LLM 的好坏有标准吗?聊聊 BLEU、ROUGE、准确率
本文深入解析了自然语言处理领域的三大核心评估指标:BLEU、ROUGE和准确率。BLEU是机器翻译的黄金标准,通过n-gram重叠度评估质量,具有计算快速、多语言适用等优点,但存在忽略语义的局限性。ROUGE专为文本摘要设计,包含ROUGE-N(n-gram召回率)、ROUGE-L(最长公共子序列)等变体。准确率则作为基础分类指标,虽然简单直观但存在数据集敏感问题。这三种指标各有其适用场景和优缺点
引言
在大型语言模型(LLM)快速发展的今天,如何科学、全面地评估模型性能成为关键问题。评估指标不仅指导着模型的优化方向,也影响着研究社区对技术进展的客观判断。BLEU、ROUGE和准确率作为自然语言处理领域最基础和广泛使用的评估指标,各自从不同角度衡量着模型的生成质量和理解能力。本文将深入解析这些指标的原理、计算方法、适用场景及局限性。
BLEU指标:机器翻译的黄金标准
BLEU的基本原理
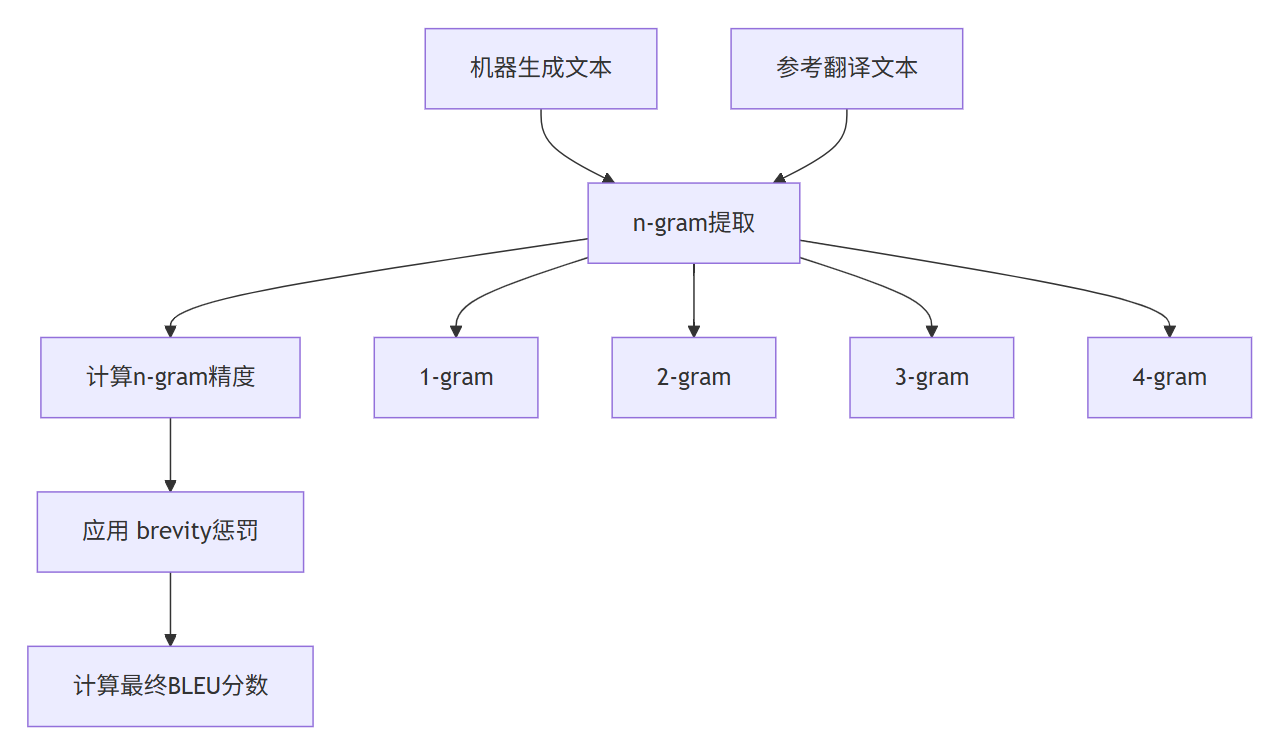
BLEU(Bilingual Evaluation Understudy)最初是为机器翻译任务设计的评估指标,通过比较机器生成文本与人工参考文本之间的n-gram重叠度来评估质量。其核心思想是:机器翻译结果与专业人工翻译越接近,质量就越高。
BLEU的数学计算
BLEU分数的计算公式如下:
![[Pasted image 20251027105000.png]]
其中:
![[Pasted image 20251027105018.png]]
import math
import collections
from fractions import Fraction
def compute_bleu(reference_corpus, candidate_corpus, max_n=4, weights=None):
"""
计算BLEU分数
参数:
reference_corpus: 参考文本列表,每个元素是一个参考文本的token列表
candidate_corpus: 候选文本列表,每个元素是一个候选文本的token列表
max_n: 最大的n-gram阶数
weights: 各n-gram的权重
"""
if weights is None:
weights = [1.0 / max_n] * max_n
candidate_length = 0
reference_length = 0
# 统计匹配的n-gram数量和总n-gram数量
matches_by_order = [0] * max_n
possible_matches_by_order = [0] * max_n
for references, candidate in zip(reference_corpus, candidate_corpus):
candidate_length += len(candidate)
# 找到长度最接近的参考文本
ref_lens = [len(ref) for ref in references]
reference_length += min(ref_lens, key=lambda x: abs(x - len(candidate)))
# 计算各阶n-gram的匹配情况
for n in range(1, max_n + 1):
candidate_ngrams = get_ngrams(candidate, n)
possible_matches_by_order[n-1] += len(candidate_ngrams)
# 计算与所有参考文本的最大匹配数
max_ref_count = 0
for reference in references:
ref_ngrams = get_ngrams(reference, n)
ref_count = count_matching_ngrams(candidate_ngrams, ref_ngrams)
max_ref_count = max(max_ref_count, ref_count)
matches_by_order[n-1] += max_ref_count
# 计算n-gram精度
precisions = []
for i in range(max_n):
if possible_matches_by_order[i] == 0:
precisions.append(0)
else:
precisions.append(matches_by_order[i] / possible_matches_by_order[i])
# 计算brevity penalty
if candidate_length > reference_length:
bp = 1.0
else:
bp = math.exp(1 - reference_length / candidate_length)
# 计算几何平均
geometric_mean = 0
for precision, weight in zip(precisions, weights):
if precision > 0:
geometric_mean += weight * math.log(precision)
bleu_score = bp * math.exp(geometric_mean)
return bleu_score
def get_ngrams(tokens, n):
"""提取n-gram"""
ngrams = collections.Counter()
for i in range(len(tokens) - n + 1):
ngram = tuple(tokens[i:i+n])
ngrams[ngram] += 1
return ngrams
def count_matching_ngrams(candidate_ngrams, reference_ngrams):
"""计算匹配的n-gram数量"""
count = 0
for ngram in candidate_ngrams:
count += min(candidate_ngrams[ngram], reference_ngrams.get(ngram, 0))
return count
BLEU的优缺点分析
| 优点 | 缺点 |
|---|---|
| 计算快速,易于实现 | 只考虑表面形式,忽略语义相似性 |
| 与人工评估有较好相关性 | 对同义词和 paraphrasing 不敏感 |
| 在多语言任务中表现稳定 | 偏向较短的生成结果 |
| 业界标准,便于比较 | 需要多个参考翻译以获得可靠结果 |
BLEU的典型应用场景
# BLEU在机器翻译评估中的应用示例
def evaluate_translation_model(model, test_dataset, tokenizer):
"""评估翻译模型的BLEU分数"""
all_candidates = []
all_references = []
for source_text, target_texts in test_dataset:
# 模型生成翻译
candidate = model.translate(source_text)
candidate_tokens = tokenizer.tokenize(candidate)
# 准备参考翻译
reference_tokens_list = [tokenizer.tokenize(ref) for ref in target_texts]
all_candidates.append(candidate_tokens)
all_references.append(reference_tokens_list)
bleu_score = compute_bleu(all_references, all_candidates)
return bleu_score
# BLEU分数解释指南
bleu_interpretation = {
"0-10": "几乎不可用",
"10-20": "可理解但质量较差",
"20-30": "质量一般",
"30-40": "质量良好",
"40-50": "质量优秀",
"50+": "接近人工翻译质量"
}
ROUGE指标:文本摘要的专用评估工具
ROUGE的基本原理
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)系列指标专门为文本摘要任务设计,主要基于召回率来评估生成摘要与参考摘要的相似度。
ROUGE的主要变体
ROUGE-N
ROUGE-N 计算 n-gram 的召回率:
![[Pasted image 20251027105034.png]]
ROUGE-L
ROUGE-L 基于最长公共子序列(LCS):
![[Pasted image 20251027105059.png]]
def compute_rouge_n(candidate, references, n=2):
"""
计算ROUGE-N分数
参数:
candidate: 候选文本的token列表
references: 参考文本的token列表列表
n: n-gram的阶数
"""
candidate_ngrams = get_ngrams(candidate, n)
if not candidate_ngrams:
return 0.0, 0.0, 0.0
# 计算与每个参考文本的匹配情况
max_recall = 0.0
for reference in references:
reference_ngrams = get_ngrams(reference, n)
if not reference_ngrams:
continue
# 计算匹配的n-gram数量
match_count = 0
for ngram in candidate_ngrams:
match_count += min(candidate_ngrams[ngram], reference_ngrams.get(ngram, 0))
recall = match_count / sum(reference_ngrams.values())
max_recall = max(max_recall, recall)
precision = match_count / sum(candidate_ngrams.values())
# 计算F1分数
if precision + max_recall == 0:
f1 = 0.0
else:
f1 = 2 * precision * max_recall / (precision + max_recall)
return precision, max_recall, f1
def compute_rouge_l(candidate, references):
"""
计算ROUGE-L基于最长公共子序列
"""
def lcs_length(x, y):
"""计算最长公共子序列长度"""
m, n = len(x), len(y)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
if x[i-1] == y[j-1]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
return dp[m][n]
candidate_len = len(candidate)
max_r_lcs = 0.0
max_p_lcs = 0.0
for reference in references:
reference_len = len(reference)
lcs = lcs_length(candidate, reference)
r_lcs = lcs / reference_len if reference_len > 0 else 0.0
p_lcs = lcs / candidate_len if candidate_len > 0 else 0.0
max_r_lcs = max(max_r_lcs, r_lcs)
max_p_lcs = max(max_p_lcs, p_lcs)
# 计算F1分数
if max_p_lcs + max_r_lcs == 0:
f_lcs = 0.0
else:
f_lcs = 2 * max_p_lcs * max_r_lcs / (max_p_lcs + max_r_lcs)
return max_p_lcs, max_r_lcs, f_lcs
ROUGE指标对比分析
| ROUGE变体 | 计算基础 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| ROUGE-1 | 1-gram重叠 | 基础评估 | 计算简单快速 | 忽略词序信息 |
| ROUGE-2 | 2-gram重叠 | 标准评估 | 考虑局部词序 | 对paraphrase不敏感 |
| ROUGE-L | 最长公共子序列 | 流畅性评估 | 考虑句子级结构 | 计算复杂度较高 |
| ROUGE-W | 加权LCS | 连贯性评估 | 考虑连续匹配 | 实现复杂 |
| ROUGE-S | 跳跃bigram | 创意文本 | 允许词间间隔 | 结果解释性差 |
准确率:分类任务的基础指标
准确率的定义与计算
准确率是最直观的分类任务评估指标,表示模型预测正确的样本比例:
![[Pasted image 20251027105114.png]]
def compute_accuracy(predictions, labels):
"""
计算分类准确率
参数:
predictions: 模型预测结果
labels: 真实标签
"""
correct = 0
total = len(predictions)
for pred, label in zip(predictions, labels):
if pred == label:
correct += 1
accuracy = correct / total
return accuracy
def compute_per_class_accuracy(predictions, labels, classes):
"""
计算每个类别的准确率
"""
class_correct = {cls: 0 for cls in classes}
class_total = {cls: 0 for cls in classes}
for pred, label in zip(predictions, labels):
class_total[label] += 1
if pred == label:
class_correct[label] += 1
per_class_accuracy = {}
for cls in classes:
if class_total[cls] > 0:
per_class_accuracy[cls] = class_correct[cls] / class_total[cls]
else:
per_class_accuracy[cls] = 0.0
return per_class_accuracy
准确率的局限性及补充指标
虽然准确率直观易懂,但在某些场景下存在明显局限性:
class ClassificationMetrics:
def __init__(self, predictions, labels, classes):
self.predictions = predictions
self.labels = labels
self.classes = classes
def compute_confusion_matrix(self):
"""计算混淆矩阵"""
cm = {}
for true_class in self.classes:
cm[true_class] = {}
for pred_class in self.classes:
cm[true_class][pred_class] = 0
for pred, true in zip(self.predictions, self.labels):
cm[true][pred] += 1
return cm
def compute_precision_recall_f1(self):
"""计算精确率、召回率和F1分数"""
cm = self.compute_confusion_matrix()
metrics = {}
for cls in self.classes:
tp = cm[cls][cls]
fp = sum(cm[other][cls] for other in self.classes if other != cls)
fn = sum(cm[cls][other] for other in self.classes if other != cls)
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
if precision + recall > 0:
f1 = 2 * precision * recall / (precision + recall)
else:
f1 = 0
metrics[cls] = {
'precision': precision,
'recall': recall,
'f1': f1
}
return metrics
def compute_macro_average(self):
"""计算宏平均"""
metrics = self.compute_precision_recall_f1()
macro_precision = sum(m['precision'] for m in metrics.values()) / len(metrics)
macro_recall = sum(m['recall'] for m in metrics.values()) / len(metrics)
macro_f1 = sum(m['f1'] for m in metrics.values()) / len(metrics)
return {
'macro_precision': macro_precision,
'macro_recall': macro_recall,
'macro_f1': macro_f1
}
综合评估框架与实践建议
多指标综合评估
在实际应用中,通常需要结合多个指标来全面评估模型性能:
class ComprehensiveEvaluator:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def evaluate_generation_task(self, test_data, task_type):
"""评估生成式任务"""
results = {}
if task_type == "translation":
# 机器翻译任务使用BLEU
references = [item['references'] for item in test_data]
candidates = [self.model.translate(item['source']) for item in test_data]
results['bleu'] = compute_bleu(references, candidates)
elif task_type == "summarization":
# 文本摘要任务使用ROUGE
references = [item['references'] for item in test_data]
candidates = [self.model.summarize(item['text']) for item in test_data]
rouge1_f1 = compute_rouge_n(candidates, references, 1)[2]
rouge2_f1 = compute_rouge_n(candidates, references, 2)[2]
rougeL_f1 = compute_rouge_l(candidates, references)[2]
results.update({
'rouge1_f1': rouge1_f1,
'rouge2_f1': rouge2_f1,
'rougeL_f1': rougeL_f1
})
elif task_type == "classification":
# 分类任务使用准确率和F1
predictions = [self.model.classify(item['text']) for item in test_data]
labels = [item['label'] for item in test_data]
accuracy = compute_accuracy(predictions, labels)
metrics_calculator = ClassificationMetrics(predictions, labels,
set(labels))
f1_metrics = metrics_calculator.compute_macro_average()
results.update({
'accuracy': accuracy,
'macro_f1': f1_metrics['macro_f1']
})
return results
def generate_report(self, results):
"""生成评估报告"""
report = "模型评估报告\n"
report += "=" * 50 + "\n"
for metric, value in results.items():
report += f"{metric}: {value:.4f}\n"
# 提供性能解读
report += "\n性能解读:\n"
if 'bleu' in results:
bleu = results['bleu'] * 100
if bleu < 20:
report += "BLEU分数较低,翻译质量需要显著改进\n"
elif bleu < 40:
report += "BLEU分数中等,翻译质量基本可用\n"
else:
report += "BLEU分数较高,翻译质量优秀\n"
return report
指标选择指南
| 任务类型 | 主要指标 | 辅助指标 | 注意事项 |
|---|---|---|---|
| 机器翻译 | BLEU | TER, METEOR | 需要多个参考翻译 |
| 文本摘要 | ROUGE | BLEU, 人工评估 | 关注ROUGE-2和ROUGE-L |
| 文本分类 | 准确率 | F1, 精确率, 召回率 | 类别不平衡时慎用准确率 |
| 问答系统 | F1, EM | BLEU, ROUGE | 结合精确匹配和模糊匹配 |
| 对话系统 | 多样性 | 连贯性, 相关性 | 需要多维度评估 |
未来发展趋势
随着LLM能力的扩展,传统指标面临挑战,新的评估方法正在发展:
- 基于LLM的评估:使用更强大的LLM来评估生成质量
- 语义相似度指标:如BERTScore,更好地捕捉语义相似性
- 多维度评估框架:同时评估事实性、安全性、偏见等多个维度
- 任务特定指标:为特定任务设计的专业化指标

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)