实验室6篇论文被AAAI 2026录用
在不用预训练robotic数据Pre-train的情况下,目前以0.5B的量级超过了7B量级OpenVLA-OFT的性能,并且Throughput在相同配置下是OFT的三倍,从模型端真正达到200Hz的推理,且支持任意单张24G的消费级显卡进行训练,希望这篇工作能降低大家的VLA入门门槛,真正让大家都用得起VLA!为了减轻信息丢失,该框架同时引入了一种基于关联的信息回收机制,允许保留的令牌通过自保
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料及应用!发论文/搞科研/涨薪,强烈推荐!

来源:西湖大学机器智能实验室
AAAI Conference on Artificial Intelligence(AAAI)是人工智能领域的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类会议。AAAI2026将于2026年1月20日-27日在新加坡举办。今年共有23680篇论文投稿,最终4167篇论文接收,录用率17.6%。机器智能实验室(MiLAB)共有6篇论文被AAAI2026录用,其中3篇Oral,3篇Poster,录用论文简要介绍如下:
1
重新思考对抗攻击中的目标标签条件:一种二维张量引导的生成方法
Rethinking Target Label Conditioning in Adversarial Attacks: A 2D Tensor-Guided Generative Approach(Oral)
第一作者:
刘航宇,王东林实验室博士生(2025级)
Hangyu Liu, Bo Peng, Pengxiang Ding, Donglin Wang
科
普
一
下
核心问题: 现有的目标对抗攻击方法将目标类别编码为一维向量,导致生成的对抗噪声丢失了目标的结构和细节,进而造成攻击在未知模型(黑盒)上的可迁移性很差。
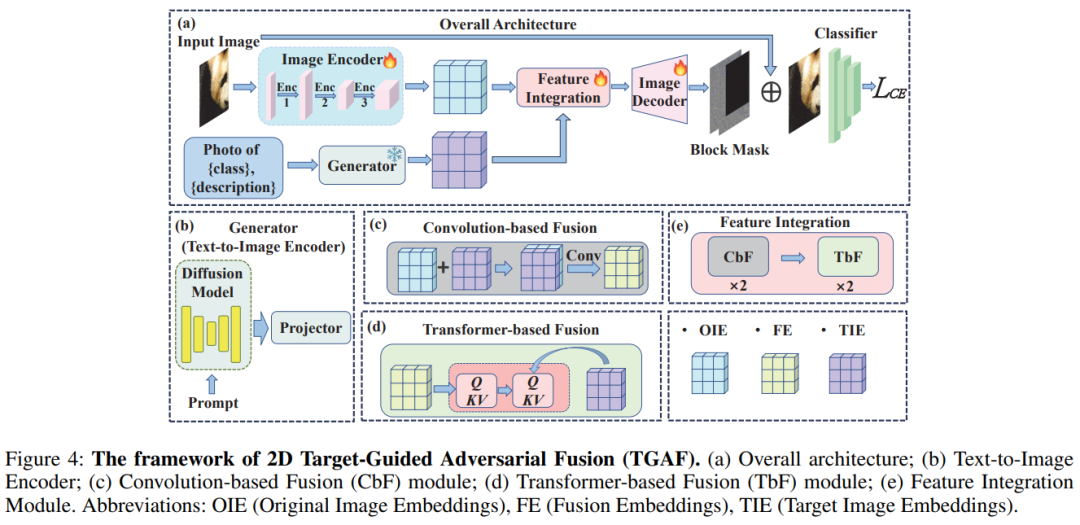
TGAF 的创新点:提升特征质量: 引入扩散模型,将目标标签编码成二维语义张量。这个 2D 表示能保留目标的空间和结构信息,从而生成更高质量的特征植入到图像中。提升特征数量:设计了一种随机块级掩码策略 ,强制生成器在更大空间范围植入目标特征,保证特征的空间充分性。
结果: TGAF 显著提高了目标攻击的成功率,超越了所有现有的最先进方法 ,并且在对抗多种防御机制时表现出强大的鲁棒性。
技
术
介
绍
本论文提出了一种新颖的 2D Tensor-Guided Adversarial Fusion (TGAF) 框架,旨在解决现有生成式多目标对抗攻击方法中,将目标标签编码成一维张量所导致的细粒度视觉信息丢失和对替代模型特定特征的过拟合问题 。本文首先确定了影响攻击可迁移性的两个关键因素:特征质量(植入目标特征的结构和细节完整性)和 特征数量(植入目标特征的空间充分性)。TGAF 框架利用扩散模型强大的生成能力,将目标标签编码为二维语义张量,从而指导生成更高质量的目标语义信息。
此外,TGAF 引入了动态块级掩码策略,在训练过程中确保生成的部分噪声保留完整的目标语义特征,以增强特征的数量。通过融合图像编码器提取的特征和 2D 目标张量,图像解码器最终生成具有高度可迁移性的对抗扰动。广泛的实验证明,TGAF 在针对正常训练模型和鲁棒模型的黑盒攻击成功率上,均显著超越了现有的先进方法。
论文地址:
https://arxiv.org/abs/2504.14137v2
2
ReconVLA:重构视觉-语言-动作模型作为有效的机器人感知器
ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver(Oral)
第一作者:
宋文轩,王东林实验室访问学生
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, Haoang Li
科
普
一
下
在读了大量的low-level perception (如bbox, trace) 作为辅助任务引导动作生成的VLA paper之后,我们开始思考这么几个问题:
VLA模型真的充分利用low-level perception了吗?在输出action之前推理bbox能否有效引导模型有选择的分配注意力、并抓取对应的物体?
技
术
介
绍
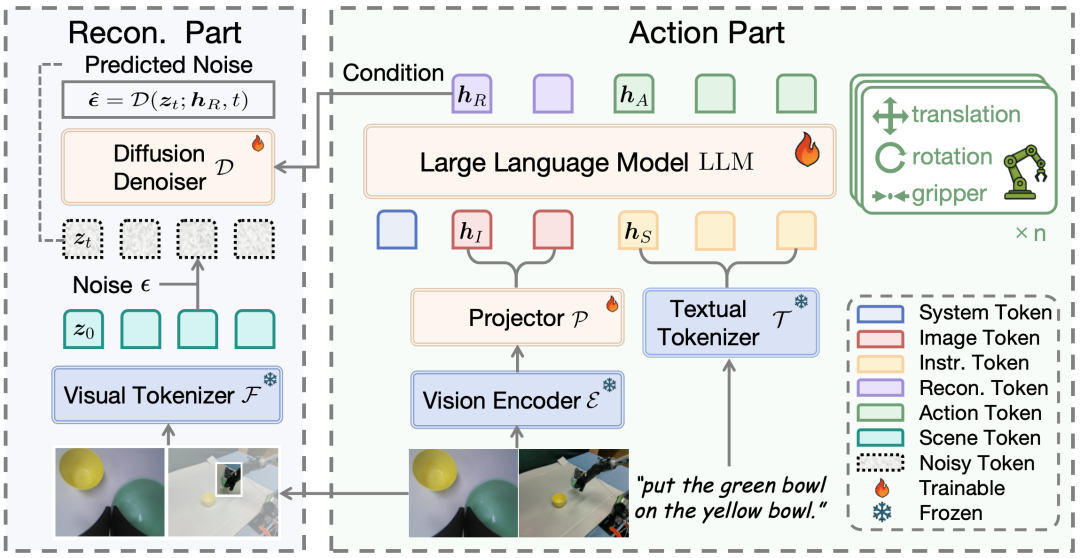
答案是No,在进行可视化后我们发现,现有的几种使用bbox辅助模型进行定位抓取的方案在vla任务上既无法有效聚焦视觉注意力,也对性能提升帮助较小。受到人眼凝视行为的启发,我们直接将vla输出的image token作为条件引导图片中关键区域的重建。这个行为强迫模型去仔细观察目标区域并进行细粒度的理解,因此成功在输出action时提高对目标区域的视觉token的注意力,从而实现了精准的操作。
与预测未来帧 (类world model) 作为辅助任务的vla不同,我们的目标是增强模型对于当前场景的感知,因此重建目标是当前帧中的关键区域,这降低了训练难度和成本,并允许我们的方法与预测未来帧同时进行,以同时增强感知能力以及未来的规划能力。
核心贡献:
1、我们提出了reconvla,通过重建的方式引导了隐式的visual grounding学习,引导vla模型精准分配视觉注意力。
2、我们通过大规模机器人数据集预训练的方式提升了vla模型的视觉泛化性以及grounding能力和图像重建能力。
3、得益于上述范式,我们仅依赖朴素的模型结构在calvin abc-d上实现了接近95%的首任务成功率,并成功在现实世界中实现对unseen物体的泛化。
论文地址:
https://arxiv.org/abs/2508.10333
3
VLA适配器:一种有效的微型视觉-语言-动作模型范式
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model(Oral)
第一作者:
王艺皓,王东林实验室实习生(2022级);丁鹏翔,王东林实验室博士生(2023级)
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, Siteng Huang, Yifan Tang, Wenhui Wang, Ru Zhang, Jianyi Liu, Donglin Wang
科
普
一
下
VLM的迭代速度是远超VLA基座模型的,那PaliGemma要是更新了权重,是不是π0也得重新经历大量robotic数据的重新预训练才能让大家使用呢?那我们能不能在不动VLM的前提下,搞出一个较好的VLA模型呢?
技
术
介
绍
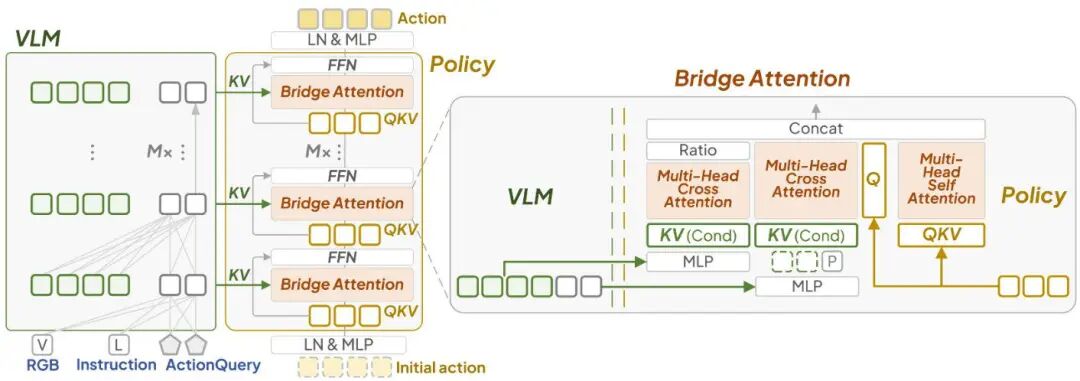
我们提出的VLA-Adapter在不用预训练robotic数据Pre-train的情况下,目前以0.5B的量级超过了7B量级OpenVLA-OFT的性能,并且Throughput在相同配置下是OFT的三倍,从模型端真正达到200Hz的推理,且支持任意单张24G的消费级显卡进行训练,希望这篇工作能降低大家的VLA入门门槛,真正让大家都用得起VLA!基于前面科普问题的驱动下,我们在OFT的范式下做了很多的实验探究,发现如果仅仅按照OFT的做法,没有经过robotic预训练的VLM确实会比预训练的要差一大截,但是这是否意味着我们的想法不可能呢?不!后续我们发现,这只是VL—A的mapping方式不合理造成的。我们系统分析了现有VLA中所有的mapping方式,发现:大家VLM本身的features和现在大家常用的latent features本质上表征是不一样的,前者依旧保留了大量的场景信息,即使是第一层特征也能有不错的性能;后者则完全是任务相关的特征,因而越到后面的层效果越好。考虑到这种现象,我们参考了LLaMA-Adapter的设计思路,在生成动作的Policy网络的Attention层面上加入一个可学习的权重,让Policy网络在训练过程中能够自适应得选择从VLM得到的不同conditions,即不同种类features,从而用一个很简单的方法就实现了性能的质变!
论文地址:
https://arxiv.org/abs/2509.09372
4
跨层膜电势更新:构建单时间步高效脉冲神经网络
Activation-wise Propagation: A One-Timestep Strategy for Spiking Neural Networks(Poster)
第一作者:
宋键,王东林实验室科研助理
Jian Song, Xiangfei Yang, Shangke Lyu, Donglin Wang
科
普
一
下
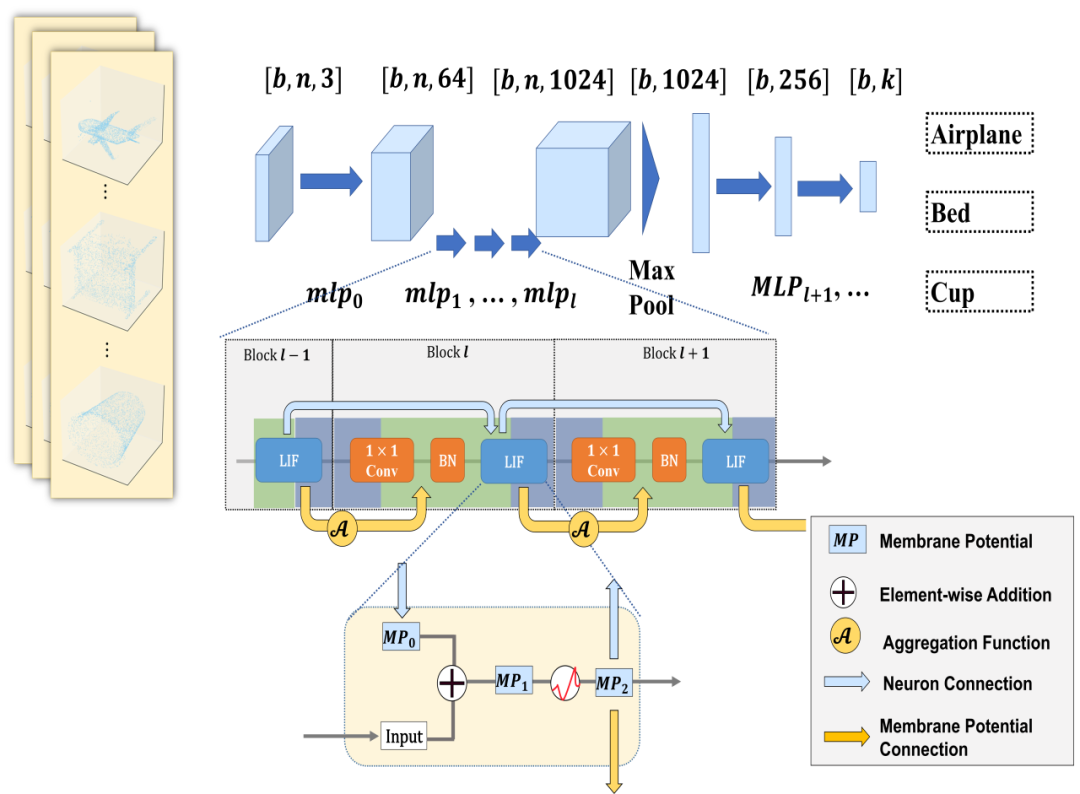
脉冲神经网络(Spiking Neural Networks, SNNs)的主流范式普遍依赖时间步迭代(timestep-wise iterative update):每层神经元必须在特定数量的时间步内反复更新中间状态——膜电势(Membrane Potential, MP),并在每步根据MP是否达到阈值来发放脉冲,实现时序编码。这种顺序依赖导致两方面问题:1. 计算效率更低:MP的逐时刻累积与衰减强制网络执行长时间步的串行计算,使 SNN 在训练与推理上远慢于传统神经网络。这种时序计算也带来了不可避免地性能-效率权衡:提高精度往往需要更长的时间步(如4、8甚至16),但这将显著增加计算成本,制约其在资源受限场景下的部署。2. 结构性限制:MP 必须按照时间顺序更新,使得 SNN 难以利用现代硬件在层级维度上的并行优势,与深度神经网络的大规模并行计算能力存在显著差距。
技
术
介
绍
我们提出 Activation-wise Membrane Potential Propagation(AMP2),这是一种跨层神经元膜电势更新机制,可以在不使用时间步迭代的前提下完成 MP 的累积与传播,从而实现 SNN 的单时间步高效计算。AMP2 的核心思想是: 将膜电势的累积从每个神经元的时序维度转移到层级维度,使 MP 能够在相邻层之间并行传播,而非依赖单层神经元逐个时间步的迭代计算。具体而言,AMP2 包含以下两个关键设计: 1. Activation-Wise Propagation (AWP), 传统 SNN 的每一层都在时间轴上更新 MP,而 AMP2 允许 MP 在相邻层间直接传播,上一层输出的残余膜电势将作为下一层的初始状态;Residual MP Learning (RMP), 为缓解深层网络中的脉冲衰减问题,我们进一步构建 MP 与特征之间的残差通路,使 MP 更新具备类似 ANN 残差结构的稳定性。实验显示AMP2在多个3D点云、2D事件流数据的识别数据集上达到甚至超过基于多时间步更新的SNN模型。并在Spiking PointNet、Spiking RestNet等多种SNN架构中带来稳定的性能提升。
论文地址:
https://arxiv.org/abs/2502.12791
5
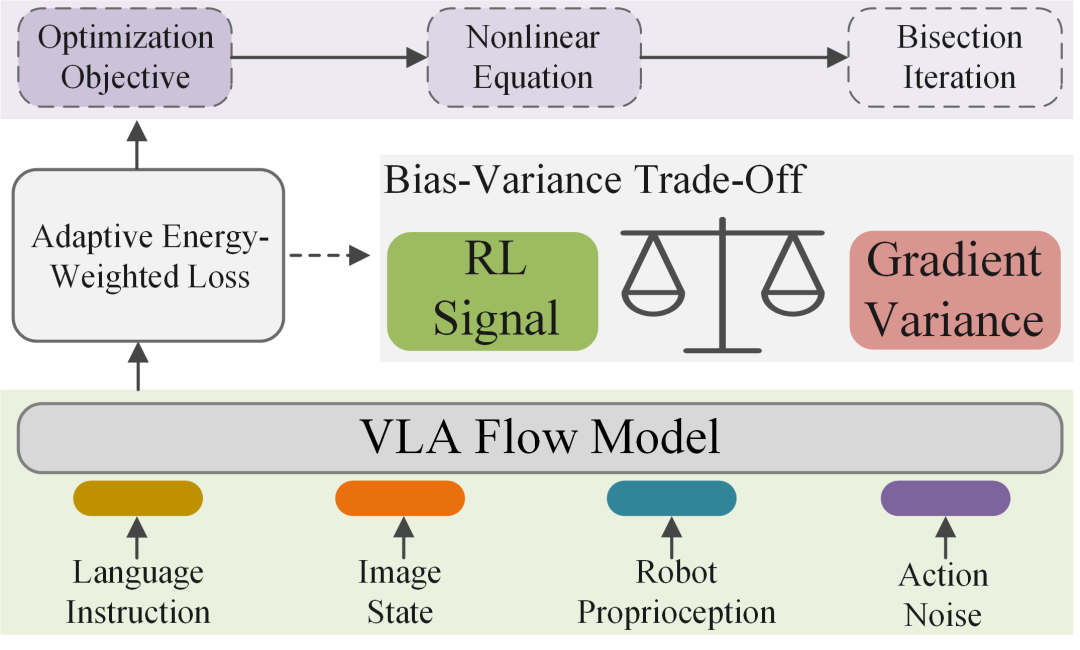
ARFM: 平衡数据质量与损失方差--VLA流模型的自适应离线强化学习后训练方法
Balancing Signal and Variance: Adaptive Offline RL Post-Training for VLA Flow Models(Poster)
第一作者:
张洪银,王东林实验室博士生(2022级)
Hongyin Zhang, Shiyuan Zhang, Junxi Jin, Qixin Zeng, Yifan Qiao, Hongchao Lu, Donglin Wang
科
普
一
下
想象一位“机器人管家”:你递给它一张便签“把打翻的牛奶擦干净,再顺便把杯子放回橱柜”,它就能看懂文字、识别场景、规划动作并一气呵成地完成。这背后正是“视觉-语言-动作”(Vision-Language-Action,VLA)大模型——它把“眼睛”(摄像头)、“大脑”(视觉-语言理解)和“双手”(机械臂控制)装进同一个神经网络。
近两年,研究者发现用“流匹配”(flow matching)方法训练 VLA 模型特别高效:只要给大量“人类演示视频—语言指令—机械臂轨迹”三元组,模型就能学会“像人一样”流畅地搬、抓、拧、插。然而,当任务稍复杂(例如细扣螺丝、叠高脚杯),机器人就会“手抖”或“理解不到位”。症结在于:纯模仿学习只能“照抄”演示,无法判断哪些演示质量高、哪些动作有风险,更谈不上在错误中自我改进。
强化学习(RL)恰好擅长“深入理解数据的质量”,但传统 RL 需要在线交互,真实机器人“摔打”成本高。能不能把 RL 的“数据质量分布的识别能力”安全地搬进 VLA 模型,又不让它把好不容易学会的流畅动作“带歪”?这篇论文给出了肯定答案。
技
术
介
绍
基于流匹配的视觉-语言-动作(VLA)模型在通用机器人操作任务中表现出色。然而,这些模型在复杂的下游任务中的动作精度却不尽如人意。一个重要原因是这些模型仅依赖于训练后的模仿学习范式,这使得它们难以深入理解数据质量的分布特性,而这恰恰是强化学习(RL)的优势所在。本文从理论上提出了一种适用于VLA流模型的离线RL训练后目标函数,并提出了一种高效可行的离线RL微调算法——自适应强化流匹配(ARFM)。通过在VLA流模型损失函数中引入自适应调整的缩放因子,我们构建了一个合理的偏差-方差权衡目标函数,以最优地控制RL信号对流损失的影响。ARFM自适应地平衡了RL优势的保持和流损失梯度方差的控制,从而实现了更加稳定高效的微调过程。大量的仿真和现实世界的实验结果表明,ARFM 具有优异的泛化能力、鲁棒性、少样本学习能力和连续学习性能。
论文地址:
https://arxiv.org/abs/2509.04063
6
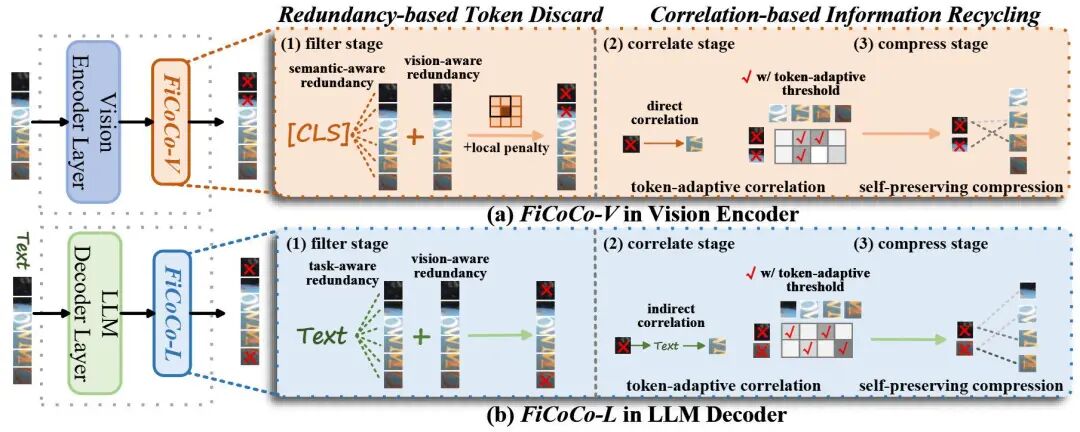
过滤,关联,压缩:一种用于 MLLM 加速的免训练Token缩减算法
Filter, Correlate, Compress: Training-Free Token Reduction for MLLM Acceleration(Poster)
第一作者:
韩宇航,王东林实验室科研助理
Y. Han, X. Liu, Z. Zhang, P. Ding, J. Chen, H. Chen, D. Wang, Q. Yan, S. Huang
科
普
一
下
大型多模态模型(MLLM)的“卡顿”挑战
想象一下,你正在使用一个能看图、能理解你指令的超级AI(大型多模态模型,简称 MLLM)。你给它看一张高清照片,并问它一个问题。
问题来了:这张高清照片在AI内部会被切分成数千个“视觉碎片”——我们称之为Token。AI需要同时处理这些视觉碎片和你的文字指令。由于计算量是随着碎片数量平方级增长的,碎片越多,AI运行得就越慢,就像电脑卡顿一样 。在AI给出回答之前,等待它处理完所有输入(这个过程叫预填充)可能会占据它80%的时间,成为效率瓶颈 。
什么是“筛选-关联-压缩”(FiCoCo)框架?
我们提出了一种全新的、无需重新训练的加速框架,叫做 Filter-Correlate-Compress (FiCoCo)。它的核心思想是像一个高效率的秘书,在AI开始工作前,快速整理并压缩输入的视觉数据,从而大幅减少AI的工作量 。
整个过程分为三步:
1. 筛选 (Filter): 识别冗余。一张图片中,比如大片的蓝天或绿草,很多视觉碎片的信息是重复的。FiCoCo 通过一种集成的标准(比如同时考虑图像本身的重复性和全局语义)来精准地筛选出那些“不重要”或“多余”的视觉碎片,并将它们丢弃 。
2. 关联 (Correlate): 回收信息。即使被丢弃的碎片,也可能包含微弱但有用的信息。FiCoCo 引入了“关联机制”,允许被保留的碎片去有选择性地“吸收”或“回收”那些被丢弃碎片的残余信息 。这种吸收是动态的,并且是根据碎片之间的相关性来决定的 。
3. 压缩 (Compress): 保护核心。在吸收残余信息时,必须防止“噪音稀释”——即防止被保留的碎片被过多冗余信息稀释,从而失去其核心内容 。因此,我们设计了一种“自保留压缩”算法,确保每个被保留的碎片至少保留50%的原始信息,同时只接收与之高度相关的被丢弃信息 。
FiCoCo 的两种“模式”
为了适应不同的需求,FiCoCo 有两种模式:
• FiCoCo-V(视觉模式): 专注于图像本身的冗余,在视觉编码器中运行,独立于具体的任务指令 。
• FiCoCo-L(任务模式): 直接在 LLM 解码器中运行,能利用你的文字指令(任务先验)来判断哪些视觉碎片是任务“最需要”的,从而更精确地保留关键信息 。
FiCoCo 的优势
FiCoCo 的最大优势在于:
• 极高的效率: 它可以将计算量(FLOPs)减少高达 14.7 倍 。
• 性能损失极小: 在大幅提速的同时,它能保留高达 93.6% 的原始模型性能 。
• 即插即用: 它是“免训练”的,可以直接应用于各种现有的 MLLM 模型(如 LLaVA-NeXT, Video-LLaVA 等),无需耗费巨大的资源进行重新训练 。
技
术
介
绍
多模态大语言模型(MLLMs)的二次复杂度与其上下文长度相关,带来了巨大的计算和内存挑战,阻碍了其在现实世界中的部署。我们设计了一个“过滤-关联-压缩”框架,通过在预填充(prefilling)阶段系统地优化多模态上下文长度来加速 MLLM。该框架提出一种基于冗余的令牌丢弃机制,使用一种新颖的集成度量来准确过滤掉冗余的视觉令牌;为了减轻信息丢失,该框架同时引入了一种基于关联的信息回收机制,允许保留的令牌通过自保留压缩选择性地回收来自相关联的被丢弃令牌的信息,从而防止稀释其自身的核心内容;该框架的 FiCoCo-L 变体进一步利用任务感知的文本先验知识,直接在 LLM 解码器内执行令牌缩减。广泛的实验证明,FiCoCo 系列能有效地加速多种 MLLMs,优于最先进的免训练方法,并展示了其在模型架构、规模和任务方面的有效性和通用性。
论文地址:
https://arxiv.org/abs/2501.05179
MiLAB
西湖大学机器智能实验室(Machine Intelligence Laboratory, MiLAB)专注于机器人具身智能和强化学习领域研究,旨在赋予机器人像人一样的行为能力,实验室PI王东林博士担任国家科技创新2030重大项目负责人(首席科学家)。实验室主要研究方向为机器人具身智能和强化学习,构建了机器人强化具身智能方法体系,研发了足式机器人产品。发表NeurIPS、ICML、ICLR、RSS、Nature子刊等人工智能和机器人顶会顶刊论文200余篇。
实验室主页:
https://milab.westlake.edu.cn
本文系学术转载,如有侵权,请联系CVer小助手删文
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ICCV 2025 论文和代码下载
在CVer公众号后台回复:ICCV2025,即可下载ICCV 2025论文和代码开源的论文合CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)