【大模型基础】OCR技术全解析:从原理到实践的深度指南
OCR技术全解析:原理、应用与方案对比 OCR(光学字符识别)技术已成为连接物理与数字世界的核心工具,广泛应用于金融、政务、教育等领域。其核心流程包括图像预处理、文本检测、识别和后处理,技术发展经历了传统算法到深度学习的演进。OCR按场景可分为通用型、特定场景型和复杂场景型,按技术路线分为传统OCR、深度学习单阶段和端到端模型。主流架构采用DBNet检测和Transformer+CTC识别算法。应
OCR技术全解析:从原理到实践的深度指南
在数字化转型加速推进的今天,光学字符识别(OCR)技术作为连接物理世界文本与数字信息的核心桥梁,已广泛渗透到金融、教育、政务、物流等多个领域。从手机扫码识别、发票报销自动录入,到古籍数字化、智能客服信息提取,OCR技术正在不断降低信息录入门槛,提升行业效率。本文将全面拆解OCR技术,涵盖技术原理、种类对比、架构设计、应用场景、开源与收费方案,以及优劣势与解决方案,助力读者快速掌握OCR技术的核心逻辑与实践要点。
一、OCR技术详解介绍
OCR(Optical Character Recognition,光学字符识别)是指通过光学设备(如摄像头、扫描仪)获取图像中的文本信息,再通过计算机算法将其转化为可编辑、可检索的数字文本的技术。其核心目标是实现“图像文本→数字文本”的精准转化,本质上是计算机视觉(CV)与自然语言处理(NLP)的交叉应用。
1.1 OCR技术核心流程
一个完整的OCR系统通常包含4个核心环节,各环节环环相扣,直接影响最终识别效果:
-
图像预处理:作为OCR的基础环节,主要目的是提升图像质量,为后续识别降低难度。核心操作包括:图像去噪(去除高斯噪声、椒盐噪声)、图像增强(调整对比度、亮度)、倾斜校正(解决图像拍摄/扫描倾斜问题)、二值化(将彩色/灰度图转化为黑白二值图,突出文本区域)、版面分析(分割文本、图片、表格等不同区域,确定识别顺序)。
-
文本检测(Text Detection):从预处理后的图像中精准定位文本所在区域,相当于“找到哪里有字”。传统方法依赖纹理特征、边缘检测等,现代方法则以深度学习为主,能有效应对复杂背景、不规则文本(如弯曲文本)、多语言混合等场景。
-
文本识别(Text Recognition):对检测到的文本区域进行字符解析,相当于“认出是什么字”。这是OCR的核心环节,负责将图像中的字符转化为数字文本,需要解决字体差异、字符变形、遮挡等问题。
-
后处理:对识别结果进行优化修正,提升准确率。主要操作包括:语法纠错(如将“10086”误识别为“1008b”修正)、格式标准化(如统一日期、金额格式)、上下文语义修正(结合语境优化识别结果)。
1.2 OCR技术发展历程
OCR技术的发展可分为三个关键阶段,技术路线从传统算法逐步过渡到深度学习:
-
传统算法阶段(20世纪50年代-21世纪初):依赖手工设计特征,如模板匹配、轮廓提取、投影法等。优点是计算量小、部署简单;缺点是鲁棒性差,对字体、光照、背景变化适应性弱,仅适用于印刷体、简单背景场景。
-
深度学习初期(2010年-2016年):基于卷积神经网络(CNN)的特征提取替代手工特征,结合循环神经网络(RNN)处理序列文本,如CRNN(卷积循环神经网络)模型的提出,显著提升了印刷体和简单手写体的识别准确率。
-
深度学习成熟阶段(2016年至今):Transformer架构引入OCR领域,结合注意力机制,解决了长文本、复杂排版、不规则文本的识别难题;同时,端到端OCR模型(如DTRB、PP-OCR)实现了“文本检测+识别”的一体化,简化了模型训练与部署流程,识别精度和效率大幅提升。
二、OCR种类对比区别
根据不同的分类维度,OCR可分为多种类型,不同类型在技术路线、适用场景、性能表现上存在显著差异。以下从核心分类维度展开对比:
2.1 按识别场景分类
| 类型 | 核心特点 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 通用OCR | 支持多字体、多语言,适配常规文本场景,无特殊定制化优化 | 日常文档扫描、网页截图识别、手机拍照识字 | 适用范围广,部署成本低 | 复杂场景(如低光照、弯曲文本)识别准确率低 |
| 特定场景OCR | 针对特定场景进行算法优化,如票据、身份证、车牌、手写体等 | 发票报销、身份证核验、车牌识别、病历录入 | 场景适配性强,识别准确率高 | 适用范围窄,跨场景通用性差 |
| 复杂场景OCR | 支持低光照、模糊、倾斜、遮挡、弯曲文本等复杂环境 | 户外广告识别、古籍数字化、工业零件编号识别 | 鲁棒性强,适应恶劣环境 | 计算量较大,部署要求高 |
2.2 按技术路线分类
| 类型 | 核心技术 | 识别精度 | 部署成本 | 适用场景 |
|---|---|---|---|---|
| 传统OCR | 模板匹配、投影法、边缘检测、SVM分类器 | 较低(仅适用于标准印刷体) | 低(无需大量算力) | 简单印刷体文档、固定格式票据(如老式发票) |
| 深度学习OCR(单阶段) | CRNN、CTC解码、ResNet特征提取 | 中高(支持印刷体、简单手写体) | 中(需基础GPU算力) | 常规文档识别、手机拍照识字 |
| 深度学习OCR(端到端) | Transformer、注意力机制、DTRB、PP-OCR | 高(支持复杂排版、不规则文本) | 高(需高性能GPU/TPU) | 复杂文档、弯曲文本、多语言混合识别 |
2.3 按部署方式分类
| 类型 | 部署模式 | 网络依赖 | 数据安全性 | 适用场景 |
|---|---|---|---|---|
| 云端OCR | 模型部署在云端服务器,用户通过API调用 | 强依赖网络 | 较低(数据需上传云端) | 中小企业、个人用户、非敏感数据识别 |
| 本地OCR | 模型部署在本地设备(如电脑、手机、嵌入式设备) | 无网络依赖 | 高(数据不上传) | 政务、金融、医疗等敏感数据场景,离线设备 |
| 混合OCR | 常规识别在本地,复杂场景调用云端模型 | 弱依赖网络 | 中高(敏感数据本地处理) | 兼顾效率与安全性的企业场景(如大型企业财务报销) |
三、OCR架构设计图
以下是基于深度学习的端到端OCR系统架构设计图,涵盖从图像输入到结果输出的全流程,包含数据层、预处理层、核心模型层、后处理层及应用层,支持复杂场景下的高精度识别: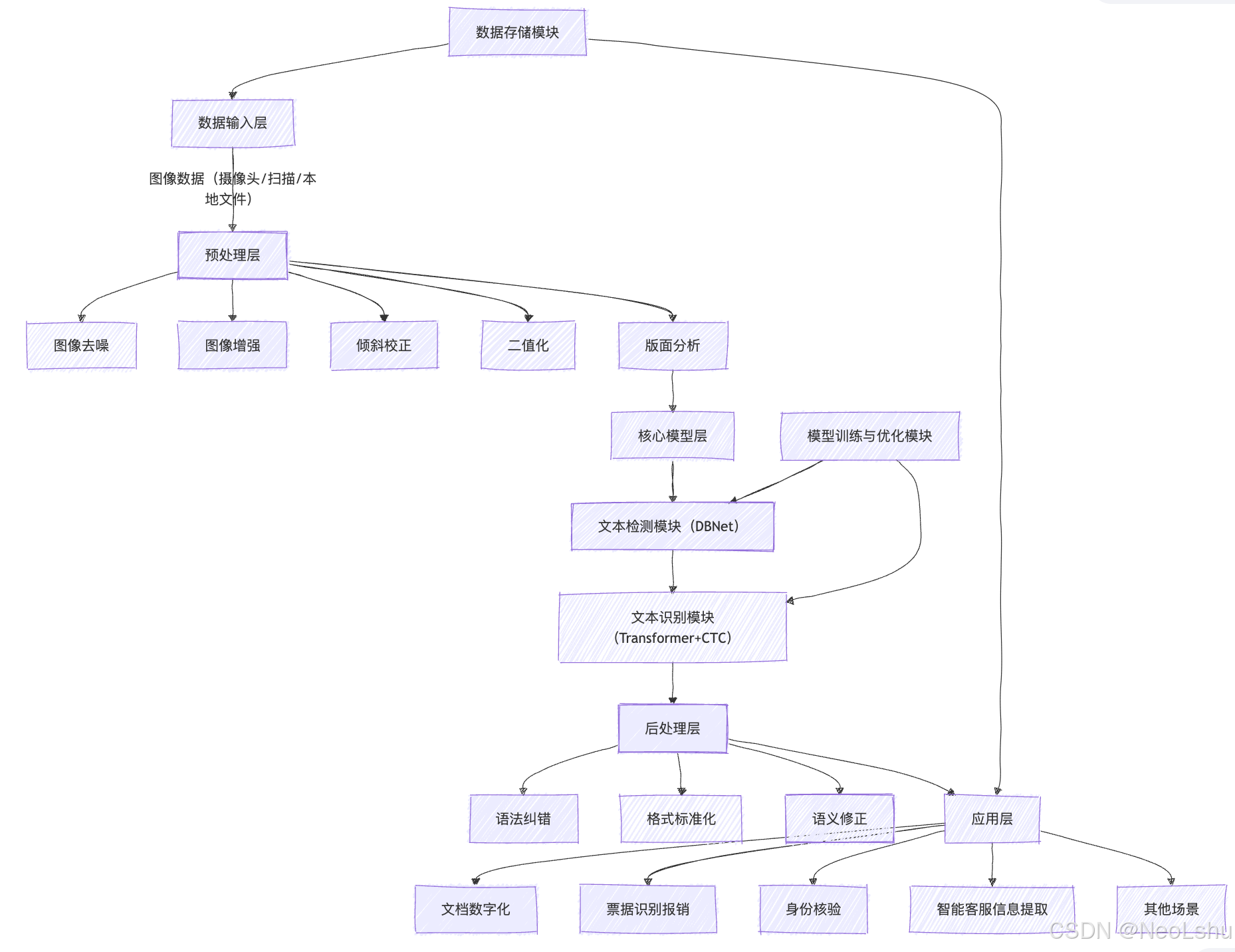
架构说明:
-
数据输入层:支持多种图像来源,适配不同设备的图像采集需求;
-
预处理层:通过多步骤图像优化,提升文本区域的辨识度,为核心模型降低难度;
-
核心模型层:采用主流的DBNet文本检测算法(精准定位文本区域)和Transformer+CTC融合的识别算法(提升复杂文本的识别准确率),实现端到端的文本检测与识别;
-
后处理层:通过语法、语义优化,修正识别误差,提升结果可靠性;
-
辅助模块:模型训练模块支持持续优化模型性能,数据存储模块实现图像与识别结果的留存与检索。
四、OCR的使用场景&开源、收费方案
4.1 核心使用场景
OCR技术的应用已覆盖多个行业,以下是典型场景及应用价值:
-
金融行业:发票识别自动报销(减少人工录入误差,提升报销效率)、身份证/银行卡核验(降低身份造假风险)、银行票据识别(实现票据数字化归档,提升检索效率);
-
政务行业:身份证/户口本识别(简化政务办理流程,实现“无纸化”办公)、营业执照识别(企业注册、变更流程优化)、古籍/档案数字化(保护文化遗产,提升档案检索效率);
-
教育行业:试卷识别批改(减轻教师批改负担)、教材/文献数字化(构建电子图书馆,方便学生检索学习)、手写作业识别(实现作业自动批改与学情分析);
-
物流行业:快递面单识别(自动提取收件人信息,提升分拣效率)、货运单据识别(实现物流信息数字化追踪);
-
日常生活:手机拍照识字(快速提取图像文本)、翻译软件实时识别(跨语言沟通辅助)、PDF文档转Word(实现可编辑文本转化)。
4.2 开源方案
开源OCR方案适合有技术研发能力的企业/个人,可基于开源框架进行二次开发,适配特定场景需求。以下是主流开源方案对比:
| 开源框架 | 核心优势 | 支持语言 | 适用场景 | 学习成本 |
|---|---|---|---|---|
| PP-OCR(百度飞桨) | 端到端模型,识别精度高,支持多语言,提供丰富的预训练模型和工具包 | 中文、英文、日文、韩文等 | 通用文档、票据、手写体识别 | 中(提供详细文档和教程) |
| Tesseract-OCR(Google) | 历史悠久,社区活跃,支持多平台,可自定义训练模板 | 多语言(支持100+语言) | 简单印刷体文档、常规文本识别 | 低(部署简单,文档丰富) |
| EasyOCR(Python) | API简洁易用,支持多语言,无需复杂配置,适合快速验证场景 | 中文、英文、泰文等 | 快速原型开发、简单图像识别 | 低(Python开发者友好) |
| CRNN-OCR | 基于CNN+RNN的经典架构,适合序列文本识别,可灵活定制特征提取模块 | 通用多语言 | 印刷体、简单手写体识别 | 中(需要深度学习基础) |
4.3 收费方案
收费方案适合无技术研发能力、追求快速落地的企业/个人,主流厂商提供API调用、 SaaS平台等服务,按调用量或套餐收费:
| 厂商 | 收费模式 | 核心服务 | 优势 | 适用客户 |
|---|---|---|---|---|
| 百度智能云OCR | 按调用量收费(0.01元/次起),提供免费额度(1000次/月),套餐优惠 | 通用OCR、票据OCR、身份证OCR、手写体OCR | 识别精度高,支持多场景,API稳定 | 中小企业、个人开发者 |
| 阿里云OCR | 按调用量收费(0.015元/次起),免费额度(500次/月),企业套餐定制 | 通用OCR、金融票据OCR、车牌识别、文档结构化识别 | 云端算力强,支持大规模并发,安全合规 | 中大型企业、金融机构 |
| 腾讯云OCR | 按调用量收费(0.01元/次起),免费额度(1000次/月),行业定制套餐 | 通用OCR、身份证/银行卡OCR、发票识别、营业执照识别 | 接入简单,支持微信生态集成,性价比高 | 中小企业、微信生态开发者 |
| 讯飞OCR | 按调用量收费(0.02元/次起),免费额度(500次/月),行业解决方案定制 | 手写体OCR、医疗票据OCR、古籍OCR、复杂场景OCR | 手写体识别精度高,行业定制能力强 | 医疗行业、教育行业、文化机构 |
五、OCR的优劣势和相关的解决方案
5.1 优势分析
-
提升效率:替代人工录入,将文本转化效率提升10倍以上,如发票报销从“人工录入10分钟/张”缩短至“OCR识别3秒/张”;
-
降低成本:减少人工成本投入,尤其适用于大规模文本处理场景(如档案数字化、物流面单处理);
-
提升准确率:深度学习OCR对标准文本的识别准确率可达99%以上,远超人工录入误差率(约0.5%);
-
数字化赋能:将物理世界的文本转化为数字信息,助力企业构建数字化资产,实现数据检索、分析与复用;
-
场景适配性广:支持印刷体、手写体、多语言、复杂背景等多种场景,覆盖全行业需求。
5.2 劣势分析
-
复杂场景识别能力有限:低光照、模糊、倾斜角度过大、文本遮挡、弯曲文本等场景下,识别准确率显著下降;
-
小语种/特殊字体支持不足:对小众语种(如梵文、冰岛语)、艺术字体、古文字的识别能力较弱;
-
部署与研发成本差异大:端到端深度学习OCR需高性能算力支持,本地部署成本高;开源方案需专业技术团队进行二次开发;
-
数据安全风险:云端OCR需上传图像数据,存在敏感信息(如身份证、病历)泄露风险;
-
对图像质量依赖高:原始图像质量差(如分辨率低、噪声多)时,即使经过预处理,识别效果仍难以保证。
5.3 针对性解决方案
-
复杂场景优化方案:采用多模态融合技术(结合图像特征与语义信息);引入超分辨率重建技术提升模糊图像质量;优化文本检测算法(如采用EAST、DBNet++等先进算法),提升不规则文本定位能力;
-
小语种/特殊字体解决方案:构建小语种/特殊字体数据集,进行模型微调;采用迁移学习技术,基于通用语言模型快速适配小众语种;开源社区共建多语言模型(如PP-OCR的多语言扩展包);
-
部署成本优化方案:中小企业优先选择云端API调用(按用量付费,无需前期算力投入);需本地部署的场景,采用模型轻量化技术(如量化、剪枝),降低对硬件的要求;选择开源轻量化框架(如EasyOCR、PP-OCR Tiny);
-
数据安全解决方案:敏感场景采用本地OCR部署(数据不上传云端);云端OCR选择支持数据加密传输与存储的厂商;签订数据安全协议,明确厂商数据使用权限;
-
图像质量提升方案:前端采集设备优化(如采用高清摄像头、自动对焦功能);预处理环节增强(如多轮去噪、自适应对比度调整);提供图像采集规范,指导用户拍摄高质量图像。
5.4 开源OCR框架代码使用示例
以下选取主流的PP-OCR(百度飞桨)和EasyOCR两个开源框架,提供简单易懂的Python调用示例,覆盖环境安装、图像读取、识别执行及结果输出全流程,帮助开发者快速上手实践。
5.4.1 PP-OCR调用示例
PP-OCR支持中英文、多语言识别,具备高精度和丰富的预训练模型,适合通用文档、票据等多种场景。
# 1. 安装依赖
# pip install paddlepaddle paddleocr
# 2. 导入相关库
from paddleocr import PaddleOCR, draw_ocr
# 3. 初始化OCR模型(use_angle_cls=True开启角度识别,lang='ch'指定中文)
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
# 4. 读取待识别图像(支持本地路径或URL)
img_path = "test_document.jpg" # 替换为你的图像路径
# 5. 执行OCR识别
result = ocr.ocr(img_path, cls=True)
# 6. 解析并输出识别结果
for line in result:
print("文本位置坐标:", line[0])
print("识别文本:", line[1][0])
print("置信度:", line[1][1])
print("-" * 50)
# 可选:可视化识别结果(将识别框和文本绘制到图像上)
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='simhei.ttf') # 需提前准备中文字体文件
im_show = Image.fromarray(im_show)
im_show.save('result.jpg') # 保存识别结果图像
5.4.2 EasyOCR调用示例
EasyOCR以API简洁、配置简单著称,无需复杂环境搭建,适合快速原型开发和简单图像识别场景。
# 1. 安装依赖
# pip install easyocr
# 2. 导入相关库
import easyocr
# 3. 初始化OCR阅读器(指定识别语言,支持多语言组合,如['ch_sim', 'en'])
reader = easyocr.Reader(['ch_sim', 'en']) # ch_sim=简体中文,en=英文
# 4. 读取待识别图像(支持本地路径或URL)
img_path = "test_image.jpg" # 替换为你的图像路径
# 5. 执行OCR识别(detail=0仅返回文本,detail=1返回详细信息含坐标和置信度)
result = reader.readtext(img_path, detail=1)
# 6. 解析并输出识别结果
for detection in result:
print("文本位置坐标:", detection[0])
print("识别文本:", detection[1])
print("置信度:", detection[2])
print("-" * 50)
# 可选:简单可视化(使用OpenCV绘制识别框)
import cv2
img = cv2.imread(img_path)
for detection in result:
top_left = tuple([int(i) for i in detection[0][0]])
bottom_right = tuple([int(i) for i in detection[0][2]])
img = cv2.rectangle(img, top_left, bottom_right, (0, 255, 0), 2) # 绿色框标记识别区域
img = cv2.putText(img, detection[1], top_left, cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 1) # 蓝色文本标注
cv2.imwrite('easyocr_result.jpg', img) # 保存识别结果图像
cv2.imshow('Result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
说明:上述代码示例均为基础调用方式,实际使用时需根据场景调整参数(如图像预处理、语言类型、置信度阈值等);对于复杂场景(如低光照、倾斜文本),建议先对图像进行去噪、校正等预处理操作,再执行识别以提升准确率。
六、总结与展望
OCR技术作为数字化转型的核心支撑技术之一,已从传统的印刷体识别发展为端到端的复杂场景识别,应用价值持续提升。其优势在于高效、低成本的文本数字化转化,劣势则集中在复杂场景适配、小语种支持、成本与安全等方面,通过技术优化与方案选型可有效缓解这些问题。
未来,OCR技术将朝着以下方向发展:一是与大语言模型(LLM)融合,提升语义理解与纠错能力;二是轻量化与端侧部署普及,降低应用门槛;三是多模态融合(结合语音、视频信息),实现更全面的信息提取;四是行业定制化深化,针对医疗、教育等特殊领域提供更精准的解决方案。随着技术的不断进步,OCR将进一步渗透到更多细分场景,为数字经济发展注入更强动力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)