收藏必备:从零学习LightRAG:知识图谱增强型RAG架构实战指南
LightRAG:知识图谱增强的新型RAG架构 摘要(148字): LightRAG由北邮与港大联合开发,创新性地融合知识图谱技术,通过图结构化文本索引和双层检索机制(local/global/hybrid/naive四种模式)提升检索效率。其核心突破在于实体关系抽取和增量更新能力,特别适合处理复杂依赖关系查询。实验显示不同模式各有侧重,但整体效果受数据集影响较大。项目提供完整代码实现和Neo4j
LightRAG是由北邮和港大联合开发的新型RAG架构,创新性地结合知识图谱技术,通过图结构化文本索引和双层检索机制(local/global/hybrid/naive四种模式)提升检索效率。它能够增量更新知识,解决传统RAG在复杂依赖关系检索上的不足,并支持Neo4j可视化。本文提供了完整代码实现,适合开发者学习和实践。
前排提醒!文末有大模型CSDN独家资料包,看到最后别错过哦~
1 概述
LightRAG是一种结合知识图谱技术的新型RAG架构,它是由北京邮电大学和香港大学联合发表的论文,它的核心原理,我们在[论文解读LightRAG:知识图谱与大语言模型的结合],RAG方向的新探索中已经介绍过了,在此处简单复习一下,简单说,LightRAG还是对检索方面做了比较大的创新,具体而言有两点:
- 图结构化文本索引:使用LLM识别文本中的实体(如人名、地点、事件)及其关系,从而构建知识图谱,这样能够更有效地捕捉实体之间地复杂依赖关系。
- 双层检索机制:LightRAG采用双层检索系统,结合低层次检索(针对特定实体及其关系的精确信息)和高层次检索(涵盖更广泛的主题和上下文)。这种分层检索策略能够从不同粒度级别收集数据,提高检索的全面性和效率。
除了索引方面的创新,LightRAG还可以增量更新知识,新的文档可以无缝集成到现有的图结构中,而无需重建整个索引。
需要注意的是,LightRAG这类借助知识图谱的RAG技术,它要解决的问题,其实跟常规的RAG是有区别的。
假如现在LLM在训练阶段是没有见过《西游记》的,那如果我们使用《西游记》作为知识库来构建一个RAG,当问到类似“唐僧的徒弟都是些什么来历”,传统RAG是要使用这句话去原文做语意/关键词检索的,很显然《西游记》中不太可能会有类似“唐僧的徒弟来历分别是…”这样直白的表述,而是“孙悟空,唐僧的大徒弟,曾经是…”、“猪八戒,法号猪悟能,唐僧的二徒弟,曾经是天蓬元帅,因为…”、“沙和尚,唐僧的三徒弟,曾任卷帘大将…”,而使用知识图谱,分别抽取出唐僧、孙悟空、猪八戒、沙和尚,以及他们之间的关系,则面对“唐僧的徒弟都是些什么来历”这样的问题时,会首先解析到要查找与唐僧有师徒关系的实体,进而查找这些实体的属性——来历,这样很容易检索出三个徒弟的信息,从而正确回答问题。
2 效果
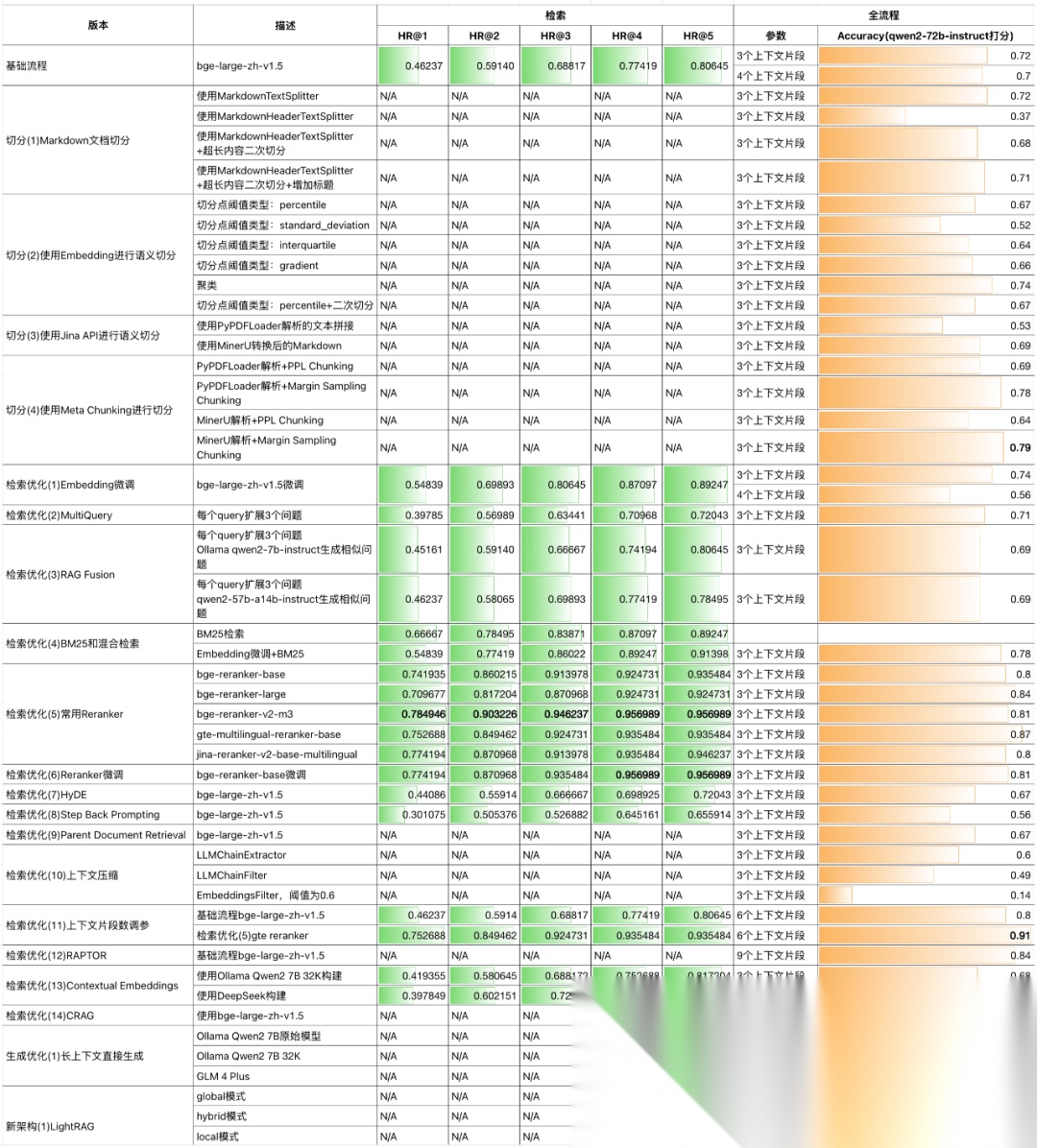
虽然LightRAG在一些测试集上取得了比较好的效果,但在我们的测试用例中,变现非常差,有可能是因为这个测试集不适合使用LightRAG,也有可能是参数没有调好,欢迎大家在评论区讨论。
LightRAG有4种模式,他们的工作方式是:
- naive:这是经典的RAG检索模式,基于查询向量直接检索与查询最相关的文档片段(chunks)
- local:基于低层次关键词(low-level keywords)进行检索。这些关键词通常对应具体实体。通过检索与这些实体相关的数据,获取其邻域内的关系和原始文档片段
- global:基于高层次关键词(high-level keywords)进行检索,这些关键词通常对应广泛的概念或主题。通过检索与这些概念相关的全局关系,获取相关实体和文档片段
- hybrid:结合了local和global模式的优点。同时利用低层次和高层次关键词,分别检索局部和全局信息,然后将结果合并
3 核心代码
为了公平对比,本文所使用的Embedding,和其他的实验保持一致,都是使用HuggingFace库加载的bge-large-zh-v1.5,为此还特意修改了代码。
大模型也使用了Ollama中的qwen2-7b,考虑到LightRAG的上下文通常比较长,此处做了修改,使得它可以接受更长的上下文,具体修改方法可以参考使用RAG技术构建企业级文档问答系统:生成优化(1)超长上下文LLM vs. RAG。本文代码已开源,地址在:https://github.com/Steven-Luo/MasteringRAG/blob/main/new_arch/01_lightrag.ipynb
3.1 创建LightRAG对象
from
lightrag
import
LightRAG
from
lightrag.llm
import
ollama_model_complete
from
lightrag.utils
import
EmbeddingFunc
from
transformers
import
AutoTokenizer, AutoModel
# 可以替换为本地路径
model_path =
'BAAI/bge-large-zh-v1.5'
embeddings = get_embeddings(model_path)
rag = LightRAG(
working_dir=expr_dir,
llm_model_func=ollama_model_complete,
llm_model_name=
'qwen2:7b-instruct-32k'
,
chunk_token_size=
500
,
chunk_overlap_token_size=
50
,
embedding_func=EmbeddingFunc(
embedding_dim=
1024
,
max_token_size=
500
,
func=
lambda
texts: hf_ollama_embedding(
texts,
hf_embed_model=embeddings
)
# func=lambda texts: ollama_embedding(
# texts,
# embed_model="znbang/bge:large-zh-v1.5-q8_0"
# )
# func=lambda text: hf_embedding(
# text,
# tokenizer=AutoTokenizer.from_pretrained(model_path),
# embed_model=AutoModel.from_pretrained(model_path, device_map=device)
# )
)
)
3.2 建立索引
# processed_texts是将知识库拼接成了一个长字符串
rag.insert(processed_texts)
3.3 使用
from
lightrag
import
QueryParam
# naive模式
print
(rag.query(
'报告的发布日期是什么时候?'
,
QueryParam(
mode=
'naive'
,
top_k=
2
)
))
# global模式
print
(rag.query(
'报告的发布日期是什么时候?'
,
QueryParam(
mode=
'global'
,
top_k=
2
)
))
# hybrid模式
print
(rag.query(
'报告的发布日期是什么时候?'
,
QueryParam(
mode=
'hybrid'
,
top_k=
2
)
))
# local模式
print
(rag.query(
'报告的发布日期是什么时候?'
,
QueryParam(
mode=
'local'
,
top_k=
2
)
))
QueryParam有一个only_need_context参数,当它设置为True时,可以查看检索结果,样例代码中有检索样例,从检索样例也可以大致看出来LightRAG效果不好的原因。
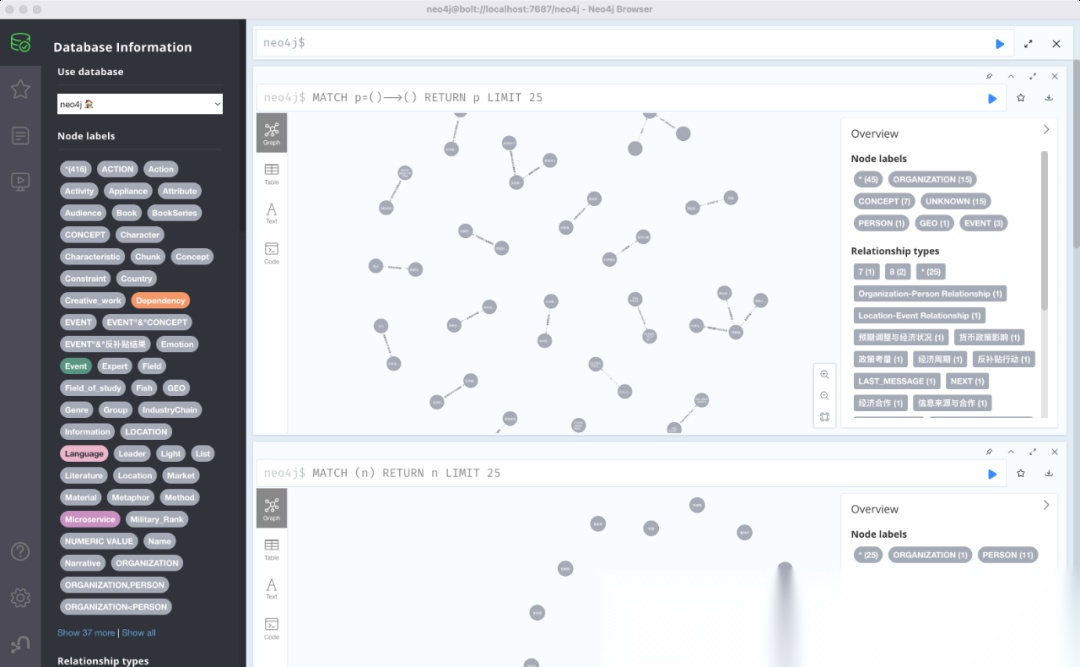
4 可视化
最终,LightRAG的结果,可以方便地使用Neo4j进行可视化,导入Neo4j的样例代码在:https://github.com/Steven-Luo/MasteringRAG/blob/main/new_arch/graph_visual_with_neo4j.py
可视化效果如下:
零基础如何学习大模型
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 36
36 0
0- 0



 已为社区贡献389条内容
已为社区贡献389条内容

所有评论(0)