Agentic RAG-R1:让大模型从「检索助手」跃升为「思考+搜索王者」!
汇总已有证据,压缩上下文✅4🛠️。
Agentic RAG-R1 是由北京大学研发的一项开源研究项目,旨在推动语言模型在自主检索与推理能力方面的能力边界。该项目通过引入强化学习策略(GRPO),构建了一个可自我规划、检索、推理与总结的智能体式 RAG 系统。
核心亮点
-
1. Agentic RAG 架构:融合检索增强生成(RAG)与 Agentic AI 机制,模型不仅生成答案,还能“决定如何生成答案”。
-
2. 强化学习优化(GRPO):借助 Generalized Relevance Policy Optimization,让模型学会更合理地选择检索和推理步骤。
-
3. 多轮推理与回溯能力:支持计划、回溯、总结等多种 agent 行为,实现人类式的问题解决流程。
-
4. LoRA 与量化支持:低成本微调与高效推理并存,轻松部署大模型至生产环境。
-
5. 丰富奖励机制:引入格式、准确性、RAG 表现等多个维度的奖励,训练出更“懂业务”的智能体。
Github项目地址: https://github.com/jiangxinke/Agentic-RAG-R1
“模型自主、工具自选、推理自洽”——Agentic RAG-R1 用强化学习把 RAG 带进智能体时代。
📚 背景:为什么 RAG 需要 “Agentic”?
-
• 事实性:RAG 通过外部检索解决 “幻觉” 问题,但仍依赖人工提示来决定何时检索。
-
• 上下文爆炸:检索结果越多,拼接进上下文越长,反而稀释关键信息。
-
• 多跳推理:复杂任务需要 “查-思-查-思” 循环,仅一次检索难以覆盖。
Agentic RAG-R1 让模型在每一步“思考”时都能自主决定:
-
1. 是否检索? —— 省掉无关调用,提高效率
-
2. 检索什么? —— 人类不再手写复杂 prompt
-
3. 如何引用? —— 自动将证据融入推理链
🏗️ 体系结构:全面的 Agentic 思考
✨ 核心理念:两大王牌技术的强强联合

- 🔍 检索增强生成 (RAG):在生成过程中即时从外部知识库检索信息,兼具语言模型的创造力与实时、可信的事实。
- 🤖 Agentic AI 智能体:让模型自主决定何时检索、检索什么,以及如何把检索证据编织进推理链,真正做到“会思考、会行动”。
🏗️ 架构:基于 TC-RAG 的智能体思考循环
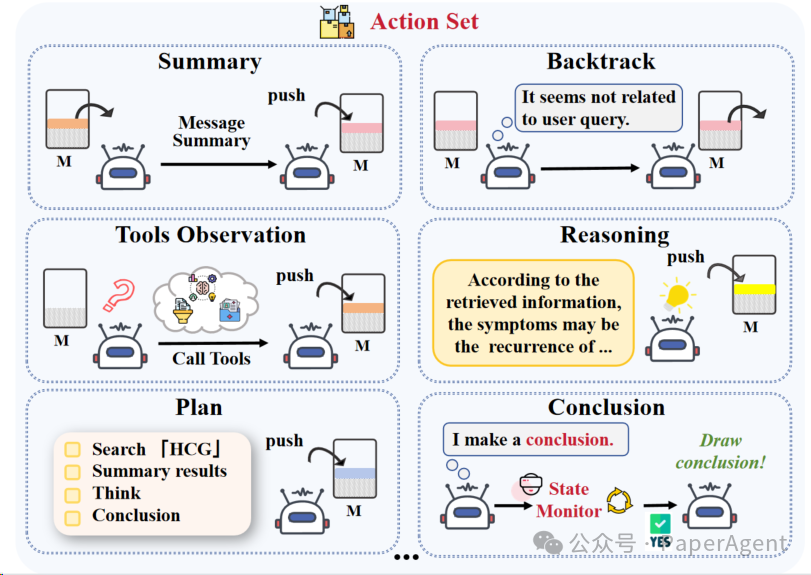
目前支持如下动作:
|
# |
动作 |
说明 |
状态 |
|
1 |
🤔 Reasoning(推理) |
展开思考、提出假设 |
✅ |
|
2 |
🔄 Backtrack(回溯) |
回到上一节点,修正思路 |
✅ |
|
3 |
📝 Summary(总结) |
汇总已有证据,压缩上下文 |
✅ |
|
4 |
🛠️ Tool Observation(工具调用) |
访问 Wiki / 文档 / 知识图谱等 |
✅ |
|
5 |
✅ Conclusion(结论) |
输出最终答案 |
✅ |
🔬 技术细节深挖
Features ✨
| 组件 | 关键点 | 优势 |
| GRPO (Generalized Relevance Policy Optimization) |
采样多条推理-检索轨迹,对“高相关、高准确、高格式”路径赋正奖励 |
训练稳定
、收敛快,避免 RLHF 里的 Reward Hacking |
| LoRA + NF4 量化 |
10 % 参数可训练,int-4 存储 |
GPU 省钱
,多实验迭代无压力 |
| Deepspeed Zero-3 |
权重 & 优化器拆分到 CPU / NVMe |
3×A100 → 32B
轻松起飞 |
| 多模态工具接口 |
支持文本、代码、数据库、REST API |
让模型在“真实工作流”里落地 |
奖励公式: (
其中 r_rag 由 RAGAS 自动评测检索片段是否被有效引用。
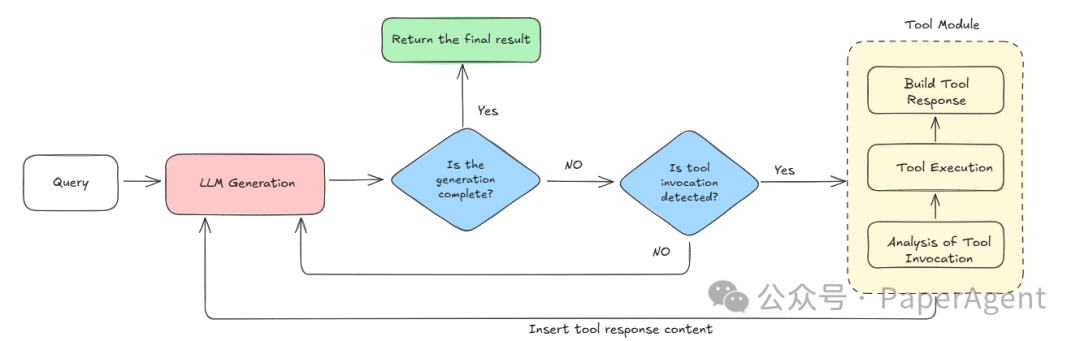
Rollout Generation 🔄
📊 结果:数据说话
数据集:MedQA(中英双语) | Judge Model:Qwen-2.5-72B
| 设置 | 格式准确率 ↑ | 答案准确率 ↑ |
|
微调前 |
39 % |
84 % |
|
微调前 + 检索 |
56 % |
79 % |
| 微调后 + 检索 | 92 % (+53 %) | 87 % (+3 %) |
-
• 跨语言:中/英两份测试集均显著提升
-
• 复杂推理:多跳问题正确率提升 8 % 以上
-
• 工具调用成功率:> 95 %,日志可追溯
实际测试结果:

💬 FAQ
Q1:必须用 32B 模型吗?
A1:不需要!我们默认用 Qwen-2.5-7B-Instruct;你也可以换成 Llama-3-8B / Baichuan-13B,只需改配置。
Q2:RL 训练很复杂吗?
A2:脚本参数与常规 LoRA 差不多,多加一份奖励配置即可。CPU 显存不足?Zero-3 + Offload 轻松搞定。
📢 结语 & 口号
“模型自主,检索在手;深度推理,靠谱出口!”
“让 LLM 会自己找资料,再也不用 Ctrl + C / Ctrl + V!”

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献715条内容
已为社区贡献715条内容

所有评论(0)