忘掉重启?不存在!LangGraph 与 PostgreSQL 联手给 AI 装上永生记忆
1.3 Conditional Edge —— 让流程「带脑子」• 作用:根据 State 中的某个字段值,在运行时动态选择下一步节点,实现非线性、递归甚至循环逻辑。• 典型写法:```pythonelse:```LangGraph 会把 routing_fn 的返回值(节点名)作为下一步要调度的节点。• 收益:– 减少硬编码 if/else,逻辑集中在一处。– 同一套图可服务多种业务场景(客服、
开场:当 AI 患上“断片症”——为什么你的 Agent 需要一颗“永生记忆”
今天的 LLM 像一位才华横溢却宿醉未醒的天才:每次对话都从零开始,昨天的洞察、上周的教训,一关机就蒸发。
• 招聘助手刚帮你筛完 50 份简历,重启后却问你“想找什么岗位?”
• 智能客服承诺跟进投诉,第二天却满脸陌生:“请问您反馈过什么问题?”
这种“金鱼级”记忆不仅让用户体验崩溃,也锁死了 Agent 向高阶任务演进的脖子。
破局之道:给 Agent 外挂一颗 **不会掉电的大脑**——长期记忆系统。
它要求:
1. 跨会话持久化:今天聊的,明年还能续上。
2. 结构化检索:秒级捞出“三年前某项目的技术债列表”。
3. 可反思升级:Agent 能从自己写过的代码、踩过的坑中自我进化。
本篇文章就是一份 “记忆永续”<现场破解>:
• 主刀框架:LangGraph——把 LLM、工具链、状态机编织成可演化的工作流;
• 记忆仓:PostgreSQL——ACID、向量、JSONB、全文检索一把抓;
• 现场 Demo:20 行代码即可让 Agent 记住用户偏好、对话历史、任务上下文,并支持“时间旅行式”回滚。
我们将拆解存储 schema、向量索引、会话窗口、自我反思四条主线,并给出可直接复制的开源模板。读完即可让你的 Agent 从“七秒记忆”进化为“终身学霸”。
1:LangGraph 图架构与检查点深度解析
在真正动手编码之前,让我们先把 LangGraph 的「五脏六腑」拆成 4 个核心概念,逐层剖开,看看它们如何协作,最终让 Agent 拥有“记忆”与“思考”的能力。
1.1 Agent State —— Agent 的「瞬时意识」
• 本质:一个普通的 Python dict 或 TypedDict,但语义上它是 Agent 在 t 时刻的完整快照。
• 里面装什么:
– messages:List[BaseMessage] – 对话历史,包括用户输入、LLM 回复、工具回包。
– current_task:str – 当前正在执行的任务描述,方便后续节点判断“我该干什么”。
– tool_outputs:Dict[str, Any] – 工具调用后的结构化结果,供下游节点校验或再次加工。
– user_profile:Dict[str, Any] – 长期记忆片段,例如用户偏好、已学会的知识。
• 运行时行为:
– 每次节点函数被调用时,都会拿到一份 State 的只读副本。
– 节点函数返回一个「补丁」dict,只写需要变更的字段;LangGraph 会自动合并回全局 State。
– State 的 schema 可以随时扩展,无需重启服务,只要节点逻辑兼容即可。
1. 2 Graph —— Agent 的「流程骨架」
• 建模方式:有向图(Directed Graph)。
– 节点(Node):一个 Python callable,签名统一为
```python
def my_node(state: State) -> State | dict:
```
常见节点:
• llm_node:调用大模型生成回复或下一步计划。
• tool_node:执行外部工具(搜索、计算、API 调用)。
• memory_node:把本轮关键信息写入长期存储。
– 边(Edge):定义节点之间的流转关系。
• 普通边:固定从 A → B。
• 条件边:见下一节。
1.3 Conditional Edge —— 让流程「带脑子」
• 作用:根据 State 中的某个字段值,在运行时动态选择下一步节点,实现非线性、递归甚至循环逻辑。
• 典型写法:
```python
def routing_fn(state: State) -> str:
if state["current_task"] == "need_search":
return "search_tool"
elif state["retry_count"] > 3:
return "fallback"
else:
return "continue_llm"
```
LangGraph 会把 routing_fn 的返回值(节点名)作为下一步要调度的节点。
• 收益:
– 减少硬编码 if/else,逻辑集中在一处。
– 同一套图可服务多种业务场景(客服、招聘、代码助手),只需换 routing 函数。
1.4 Checkpointer —— 长期记忆的「时光机」
• 职责:
– 在图执行过程中,按步骤把 State 序列化并写入持久化后端。
– 当进程重启或用户重新连接时,根据 session_id 把 State 完整拉回内存,实现「断点续跑」。
• 存储粒度:
– 每个节点运行完都会触发一次 checkpoint,因此可以回溯到任意中间步骤。
• 支持的 Backend(全部实现同一接口):
– SQLiteCheckpointer:本地文件,零依赖,适合原型。
– PostgresCheckpointer:ACID、JSONB、向量扩展,一条 SQL 就能做语义检索。
– RedisCheckpointer:亚毫秒级读写,适合高频会话缓存。
– 自定义:只要继承 BaseCheckpointer,实现 save(thread_id, step, state) 与 load(thread_id, step) 即可。
• 数据一致性:
– 默认使用可序列化隔离级别(PostgreSQL)或 Lua 脚本(Redis)保证并发安全。
– 支持「只读重放」模式:允许一个线程写入,多个线程并行读取历史快照做 A/B 回溯。
──────────────────
State 是「此刻的我」,Graph 是「我要怎么走」,Conditional Edge 是「看情况拐弯」,Checkpointer 是「把这一切都刻进硬盘」。
掌握这四件套,LangGraph 就从「流程框架」升级为「带记忆、能思考、可扩展的 Agent 操作系统」。
借助 Checkpointer 机制,LangGraph 将 Agent 的运行时状态与其持久化存储解耦,赋予开发者灵活选择多种后端(如 SQLite、PostgreSQL、Redis 等)的能力,从而实现对长期记忆的高效管理与定制化存储。
2:PostgreSQL:为 AI Agent 注入持久记忆的强力引擎
在众多持久化存储方案中,PostgreSQL 凭借其卓越的性能和功能,成为关系型数据库中的领先选择,也使其成为 AI Agent 长期记忆管理的理想后端:
2.1结构化强、一致性高 :
作为关系型数据库,PostgreSQL 天然适合处理结构化数据。Agent 的状态信息,如对话历史、用户画像、工具调用记录等,均可清晰映射到数据库表结构中,保障数据的一致性与完整性。
2.2高可靠性与数据持久性 :
PostgreSQL 支持完整的事务机制(ACID)、数据备份与恢复策略,能够在系统故障或崩溃时确保数据不丢失,满足关键业务场景下的高可用需求。
2.3灵活高效的查询能力 :
借助 SQL,开发者可以轻松实现对 Agent 行为日志、用户交互记录的复杂查询、统计与分析。结合扩展如 pgvector,还能直接在数据库中进行向量检索,赋能知识检索与语义记忆能力。
2.4良好的可扩展性 :
通过读写分离、分区表、逻辑复制以及集群解决方案(如 Citus),PostgreSQL 可以轻松应对大规模并发访问和数据增长,适应生产环境下的高性能需求。
2.5成熟生态与广泛支持 :
拥有活跃的社区、丰富的第三方工具以及成熟的运维体系,显著降低了开发与运维门槛,提升了系统的稳定性和可持续发展能力。
2.6与 LangGraph 原生集成 :
LangGraph 提供了内置的 PostgresSaver 组件,简化了 PostgreSQL 的接入流程,使开发者能够快速构建具备长期记忆能力的智能代理应用。
3:把 LangGraph 的脑电波焊进 Postgres
接下来,直接workshop!
我们将手撕一个 ReAct Agent,把它的大脑切片放进 PostgreSQL——让每一步推理、每一次工具调用、每一句对话都实时写库,真正做到“关机不丢魂,重启即满血”。
3.1 环境准备与依赖安装
首先,确保你的 Python 环境就绪,并安装必要的库:
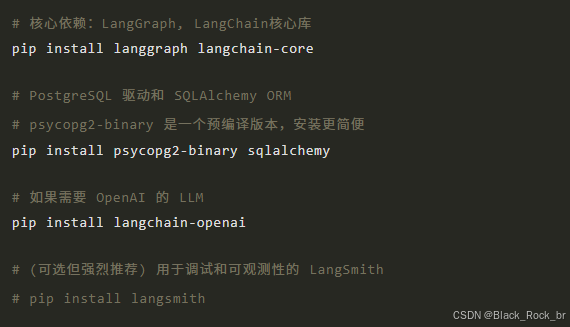
3.2 PostgreSQL 启动脚本设置
请确保你已部署并运行了一个 PostgreSQL 实例,并为 Agent 的记忆存储需求创建好专用的数据库和访问用户。
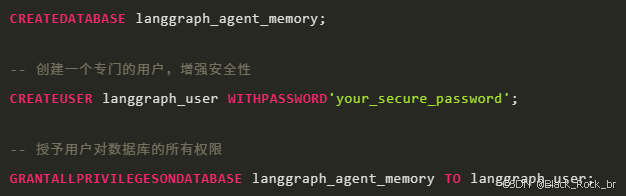
3.2.1 通过 psql 创建数据库和用户
连接到你的 PostgreSQL 服务器(例如,使用 psql -U postgres -h localhost 并输入密码),然后执行以下 SQL 命令
PostgreSQL 连接字符串 (URI)
根据你的设置,连接字符串通常遵循以下格式:postgresql+psycopg2://<user>:<password>@<host>:<port>/<database_name>
3. 3构建 LangGraph ReAct Agent
我们将构建一个经典的 ReAct Agent,它能够接收用户输入,决定是调用工具还是直接回答,并执行相应操作。
3.3.1 Agent 状态定义
Agent 的状态是其内部信息的载体,messages 是最核心的部分,用于存储对话历史。
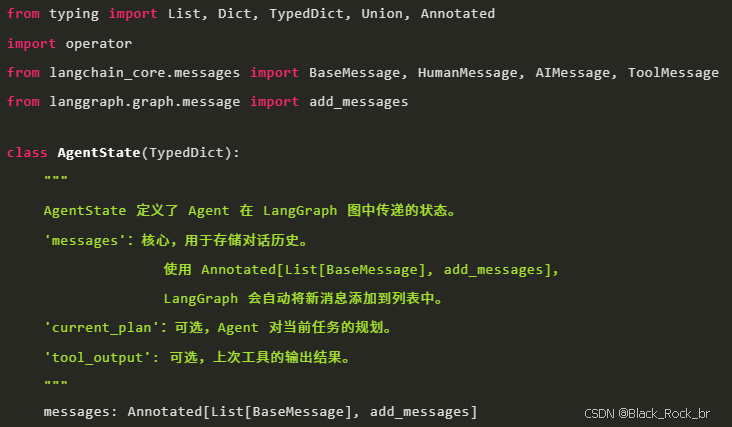
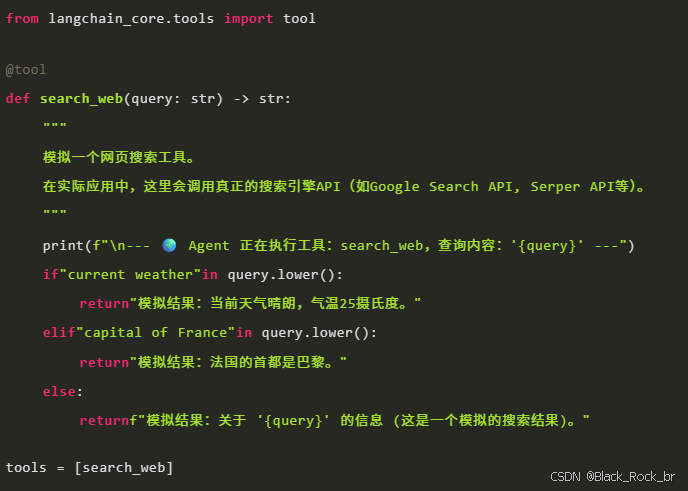
3.3.2 工具定义
Agent 通过调用工具来与外部世界交互,执行特定任务。这里我们定义一个简单的模拟网页搜索工具。
3.3.3LLM 配置
我们将使用 OpenAI 的模型,并绑定我们定义的工具。bind_tools 让 LLM 知道何时以及如何调用这些工具


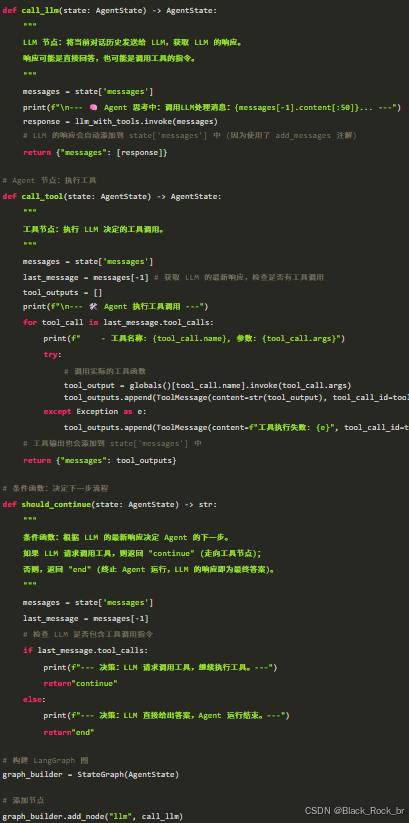
3.3.4 Agent 节点与决策逻辑
我们将 Agent 的核心逻辑拆分为两个节点 (call_llm 和 call_tool) 和一个条件函数 (should_continue)。
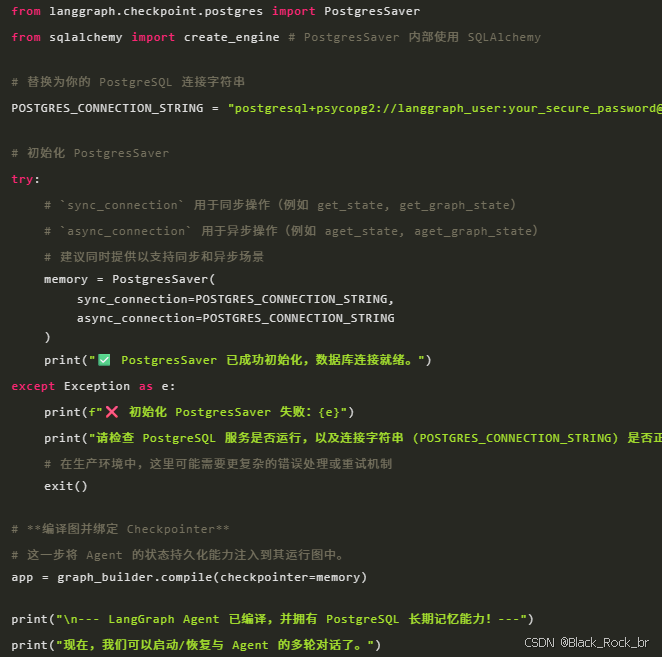
3.4. 整合 PostgreSQL Checkpointer
现在,我们将 PostgresSaver 引入到我们的 LangGraph 应用中。
3.5. 运行 Agent 并测试长期记忆
现在,我们可以像使用普通 LangGraph 应用一样运行我们的 Agent,但每次调用 invoke 时,通过 config 参数传入一个唯一的 thread_id。这个 thread_id 就是 LangGraph 在 PostgreSQL 中存储和检索特定对话历史的键
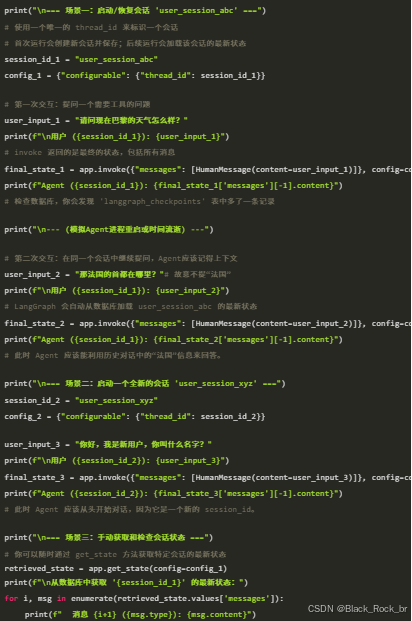
只要全亮,就说明你的 Agent 真正拥有了“过目不忘”的超能力:
1. 工具调用闪现
输入“巴黎天气”,终端瞬间弹出一条日志:
```
[search_web] → query='巴黎 天气'
```
这是 ReAct 循环在“动手”而非“张嘴”。
2. 上下文穿越
紧接着问:“那法国的首都在哪里?”
无需再提“法国”,Agent 直接回答“巴黎”。
因为 PostgreSQL 里那条 `thread_id` 的快照把上一轮对话的“法国=巴黎”牢牢记住。
3. 数据库彩蛋
连上 Postgres,执行:
```sql
SELECT thread_id, checkpoint_id, metadata->>'step' AS step, length(state) AS bytes
FROM langgraph_checkpoints
ORDER BY checkpoint_id DESC
LIMIT 5;
```
你会看到 5 行新鲜出炉的“记忆切片”——每一行都是 Agent 在思考过程中的一个瞬间,字节数即当时的“意识大小”。
4:拓展与进阶:实现真正的“学习”与“推理”
仅仅保存对话历史只是长期记忆的起点。要让 Agent 具备更强大的“智慧”,还需要结合以下高级技术:
4.1 结构化知识库(RAG 与 pgvector)
对于招聘类 Agent 来说,仅记住对话历史远远不够,它还需要掌握丰富的招聘专业知识,例如职位描述模板、行业薪酬标准、企业文化分析、常见面试问题等。
4.1.1实现方式:
将这些非结构化文本资料转化为向量嵌入(Vector Embeddings),并存储在具备向量检索能力的数据库中。PostgreSQL 配合 pgvector 扩展后,能够原生支持向量存储与相似性搜索,是构建 RAG(Retrieval-Augmented Generation,检索增强生成)系统的理想选择。
4.1.2Agent 协作流程:
4.1.1.1 知识检索 Agent:
接收用户输入的查询请求,将其转换为向量表示,并在 PostgreSQL + pgvector 中查找最相关的信息片段。
4.1.1.2推理生成 Agent:
接收来自知识检索 Agent 的匹配结果以及用户的原始查询内容,结合大语言模型(LLM)进行综合理解和推理,最终输出更加精准、专业且上下文贴合的回答。
这种分工协作机制不仅提升了 Agent 的知识利用效率,也显著增强了其在招聘场景下的智能化服务能力。
4.2 让 Agent 把长篇对话蒸馏成一句话,再写进反思日记(Summarization & Reflection)
随着对话持续进行,messages 列表会不断增长,导致输入 LLM 的 Token 数量上升,不仅增加计算成本,还可能超出模型的上下文长度限制。
4.2.1解决方案:
引入一个“摘要 Agent”节点。当对话轮数达到设定阈值(如 10 至 20 轮),或检测到话题发生明显转变时,自动触发该节点。它将调用 LLM 对前 N 轮对话内容进行总结,生成一段简洁的历史摘要。
4.2.2存储与使用方式:
将生成的摘要信息存入 PostgreSQL 的独立数据表中,并与对应的 `thread_id` 关联,作为该对话的“长期记忆摘要”。在每次新对话开始时,将该摘要作为系统提示(System Prompt)或附加上下文注入至 LLM 输入中,从而在不传递完整历史消息的前提下,仍能为模型提供足够的背景信息,实现高效、连贯的对话体验。
4.3 学习与适应性(Learned Behaviors)
把“长期记忆”再升一级——让 Agent 真正“长脑子”:
4.3.1 学习引擎
• 自动嗅探:每轮对话后,Agent 把高频词、格式偏好、任务套路提炼成 JSON 片段。
• 结构落库:不丢进通用 state,而是写入专属的 `user_profile`、`task_pattern` 表——字段精细到「简历模板=PDF+两栏+技能置顶」。
4.3.2 一键调用
下次同用户开口,Agent 先用向量索引召回最相关的 3 条“学习卡片”,再决定用哪套模板、哪种语气,甚至直接给出上次审到一半的简历批注。
4.3.3 场景示例
招聘经理 Alice 偏爱「技能-项目-教育」倒序排版;Agent 记住后,再推新简历时自动按此排序,并把上一轮她最关注的“Kubernetes 经验”高亮置顶——零提示,一步到位。
5:挑战与最佳实践
尽管 AI Agent 的长期记忆能力展现出巨大潜力,但在实际落地过程中仍面临多重挑战:
5.1主要挑战
5.1.1. 数据隐私与安全风险
长期存储用户对话、个人信息等敏感内容,必须严格遵循 GDPR、CCPA 等数据保护法规。同时需实施数据加密、细粒度访问控制、定期审计和脱敏策略,确保数据在整个生命周期内的安全性。
5.1.2. 偏见与公平性问题
如果训练或历史数据中存在偏见,Agent 可能会在决策中继承甚至放大这些偏差。因此,需要持续监控其行为输出,评估模型公平性,并引入去偏机制来保障公正性。
5.1.3. 成本控制难题
海量数据的存储与处理、频繁的 LLM 调用以及向量检索操作都会带来可观的成本开销。通过对话摘要减少上下文长度、优化向量数据库结构等方式可有效降低成本压力。
5.1.4. 架构复杂度上升
引入数据库、RAG 模块、摘要 Agent 等组件显著提升了系统架构的复杂性。这要求团队具备扎实的 DevOps 与 MLOps 能力,以支持高效部署、实时监控和稳定维护。
5.1.5. 可解释性与可控性不足
当 Agent 行为出现异常时,如何追溯其决策路径?如何理解它调用了哪些记忆?这就需要完善的日志体系、使用 LangSmith 等可观测性工具,并设计必要时的人工干预机制。
5.1.6. 记忆模式的设计难题
如何划分不同类型的记忆(如消息历史、摘要、结构化知识)并建立有效的关联关系?这不仅影响系统的性能与扩展性,也直接决定了 Agent 的智能表现。
5.2 推荐的最佳实践
5.2.1分层记忆架构
结合短期记忆(当前对话上下文)、中期记忆(会话摘要)和长期记忆(外部知识库、用户画像),实现资源的最优利用。
5.2.2模块化开发与部署
将记忆管理、工具调用、推理生成等功能解耦为独立模块,提升系统的可维护性、灵活性与可扩展性。
5.2.3强化可观测性建设
利用 LangSmith 等工具全面记录每次运行过程,监控 Token 使用、响应延迟、错误率等关键指标,并可视化 Agent 的思考路径。
5.2.4持续迭代与优化
AI Agent 不应是静态系统,而应基于真实用户的反馈和行为数据不断优化记忆策略、推理逻辑和整体表现,推动其逐步走向成熟。
构建具备长期记忆能力的 AI Agent 是一个系统工程,既需要技术上的深思熟虑,也需要对业务场景的深入理解。只有兼顾效率、成本、安全与用户体验,才能真正释放 AI 的长期价值。
6:结语:迈向真正具备智能的 AI Agent
借助 LangGraph 强大的流程编排能力,结合 PostgreSQL 在数据持久化方面的稳定与灵活性,我们成功为 AI Agent 构建了“永不遗忘”的长期记忆系统。这不仅有效解决了其在状态管理和上下文延续方面的核心挑战,更让 Agent 从一个单纯的“对话响应器”,进化为能够持续学习、积累经验并提供个性化服务的“智能协作者”。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)