redis--黑马点评--全局ID生成器详解
订单的特点就是数据量比较大,因为用户只要产生购买的行为,就会不停的产生新的订单,如果项目有一定的规模,用户量达到数百万,每天的订单可能就高达数百万,日积月累,单张表显然不能保存如此多的数据,如果无法保存,就需要分到多张表中,如果每张表都采用自增长,每张表都自增,那么订单的id就一定会重复,而订单就不应该重复,因为从业务的角度来考虑,将来一些售后服务还需要订单id,如果id重复,将来一定会出问题。生
全局唯一ID
介绍:在整个电商项目的业务之中,具有唯一性的商品就是优惠券,用户会去抢购优惠券,当他抢购是自然就需要生成订单,订单就保存在tb_voucher_order表中,打开数据库,观察表结构:
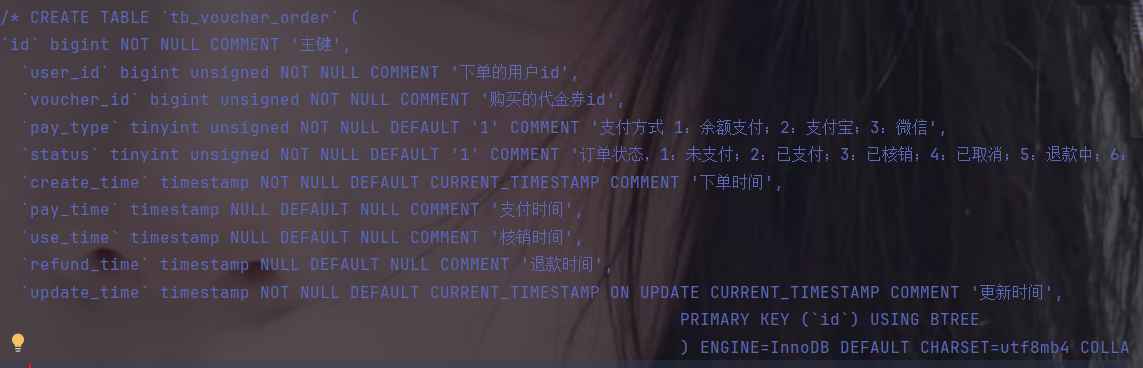
通过这张表可以看到:
-
user_id是存储用户的一个id,哪个用户来购买的需要记录下来。
-
voucher_id是购买代金券的id,购买了什么商品
-
pay_type 支付的方式
-
status:订单状态,刚创建时默认未支付,如果用户支付以后就会变成已支付,支付完成后,用户在店里使用这张券以后就会变成已核销状态,如果用户下单以后未支付直接取消,就会变成已取消状态,或者付款之后,没有使用就退款,就会出现退款中,和已退款状态
-
与这些状态对应的还有时间
-
create_time:下单时间
-
pay_time:支付时间
-
use_time:核销时间
-
refund_time:退款时间
-
update_time:更新时间
-
特别注意:在该表中的主键没有使用自增长
为什么呢?
订单如果使用数据库自增ID就存在一些问题:
-
id的规律性太明显,容易暴露一些关键信息给用户。
-
收单表数据量的限制
订单的特点就是数据量比较大,因为用户只要产生购买的行为,就会不停的产生新的订单,如果项目有一定的规模,用户量达到数百万,每天的订单可能就高达数百万,日积月累,单张表显然不能保存如此多的数据,如果无法保存,就需要分到多张表中,如果每张表都采用自增长,每张表都自增,那么订单的id就一定会重复,而订单就不应该重复,因为从业务的角度来考虑,将来一些售后服务还需要订单id,如果id重复,将来一定会出问题。
那如何解决呢?
全局ID生成器(因为经常用在分布式系统下,又被称为分布式唯一ID生成器)
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
全局:在同一个业务下,无论分布式系统有多少个服务,多少个节点,业务之下又分成了多少张不同的表。该ID一定是当前业务中唯一的ID,不会出现冲突。
虽然该项目是一个单体项目,但是数据量庞大的情况下,也可能用到它。
全局唯一ID需要满足以下五个特性:
-
唯一性:大多数订单业务都要求订单ID唯一
-
高可用:作为ID生成器,必须确保随时生成可用正确ID。
-
高性能:不仅要保证生成ID的唯一性,正确性,还需要保证生成ID的速度足够快。
-
递增性:生成ID需要满足不断变大的特性,因为该ID需要代替数据库自增ID。要确保整体的逐渐变大,这样有利于数据库创建索引,提高插入时的速度。
-
安全性:数据库是逐渐递增的,较为简单,快捷,但是存在安全问题,容易暴露关键信息,因此生成ID在满足以上四个特性的基础上还要保证规律性不能太明显。
而redis中的String数据结构里有一种自增特性,incrby指令可以制定对应的步长来进行自增。
可以保证唯一性:Redis独立于数据库之外,不管数据库有几张表或者有几个不同的数据库,但redis只有一个,因此他的自增一定是唯一的,不会存在多个自增的情况。redis的集群方案,主从方案,哨兵方案都可以保证Redis的高可用。redis存储于内存中,同样满足高性能。而既然是自增,那么也就保证了递增性。
而为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其他消息,让其规律性不这么明显:
为了提高数据库的性能,id会采用数值类型(Long)直接插入数据库(因为数值类型在数据库中占用空间较小,建立索引方便,速度更快)。
因为采用的是Long型,有8个字节,64个比特位,
第一个比特位是符号位,永远为0。
中间31个bit为时间戳(以秒为单位,定一个初始的时间,在计算下订单时的时间与初始时间的时间差是多少秒并记录下来,可以使用69年),用来增加ID复杂性,不是单纯的Redis自增。
后面32位bit为序列号,序列号中就是Redis自增的值。支持每秒产生2^32个不同ID
因此如果在一秒钟下了多份订单,即使时间戳相同,那么后面的序列号也会不同。
综上所述,利用redis就能够满足分布式系统中全局唯一ID的五大特性。
redis实现全局唯一ID
全局唯一ID的生成策略是基于redis中的自增长,而,redis自增长需要有一个key,对应的值不断增长,不同业务要使用不同的key,不能去使用同一个自增长,因此需要声明一个方法,传入前缀参数用来区分不同业务,返回值为Long型。
接下来方法的核心业务:生成时间戳与序列号,最终将其拼接起来。
-
生成时间戳:时间戳是一个31位的数字,单位为秒,需要一个基础的日期作为开始时间,再拿当前时间减去开始时间。需要先注入初始值。最好为常量,在拿到当前时间,去减去开始时间 即得到时间戳。
代码展示:
private static final long BEGIN_TIMESTAMP = 1735689600L; // 1.生成时间戳 long currentSecond = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC); long timestamp = currentSecond - BEGIN_TIMESTAMP;
-
生成序列号:需要先注入redis到IOC容器中,在进行自增
注意事项:不能只选择一个key来坐自增长,即无论订单业务持续多长时间,自始至终就只是这一个key在做自增长,随着不断的发展,key的值会也来越大,而redis单个key的自增长的数值是有限度的,上限为2 ^ 64。而且真正用来记录的序列号只有32位bit,如果接下来存的数值超过了2^32位,那么序列号这一部分就存不下。因此不能一直使用同一个key,哪怕是同一个业务。
解决方案,可以在该key后面在拼接一个时间戳,比如哪一天下的订单,当天的key就为 key名+ “20250605”。向下类推。这样还可以统计每一天下单的总量。
String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
我们可以根据该代码来实现对订单量的统计,如果要一年一统计,就找yyyy后缀的即可,如果按月,则yyyy:MM后缀统计即可
代码实现:
String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix +":"+ date);
-
进行拼接:将时间戳与序列号进行拼接,在前面加上符号位。即可完成
注意事项:返回值为long型,如果简单地拼接,返回的类型为字符串类型,所以需要以数字的形式进行拼接,即数字的高位为时间戳,数字的低位为序列号,这种拼接就需要借助于位运算:
将时间戳的值向左侧移动多少位,移动到足够序列号的位置即可,即时间戳的值向左移动32位,再将序列号的填充从到这一部分。
而填充则需要借助或运算。
代码展示:
return timestamp << COUNT_BITS | count;
至此,全局唯一id生成器完成。
代码如下:
@Component
public class RedisIdWorker {
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1735689600L;
/**
* 序列号位数
*/
private static final int COUNT_BITS = 32;
@Resource
private StringRedisTemplate stringRedisTemplate;
public long nextId(String keyPrefix) {
// 1.生成时间戳
long currentSecond = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC);
long timestamp = currentSecond - BEGIN_TIMESTAMP;
// 2.生成序列号
// 获取当前日期
String date = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix +":"+ date);
// 3.拼接返回
return timestamp << COUNT_BITS | count;
}
进行测试,编写测试类,利用线程池来进行并发测试:
@Test
void testIdWorker() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(300);
//CountDownLatch 相当于 一个线程计数器,没执行完一个线程就调用countDown()方法 -1 ,直到减为0,之后还会变成初始值。
Runnable task = ()->{
for (int i = 0; i < 100; i++) {
long id = redisIdWorker.nextId("order");
System.out.println("id = " + id);
}
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
es.submit(task);
}
// 等待所有任务执行完毕
latch.await();
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - begin));
}
测试完成,耗时1190毫秒
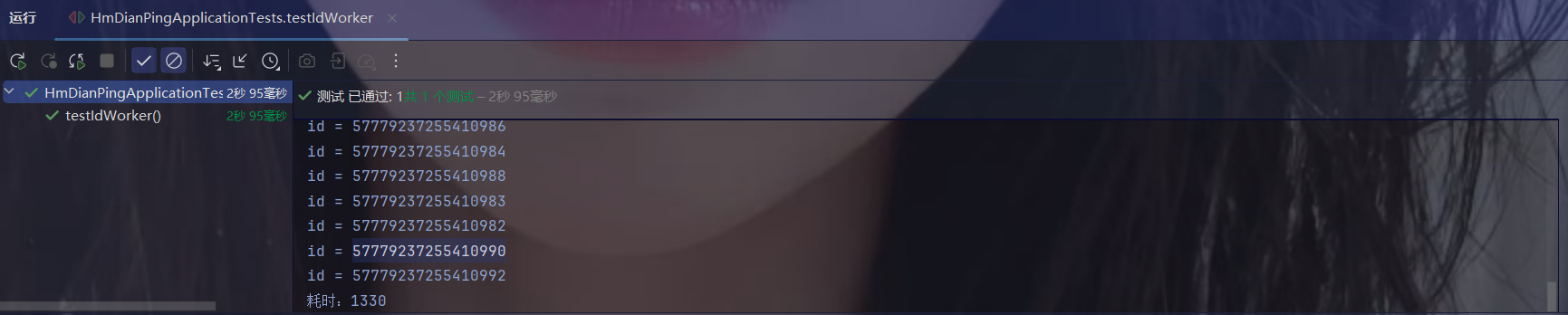
检查Redis数据库:
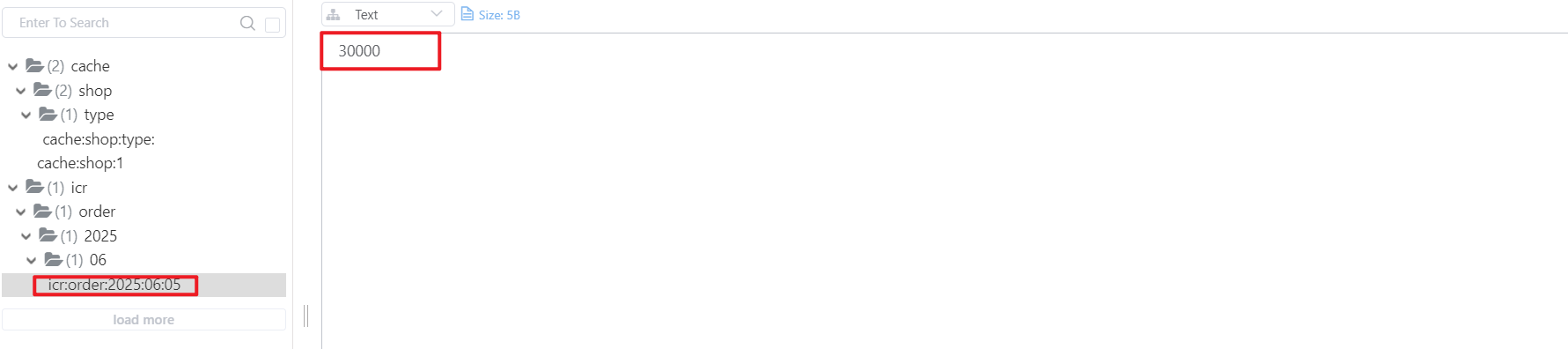
总计生成了30000个ID。
总结:
全局唯一生成ID策略:
-
除了用redis实现,还可以使用UUID,直接使用将jdk自带的UUID工具类就可生成,生成的是16进制的数值,返回的是字符串结构,并且不是单调递增的特性。因此虽然可以做,但并不是很友好。所以这种方式使用较少。
-
Redis自增,该方案相对来讲各种特性都能够满足,整体单调递增,数值长度也不大,而且为数字类型,存储在数据库里占的空间相对来讲较小,比较友好。
-
snowflake算法(雪花算法):比较知名的全局唯一ID生成策略,该方案也采用了一种long类型的64位的数字。该方案的自增采用了机器内部的自增,因此需要维护一个机械ID。雪花算法不依赖于redis,性能方面可能会更好一些,但是对于时间依赖度较高,有兴趣可以去百度一下。
-
数据库自增:该方案并不是在订单表中设置自增,而是直接写一张自增表,这张表专门做自增,再让其他需要id的表来拿自增表中的ID,这样相当于其他表用的是同一张表的自增ID。这样可以保证一致性,但性能可能不怎么好。
redis自增ID策略:
-
整体结构:时间戳加自增ID
-
注意事项:key可以设置成每一天更换一次,优点:方便统计订单量,还可以限定key的值不会太大以至于超出上限。
希望对大家有所帮助。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)