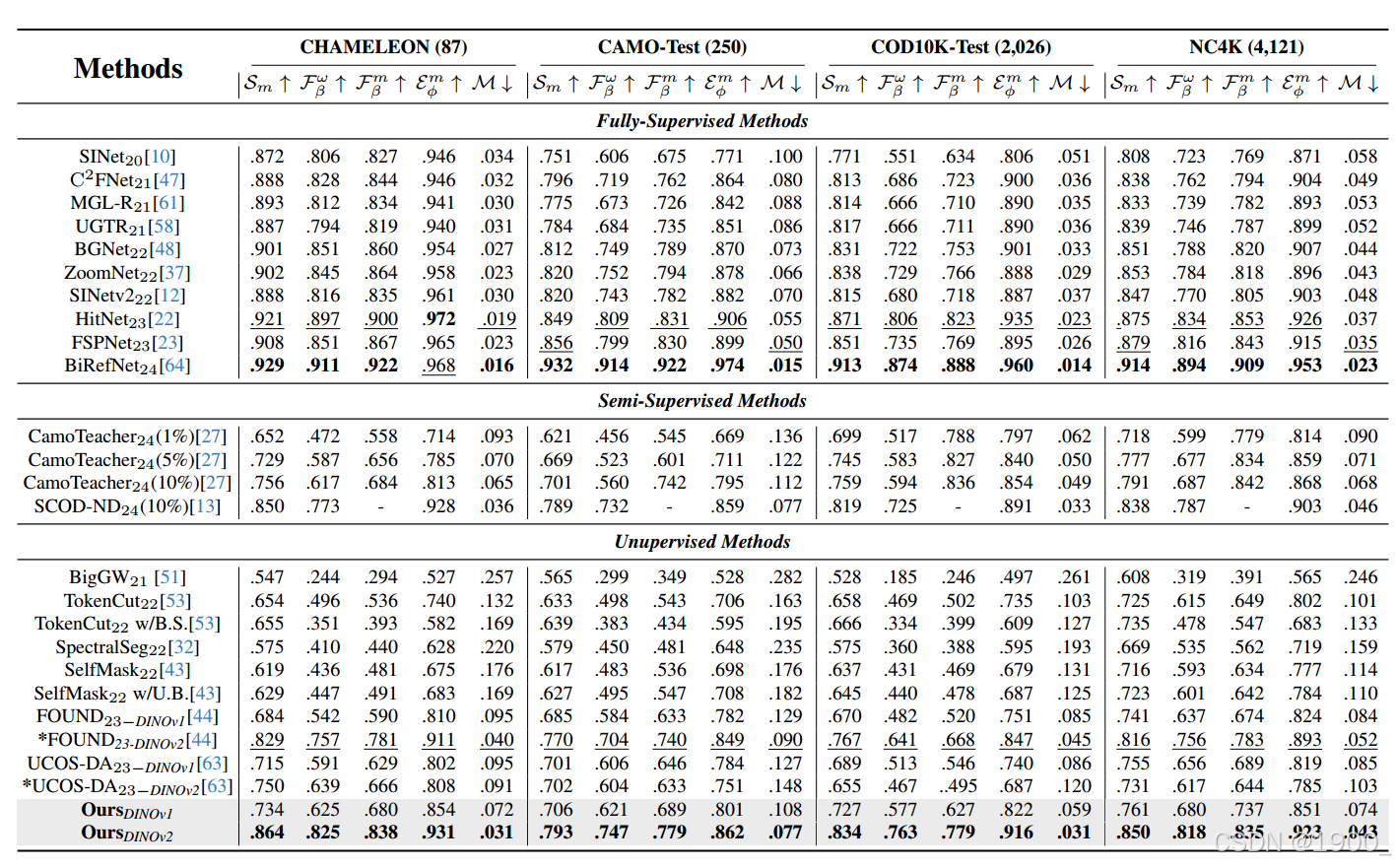
实验
固定策略分支:按照文献[44],我们采用简单的 背景种子(background seed) 方法生成粗伪标签。
主干网络:按照文献[44, 63],我们使用强大的 自监督预训练网络 DINOv2作为编码器。
教师模型更新:通过指数滑动平均(EMA),动量 η 设为 0.99。
训练轮数:共训练 25 个 epoch。
批次大小:每 GPU 32 张图像。
框架与硬件:所有实验基于 PyTorch 2.1 实现,运行在一台配备 Intel Xeon Silver 4214R CPU(2.40 GHz)、512 GB RAM 和 1 张 NVIDIA Titan A100-40G GPU 的机器上。
随机种子:所有实验使用相同的随机种子。
消融实验:
先是模块消融:
用1x1卷积替换这些模块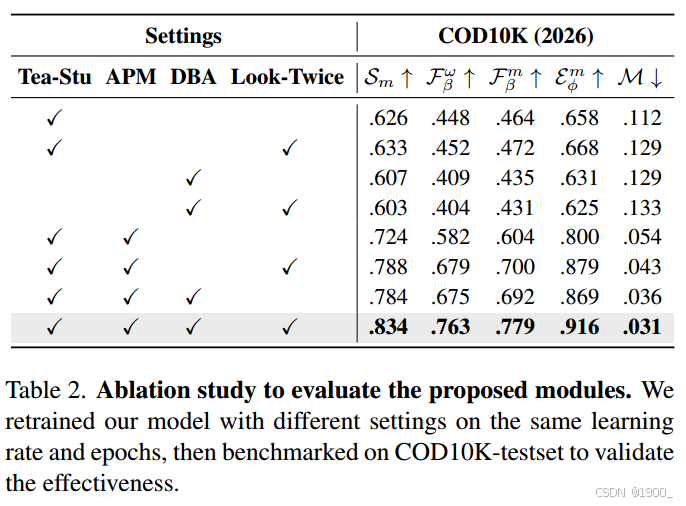
然后对融合策略进行消融:
固定1:1比例混合和线性衰减混合方法 以及本文的自适应混合方法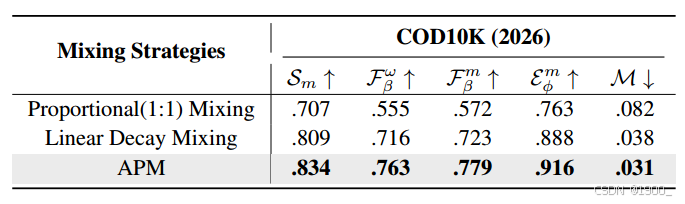
对小物体占比阈值的设置进行消融
0.15表现最好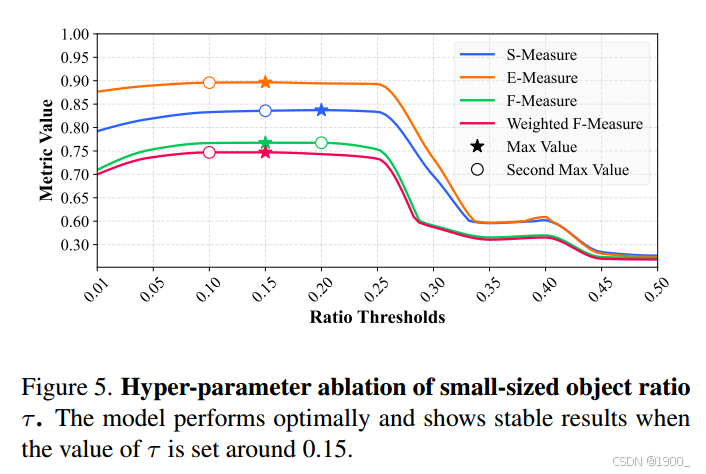
对固定策略标签生成进行消融
用纯黑或者纯白代替,或者随机Perlin噪声
最后一行是本文用的背景种子 Background-Seed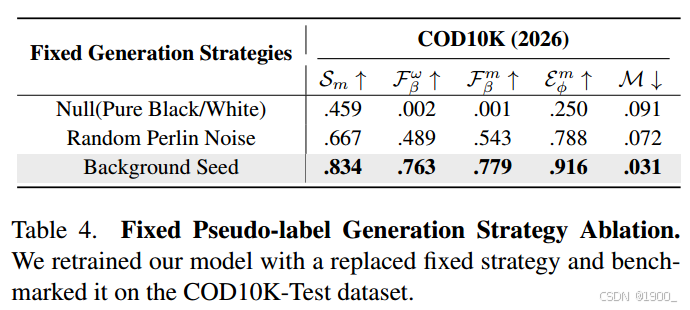
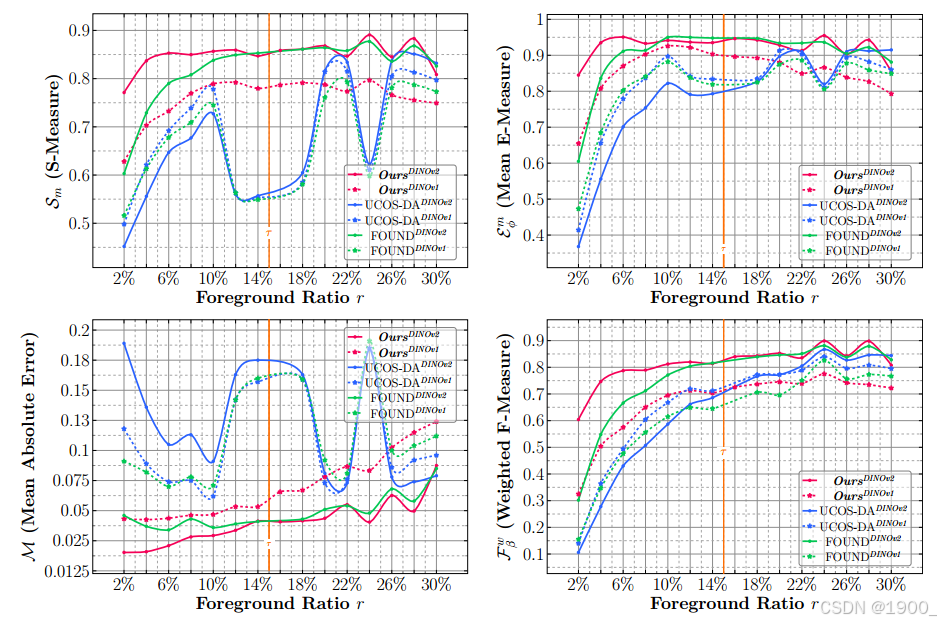
作者还对前景大小进行了研究:
我们按照测试集前景的比例以2%的间隔划分测试集,然后对我们的方法和以前的一些SOTA方法之间的性能进行基准测试[44,63]。如图6所示,我们的方法在处理较小尺寸的目标时具有显着的优势。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)