LLMLingua-2:任务无关的prompt压缩
LLMLingua-2:任务无关的prompt压缩
LLMLingua-2:任务无关的prompt压缩
领域:prompt压缩
一句话概括问题:
任务无关的prompt压缩。训练encoder进行token级分类任务做到prompt压缩。
现有方法的缺点:
1.将信息熵作为压缩指标,这是次优的,因为:
(1)无法捕获所有关键信息
(2)信息熵与prompt压缩的目标不对齐
2.以前的方法要么不是任务无关的,要么没解决问题1
挑战:
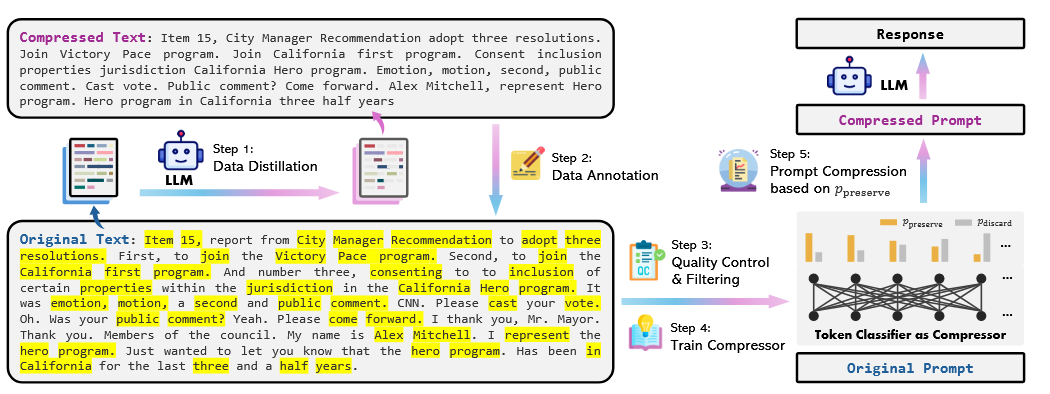
1.如何构建训练数据集(输入是prompt,标签是每个token是否保留)?(GPT4容易产生幻觉内容,还会修改输入文字的表达内容)
2.有了数据集,怎么自动标注?
(1)某一个单词可能出现多次,不知道保留的具体是哪个位置上的单词了
(2)GPT会改某些词的时态(这样就找不到原单词了)
(3)GPT有时会改顺序(给标签匹配造成了困难)
如下图所示

3.如何设计更有效的压缩算法?
流程:
构建数据集->标注数据集->训练一个模型来判断删除什么token
方法
1.构建数据集上:
(1)让GPT4只删除原来句子里不关键的词,不要加入新词,也不设置固定的压缩比例(因为GPT4根本不听),而是让它尽量删除没用的词。

(2)如果是很长的句子,GPT4性能会下降。所以将句子切分为多个小于512的块
2.构建数据集后,标注上:
(1)以压缩后的每个单词为外循环,在原句里找
(2)先往右找再往左找(解决GPT私自改单词顺序的问题)
(3)找到后,下次找就以这个点为起始点找(解决一个词对应多个词的问题)
(4)模糊匹配(解决单词时态改变问题)
具体算法如下图:

3.在刚刚得到的数据集上去除质量不好的数据样本:
定义了一些指标:VR,HR,MR,AG(AG=HR-MR)
VR衡量压缩文本中有多少词是原始文本中没有的,即出现了“新增内容”的比例。对于VR指标,删除top 5%的数据即可。
MR计算原文中有多少词在压缩文中有匹配,HR计算压缩文本中有多少词能在原文中找到。再计算出AG。删除AG值 top 10%的样本。
4.训练压缩用的模型
用transformer encoder,用刚才的数据集训练做token级分类任务即可。
对于一个特定的压缩比,只需要取token级分类结果,取topk即可。
5.实验
这里展示几个简单的实验
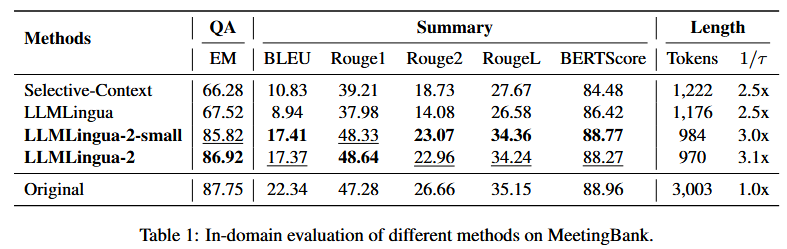
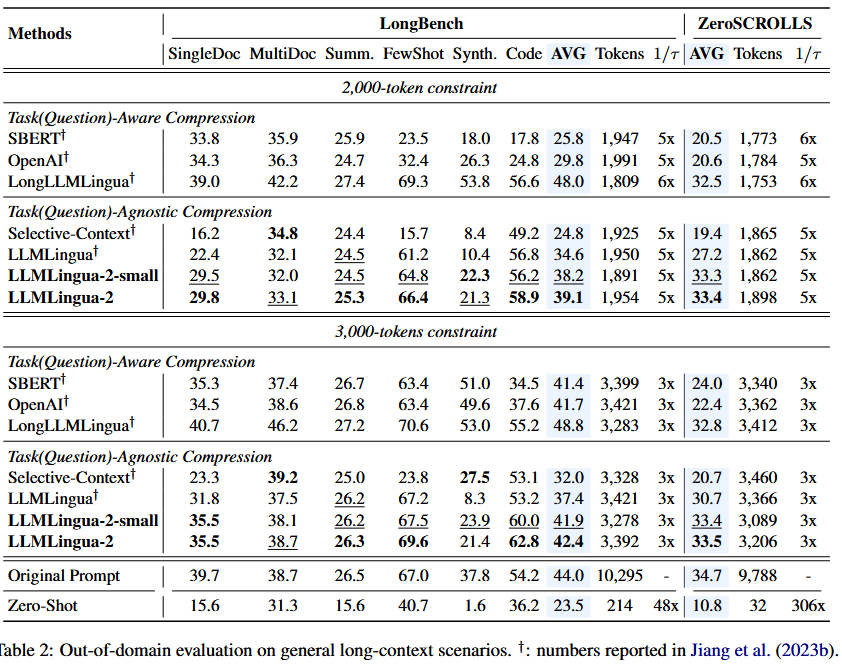
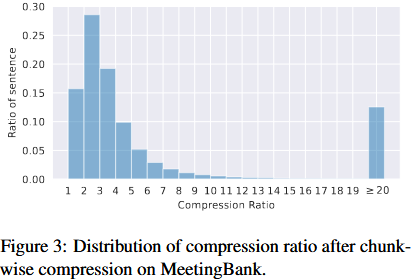
去年看到,某企业有相关的技术难题,技术诉求为压缩5倍长度性能损失小于5%。另外,还有任务自适应压缩策略,要求比统一压缩策略效果提升10%。当然,推理时延不能提高。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)