效率工具:Cursor(AI IDE)的工作原理
本文深入解析了Cursor等AI编程工具的底层机制与优化技巧。文章指出,LLM的本质是预测下一个单词,而AI IDE在此基础上通过多轮工具调用实现智能代理功能。作者从三个阶段(早期解码式、指令微调、工具调用)阐述了LLM的发展历程,并揭示了Cursor等IDE的工作原理:基于VS Code二次开发,整合聊天面板和多种工具,通过精心设计的提示词实现复杂编码任务。文章还分享了实用技巧。
引言
了解 Cursor、Windsurf、Copilot 等 AI 编程工具的底层机制,能显著提升你的开发效率,尤其是在体量庞大、结构复杂的代码库中。许多人之所以觉得 AI IDE “不够稳定”,往往是把它们当作传统工具使用,而忽视了它们自身的局限和最佳使用姿势。一旦理解了这些原理,就像掌握了“作弊码”:在我写这篇文章时,Cursor 已能为我生成约 70% 的代码。
本文将深入解析这些 IDE 的运行方式、Cursor 的系统提示(system prompt),并分享如何通过调整你的代码写作方式和 Cursor 规则来获得更好的体验。
从 LLM 到编码代理(Coding Agent)
大语言模型的本质
LLM 的核心能力其实很简单:不断预测下一个单词。但就是基于如此简单的机制,我们却能构建出形形色色的复杂应用。
三个阶段:从补全文本到智能代理
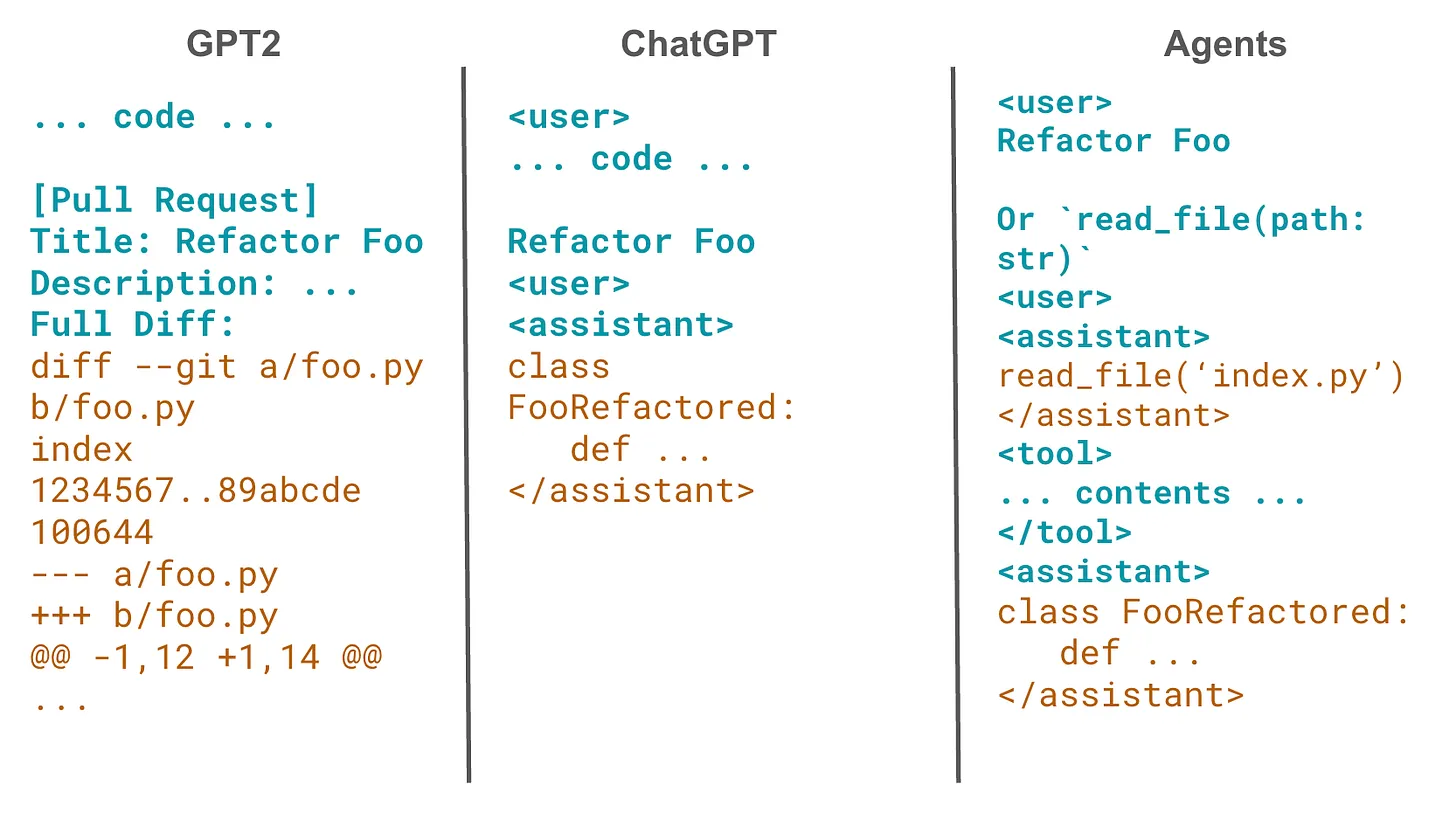
在示意图中,蓝色代表“前缀/提示(prompt)”,橙色代表 LLM 自动补全的内容。要让代理返回一次可交付的答案,需要多轮调用 LLM,每一轮都由本地客户端而非 LLM 本身去执行工具,并把结果馈送回去。
-
早期解码式 LLM(如 GPT-2)
-
依靠手工拼接前缀来“诱导”模型补全出想要的内容。
-
例:
Topic: Whales Poem: ← 让模型在此处接着写整首诗 -
写代码时也类似,需要你把 PR 标题、描述、差异(diff)等全部写进 prompt。
-
-
指令微调(ChatGPT 时代)
- 你可以直接说:“Refactor Foo 方法”,模型就能返回代码。
- 本质同样是补全,只是系统在前缀里加入了形如
<user>…</user>的角色标签。
-
工具调用(Tool Calling)
- 在前缀里约定:“如果要读文件就输出
read_file(path)”。 - LLM 补全出
read_file('index.py')→ 本地执行 → 再把文件内容以<tool>…</tool>形式回传给模型。 - 这样模型就能与外部世界交互,完成更加复杂的任务。
- 在前缀里约定:“如果要读文件就输出
代理式编码(Agentic Coding)
像 Cursor 这样的 IDE,本质上是对上述流程的“奢华包装”。要做一款 AI IDE,你大概需要:
-
基于 VS Code 二次开发;
-
加一个聊天面板,选一款性能好的 LLM(如 Claude Sonnet 3.7);
-
实现若干“工具”供 LLM 调用:
read_file(full_path)write_file(full_path, content)run_command(command)
-
反复打磨内部提示词:
- “你是一名专家级程序员”
- “别凭空猜测,需要时请调用工具”
- ……
听上去容易,真做起来却会踩无数坑:语法错误、幻觉、结果不稳定……秘诀就是围绕模型的优势与短板来设计工具与提示词,并用“小模型+流水线”分担主模型的“认知负载”。
优化代理式编码
下图展示了 AI IDE 在后台做了哪些事。IDE 会把你在聊天里用
@标注的文件插入上下文,调用多种搜索工具补充信息,然后用特定的 diff 语法编辑文件,最后给用户返回总结性回复。
常见优化与使用技巧
| 场景 / 问题 | IDE 的做法 | 使用小贴士 |
|---|---|---|
| 显式上下文:用户其实知道该改哪些文件 | 支持 @file / @folder 语法,把完整文件内容注入 <attached-files> |
多用 @ 指定文件夹/文件,上下文越明确,回复越快、越准 |
| 语义搜索:如“登录逻辑在哪儿?” | 全量向量化代码库 → 查询时用另一模型重新排序、过滤 | 在文件顶部写清 “文件作用、主要职责、何时修改”,注释 = 高质量向量语料 |
| 写文件难:让模型一次性输出完整文件易出错 | 主模型只生成“语义差异(semantic diff)” 用更小、更快的 apply-model 把 diff 应用到实际文件 → 再跑 linter → 把 diff 和 lint 结果返给主模型自我修正 |
- 无法直接“喊话”给 apply-model,比如 “别乱删注释” —— 该问题应通过主模型约束 - 大文件 >500 行时先拆分,apply-model 才不会慢又出错 - 投资一套 高质量 Linter,Lint 结果是极高价值的上下文 |
| 文件名含糊 | 推荐使用唯一且语义化的文件名,如 foo-page.js 而非多处 page.js |
这样模型在 edit_file 时不会搞混 |
| 模型特性 | 选择“在代理场景里表现好的” LLM,Anthropic 系列常见于 Cursor | 关注能评估“代理式写码”的排行榜,如 WebDev Arena |
| 自修复 | 高阶玩法:自定义 apply_and_check_tool,跑更严的 lint、启动无头浏览器回归测试,收集日志/截图作为反馈 |
MCP(Model Context Protocol)将极大简化此类工作流 |
Cursor 系统提示逐行解析
通过 MCP 注入,我提取了 2025 年 3 月 Cursor Agent 的最新系统提示。与很多工具相比,Cursor 的提示写得相当考究,这也是它效果领先的重要原因。
下面节选几条设计亮点,并加上简要点评:
- XML + Markdown 分段:
<communication>、<tool_calling>等标签让人和模型都更易阅读。 - “powered by Claude 3.5 Sonnet”:避免模型自报家门时说错版本,引发计费争议。
- “the world’s best IDE”:简单一句话,防止模型在出错时推荐竞争产品。
- “Refrain from apologizing”:专治 Sonnet 喜欢说 “Sorry”。
- “NEVER refer to tool names when speaking”:仍偶有模型在回复里泄露
edit_tool;加粗提醒能一定程度缓解。 - “Before calling each tool, first explain”:流式输出时,先向用户说明正在干什么,避免“卡顿感”。
- …(更多细节请参见全文)
整个系统提示完全静态,不含任何用户或项目特有内容,以便缓存并降低延迟——对需要多次调用 LLM 的代理尤为关键。
如何高效编写 Cursor 规则(Rules)
在 LLM 眼中,你的 “项目规则” 是一堆可按需检索的“百科条目”,而不是硬塞进系统提示的额外指令。
- 别给规则“贴身份”:诸如“你是一名资深前端”会与系统身份冲突。
- 少写负面约束:比起 “不要做…”,更有效的是 “在…情况下,应…”。
- 名称+描述要高辨识度:让代理一眼能判断某条规则是否适用。
- 用百科体写规则正文:强调“是什么”“为何如此”,而非详尽步骤;必要时用
[链接](path/to/code)标注关键文件。 - 规则太多,其实是坏信号:理想的 AI 友好型代码库越直观,规则就越少。
结语
想想看:一款基于 VS Code 的“外壳”,凭借开源的代理提示和公开的模型 API,就能拿到接近 100 亿美元 的估值,真是疯狂。未来谁会主导 AI IDE 赛道?Cursor 会自研模型吗?还是 Anthropic 直接推出自家 IDE?无论答案如何,懂得如何为 AI 调整你的代码库、文档和规则,将是一项长期受益的技能。
如果你觉得 Cursor 用得不顺手,大概率是用法不对。希望本文能帮你跳出“凭感觉”使用的陷阱,以更系统、更高效的方式拥抱 AI 编程时代。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)