大模型新书推荐:《图解大模型》轻松上手 LLM!
今天推荐的这本书——《Hands-On Large Language Models》,由 Jay Alammar 和 Maarten Grootendorst 联合撰写,O’Reilly Media 出版,用 LLM 做研究,这本书是最好的起点。

1. 简介
理解并灵活运用大型语言模型(LLMs),正逐渐成为经济学研究者的新型“基本功”。今天推荐的这本书——《Hands-On Large Language Models》,由 Jay Alammar 和 Maarten Grootendorst 联合撰写,O’Reilly Media 出版,用 LLM 做研究,这本书是最好的起点。
-
Jay Alammar 是 NLP 界的“图解大师”,擅长将复杂的模型原理通过图解和类比方式讲得清清楚楚,被誉为“最懂普通人学习语言模型痛点的人”。
-
Maarten Grootendorst 是知名的开源项目作者,开发了在经济学中极具实用价值的 BERTopic,被广泛用于文本挖掘、社交媒体等主题建模中。
该书的中文版也于今年上线,译名为《图解大模型:生成式AI原理与实战》,还特别增加了 DeepSeek-R1 模型的工作机制讲解,十分贴心。

2. 为什么经济学研究者值得读这本书?
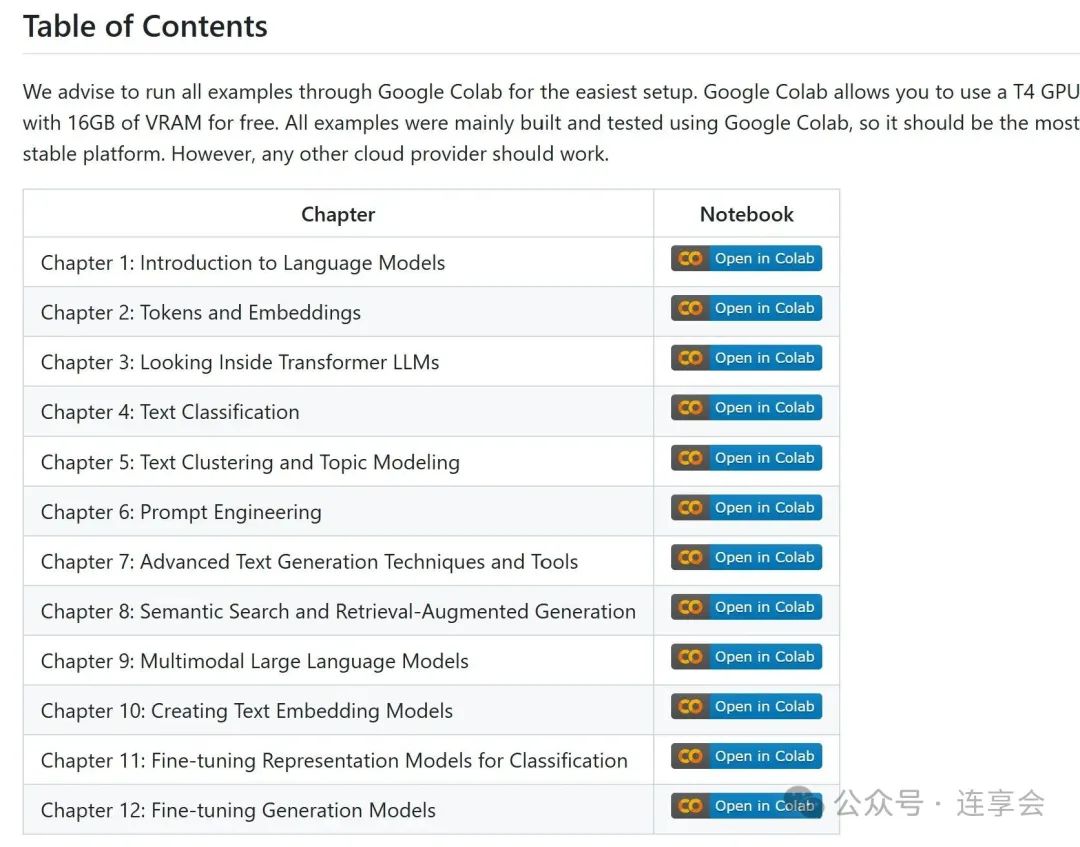
《Hands-On Large Language Models》是一本有代码、能实战、跑得通的 LLM 入门与进阶指南,每个章节都有相应开源代码,代码全部托管于 GitHub 平台,方便读者随时获取,也支持在 Google Colab 平台上直接运行。
搭配 GitHub 源码:边学边练Hands-On Large Language Models
https://github.com/HandsOnLLM/Hands-On-Large-Language-Models
本文将以经济学研究者的视角出发,系统梳理这本书中最不容错过的几个实用亮点:
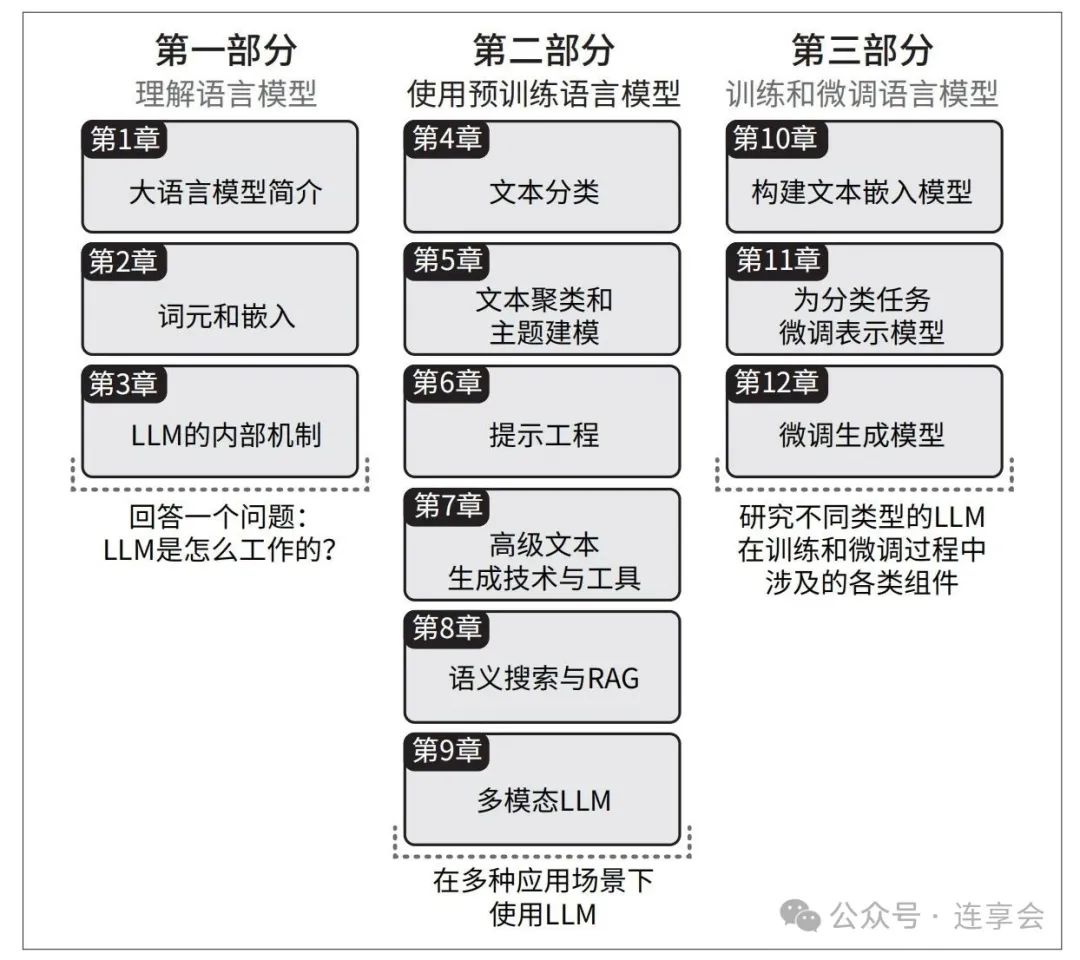
3. Part 1:LLM的基础概念及底层逻辑
对于非计算机专业背景的学者来说,理解 LLM 的运作机制常常是一个认知门槛。这本书前三章通过类比图示+实用案例+代码的方式,讲透了以下几个关键概念:
-
Token(词元)是如何被切分与处理的?
-
Embedding(嵌入):文本转向量的核心技术
-
将新闻报道、社交评论等非结构化数据转化为向量,是后续聚类、回归、因果分析等任务的前提
-
理解嵌入的演化过程(Bag-of-Words → Word2Vec → Transformer),解释为什么传统方法难以捕捉语义、而LLM 则可以
-
-
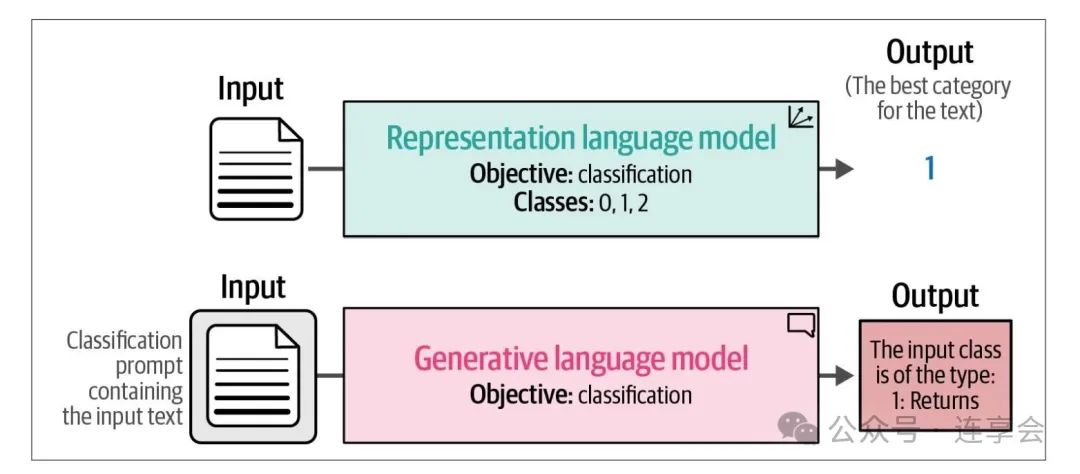
LLM 模型梳理: Representation vs. Generative
-
Representation Models(编码器): 如 BERT,擅长捕捉上下文语义,适用于文本分类、实体识别等任务
-
Generative Models(解码器): 如GPT系列,擅长生成连贯文本,可用于模拟经济情景等
-
4. Part 2:主流实战任务与场景
理解 LLM 后,这本书的后面部分引导我们“用起来”。书中详细介绍了应用已经训练好的 LLM 和如何微调 LLM 进行研究,特别是文本分类、聚类、提示工程等经济学研究中的常用方法。
4.1 文本分类
文本分类技术经常用在对财经新闻、社交媒体进行情感分类,预测市场走势中。除了用传统的机器学习方法,这本书第4章和第11章提供了多种基于 LLM 的分类方法:
以 BERT 为代表的 Representation Models
-
任务特定模型:在一个大型数据集上预训练的,例如 BERT,可专门用于情感分析
-
嵌入模型:选择合适的模型生成嵌入向量,将这些向量作为输入来训练分类器
书中推荐了 Hugging Face Hubs 这个宝藏平台,有超过6万个用于文本分类的模型,以及超过8000个用于生成嵌入的模型。我们可以根据语言、大小、性能等维度灵活选择一个适合的模型!通过 Sentence Transformers 库 生成高质量的文本嵌入,便于后续进行分类、聚类等任务:
from sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
# 将文本转换为嵌入
train_embeddings = model.encode(data["train"]["text"], show_progress_bar=True)
test_embeddings = model.encode(data["test"]["text"], show_progress_bar=True)
以 GPT 系列为代表的 Generative Models
-
开源的“编码器-解码器”模型 (Flan-T5)
-
闭源的仅“解码器”模型 (GPT-3.5): 如何通过网络接口 (API) 来使用实现分类
微调 BERT 模型进行高精度分类
举个例子,通过微调 RoBERTa 等专业模型,我们可以构建高精度的市场情绪分析系统,准确捕捉投资者情绪波动。
没有标注好的样本怎么办?
在没有任何标注数据的情况下,书中也提供了伪标签、少样本学习等解决方案,极具实用性。
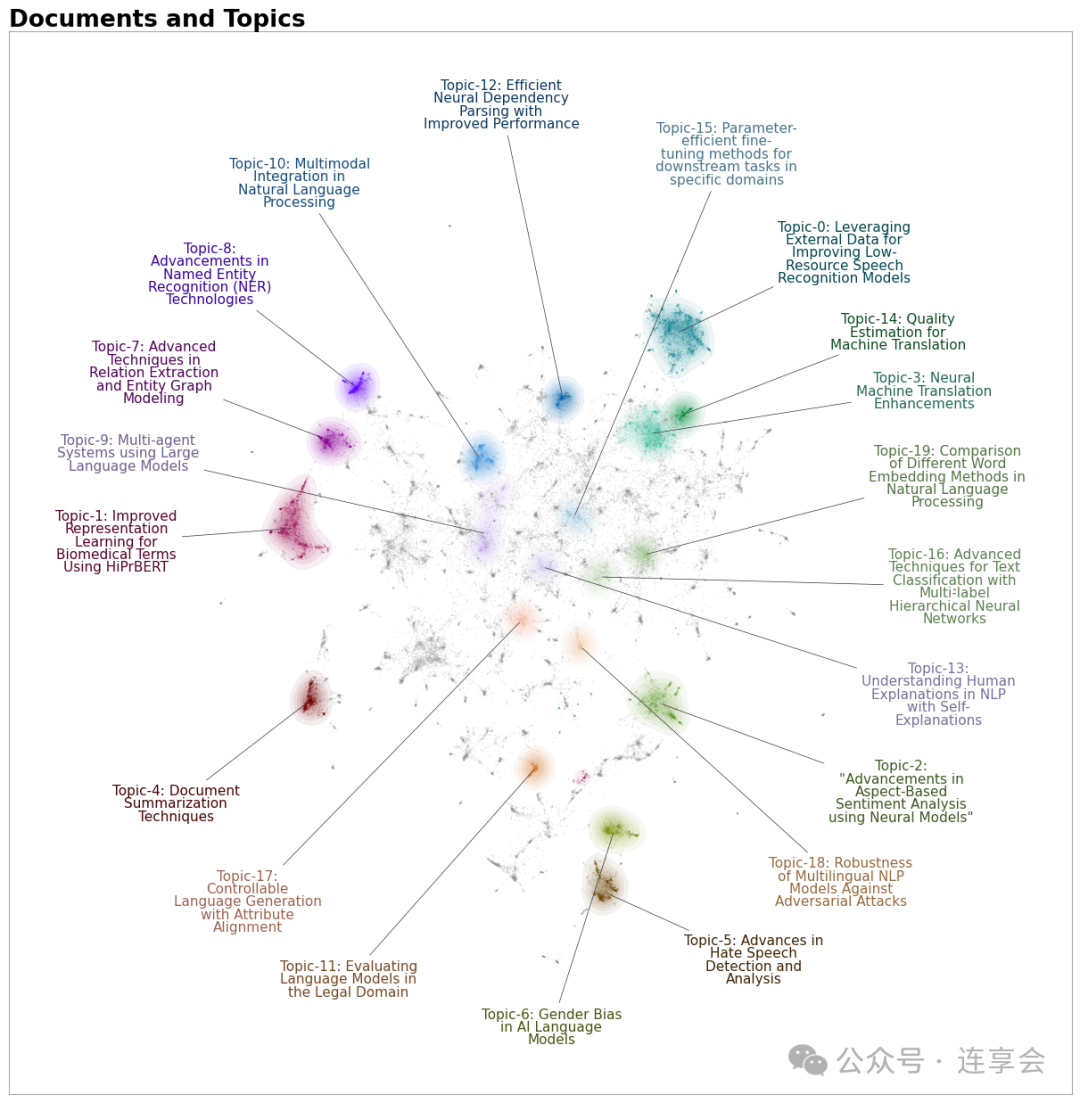
4.2 文本聚类和主题建模
第5章系统介绍了如何利用 LLM 进行高效的文本聚类分析,适用于:
-
自动识别政策焦点变化趋势
-
分析学术文献的主题演化路径
-
监测社交媒体话题演变
方法包括:
-
文本嵌入:使用 BERT、MPNet 等模型生成高质量文本向量
-
降维处理:如 UMAP、t-SNE,便于可视化和聚类;
-
聚类算法:如 KMeans、HDBSCAN
-
HDBSCAN 特别适合经济学研究,因为它能够自动确定最优聚类数量,并有效识别异常值
-
-
主题解释:手动检查聚类结果,用 GPT 等归纳主题标签
-
可视化主题结果
4.3 提示工程的实用技巧
提示工程是与文本生成型大型语言模型交互的核心技能。书中第6章和第7章系统讲解了常见的提示工程方法和一些小技巧:
-
温度(temperature)与 top_p 参数控制生成文本的多样性
-
上下文学习(In-context Learning):通过提供示例引导模型输出
-
链式提示(Chaining Prompts):将多个提示串联,解决复杂问题
-
思维链(Chain-of-Thought, CoT):让模型先思考再回答
-
采样分析(Ensemble Sampling):多次生成取多数结果,提高准确性
用于提高生成文本质量的方法:
-
链(Chains):通常将一个 LLM 与某个额外的工具、提示或功能连接在一起
-
记忆(Memory):帮助 LLM 记忆记住我们之前对话中的内容
-
代理(Agents):利用 ReAct 框架,允许 LLM 对自身的思考进行推理,采取行动,并观察结果
这些技巧特别适用于:
-
复杂因果机制的自动推理
-
结构化信息提取(如提取政策工具、作用机制、效果指标)
-
构建经济学文献综述助手
4.4 RAG:让LLM不再胡说八道
LLM 虽然强大,但存在幻觉 (hallucinations) 问题,即可能生成不准确或虚构的信息。这对经济学研究极为不利。,模型可能生成看似合理但不准确或过时的信息,这对我们经济学研究来说是一个很大的问题。
书中第8章系统讲解了 RAG(Retrieval-Augmented Generation, 检索增强生成):
-
检索系统找文献或原始数据
-
LLM 生成回答并引用原始材料
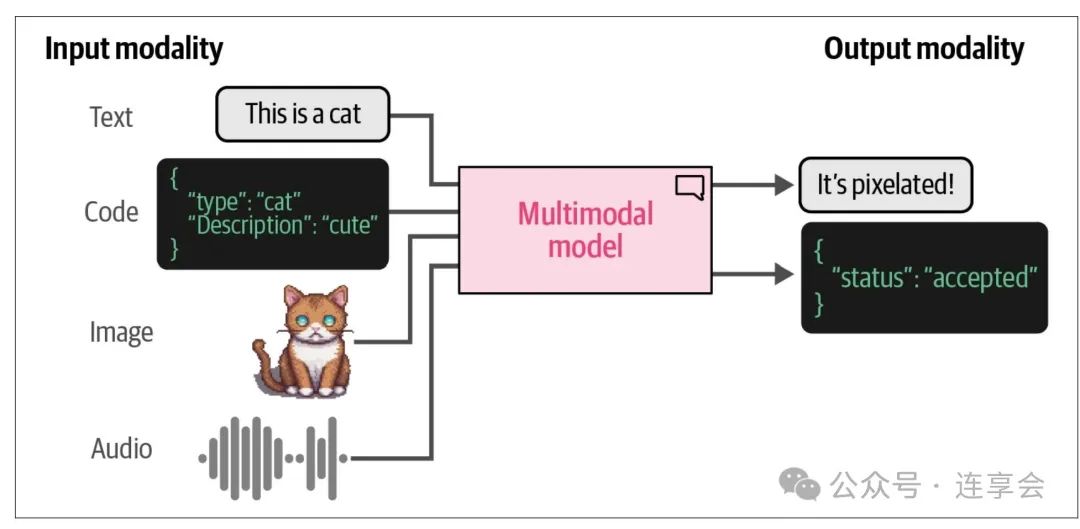
4.5 多模态 LLM: 处理“图+文”
在传统经济学研究中,图像与文本的信息往往被割裂处理。但在很多真实世界的问题中,图文是不可分割的。例如城乡发展研究中抓取不同城市地区的街景图像,通过图像模型提取绿化率、楼宇密度等。
本书第9章讲解了 CLIP、BLIP-2 等多模态模型的原理与调用方式,展示了如何将图像和文本转成向量后进行相似度分析,非常适合希望扩展数据维度的研究者。
4.6 LLM 微调技术:打造属于你自己的研究助理
大型语言模型虽强,但它的“通用性”也意味着:
-
输出风格可能不适合我们个人的写作习惯
-
回答方式不符合经济学的严谨规范
-
不知道你研究领域的细节与风格
这时,“微调”就显得尤为重要。书中详细介绍了从最简单到最前沿的几种方法:
-
监督微调 (SFT)
-
给模型提供“输入-输出”对,例如一个政策文本和对应的分类标签,让它学会你想要的格式
-
构建高精度文本分类器、信息抽取器
-
-
偏好微调 (RLHF) 适用于构建一个输出风格与逻辑更贴合你需求的模型 举个例子,我们可以收集几十篇高水平经济学综述段落作为训练集,让模型学会如何总结一篇 NBER 工作论文、怎么使用“这表明……”“一种解释是……”等写作话术,并自动根据论文输出一段 summary。这样打造出来的 LLM,不再是全能型废柴,而是一个懂你的研究助手。
总之,《Hands-On Large Language Models》是一本真正把 LLM 用法讲清楚又讲实在的书,也是经济学者“拿捏AI”过程中不可或缺的工具书。不管是刚刚开始接触 LLM,希望弄懂 Embedding、token、prompt 是什么,还是已经在做文本挖掘、政务公开数据分析,或者想把大模型变成写论文的好搭子,都能从这本书中找到实操路径!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献470条内容
已为社区贡献470条内容

所有评论(0)