小白搭建大模型应用与智能体(1)——了解大模型私有化部署
本系列内容将对笔者学到的大模型私有化部署、应用与智能体做一个全方位的总结,旨在从较低的技术门槛层面,帮助需要搭建大模型应用的企业或者个人,了解大模型应用搭建的整个流程,并可以根据本篇文章的整体思路,拓展学习其中的其他知识。
小白搭建大模型应用与智能体(1)——了解大模型私有化部署
文章目录
前言
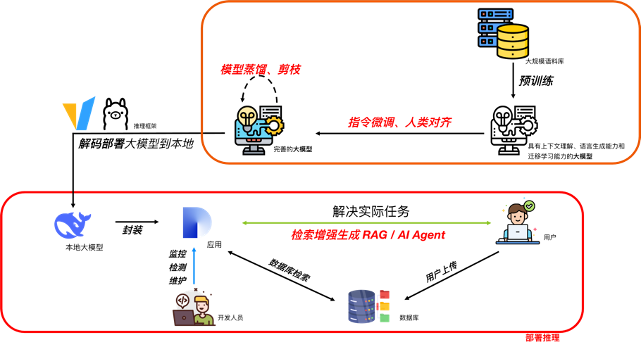
大模型私有化部署(Private Deployment of Large Models) 是指将大型人工智能模型(如 GPT、ChatGLM、LLaMA 等)部署在企业或组织的内部环境中,而非依赖于公共云服务。这种部署方式使企业能够更好地控制数据安全、模型性能和定制化需求。
本系列内容将对笔者学到的大模型部署、应用与智能体做一个全方位的总结,旨在从较低的技术门槛层面,帮助需要搭建大模型应用的企业或者个人,了解大模型应用搭建的整个流程,并可以根据本篇文章的整体思路,拓展学习其中的其他知识。
有一个容易混淆的点是,我们普遍熟知的大模型如GPT、DeepSeek、LLaMA等,其实是大模型的很小一个分支,即语言大模型(Large Language Model, LLM) 。根据数据模态分类,大模型还包含视觉大模型(Computer Vision Models, CV)、语音大模型(Automatic Speech Recognition Models, ASR)以及多模态大模型(Multimodel Models)。笔者之后在文章中提到的“大模型”均指代语言大模型。
一、为什么要进行大模型私有化部署?
近年来,随着ChatGPT、DeepSeek、豆包等多种大模型应用的爆火,企业与个人纷纷开始探索大模型的私有化部署与应用。
对于企业而言,通过在公有云或私有云环境中构建本地部署的大模型,既能够保障数据主权,又能充分挖掘内部知识库与业务数据的潜在价值。
对于个人而言,一款个性化服务的大模型应用可以完美适配个性化需求,对特定场景和任务都可以灵活制定具有个人需求导向的解决方案。
二、私有化部署的准备过程
0. 大模型训练流程
由于目前大模型训练趋于完善,一般部署时不考虑此部分技术实现,此处仅作为知识拓展与流程补充。具体大模型训练的实现方式可以参考站内其他文章。

a. 预训练
——利用大规模语料库以向量形式对大模型进行语义训练。
b. 模型微调
——使大模型的响应精度提高,回答更符合人类逻辑。
-
指令微调:利用自然语言对话数据集来微调大模型。相当于告诉大模型“我想让你这样回答”。
-
人类对齐:即基于人类反馈的强化学习方法(Reinforcement Learning from Human Feedback, RLHF)。这相当于告诉大模型“我想让你回答两个答案中更好的那一个”。RLHF一般是先利用人类反馈数据集训练一个奖励模型,然后再用奖励模型训练用作大模型微调的策略模型。
其中,人类反馈数据集通常包含针对同一个人类提问,两份不同的机器响应回答,再由人类标注这两种回答哪份偏好、哪份偏坏。奖励模型的训练目标是,评估人类更倾向于何种回答。策略模型的训练目标则是,使大模型根据最大回报执行策略进行微调。
c. 模型蒸馏、剪枝
——通过精简模型结构来减少参数量,使模型可以在尽量保持原有输出效果的情况下,可以被更高效的部署在低算力的设备上。
-
模型蒸馏:将简单模型用复杂模型的输出方式进行微调,使简单模型的回答更接近复杂模型。例如常见的 “DeepSeek-R1-Distill-Llama-8B” ,就是用 DeepSeek-R1 微调的 Llama-8B 模型。
-
模型剪枝:删除模型冗杂的组件或权重。这个一般不赞成,可能会影响到输出的精度。
1. 大模型部署准备
a. 硬件准备
- CPU:负责大模型预处理
- GPU:负责微调和大模型推理
- 内存:负责加载模型权重
- 存储:负责存储模型文件和数据集
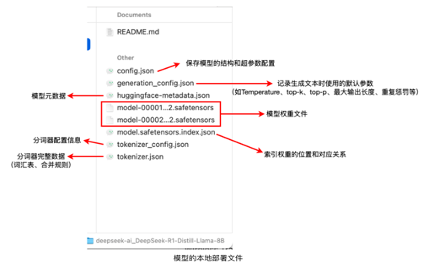
大模型部署前的硬件准备应该根据个人需求或企业需求自行选择。参考链接:各种本地大模型各种参数对应详情表
b. 环境搭建
- 操作系统:Windows、macOS、Linux
- 操作环境:Anaconda / Miniconda、Docker、Windows Subsystem for Linux (WSL2)
- 深度学习框架:Pytorch、TensorFlow、Keras、MindSpore、Caffe
- 高性能计算库:CUDA、CANN
c. 模型选择
模型下载一般可以通过HuggingFace、ModelScope、Github等官方链接下载。
- 本地部署:根据需求下载模型,一般推荐参数少的小模型例如1.5B、7B等。
- 云端部署:一般是企业级部署会用到,推荐大参数的模型例如32B、70B等。
- API 部署:使用大模型官方提供的API(如OpenAI API、Anthropic API)按量计费。
小Tips:国内现在个人如果想要部署大模型,Qwen2.5也是不错的选择。
d. 推理框架选择
这里要明确大模型部署和大模型推理的区别:推理是指在模型训练完成后,利用输入数据通过已训练的模型进行前向计算,生成预测结果的过程。部署则是指将训练好的模型集成到实际应用中,使其能够在生产环境中提供服务的过程。
- vLLM:可以处理大规模、高并发的模型推理,面向企业级部署居多。
- OLLAMA:个人/本地部署大模型的常见轻量级推理框架。
- XInference:灵活部署多种类别模型。
另外有一款功能强大的工具套件 OpenVINO ,主要用于将训练好的深度学习模型转换为适合在英特尔硬件上高效运行的格式,并提供推理加速,这个在后续文章中会有拓展(挖坑*1)。
2. 本地化部署流程
一个最简单的大模型本地部署流程如下:
硬件准备 --> 环境搭建 --> 模型获取(下载) --> 模型部署
这里放上 Ollama 本地部署大模型的参考链接,在此不过多赘述:本地部署大模型?看这篇就够了,Ollama 部署和实战。
完成本地部署后,就可以使用推理框架在终端进行大模型对话。在此基础上,为了扩展大模型的应用功能,我们可以通过不同的方式优化和集成大模型,以下是常见的四种应用形式:
a. API集成
将大模型封装为API,方便其他应用调用。这种方式适用于需要将大模型的推理能力嵌入到现有系统中的场景,例如智能客服、自动翻译等。
b. 检索增强生成(RAG)
结合外部知识库与大模型进行增强,提升生成的准确性和相关性。这种方式适用于需要结合实时数据或特定领域知识进行推理的应用,例如智能问答、文档生成等。
c. 智能体(Agent)
通过大模型构建智能代理,执行特定任务或与用户进行互动。智能体可以应用于如金融助手、智能客服等领域,实现个性化的服务。
d. 平台化应用
将大模型整合到一个平台中,提供统一的服务接口。此方式适用于构建多功能的AI平台,支持不同模型或模块的调用与管理,方便用户进行集成和操作。
总结
本文介绍了大模型私有化部署的主要流程,主要是进行一个入门知识的概述。在后续章节中,我们会分别讲解大模型应用的具体实现流程。
欢迎大家讨论与补充。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)