UFO²:桌面代理操作系统
最近的计算机使用代理(CUA),由多模态大型语言模型(LLM)驱动,为通过自然语言自动化复杂的桌面工作流提供了有希望的方向。然而,大多数现有的CUA仍然停留在概念原型阶段,受到浅层操作系统集成、基于截图的脆弱交互和执行干扰的限制。我们提出了UFO²,这是一个针对Windows桌面的多代理AgentOS,将CUA提升为实用的系统级自动化工具。UFO²具有一个集中式的HostAgent用于任务分解和协

张冬梅
微软
摘要
最近的计算机使用代理(CUA),由多模态大型语言模型(LLM)驱动,为通过自然语言自动化复杂的桌面工作流提供了有希望的方向。然而,大多数现有的CUA仍然停留在概念原型阶段,受到浅层操作系统集成、基于截图的脆弱交互和执行干扰的限制。
我们提出了UFO²,这是一个针对Windows桌面的多代理AgentOS,将CUA提升为实用的系统级自动化工具。UFO²具有一个集中式的HostAgent用于任务分解和协调,以及一组配备本地API、领域特定知识和统一GUI-API操作层的应用专用AppAgent。这种架构在保持模块化和可扩展性的同时实现了强大的任务执行能力。混合控制检测管道将Windows UI Automation(UIA)与基于视觉的解析融合在一起,以支持多样化的界面风格。通过投机性的多动作规划进一步提高了运行效率,减少了每步的LLM开销。最后,画中画(PiP)接口允许在隔离的虚拟桌面上进行自动化,使代理和用户能够同时操作而不会相互干扰。
我们在20多个实际的Windows应用程序上评估了UFO²,展示了其相比先前CUA在鲁棒性和执行准确性上的显著改进。我们的结果表明,深入的操作系统集成开启了一条可靠、面向用户的桌面自动化的可扩展路径。
UFO²的源代码可在https://github.com/microsoft/UFO/公开获取,并在https://microsoft.github.io/UFO/提供详尽的文档。
关键词:计算机使用代理、大型语言模型、桌面自动化、Windows系统
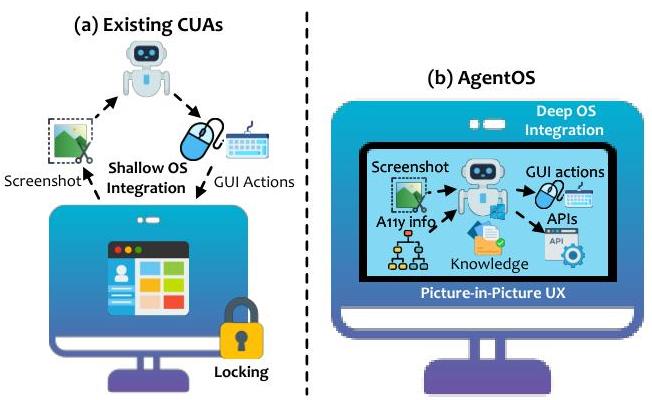
图1. (a)现有CUA与(b)桌面AgentOS UFO²的对比。
ACM参考格式:
Zhang Chaoyun等。2025. UFO²: The Desktop AgentOS. In . ACM, New York, NY, USA, 24 pages. https://doi.org/10.1145/nnnnnnn. nnnnnnn
1 引言
桌面应用程序的自动化长期以来一直是提高劳动力生产力的核心。商业机器人流程自动化(RPA)平台如UiPath [1]、Automation Anywhere [2] 和 Microsoft Power Automate [3] 展示了这一趋势,通过图形用户界面(GUI)[4, 5] 使用预定义脚本来复制重复的用户交互。然而,这些基于脚本的方法在动态、不断演变的环境中往往表现得非常脆弱 [6]。即使是微小的界面变化也可能破坏底层自动化脚本,需要手动更新并耗费大量维护努力。随着软件生态系统的日益复杂和异构化,基于脚本的自动化脆弱性严重限制了其可扩展性、适应性和实用性。
*通讯作者。邮箱: chaoyun.zhang@microsoft.com
${ }^{\dagger}$ 此工作是在微软实习期间完成的。
最近,计算机使用代理(CUAs)[7]作为一种有前途的替代方案出现。这些系统利用先进的多模态大型语言模型(LLMs)[8, 9] 来解释多样化的用户指令、感知GUI界面并生成自适应动作(例如鼠标点击、键盘输入),无需固定的脚本[7]。早期原型如UFO [10]、Anthropic Claude [11] 和 OpenAI Operator [12] 表明,这类由LLM驱动的代理可以稳健地自动化传统RPA流水线无法处理的过于复杂或模糊的任务。然而,尽管取得了这些进展,当前的CUA实现仍主要处于概念层面:它们主要优化视觉定位或语言推理 [12-16],但对桌面操作系统(OSs)和应用程序内部的系统级集成关注较少(图1(a))。
依赖原始GUI截图和模拟输入事件存在几个缺点。首先,仅基于视觉的输入可能嘈杂且冗余,增加了LLM的认知负担并降低了执行效率 [17]。其次,现有的CUA很少利用操作系统的原生可访问性接口、应用级API或详细进程状态——这错失了显著提高决策准确性、减少延迟和实现更可靠执行的机会。最后,在主用户桌面上模拟鼠标和键盘事件会锁定用户在自动化过程中无法操作,导致用户体验(UX)较差。必须解决这些限制,CUA才能从有趣的概念原型发展为适用于实际桌面自动化的强大、可扩展解决方案,这促使我们提出核心研究问题:
我们如何构建一个灵活适应不断变化的界面、可靠编排多样化应用并尽量减少对用户工作流干扰的稳健、深度集成的桌面自动化系统?
作为回应,我们提出了UFO²,这是Windows的新AgentOS,重新设想桌面自动化作为第一类操作系统抽象。与之前将自动化视为截图和模拟输入事件之上的层的CUA不同,UFO²被设计为深度集成的多代理执行环境——嵌入操作系统功能、应用程序特定的内省和领域感知规划到核心自动化循环中,如图1(b)所示。
在其基础之上,UFO²为自然语言驱动的自动化提供了一个模块化的、系统级别的基底。一个集中的协调器,即HostAgent,解释用户指令,将其分解为语义上有意义的子任务,并动态调度给专门的AppAgents执行——这些专家模块针对特定的Windows应用程序定制。每个AppAgent都配备了可扩展的工具箱,包括应用程序特定的API、混合GUI-API操作接口和集成的知识,关于应用程序的能力和语义。这种架构使得在多个并发应用程序之间进行稳健的协调成为可能,
支持跨越Excel、Outlook、Edge等的工作流。
为了在全谱的应用程序UI中实现可靠的执行,UFO²引入了混合控制检测流水线,结合Windows UI Automation(UIA)API与高级视觉定位模型[18]。这允许代理内省和作用于标准和自定义UI组件,弥合结构化可访问性树和像素级感知之间的差距。此外,UFO²持续将外部文档、补丁说明和过去的执行轨迹整合到统一的向量化内存层中,使每个AppAgent能够在不重新训练的情况下逐步完善其行为。
在交互层,UFO²暴露了一个统一的GUI-API执行模型,其中代理无缝组合传统的GUI动作(如点击、按键)与本地Windows或应用程序特定的API。这种混合方法提高了执行效率,减少了对UI布局变化的脆弱性,并启用了更具表达力的高层次操作。为进一步最小化与LLM为基础的动作规划相关的延迟,UFO²包含了一个投机性的多动作执行引擎,该引擎使用轻量级控制状态检查主动推断和验证动作序列,从而在不损害正确性的情况下大幅减少推理开销。
最后,为了确保实用且非侵入式的用户体验,UFO²引入了一个新的画中画(PiP)接口:一个安全的嵌套桌面环境,代理可以在其中独立于用户的主会话执行。基于Windows的原生远程桌面回环基础设施,PiP允许用户代理在用户的主要桌面上无中断地并行操作,解决了现有CUA中最持久的用户体验限制之一。
共同作用下,这些设计原则使UFO²不仅仅是一个更智能的代理,而且是一种新的OS级别抽象,用于自动化——将桌面工作流转变为可编程、可组合且稳健的实体。总而言之,本文做出了以下贡献:
- 深度OS集成:我们设计并实现了UFO²,一个多代理AgentOS,深嵌于Windows OS中,通过内省、API访问和精细的执行控制来协调桌面应用程序。
-
- 统一GUI-API动作层:我们提出了一个混合动作接口,将传统的GUI交互与应用程序原生API调用桥接起来,实现灵活、高效且稳健的自动化。
-
- 混合控制检测:我们引入了一种融合管道,结合UIA元数据与基于视觉的检测,即使在非标准界面中也能实现可靠的控制定位。
-
- 持续知识整合:我们建立了一个检索增强型记忆体,整合文档和历史执行日志,允许代理在不重新训练的情况下自主改进。
-
- 投机性多动作执行:我们通过预测和验证动作序列提前使用UI状态信号来减少LLM调用开销。
-
- 非干扰式用户体验:我们开发了一个嵌套的虚拟桌面环境,允许自动化与用户活动并行进行,避免干扰并提高采纳度。
-
- 全面评估:我们在20多个实际的Windows应用程序上评估了UFO²,显示与最先进的CUA(如Operator)相比,在成功率、执行效率和可用性方面的一致改进。
总体而言,UFO²通过将自动化范式从GUI脚本转移到结构化、可编程的应用程序控制,推动了OS原生自动化的愿景。即使与通用模型如GPT-40配对,UFO²的表现也比专用CUA高出超过10%,突显了系统级集成和架构设计的变革性影响。
- 全面评估:我们在20多个实际的Windows应用程序上评估了UFO²,显示与最先进的CUA(如Operator)相比,在成功率、执行效率和可用性方面的一致改进。
2 背景
2.1 传统桌面自动化的脆弱性
几十年来,桌面自动化依赖于脆弱的技术来复制人类与基于GUI的应用程序的交互。商业RPA(机器人流程自动化)工具——如UiPath [1]、Automation Anywhere [2] 和Microsoft Power Automate [3]——通过记录和重放鼠标移动、按键或基于规则的脚本来操作。这些系统高度依赖表面级GUI提示(例如像素区域、窗口标题),对应用程序状态提供的洞察很少。
尽管在企业环境中广泛部署,传统的RPA系统表现出较差的鲁棒性和可扩展性 [19]。即使是轻微的UI更新——比如重新排列按钮或重新标记菜单——都会悄无声息地破坏自动化脚本。维持正确性需要频繁的人工干预。此外,这些工具缺乏对应用程序工作流的语义理解,无法推理或适应新任务。因此,RPA工具仍局限于稳定环境中的狭窄、重复工作流,远未达到通用自动化。
2.2 计算机使用代理的兴起
大型语言模型(LLMs)和多模态感知的最新进展启用了一种新的自动化系统类别,称为计算机使用代理(CUAs)[79]。CUAs旨在通过利用LLMs解释用户指令、感知GUI布局并合成诸如点击和按键之类的动作来跨应用程序和任务进行泛化。早期的CUAs如UFO [10]展示了多模态模型(例如GPT-4V [20])可以将自然语言请求映射到GUI动作序列,而无需手工制作的脚本。更近期的行业原型,包括Claude3.5(计算机使用)[11]和OpenAI Operator [12],进一步推动了这一边界,在多个应用程序中执行现实的桌面工作流。
这些CUAs代表了从静态RPA脚本到自适应、通用目的自动化的有希望的进化。然而,尽管它们复杂,当前的CUA主要仍是研究原型,受制于阻碍实际部署的架构和系统级限制。
2.3 CUAs中的系统挑战
当前的CUA在三个方面存在根本不足,我们认为这些不足源于缺少操作系统抽象:
(1) 缺乏OS级集成。大多数CUA通过截图和低级输入仿真(鼠标和键盘事件)与系统交互。它们忽略了丰富的系统接口,如可访问性API、应用程序进程状态和本地进程间通信机制(例如shell命令、COM接口[21])。这种表层交互模型限制了可靠性和效率——每个动作都必须从像素中推断出来,而不是从结构化状态中得出。
(2) 缺乏应用程序内省。CUA通常作为对应用程序特定功能了解有限的通才操作。它们将所有接口视为统一的,无法利用内置API或供应商文档。结果是,除非这些流程明确嵌入模型中,否则它们无法推理高层次概念。这种僵化限制了其泛化能力并使维护成本高昂。
(3) 干扰且不安全的执行模型。大多数CUA直接在用户的桌面会话上驱动自动化,劫持真实的鼠标和键盘。这种设计阻止用户在执行期间与系统交互,引入干扰风险,并违反安全系统设计的基本隔离原则。长时间运行的任务——尤其是涉及多次LLM查询的任务——可能会占用会话数分钟之久。
2.4 缺失的抽象:OS对自动化的支持
尽管对智能、语言驱动的自动化需求不断增长,现有的操作系统并未提供将GUI应用程序控制暴露给外部代理的第一类抽象。与系统调用、文件或套接字相反,GUI工作流仍然是不透明和不可编程的。结果,无论是RPA还是CUA系统都被迫作为GUI之上的临时层操作,没有统一的基底用于执行、协调或内省。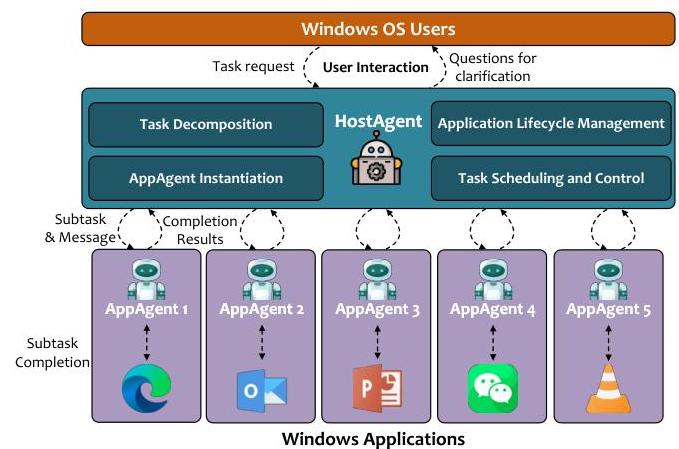
图2. UFO2\mathrm{UFO}^{2}UFO2体系结构概述。
本文认为自动化应提升为系统原语。我们提出了UFO 2^{2}2,一种新的Windows AgentOS,通过将自动化作为深度集成的OS抽象来解决这些问题——暴露GUI控件、应用程序API和任务协调作为可编程、可检查和可组合的系统服务。
3 系统设计 UFO2\mathrm{UFO}^{2}UFO2
鉴于第2节中强调的挑战,UFO2\mathrm{UFO}^{2}UFO2旨在无缝解释自然语言用户请求,并可靠地在广泛的Windows应用程序中自动化任务。本节提供了一个 UFO2\mathrm{UFO}^{2}UFO2 的架构概述(第3.1节),并解释了每个组件如何与底层操作系统深度集成以克服当前CUA的缺陷,最终实现实用且稳健的桌面自动化AgentOS。
3.1 UFO 2^{2}2作为自动化系统基底
图2展示了UFO2\mathrm{UFO}^{2}UFO2的高层架构,它为Windows桌面上的任务导向自动化提供了结构化的运行时环境。作为本地守护进程部署,UFO2\mathrm{UFO}^{2}UFO2使用户能够发出自然语言请求,这些请求被转换为跨越多个GUI应用程序的协调工作流。该系统提供了协调、内省、控制执行和代理协作的核心抽象,将这些作为类似于传统操作系统中的系统级服务公开。
UFO2\mathrm{UFO}^{2}UFO2的核心是一个中央控制平面,即HostAgent,负责解析用户意图、管理系统状态并将子任务分派给一组称为AppAgent的专门运行时模块。每个AppAgent专属于某个应用程序(例如Excel、Outlook、文件资源管理器),封装了观察和控制该应用程序所需的所有逻辑,包括API绑定、UI检测器和知识库。这些模块充当具有应用程序特定语义的隔离执行上下文。
当收到用户请求时,HostAgent将其分解为一系列子任务,每个子任务映射到最适合完成它的应用程序。如果相应应用程序尚未运行,HostAgent使用原生Windows API启动它并实例化相应的AppAgent。执行通过一个结构化循环进行:每个AppAgent连续观察应用程序状态(通过可访问性API和基于视觉的检测器),使用类似ReAct的规划周期推理下一步操作,并调用适当的动作——要么是GUI事件,要么是原生API调用。此循环继续直到子任务终止,成功或由于无法恢复的错误。
UFO2\mathrm{UFO}^{2}UFO2通过全局黑板接口实现共享内存和控制流,允许HostAgent和AppAgent交换中间结果、依赖状态和执行元数据。这种架构支持跨越应用程序边界的复杂工作流——例如,从电子表格中提取数据并用于填充网页表单——而无需手写脚本或协调逻辑。关键的是,所有交互都在虚拟化的、基于PiP的桌面环境中进行,确保进程级隔离和安全的多应用程序并发。
设计理由:集中式多代理运行时。UFO2\mathrm{UFO}^{2}UFO2采用集中式多代理[10, 23-25]运行时以支持可靠性和可扩展性。集中式的HostAgent充当控制平面,简化任务级编排、错误处理和生命周期管理。同时,每个AppAgent被设计为松耦合的执行器,封装了深层的应用程序特定功能。
AppAgent级别的模块化允许开发者和第三方贡献者通过编写新的应用程序接口和API绑定来逐步扩展UFO2\mathrm{UFO}^{2}UFO2的功能。这些代理是可发现的、自包含的,并由运行时根据需要动态实例化。从安全性和可演化性的角度来看,这种职责分离确保应用程序逻辑可以独立于核心任务编排引擎进行演进。
总之,HostAgent - AppAgent模型允许UFO 2^{2}2作为一个可扩展、可插拔的GUI自动化运行时基底——抽象掉异构接口的复杂性,并提供统一的系统接口来访问结构化应用程序行为。
3.2 HostAgent: 系统级编排和执行控制
HostAgent充当UFO2\mathrm{UFO}^{2}UFO2的集中控制平面。它负责解释用户指定的目标,将其分解为结构化的子任务,实例化和分发AppAgent模块,并协调其在整个系统中的进度。HostAgent提供系统级服务用于内省、规划、应用程序生命周期管理和多代理同步。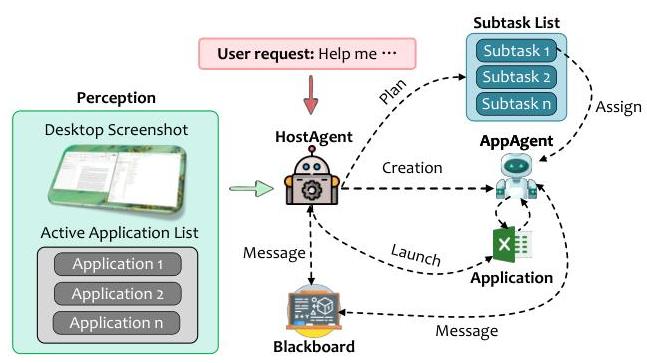
图3. HostAgent作为控制平面编排器的高层架构。
图3概述了HostAgent的架构。在原生Windows基底之上运行,HostAgent监控活跃应用程序,根据需要发出shell命令以生成新进程,并管理特定应用程序AppAgent实例的创建和销毁。所有协调均通过持久状态机进行,该状态机管理执行阶段间的转换。
责任和接口。HostAgent暴露以下系统服务:
- 任务分解。给定用户的自然语言输入,HostAgent识别潜在任务目标并将其分解为依赖有序的子任务图。
-
- 应用程序生命周期管理。对于每个子任务,HostAgent通过UIA API检查系统进程元数据以确定目标应用程序是否正在运行。如果不是,则启动程序并将其注册到运行时。
-
- AppAgent实例化。HostAgent为每个活动应用程序生成相应的AppAgent,为其提供任务上下文、内存引用和相关工具链(例如API、文档)。
-
- 任务调度和控制。全局执行计划被序列化为有限状态机(FSM),允许HostAgent强制执行顺序、检测失败并解决代理间的依赖关系。
-
- 共享状态通信。HostAgent读取和写入全局黑板,启用代理间通信和系统级调试和重放的可见性。
系统感知和内省。为了执行其控制功能,HostAgent融合了两层系统内省:
- 共享状态通信。HostAgent读取和写入全局黑板,启用代理间通信和系统级调试和重放的可见性。
- 视觉层。捕获桌面工作区的像素级截图,实现粗粒度布局理解。
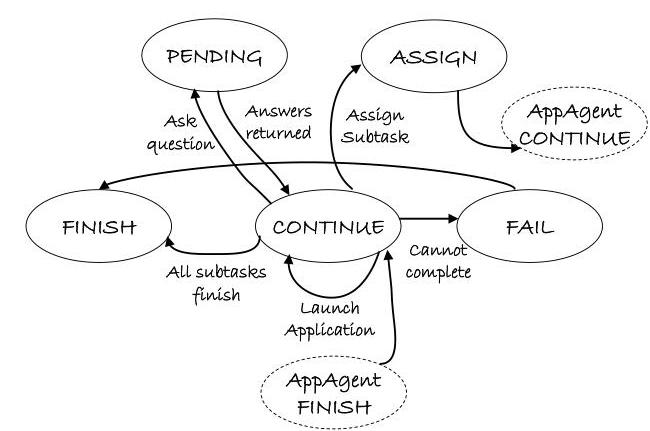
图4. HostAgent管理的控制状态转换。- 语义层。查询Windows UIA API以提取有关应用程序、窗口和控件层次结构的结构化元数据。
- 这种双重感知使HostAgent能够解决歧义、检测运行时不一致并以情境感知的方式指导代理。
结构化输出接口。HostAgent产生结构化输出以驱动下游执行:
-
子任务计划:详细的分解子任务执行计划。
-
- Shell命令:用于管理应用程序生命周期的一系列shell级调用。
-
- 分配的应用程序:用于实例化AppAgent并执行下一个子任务的应用程序的进程名和索引。
-
- 代理消息:传递给AppAgent实例的上下文特定指令以进行局部执行。
-
- 用户提示:在歧义或失败情况下的交互式澄清请求。
-
- HostAgent状态:HostAgENT内部FSM中的当前状态。
通过有限状态控制器执行。HostAgent的核心逻辑被建模为有限状态控制器(图4),具有以下状态:
- HostAgent状态:HostAgENT内部FSM中的当前状态。
-
CONTINUE:主执行循环;评估哪些子任务准备就绪以启动或恢复。
-
- ASSIGN:选择可用的应用程序进程并生成相应的AppAgent代理。
-
- PENDING:等待用户输入以解决歧义或收集额外的任务参数。
-
- FINISH:所有子任务完成;清理代理实例并最终确定会话状态。
-
- FAIL:在不可恢复的失败时进入恢复或中止模式。
-
这种明确的FSM结构使HostAgent能够稳健地编排动态工作流,同时在任务完成和故障隔离方面保持高级别的保证。
-
内存和状态管理。HostAgent维护两类持久状态:
-
私有状态:跟踪用户意图、计划进度和当前会话的控制流。
-
- 共享黑板:一个并发的、只追加的内存空间,通过记录关键观察、中间结果和可供所有AppAgenT实例访问的执行元数据,促进透明的代理通信。
这种分离确保了本地上下文保持封装,同时全局协调在系统中保持可见和一致。这种分离确保每个代理保留干净、范围明确的状态,同时受益于全球一致视图以进行协作任务执行。
- 共享黑板:一个并发的、只追加的内存空间,通过记录关键观察、中间结果和可供所有AppAgenT实例访问的执行元数据,促进透明的代理通信。
总体而言,HostAgent抽象掉了在桌面环境中管理并发、有状态、跨应用程序工作流的复杂性[26]。其控制平面角色实现了模块化执行、协调进展和稳健的任务生命周期管理——这些都是在实际部署中扩展桌面自动化的最关键特征。
3.3 AppAgent: 应用程序专业化的执行运行时
AppAgent 是 UFO2\mathrm{UFO}^{2}UFO2 中的核心执行运行时,负责在特定的 Windows 应用程序中执行单独的子任务。每个 AppAgent 作为由中心 HostAgent(第 3.2 节)启动和协调的独立、应用程序专业化的工作者进程运行。与对待所有 GUI 上下文相同的单一整体 CUA 不同,每个 AppAgent 都针对单个应用程序进行了调整,并对其 API 表面、控件语义和领域逻辑有深入的了解。
图 5 描述了 AppAgent 的架构。在从 HostAgent 接收子任务和执行上下文后,AppAgent 初始化一个 ReAct 风格的控制循环[22],在此循环中,它迭代地感知当前应用程序状态,推理下一步操作,并执行 GUI 或 API 基础动作。通过 Puppeteer 接口实现的这种混合执行层通过优先使用结构化 API(必要时保留 GUI 基础交互的回退)实现了对动态和复杂 UI 的可靠控制。
感知层。每个 AppAgent 融合了多种感知流:
- 视觉输入:捕获 GUI 截图以理解和定位控件。
-
- 语义元数据:从 Windows UIA API 提取,包括控件类型、标签、层次结构和启用状态。
-
- 符号注释:使用 Set-of-Mark (SoM) 技术[27] 对截图中的控件进行注释。
这些融合信号被转换为包含 GUI 截图和候选控件元素集的结构化观察对象。这种多模态表示使应用程序状态的理解更加全面,远远超出了单纯的视觉输入。
- 符号注释:使用 Set-of-Mark (SoM) 技术[27] 对截图中的控件进行注释。
结构化输出。基于这种状态,AppAgent 产生结构化输出:
- 目标控件(如有适用)
-
- 动作类型(例如点击、键入、调用 API)
-
- 参数或有效负载
-
- 链式思考 (CoT) [28,29] 的推理痕迹和规划
-
- 当前状态在本地 FSM 中
这种设计将感知与动作解耦,实现了确定性重播、离线调试和细粒度可观测性。
- 当前状态在本地 FSM 中
通过有限状态控制器执行。每个 AppAgent 维护一个本地有限状态机(图 6),以管理其在分配的应用程序上下文中的行为:
-
CONTINUE:默认状态用于动作规划和执行。
-
- PENDING:针对安全关键动作(例如破坏性操作);需要用户确认。
-
- FINISH:任务完成;执行结束。
-
- FAIL:检测到不可恢复的失败(例如应用程序崩溃、权限错误)。
-
这种有界执行模型将失败隔离到当前任务,并允许安全的抢占、重试或委派。FSM 还支持可中断的工作流,可以从中间检查点恢复。
内存和状态协调。为了实现有状态执行并保持上下文感知,每个 AppAgent 维护: -
私有状态:本地记录所有已执行动作、控件决策和 CoT 踪迹。
-
- 共享状态:更新系统范围的黑板,包括中间输出、遇到的错误和应用程序级见解。
-
这种双内存设计使 AppAgents 能够在代表 HostAgent 的情况下自主行动,同时与更大的系统保持同步。它还支持组合性:一个 APPAgent 的输出可能成为另一个下游子任务的输入。
应用程序感知 SDK 和可扩展性。为了支持快速接纳新应用程序,UFO2\mathrm{UFO}^{2}UFO2 提供了一个封装 AppAGENTS 开发和维护的 SDK。开发人员可以通过声明性接口注册应用程序特定的 API,包括函数元数据、参数模式和提示绑定。领域特定的帮助文档和补丁说明可以被摄取到一个可搜索的知识库中,代理在运行时查询该知识库。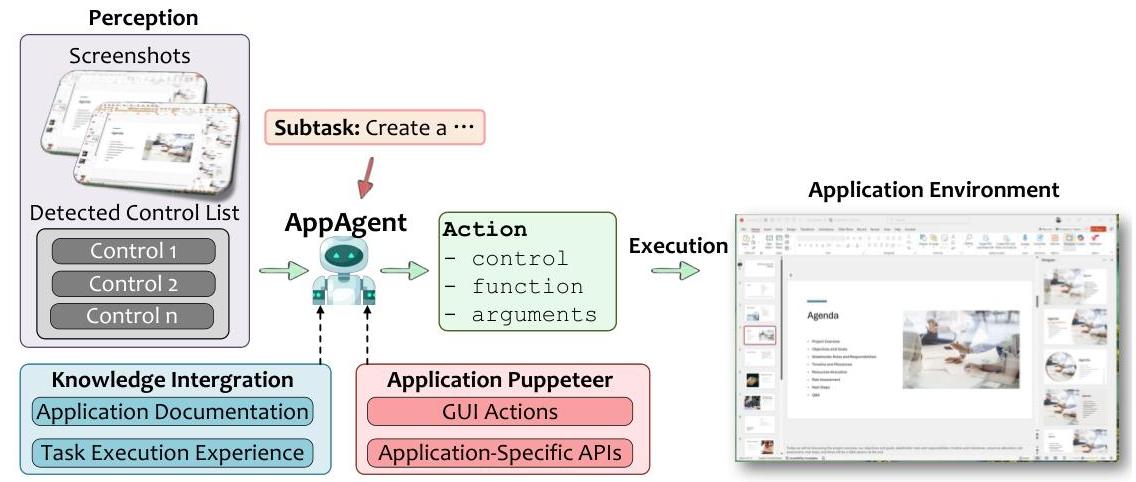
图 5. 在 UFO2\mathrm{UFO}^{2}UFO2 中每个应用程序执行运行时的 AppAgent 架构。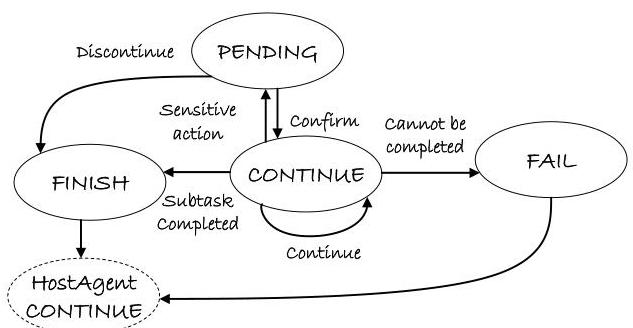
图 6. AppAgent 运行时的控制状态转换。
这种模块化抽象允许第三方厂商或高级用户在无需重新训练任何模型的情况下扩展 UFO 2{ }^{2}2 的功能。通过更新应用程序的 AppAgent 模块可以集成新功能,将更改与其他系统隔离,从而最小化回归风险。
总结。作为每个应用程序的执行运行时,每个 APPÄGENT 提供了模块化、领域感知的控制,超越了通用 GUI 代理在效率和稳健性方面的表现。其混合感知-动作循环、插件式可扩展性和本地故障包容性使 UFO2\mathrm{UFO}^{2}UFO2 能够在最小的系统级干扰下扩展到大型应用程序生态系统。
3.4 混合控制检测
可靠感知GUI元素是使APPAGENTS能够以确定和安全方式与应用程序界面交互的基础。然而,现实世界的GUI环境表现出显著的异质性:一些应用程序通过Windows UI Automation(UIA)API暴露良好结构的可访问性数据,而另一些应用程序——特别是旧版或自定义应用程序——则使用绕过UIA的非标准工具包渲染关键控件。
为了解决这种差异,UFO 2{ }^{2}2引入了一个混合控制检测子系统,将UIA基础元数据与
基于视觉的定位技术融合在一起[18,30,31],为每个应用程序窗口构建统一且全面的控件图(图7)。这种设计确保了覆盖和可靠性,为下游动作规划和执行奠定了坚固的感知基础。
UIA层检测。当可用时,UIA提供了一个语义丰富且高精度的接口,用于枚举屏幕上的控件。检测管道首先查询可访问性树,以提取满足一组运行时谓词(例如is_visible()、is_enabled())的控件。这些控件被标注其属性(类型、标签、边界框)并分配稳定的标识符,形成初始控件图。
视觉层增强。为了增强对UI不可见或自定义渲染控件的感知管道,我们集成了OmniParser-v2[18],这是一种专为快速准确的GUI解析而设计的基于视觉的定位模型。OmniParserv2结合了一个轻量级YOLO-v8[32]检测器和一个经过微调的Florence-2(0.23B)[33]编码器来处理应用程序截图并识别附加的交互元素。每次检测包括控件类型、置信度分数和空间边界框。
融合和去重。我们通过基于边界框重叠进行去重来统一这两条流。视觉检测与任何UIA派生控件的Intersection-over-Union (IoU)大于10%10 \%10%的被丢弃。剩余的纯视觉检测通过轻量级UIAWrapper抽象转换为伪UIA对象,使其能够无缝集成到其余的APPÄGENT管道中。这个融合的控件集被传递到基于SoM的注释模块[27]。图7显示了一个涉及混合渲染GUI的典型场景。黄色边界框表示标准UIA检测的元素,而蓝色边界框表示纯视觉检测。两者都被集成到一个单一的可控控件图中,由APPAgent消费。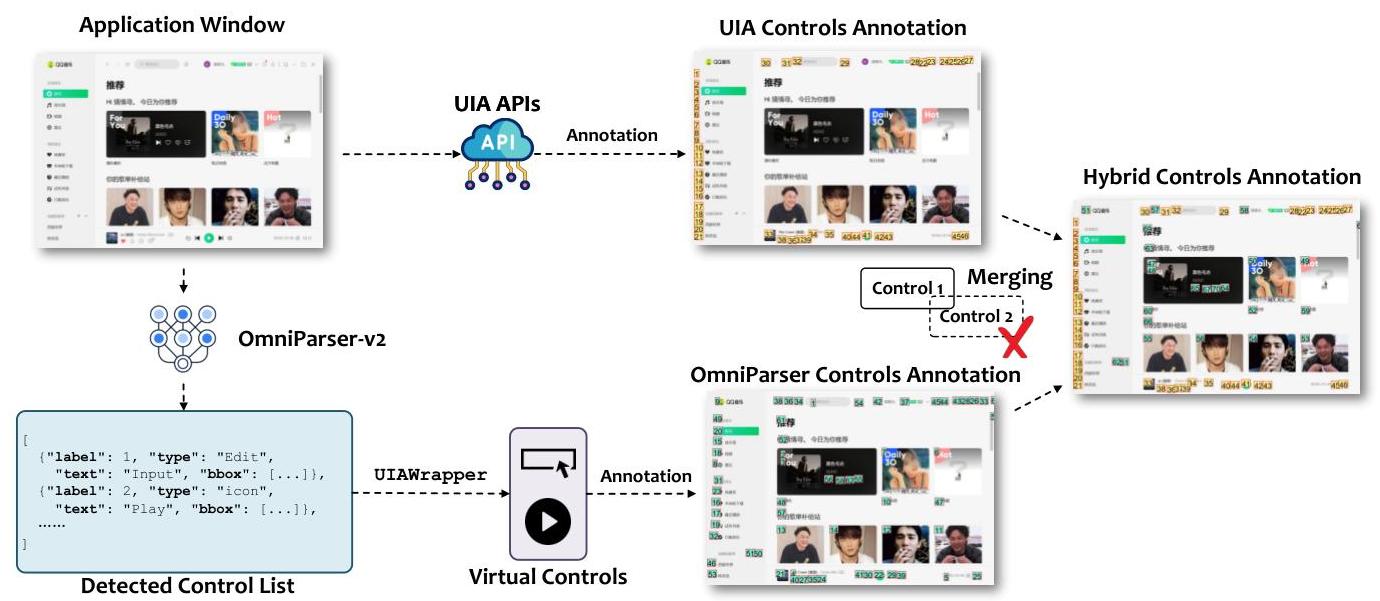
图7. UFO2\mathrm{UFO}^{2}UFO2中采用的混合控制检测方法。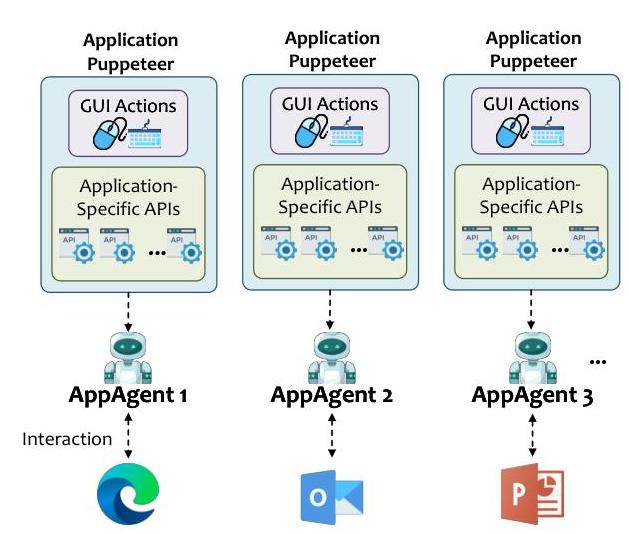
图8. Puppeteer作为一个统一的执行引擎,协调GUI动作和原生API调用。
3.5 统一GUI-API动作协调器
AppAgents可以与两种不同的接口进行交互:普遍可观察但往往脆弱的GUI前端,以及高保真但需要明确集成的原生API[17]。为了在单一运行时抽象下统一这些异构执行后端,UFO2\mathrm{UFO}^{2}UFO2引入了Puppeteer,这是一个模块化的执行协调器,它动态选择GUI级自动化和应用程序特定API来进行每一步动作(图8)。这种设计显著提高了任务的健壮性、延迟和可维护性。原本需要长GUI交互序列的任务(例如在Excel中迭代选择和格式化单元格)通常可以压缩成一个API
@ExcelWinCOMReceiver.register
class SelectTableRangeCommand:
def execute(self) -> Dict[str, str]:
return {“results”:… “error”:…}
@classmethod
def name(cls) -> str:
return “select_table_range”
图9. Excel的示例API注册。
调用,减少执行时间和失败表面面积[17,34]。
Puppeteer支持一个轻量级API注册机制,使开发人员能够暴露目标应用程序中的高级操作。API通过简单的Python装饰器接口注册,如图9所示。每个函数都包装了元数据——名称、参数模式和应用程序绑定——并自动纳入AppAgent的运行时动作空间。
在运行时,UFO2\mathrm{UFO}^{2}UFO2提示AppAgent采用决策策略为每个操作选择最合适的执行路径。如果有语义等效的API可用,Puppeteer优先选择GUI自动化以确保可靠性和原子性。如果API失败或不可用(例如缺少绑定或运行时权限错误),系统会优雅地回退到通过模拟点击或按键进行GUI控制。这种运行时灵活性使AppAgent能够在保持通用性的同时在异构环境中保持健壮性。
Puppeteer将UFO2\mathrm{UFO}^{2}UFO2中的动作执行从单片GUI为中心的模型转变为灵活、OS集成的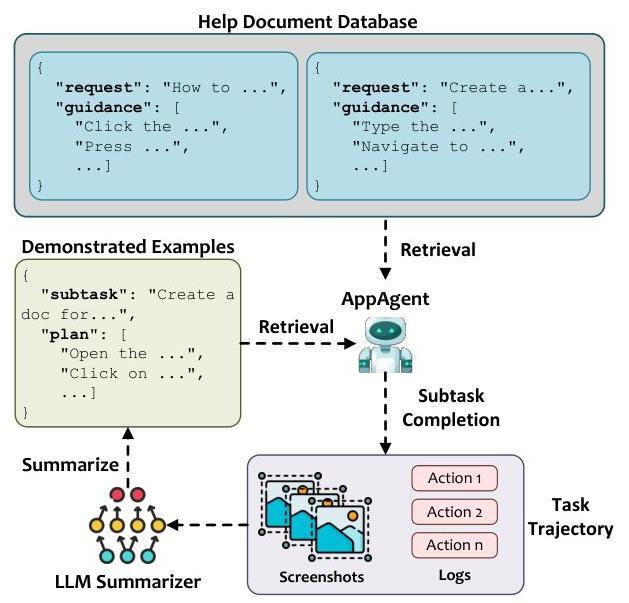
图10. UFO2\mathrm{UFO}^{2}UFO2中的知识基,结合静态文档与动态执行历史。
控制层,将感知敏捷性与语义精确性相结合。这种混合执行模型不仅提高了系统性能和稳定性,还为未来桌面代理中应用特定功能的可持续集成奠定了基础。
3.6 持续知识集成基底
与依赖静态训练语料的传统CUA不同,UFO2\mathrm{UFO}^{2}UFO2引入了一个持久且可扩展的知识基底,支持运行时增强应用程序特定理解。如图10所示,这个基底使每个AppAgent能够在无需重新训练底层模型的情况下检索、解释和应用外部文档及之前的执行轨迹。这种混合内存设计类似于OS级别的元数据管理器,抽象出两个关键知识流:静态参考(例如用户手册)和动态经验(例如执行日志)。
引导来自文档。大多数现实世界桌面应用程序通过用户指南、帮助菜单或在线教程暴露大量任务级文档。UFO 2{ }^{2}2通过提供一键界面来解析和摄取此类文档到应用程序特定的向量存储中,充分利用了这一资源。文档被结构化为json记录,其中请求字段包含自然语言描述,指导字段包含详细的执行指导。
在运行时,当AppAgent接收子任务时,它查询这个索引存储以检索相关指导,然后将其注入到代理的提示中。这种机制有效地缓解了冷启动问题——特别是在处理新应用程序或不常见操作时——通过丰富代理的推理上下文以领域为基础的过程知识。
从经验中强化。除了静态知识,UFO2\mathrm{UFO}^{2}UFO2还从其自身的执行历史中持续学习。每次自动化运行都会产生结构化日志——包括自然语言任务描述、执行的动作序列、应用程序截图和最终结果。定期地,这些日志由摘要模块离线挖掘,将成功的轨迹提炼为可重用的Example记录。
每个记录包含任务签名和关联的分步计划,存储在应用程序特定的示例数据库中。当未来遇到类似的任务时,AppAgent使用上下文学习(ICL)[35-38]检索相关演示并提高执行保真度。这种动态强化管道将系统转变为一个长期使用的代理,随着使用而改善,而不引入微调的脆弱性或运营成本[39]。
运行时RAG集成。在系统级别,知识基底充当连接预训练语言模型和应用程序特定要求的检索增强生成(RAG)层[40-43]。由于帮助文档和示例都使用语义嵌入索引,检索管道快速、可解释且缓存友好。此外,版本化索引确保知识工件能够随软件更新而演变,防止模型过时并支持在长时间部署周期内的稳健执行。
通过将静态和体验知识集成到统一的RAG管道中,UFO2\mathrm{UFO}^{2}UFO2将CUA从脆弱的训练时间构造转变为动态、进化的代理。这个基底在复杂的异构应用程序生态系统中实现可持续自动化起着基础性作用。
3.7 投机性多动作执行
传统的CUA遭受基本的执行瓶颈:每个自动化步骤都是孤立执行的,每个GUI动作都需要完整的LLM推理。这种逐步推理循环引入了过多的延迟,增加了系统资源使用,并提高了累积错误率——特别是在与复杂或多阶段工作流交互时[17]。根本原因是GUI环境的动态和不确定性,任何单一动作都可能改变界面并使未来的计划失效。
为克服这些限制,UFO2\mathrm{UFO}^{2}UFO2引入了一个系统级优化,称为投机性多动作执行,灵感来源于处理器设计中的经典投机执行和指令流水线思想。与其每次LLM调用只发布一个动作,UFO2\mathrm{UFO}^{2}UFO2投机性地生成一批可能的下一步动作,使用单次推理并通过紧密的OS集成验证其适用性。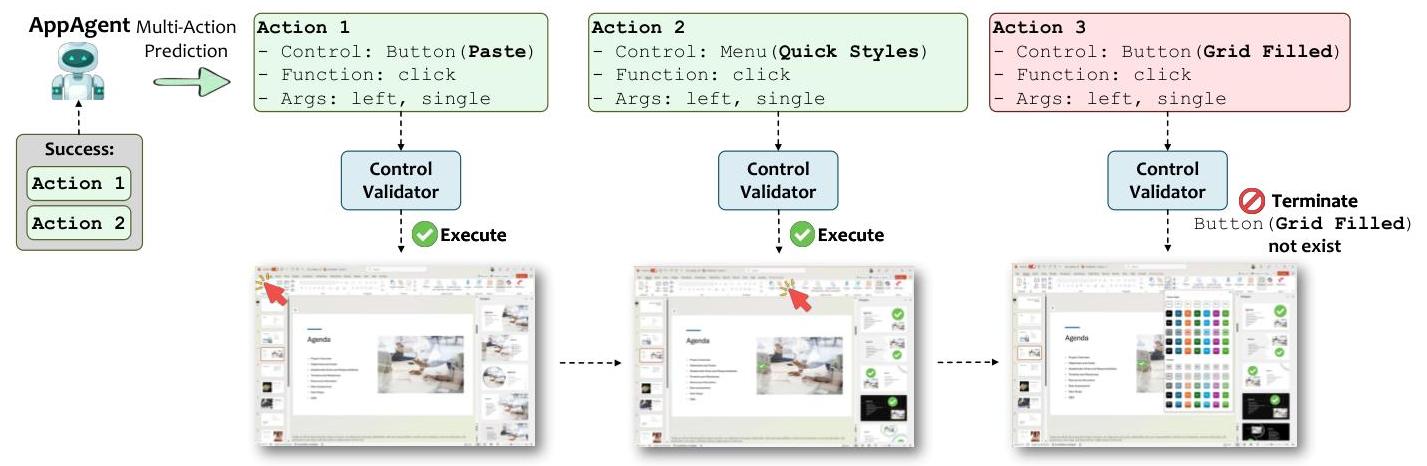
图11. UFO2\mathrm{UFO}^{2}UFO2中的投机性多动作执行:批量推理与在线验证。
算法1 UFO 2{ }^{2}2中的投机性多动作执行
输入:初始UI上下文C0C_{0}C0,批大小kkk
输出:已完成动作列表Executed
第1阶段:批量预测
A←LLM−PrEdict(C0,k)▹A=[(ctrli,opi]i=1kA \leftarrow \operatorname{LLM}_{-}\operatorname{PrEdict}\left(C_{0}, k\right) \quad \triangleright A=\left[\left(\operatorname{ctrl}_{i}, o p_{i}\right]_{i=1}^{k}\right.A←LLM−PrEdict(C0,k)▹A=[(ctrli,opi]i=1k
Executed ←[];C←C0\leftarrow[] ; \quad C \leftarrow C_{0}←[];C←C0
第2&3阶段:顺序验证-执行循环
for i←1i \leftarrow 1i←1 to kkk do
( ctrl,op, −)←A[i](\text { ctrl,op, }\left._{-}\right) \leftarrow A[i]( ctrl,op, −)←A[i]
// 在当前上下文中验证
if not UIA_IsEnabled(ctrl,C) ∨\vee∨ not
UIA_IsVisible(ctrl, CCC ) then
break ▹\quad \triangleright▹ 验证失败 →\rightarrow→ 提前停止
end if
// 执行并刷新上下文
Execute(ctrl,op)
append (ctrl,op) to Executed
C←C \leftarrowC← UIA_GetContext() ▹\quad \triangleright▹ UI 改变
end for
if |Executed| < k then
ReportPartial(Executed)
RePlan (C)(C)(C)
end if
通过紧密的OS集成验证它们的适用性。我们展示了一个算法1。
投机执行器分为三个阶段操作:
- 动作预测:AppAgent发起一次LLM查询,预测当前上下文下的多个可能动作。每个预测步骤包括目标控件、预期操作和理由。
-
- 运行时验证:对于每个动作,系统咨询Windows UIA API以验证动作的前提条件(例如is_enabled(), is_visible())。这
- 检查确保每个目标控件仍然有效且可交互。
-
- 顺序执行和提前退出:按顺序执行动作,如果因界面变化导致任何验证失败(例如控件不再存在或被禁用),立即停止。执行器随后报告部分结果集并提示代理重新规划。
我们在图11中展示了投机性多动作执行的一个示例。在这种情况下,AppAgent最初计划一次性执行三个动作:点击Paste,然后Quick Style,最后Grid Filled。然而,在第二个动作之后,控件验证器检测到第三个动作所需的控件(Grid Filled)不再存在——可能是由于前一步骤导致GUI布局发生变化。此时,Puppeteer终止执行并返回部分结果。这个例子展示了UFO2\mathrm{UFO}^{2}UFO2如何通过在执行前验证每个控件来安全地处理投机性执行,确保即使面对动态界面变化也能保持稳健性。
- 顺序执行和提前退出:按顺序执行动作,如果因界面变化导致任何验证失败(例如控件不再存在或被禁用),立即停止。执行器随后报告部分结果集并提示代理重新规划。
总体而言,这种策略大大减少了LLM调用频率,并将动作规划的成本分摊到多个步骤中,同时保留了每步验证的正确性保证。关键的是,验证是由可信的OS级API而非视觉模型执行,确保高可靠性和消除不必要的交互。
4 图中图界面
UFO2\mathrm{UFO}^{2}UFO2的一个关键设计目标是在交付高吞吐量自动化的同时保持主桌面环境的响应性和可用性。现有的CUA常常垄断用户的办公空间,长时间占据鼠标和键盘控制,使系统在任务执行期间实际上无法使用。为克服这一点,FO²引入了画中画(PiP)界面:一个由远程桌面回环支持的轻量级虚拟化桌面窗口,允许在与活动用户工作流并行时完全隔离地执行代理,如图12所示。
4.1 最小干扰的虚拟化用户环境
与在主桌面会话中运行的传统CUA不同,PiP界面呈现一个可调整大小、可移动的窗口,包含用户桌面的功能复制品。内部实现上,这是通过Windows原生远程桌面协议(RDP)回环[44]创建的一个独立虚拟会话,托管在同一台机器上。在PiP会话中启动的应用程序继承用户的标识、凭据、设置和网络上下文,确保与前台操作的一致性。
从用户的角度来看,PiP窗口表现得像一个沙盒化的工作空间:自动化在后台执行,可见但不显眼。用户保留对主桌面的完全控制,并可以随意最小化或重新定位PiP窗口。这使得UFO2\mathrm{UFO}^{2}UFO2能够在不影响用户交互或降低响应能力的情况下执行长时间或重复的工作流(例如数据录入、批处理文件操作)。
4.2 坚固的输入和状态隔离
为了确保代理动作和用户活动之间的牢固分离,UFO2\mathrm{UFO}^{2}UFO2利用RDP子系统在会话之间维护不同的输入队列和设备上下文。在PiP桌面内生成的鼠标和键盘事件完全限定于该会话,不会干扰主桌面。类似地,GUI变化和焦点转换也被限制在虚拟环境中。
这种级别的输入隔离对于防止用户或代理的意外干扰至关重要,并确保即使在同时进行前台活动时,自动化序列也能保持稳定。架构还支持受控错误恢复:PiP会话中的故障或意外UI状态不会传播到主桌面,从而保护用户的环境完整性。
4.3 安全的跨会话协调
尽管视觉和操作上有所不同,PiP会话必须逻辑上连接到主机环境。为此,UFO2\mathrm{UFO}^{2}UFO2在PiP代理运行时和主机端协调器之间建立了一个安全的进程间通信(IPC)通道。我们使用Windows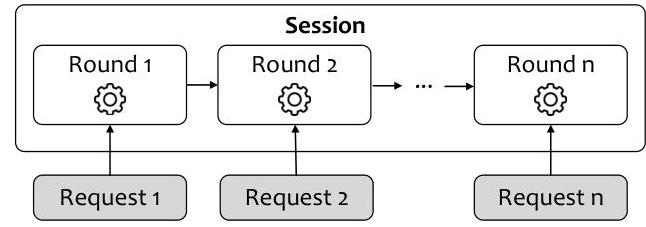
图13. UFO2\mathrm{UFO}^{2}UFO2中的交互会话模型支持多轮细化。
命名管道,使用每会话凭据进行身份验证和加密[45]。
这个IPC层支持双向消息传递:
- 从主机到PiP:任务分配、进度查询、取消和用户澄清。
-
- 从PiP到主机:状态更新、完成报告和异常通知。
用户通过主机桌面上的一个轻量级前端面板与自动化管道交互,无需直接访问PiP窗口即可实现实时可见性和部分控制。这种透明且安全的通信通道确保信任和可用性,特别是在长时间运行或部分监督的工作流中。
- 从PiP到主机:状态更新、完成报告和异常通知。
4.4 系统级影响
PiP界面不仅仅是一个用户体验改进——它是一个系统级抽象,调和了并发性、可用性和安全性。它将自动化执行与前景交互解耦,为基于GUI的代理引入了一种新的隔离原语,并通过沙箱化副作用简化了故障恢复。通过利用现有的RDP功能并以最小的系统开销,PiP界面提供了一种实用且向后兼容的大规模桌面自动化的途径。
5 实现与专门工程设计
我们将UFO2\mathrm{UFO}^{2}UFO2实现为一个涵盖超过30,000行Python和C#代码的全栈桌面自动化框架。Python作为代理编排、控制逻辑和API集成的核心运行环境,而C#支持GUI开发、调试接口和Windows特定操作,如画中画桌面。为了支持检索增强推理,UFO2\mathrm{UFO}^{2}UFO2利用Sentence Transformers [46]进行基于嵌入的文档和经验检索。
除了其核心功能外,UFO2\mathrm{UFO}^{2}UFO2还集成了多个专门的工程组件,针对关键系统目标:组合性、交互性、可调试性和可扩展部署。我们在下面重点介绍几个关键机制。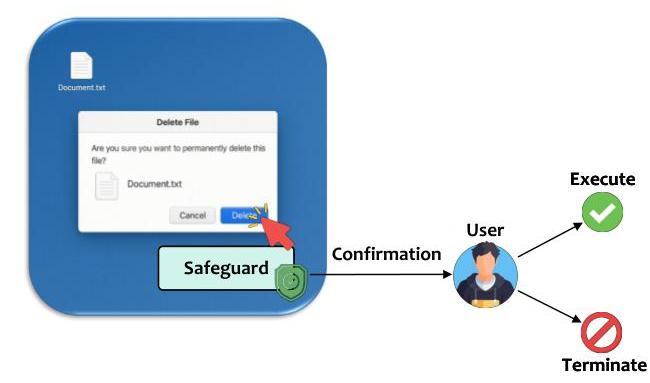
图14. UFO2\mathrm{UFO}^{2}UFO2中采用的安全机制。
5.1 多轮任务执行
与无状态的一次性代理不同,UFO2\mathrm{UFO}^{2}UFO2采用基于会话的执行模型来支持迭代和交互式工作流(图13)。每个会话在多个回合的执行中保持持久的上下文记忆——包括中间结果、任务进展和应用程序状态。用户可以细化之前的指令、启动后续任务或在代理遇到模糊或不安全操作时进行干预。
这种多轮交互范式有助于逐步收敛到复杂任务,同时保持透明度和人类监督。它使UFO2\mathrm{UFO}^{2}UFO2能够支持人机协作的细化策略,将静态LLM工作流与动态用户指导相结合。
5.2 安全机制
虽然自动化极大地提高了生产力,但任何CUA都存在执行不安全动作的内在风险,可能对用户数据或系统稳定性产生不利影响[10, 47]。示例包括删除关键文件、过早终止应用程序(导致未保存的数据丢失),或在没有明确同意的情况下激活敏感设备,如网络摄像头。这些动作存在严重风险,可能导致不可恢复的损害或安全漏洞。
为了缓解这些风险,UFO2\mathrm{UFO}^{2}UFO2纳入了一个显式的安全机制,旨在主动检测潜在的危险动作,如图14所示。具体而言,每当AppAgent识别出符合预定义风险标准的动作时,它就会进入专用的PENDING状态,暂停执行并积极提示用户确认。只有在收到明确的用户同意后,代理才会继续;否则,动作将被中止以防止伤害。构成危险动作的定义和范围可以通过简单的基于提示的接口完全自定义,使用户和系统管理员能够根据其组织的具体风险政策精确调整安全行为。这种灵活性使安全系统能够随着自动化需求的演变而动态适应。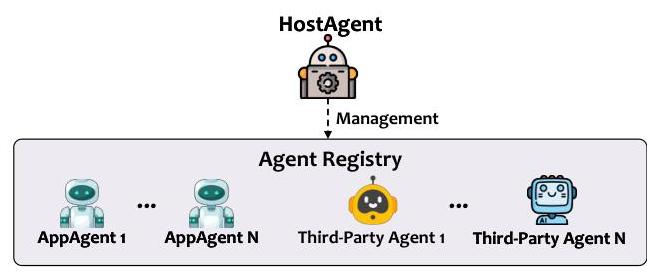
图15. 代理注册表支持将第三方组件无缝包装到AppAgent框架中。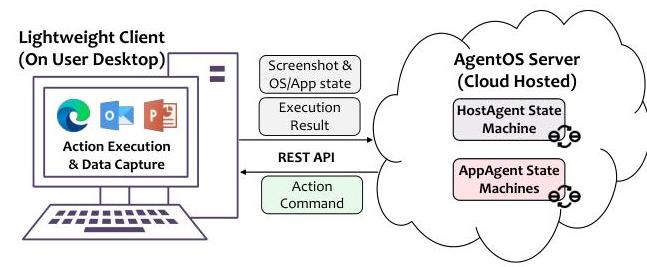
图16. AgentOS-as-a-Service使用的客户端-服务器部署模型。
通过这种主动的安全检查框架,UFO2\mathrm{UFO}^{2}UFO2显著降低了执行有害操作的可能性,从而增强了整体系统的安全性、用户信任和实际部署中的稳健性。
5.3 一切皆为AppAgent
为了支持生态系统可扩展性,UFO2\mathrm{UFO}^{2}UFO2引入了一种代理注册机制,将任意第三方组件封装为可插拔的AppAgents(图15)。通过简单的注册API,外部自动化解决方案——如领域特定的副驾驶或专有工具——可以包装轻量级兼容性适配器,向HostAgent暴露统一接口。
这种设计使HostAgent能够将本地和外部AppAgent视为等同,基于能力和专业化调度子任务。我们发现,即使是最低限度的包装器(例如OpenAI Operator [12])也能带来实质性的性能提升,突显了系统的模块化及其整合多种执行后端的能力,同时减少了工程开销。
5.4 AgentOS-as-a-Service
UFO2\mathrm{UFO}^{2}UFO2采用客户端-服务器架构以支持大规模的实际部署(图16)。轻量级客户端驻留在用户的机器上,负责GUI操作和应用侧感知。与此同时,集中式服务器(在本地或云端运行)承载HostAgent/Appagent逻辑,协调工作流并处理LLM查询。
这种控制和执行的分离提供了几个系统级的好处:
- 安全性:敏感的编排和模型执行与用户设备隔离。
-
- 可维护性:服务器端更新无需修改客户端即可传播。
-
- 可扩展性:系统可以通过集中调度和负载管理支持多个并发客户端。
客户端-服务器边界强制执行干净的服务抽象,促进模块化并简化企业环境中的推出。
- 可扩展性:系统可以通过集中调度和负载管理支持多个并发客户端。
5.5 全面的日志记录和调试基础设施
强大的可观测性对于诊断故障和支持持续的系统改进至关重要。为此,UFO2\mathrm{UFO}^{2}UFO2实现了全面的日志记录和调试框架。每个会话捕捉细粒度的执行跟踪:提示、LLM输出、控制元数据、UI状态快照和错误事件。
在每个会话结束时,UFO2\mathrm{UFO}^{2}UFO2将这些工件编译成结构化的Markdown格式执行日志。开发人员可以逐项检查代理决策,可视化界面状态转换,并重播行为以进行调试。该框架还支持提示编辑和选择性重播以进行有针对性的假设测试,显著加速了调试周期。我们在图17中展示了这些工具的示例。
这种可观测性层作为一个轻量级的代理行为溯源系统,促进了透明度、问责制和部署期间的快速迭代。
5.6 自动化任务评估器
为了提供结构化反馈并促进持续改进,UFO2\mathrm{UFO}^{2}UFO2包含了一个基于LLM的自动化任务评估引擎[48]。如图18所示,评估器解析会话跟踪——包括动作、理由和截图——并应用CoT推理将任务分解为评估标准。
它分配部分分数并合成总体结果:成功、部分或失败。这一结构化结果反馈到下游仪表板和调试工具中。它还支持自我监控和离线分析失败案例,闭环执行、诊断和改进过程。
总结。这些工程组件展示了UFO2\mathrm{UFO}^{2}UFO2对操作稳健性和可扩展性的承诺。从基于会话的执行和可插拔代理到面向服务的部署和可观测性基础设施,每个模块都反映了旨在弥合概念LLM代理架构与大规模部署系统现实的设计理念。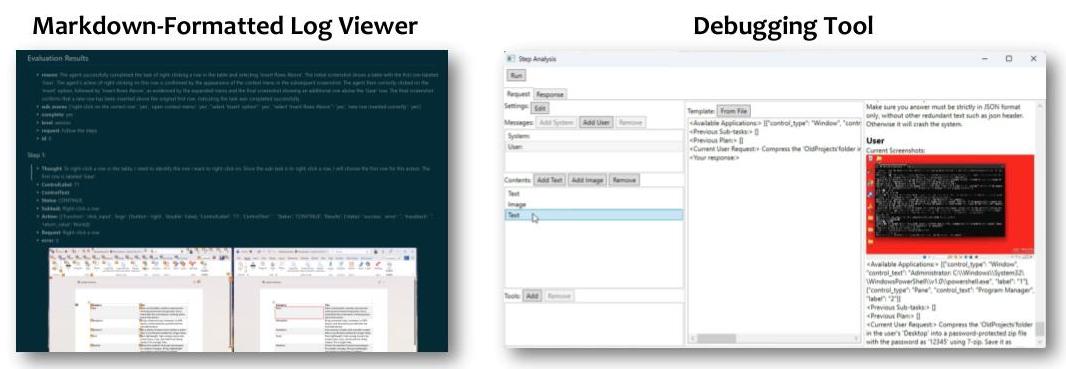
图17. UFO2\mathrm{UFO}^{2}UFO2中标记格式化的日志查看器和调试工具的插图。
任务轨迹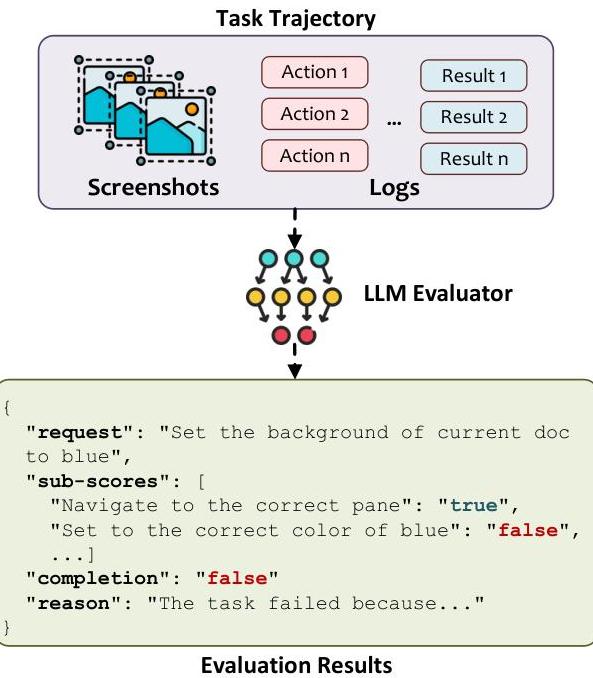
图18. 基于LLM的任务评估器将CoT推理应用于结构化的会话日志。
6 评估
我们在超过20个Windows应用程序上严格测试了UFO²,包括办公套件、文件资源管理器和自定义企业工具,以评估性能、效率和鲁棒性。我们的实验表明:
- UFO²实现了比当前最佳CUA Operator高10%的任务完成率,相对改进50%,这得益于更深层次的操作系统级集成。
-
- 混合UIA-视觉方法识别出单独使用UIA错过的自定义或非标准GUI元素,提升了具有专有小部件的界面的成功率。
-
- 允许AppAgents调用本地API或GUI交互,提高完成率超过8%,
- 减少延迟并降低纯粹基于点击的工作流的脆弱性。
-
- 利用外部文档和执行日志提高了UFO²处理不熟悉功能的能力,而无需重新训练。
-
- 投机性多动作执行将多个步骤合并为一次LLM调用,最多可降低51.5%的推理成本,且不牺牲可靠性。
-
- 通过启用Everything-as-an-APPAGENT(例如Operator),UFO²不仅提升了整体性能,还揭示了每个单独代理的全部潜力。
总体而言,这些结果证实了UFO²与Windows和应用程序级API的深度集成带来了更高的性能和更低的开销,为桌面自动化的OS原生方法提供了有力的理由。
- 通过启用Everything-as-an-APPAGENT(例如Operator),UFO²不仅提升了整体性能,还揭示了每个单独代理的全部潜力。
6.1 实验设置
部署环境。基准环境托管在具有8个AMD Ryzen 7 CPU核心和8 GB内存的隔离VM上,匹配典型的部署条件。所有GPT系列模型(GPT-4V、GPT-40、o1和Operator)均通过Azure OpenAI服务访问,而OmniParser-v2视觉模型则在一个配备NVIDIA A100 80GB GPU的单独虚拟机上运行,以支持高效和高吞吐量的视觉定位。
基准测试。我们使用两个已建立的Windows为中心的自动化基准测试UFO²:
- Windows Agent Arena (WAA) [49]:包含154个实时自动化任务,跨越15个常用的Windows应用程序,包括办公生产力工具、网页浏览器、系统实用程序、开发环境和多媒体应用程序。每个任务都包含一个自定义验证脚本,用于自动正确性检查。
-
- OSWorld-W [50]:OSWorld基准测试的针对性子集,专门针对Windows定制,包含办公室应用程序、浏览器交互和文件系统操作中的49个实时任务。任务同样配备了手工制作的验证脚本,以可靠地验证结果。
每个任务独立运行,验证严格遵循每个基准提供的原始脚本。1{ }^{1}1
- OSWorld-W [50]:OSWorld基准测试的针对性子集,专门针对Windows定制,包含办公室应用程序、浏览器交互和文件系统操作中的49个实时任务。任务同样配备了手工制作的验证脚本,以可靠地验证结果。
基线。我们将UFO 2{ }^{2}2与五个代表性的最先进CUA进行了比较,每个CUA都利用GPT-4o作为推理引擎:
- UFO [10]:一种开创性的多代理、GUI聚焦的自动化系统,专门为Windows设计,结合UIA和视觉感知。
-
- NAVI [49]:来自WAA的单代理基线,利用屏幕截图和可访问性数据进行GUI理解。
-
- OmniAgent [18]:结合OmniParser进行视觉定位和基于GPT的动作规划。
-
- Agent S [51]:具有经验驱动分层规划的多代理架构,针对复杂、多步任务进行了优化。
-
- Operator [12]:OpenAI最近推出的高性能CUA,通过屏幕截图模拟人类般的鼠标和键盘交互。
这些基线因其代表多样化的架构和设计范式(例如单代理与多代理、仅GUI与混合方法)而被选择。为确保公平性,每个代理在每项任务中最多执行30步,反映实际用户期望并防止任务执行时间过长。此外,我们还评估了一个基本版本的UFO2\mathrm{UFO}^{2}UFO2(称为UFO2\mathrm{UFO}^{2}UFO2-base),仅使用UIA检测、基于GUI的交互,而不使用动态知识集成,以及完整实现的UFO2\mathrm{UFO}^{2}UFO2,具有混合控制检测、组合GUI-API交互和持续知识增强。在OSWorld-W中为三个办公应用程序选择性实现了API集成作为示例;WAA任务中未引入任何API。更多实现细节请参见第6.4节。
- Operator [12]:OpenAI最近推出的高性能CUA,通过屏幕截图模拟人类般的鼠标和键盘交互。
评估指标。我们使用两种主要指标进行性能评估:
- 成功率(SR):定义为成功完成的任务百分比,通过基准自身的验证脚本验证。
-
- 平均完成步骤(ACS):衡量每项任务所需的平均LLM涉及的动作推断步骤数。步骤越少表示效率越高,直接与较低的推理延迟和减少的计算开销相关联。
表1. 在WAA和OSWorld-W基准测试中代理成功率(SR)的比较。
- 平均完成步骤(ACS):衡量每项任务所需的平均LLM涉及的动作推断步骤数。步骤越少表示效率越高,直接与较低的推理延迟和减少的计算开销相关联。
| 代理 | 模型 | WAA | OSWorld-W |
|---|---|---|---|
| UFO | GPT-4o | 19.5%19.5 \%19.5% | 12.2%12.2 \%12.2% |
| NAVI | GPT-4o | 13.3%13.3 \%13.3% | 10.2%10.2 \%10.2% |
| OmniAgent | GPT-4o | 19.5%19.5 \%19.5% | 8.2%8.2 \%8.2% |
| Agent S | GPT-4o | 18.2%18.2 \%18.2% | 12.2%12.2 \%12.2% |
| Operator | 计算机使用 | 20.8%20.8 \%20.8% | 14.3%14.3 \%14.3% |
| UFO 2^{2}2-base | GPT-4o | 23.4%23.4 \%23.4% | 16.3%16.3 \%16.3% |
| UFO 2^{2}2-base | o1 | 25.3%25.3 \%25.3% | 16.3%16.3 \%16.3% |
| UFO 2^{2}2 | GPT-4o | 27.9%27.9 \%27.9% | 28.6%28.6 \%28.6% |
| UFO 2^{2}2 | o1 | 30.5%30.5 \%30.5% | 32.7%32.7 \%32.7% |
这些指标有效地反映了功能有效性和实际效率,提供了明确的实际世界自动化性能指标。
6.2 成功率比较
表1总结了所有评估代理在WAA和OSWorld-W基准上的成功率(SR),经每个基准的自动化验证脚本验证。值得注意的是,即使是最基本的配置(UFO2\mathrm{UFO}^{2}UFO2-base)——仅依赖标准UI自动化和GUI驱动动作——也始终超越先前最先进的CUA。具体来说,使用GPT-4o时,UFO 2^{2}2-base在WAA上的SR达到23.4%23.4 \%23.4%,比最好的现有基线Operator(20.8%20.8 \%20.8%)高出2.6%2.6 \%2.6%。当使用更强的o1 LLM时,这一差距显著扩大,将UFO2\mathrm{UFO}^{2}UFO2-base的性能提升至25.3%25.3 \%25.3%。
此外,完整的UFO2\mathrm{UFO}^{2}UFO2版本,结合混合GUI-API动作执行、高级视觉定位和持续知识集成,进一步放大了这些性能优势。使用GPT-4o时,UFO 2^{2}2在WAA上的SR达到27.9%27.9 \%27.9%,比Operator高出显著的7.1%7.1 \%7.1%。在OSWorld-W上,UFO 2^{2}2的SR达到了28.6%28.6 \%28.6%,相比Operator的14.3%14.3 \%14.3%几乎翻倍。使用更强的o1模型进一步将UFO 2^{2}2的性能提升至30.5%30.5 \%30.5%(WAA)和32.7%32.7 \%32.7%(OSWorld-W),巩固了其领先地位。
这些显著的性能改进清楚地强调了UFO2\mathrm{UFO}^{2}UFO2深度集成操作系统级机制和其统一系统架构的优势。虽然先前的CUA主要强调模型级优化或单一依赖视觉接口,我们的结果显示,结合结构化操作系统API、专门的应用程序知识和混合GUI-API交互的稳健系统级协调对于实现更高任务可靠性和更广泛的自动化覆盖至关重要。至关重要的是,即使是一般用途、较少专业化的模型如GPT-4o,在综合的UFO 2{ }^{2}2框架内集成时,也可以超越高度专业化的CUA(如Operator)。
1{ }^{1}1 报告的基础分数在OSWorld中略有不同,因为与Ubuntu相关的早期结果相比,验证脚本进行了修正,并与Windows特定任务(OSWorld-W)对齐。
框架。这一见解强化了架构设计和操作系统集成作为实际、可部署桌面自动化解决方案的关键驱动力的价值。
性能细分。表2展示了按应用类型在WAA和OSWorld-W基准测试中的成功率(SR)细分,使我们能够深入理解UFO2\mathrm{UFO}^{2}UFO2在哪方面取得了特别强的结果,并识别需要进一步系统级改进的领域。在多个类别中,UFO2\mathrm{UFO}^{2}UFO2相较于基线CUA展现出一贯的优越性能,特别是在需要更深OS集成或复杂的多步任务执行的应用场景中。
值得注意的是,UFO2\mathrm{UFO}^{2}UFO2在涉及Web浏览器和编码环境的任务中表现出色。例如,最强配置(UFO2\mathrm{UFO}^{2}UFO2与o1)在Web浏览器任务中实现了令人印象深刻的40.0%40.0 \%40.0% SR,明显优于次优基线(OmniAgent)超过12%。同样,在与编码相关的流程中,UFO2\mathrm{UFO}^{2}UFO2(GPT-4o)实现了最高的SR 58.3%58.3 \%58.3%,显著超过了所有竞争CUA。这些结果凸显了UFO2\mathrm{UFO}^{2}UFO2混合GUI-API方法和持续知识集成的有效性,使更精确的动作推断成为可能,减少了由于GUI变化而导致的脆弱性,并大幅提升了多步工作流中的可靠性。
细分进一步揭示了应用复杂性、流行程度和系统级支持之间的明确关联。涉及LibreOffice(WAA中的Office类别的任务)的所有评估CUA普遍表现出较低的SR,主要是因为未能严格遵守可访问性标准和不完整的UIA支持。相反,OSWorld-W任务主要利用Microsoft 365 Office应用程序,它们提供了更丰富的OS原生API和结构化可访问性数据,从而使SR提升至最高51.9%51.9 \%51.9%(UFO2\mathrm{UFO}^{2}UFO2-o1)。这种差异突显了稳健的OS级集成和API可用性在实现高质量桌面自动化中的关键作用。
跨应用任务,尤其是在OSWorldW中尤为突出,提出了更大的挑战。此类任务本质上要求复杂的任务分解和稳健的代理间协调,推动CUA甚至人类用户达到极限。在此处,由集中HostAgent领导的多代理架构和专业的AppÄgents展示了显著的前景,以9.1%9.1 \%9.1% SR优于其他基线。尽管性能仍然相对适度,但它清楚地展示了系统多代理协作和集中编排在解决跨越传统应用边界的复杂情景中的力量。
总体而言,这些详细的细分结果验证了UFO2\mathrm{UFO}^{2}UFO2的系统级设计理念,特别是其对深层OS和特定应用集成、多代理协调和灵活动作编排的重视。尽管在利基或支持较少的应用领域(例如,具有有限API可用性的自定义或遗留软件)中仍有显著的改进潜力,但UFO2\mathrm{UFO}^{2}UFO2当前架构已经在实际、真实的桌面自动化任务中提供了实质性的、可测量的改进。
错误分析。为了系统地了解UFO2\mathrm{UFO}^{2}UFO2的局限性并识别进一步改进的机会,我们对UFO2\mathrm{UFO}^{2}UFO2-base(GPT-4o)在两个基准上的所有失败案例进行了详细的手动审查。按照类似于Agashe等人的分类框架[51],每个失败被归类到以下三个不同的系统级类别之一:
- 计划错误:由于任务理解不足引起的失败,通常反映在不完整或不正确的行动计划中。这些错误表明代理在任务理解和应用特定工作流中的不足或基础不够稳固。
-
- 执行错误:计划合理但在执行上有缺陷的情况(例如选择错误的控件、执行无意动作)。执行错误通常源于不准确的视觉推理、GUI元素与动作之间的错误关联或LLM的错误推断。
-
- 控件检测失败:代理未能检测或识别完成任务所需的关键GUI控件的实例,通常是因为非标准或自定义渲染的UI元素无法通过标准OS API完全访问。
- 图19总结了我们对UFO2\mathrm{UFO}^{2}UFO2-base的发现。在WAA基准上,超过62%62 \%62%的失败归因于控件检测失败,突出显示了标准UIA API覆盖率的重大空白——尤其是那些不严格遵守可访问性标准的第三方应用(例如LibreOffice)。相比之下,OSWorld-W基准显示出更高的计划错误发生率,强调此集合中的任务经常涉及更复杂的工作流,需要更深入的领域知识或高级情境推理能力,而不仅仅是简单的视觉识别。
这些观察结果提供了具体的系统级短处的切实证据,直接激发了完整版UFO2\mathrm{UFO}^{2}UFO2中所包含的改进。控件检测失败的高频率验证了我们
表2. 按应用类型在WAA和OSWorld-W上的SR细分。
| 代理 | 模型 | WAA | OSWorld-W | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 办公室 | Web 浏览器 |
Windows 系统 |
编码 | 媒体&视频 | Windows 工具 |
办公室 | 跨应用 | ||
| UFO | GPT-4o | 0.0%0.0 \%0.0% | 23.3%23.3 \%23.3% | 33.3%33.3 \%33.3% | 29.2%29.2 \%29.2% | 33.3%33.3 \%33.3% | 8.3%8.3 \%8.3% | 18.5%18.5 \%18.5% | 4.5%4.5 \%4.5% |
| NAVI | GPT-4o | 0.0%0.0 \%0.0% | 20.0%20.0 \%20.0% | 29.2%29.2 \%29.2% | 9.1%9.1 \%9.1% | 25.3%25.3 \%25.3% | 0.0%0.0 \%0.0% | 18.5%18.5 \%18.5% | 0.0%0.0 \%0.0% |
| OmniAgent | GPT-4o | 0.0%0.0 \%0.0% | 27.3%27.3 \%27.3% | 33.3%33.3 \%33.3% | 27.3%27.3 \%27.3% | 30.3%30.3 \%30.3% | 8.3%8.3 \%8.3% | 14.8%14.8 \%14.8% | 0.0%0.0 \%0.0% |
| Agent S | GPT-4o | 0.0%0.0 \%0.0% | 13.3%13.3 \%13.3% | 45.8%45.8 \%45.8% | 29.2%29.2 \%29.2% | 19.1%19.1 \%19.1% | 22.2%22.2 \%22.2% | 22.2%22.2 \%22.2% | 0.0%0.0 \%0.0% |
| Operator | 计算机使用 | 7%7 \%7% | 26.7%26.7 \%26.7% | 29.2%29.2 \%29.2% | 29.2%29.2 \%29.2% | 28.6%28.6 \%28.6% | 8.3%8.3 \%8.3% | 22.2%22.2 \%22.2% | 4.5%4.5 \%4.5% |
| UFO 2^{2}2-base | GPT-4o | 2.3%2.3 \%2.3% | 36.7%36.7 \%36.7% | 29.2%29.2 \%29.2% | 41.7%41.7 \%41.7% | 33.3%33.3 \%33.3% | 0.0%0.0 \%0.0% | 22.2%22.2 \%22.2% | 9.1%9.1 \%9.1% |
| UFO 2^{2}2-base | o1 | 2.3%2.3 \%2.3% | 30.0%30.0 \%30.0% | 37.5%37.5 \%37.5% | 50.0%50.0 \%50.0% | 33.3%33.3 \%33.3% | 8.3%8.3 \%8.3% | 22.2%22.2 \%22.2% | 9.1%9.1 \%9.1% |
| UFO 2^{2}2 | GPT-4o | 4.7%4.7 \%4.7% | 30.0%30.0 \%30.0% | 41.7%41.7 \%41.7% | 58.3%58.3 \%58.3% | 33.3%33.3 \%33.3% | 8.3%8.3 \%8.3% | 44.4%44.4 \%44.4% | 9.1%9.1 \%9.1% |
| UFO 2^{2}2 | o1 | 4.7%4.7 \%4.7% | 40.0%40.0 \%40.0% | 45.8%45.8 \%45.8% | 50.0%50.0 \%50.0% | 38.1%38.1 \%38.1% | 16.7%16.7 \%16.7% | 51.9%51.9 \%51.9% | 9.1%9.1 \%9.1% |
表3. 不同控制检测机制的SR和CRR对比。
| 控制检测器 | 模型 | WAA | OSWorld-W | ||
|---|---|---|---|---|---|
| SR | CRR | SR | CRR | ||
| UIA | GPT-4o | 23.4%23.4 \%23.4% | - | 22.4%22.4 \%22.4% | - |
| OmniParser-v2 | GPT-4o | 26.6%26.6 \%26.6% | 7.0%7.0 \%7.0% | 14.3%14.3 \%14.3% | 0%0 \%0% |
| 混合 | GPT-4o | 26.6%26.6 \%26.6% | 9.9%9.9 \%9.9% | 22.4%22.4 \%22.4% | 12.5%12.5 \%12.5% |
| UIA | o1 | 25.3%25.3 \%25.3% | - | 24.5%24.5 \%24.5% | - |
| OmniParser-v2 | o1 | 20.8%20.8 \%20.8% | 7.0%7.0 \%7.0% | 14.3%14.3 \%14.3% | 0%0 \%0% |
| 混合 | o1 | 27.9%27.9 \%27.9% | 9.9%9.9 \%9.9% | 28.6%28.6 \%28.6% | 25.0%25.0 \%25.0% |
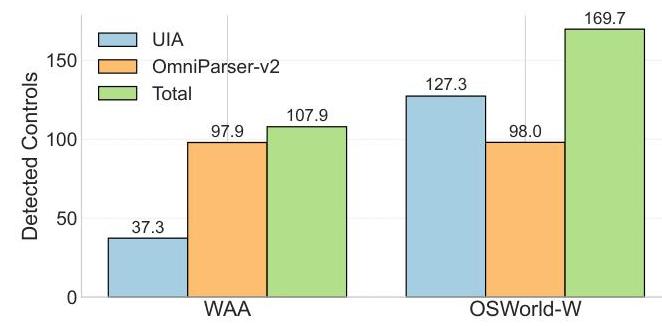
图20. 不同方法检测到的控件数量。
选择采用混合GUI检测流水线,补充标准UIA数据与先进的视觉定位技术。同样,计划错误的普遍存在强调了整合更丰富的外部文档、领域特定知识库和应用级API以加强任务理解和动作推断的关键作用。在随后的部分中,我们明确展示了这些渐进的系统级改进如何逐步减轻每个确定类别的错误,从而大幅提升UFO2\mathrm{UFO}^{2}UFO2的整体任务完成效果。
6.3 混合控制检测评估
如图19所示,相当一部分失败源于控件检测失败,其中非标准UI元素不符合UIA指南。为了量化不同检测策略的有效性,我们将仅使用UIA、仅使用OmniParser-v2和我们的混合方法(第3.4节)进行比较。我们引入了控制恢复率(CRR)来衡量在OmniParser或混合方法下“恢复”(即变为成功完成)的UIA-only失败的数量。
表3展示了两个基准在多个模型配置下的结果。混合方法始终优于仅使用UIA或仅使用OmniParser-v2的设置,整体成功率提高,并将高达9.86%9.86 \%9.86%的先前不可恢复的案例转化为完成。这一收益突出了两种检测流水线的互补优势,因为混合方法弥补了UIA的覆盖范围空白,同时避免了在更标准化的GUI中OmniParser的局限性。
在图20中,我们报告了每种来源(UIA、OmniParser-v2和合并集)下检测到的控件平均数量。由于应用覆盖率的不同,OSWorld-W中检测到的控件总数通常高于WAA。值得注意的是,UIA和OmniParser-v2都识别了大量控件子集,合并后,27.9%27.9 \%27.9%和56.7%56.7 \%56.7%的OmniParser-v2检测被丢弃,因为与UIA重叠。这些观察结果表明,OmniParser-v2通过恢复非标准或自定义元素为UIA提供了有价值的补充。同时,合并步骤去除了冗余并防止双重计数,最终在混合方案中减少了控件检测失败。
6.4 GUI + API集成的有效性
我们现在评估在Puppeteer中统一API基础动作与标准GUI交互对性能的影响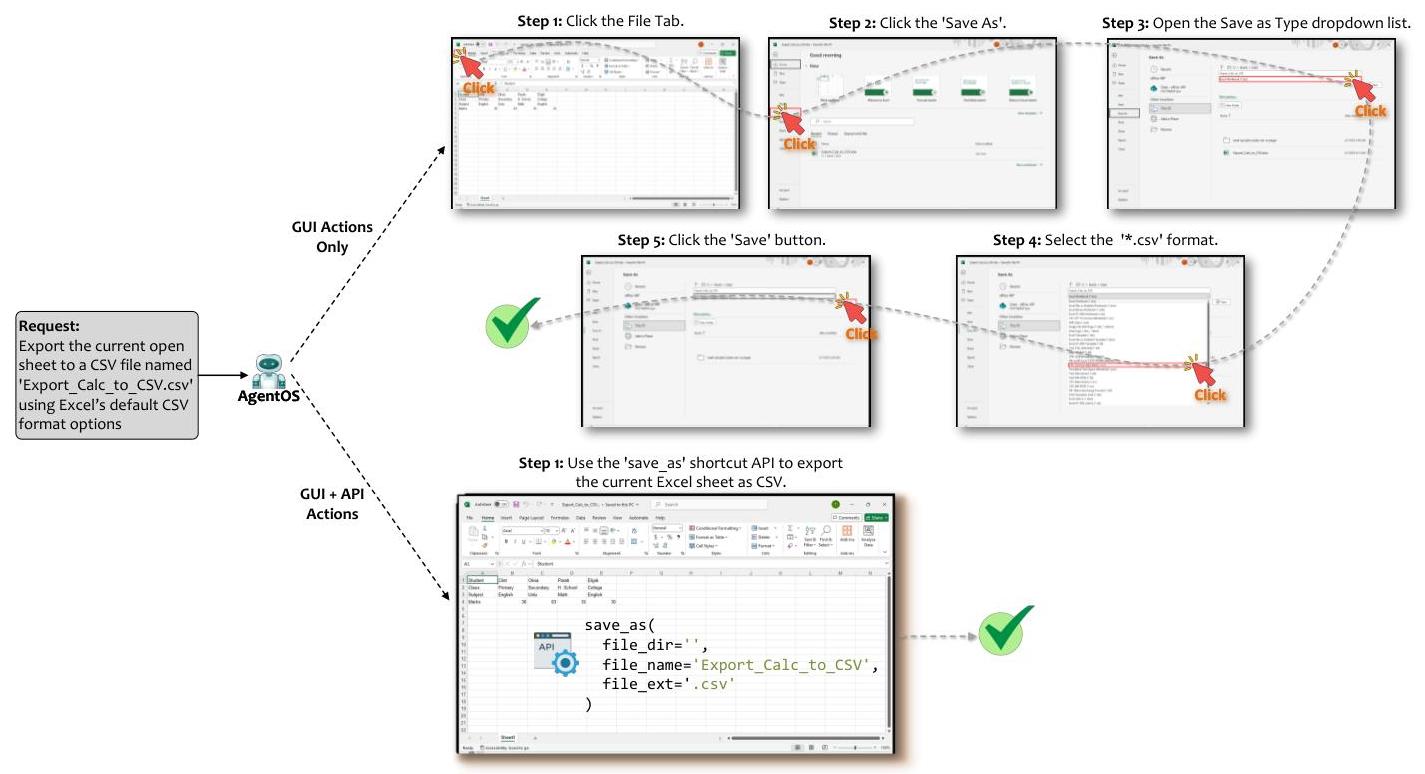
图21. 使用仅GUI动作与GUI + API动作完成同一任务的案例研究比较。
表4. Office应用程序支持的API。
| API | 应用程序 | 描述 |
|---|---|---|
| select_text | Word | 在 文档中选择匹配的文本。 |
| select_paragraph | Word | 在 文档中选择段落。 |
| set_font | Word | 设置选定文本的字体大小和样式。 |
| save_as | Word | 将当前文档保存 为所需的格式。 |
| insert_excel_table | Excel | 在所需位置插入表格。 |
| select_table_range | Excel | 在表格中选择范围。 |
| reorder_column | Excel | 重新排序表格的列。 |
| save_as | Excel | 将当前工作表保存为 所需的格式。 |
| set_background_color | PowerPoint | 设置幻灯片的背景颜色。 |
| save_as | PowerPoint | 将当前演示文稿保存为 所需的格式。 |
(第3.5节)。为此,我们专注于OSWorld中的27个与办公相关的任务,并手动开发了Word、Excel和PowerPoint的12个API。这些应用程序提供了COM接口,便于创建自定义函数,使其成为更深OS和应用级集成的理想示例。重要的是,许多这些操作需要
表5. 仅GUI动作与GUI + API动作的性能对比。
| 动作 | 模型 | SR | PRR | ERR | CRR | ACS |
|---|---|---|---|---|---|---|
| 仅GUI | GPT-4o | 16.3%16.3 \%16.3% | - | - | - | 13.8 |
| GUI+API | GPT-4o | 22.4%\mathbf{2 2 . 4 \%}22.4% | 5.9%\mathbf{5 . 9 \%}5.9% | 14.3%\mathbf{1 4 . 3 \%}14.3% | 25.0%\mathbf{2 5 . 0 \%}25.0% | 12.9\mathbf{1 2 . 9}12.9 |
| 仅GUI | o1 | 16.3%16.3 \%16.3% | - | - | - | 16.0 |
| GUI+API | 1\mathbf{~} \mathbf{~} \mathbf{~ 1} 1 | 24.5%\mathbf{2 4 . 5 \%}24.5% | 17.7%\mathbf{1 7 . 7 \%}17.7% | 0.0%\mathbf{0 . 0 \%}0.0% | 12.5%\mathbf{1 2 . 5 \%}12.5% | 6.6\mathbf{6 . 6}6.6 |
繁琐的多步GUI程序,但通过这些API(例如选择段落)成为简单的单步调用。表4详细说明了实现的API。
表5比较了(i)整体成功率(SR),(ii)计划错误恢复率(PRR),(iii)执行错误恢复率(ERR),(iv)控制检测失败恢复率(CRR),和(v)平均完成步骤(ACS)对于两种配置:仅GUI与GUI + API。我们只计算两种配置都能成功完成的任务子集的ACS,以确保公平比较。
结果显示,集成API动作提高了GPT-4o (+6.1%+6.1 \%+6.1%) 和 o1 (+8.2%+8.2 \%+8.2%) 的SR,突显了混合GUI和API交互的有效性。值得注意的是,GPT-4o通过绕过未标注的GUI元素,在从控制检测失败中恢复时最受益于API。相反,o1更频繁地通过API “快捷方式” 地址计划错误,反映出模型较强的推理能力和对简洁解决方案的偏好。
表6. 集成与未集成知识的性能对比。
| 知识 增强 |
模型 | WAA | OSWorld-W | |||
|---|---|---|---|---|---|---|
| SR | PRR | SR | PRR | |||
| 无 | GPT-4o | 23.4%23.4 \%23.4% | - | 22.4%22.4 \%22.4% | - | |
| 帮助文档 | GPT-4o | 26.6%26.6 \%26.6% | 10.34%10.34 \%10.34% | 26.5%26.5 \%26.5% | 11.8%11.8 \%11.8% | |
| 自我经验 | GPT-4o | 26.6%26.6 \%26.6% | 13.79%13.79 \%13.79% | 24.5%24.5 \%24.5% | 11.8%11.8 \%11.8% | |
| 无 | o1 | 25.3%25.3 \%25.3% | - | 24.5%24.5 \%24.5% | - | |
| 帮助文档 | o1 | 27.9%27.9 \%27.9% | 3.5%3.5 \%3.5% | 28.5%28.5 \%28.5% | 17.7%17.7 \%17.7% | |
| 自我经验 | o1 | 20.8%20.8 \%20.8% | 13.79%13.79 \%13.79% | 26.5%26.5 \%26.5% | 17.7%17.7 \%17.7% |
除了更高的成功率外,GUI + API还减少了完成任务所需的努力。UFO 2^{2}2通过GPT-4o节省了6.5%6.5 \%6.5%的步骤,而对于o1在相同任务上则显著减少了58.5%58.5 \%58.5%。后者改进源于o1战略性调用API函数,跳过了多个基于GUI的步骤。总的来说,这些发现证实了将GUI自动化与API调用结合在稳健性和效率方面的优势,并展示了深入系统集成在桌面自动化中的重要性。
案例研究。为了说明GUI + API方法如何简化任务执行,图21展示了在OSWorld-W的一个案例中,使用仅GUI或GUI + API交互导出Excel文件为CSV格式的完成轨迹。尽管两种配置最终都成功,但仅GUI设置需要五个步骤来打开保存对话框、选择文件格式并确认操作。相比之下,单次调用save_as API即可立即完成任务。除了提高效率外,这种一步解决方案还减少了多个GUI交互中累积错误的风险——这是更深OS和应用级集成优势的明确展示。
6.5 持续知识集成评估
接下来,我们评估持续知识集成(第3.6节)对UFO 2{ }^{2}2性能的影响。具体来说,我们通过外部文档和执行衍生见解增强UFO 2{ }^{2}2,以在无需重新训练的情况下动态改善其领域理解。我们创建了34份针对基准任务的帮助文档,每份包含精确的逐步指导,使UFO 2{ }^{2}2能够在运行时检索最相关的指导(每项任务最多一份)。此外,我们实现了一个自动管道,总结成功的执行轨迹——由我们的任务评估器验证并存档到可检索的知识数据库中。对于后续任务,UFO 2{ }^{2}2动态检索最多三条相关的过去执行日志,以指导任务规划和执行。鉴于知识集成主要解决计划不足(计划错误)引发的失败,我们采用计划恢复率(PRR)来衡量通过整合新知识成功解决以前失败的计划案例的比例。
表7. 单动作与投机多动作模式的SR和ACS对比。
| 动作
执行 | 模型 | WAA | | | OSWorld-W | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | | SR | ACS | 成功
子集 | SR | ACS | 成功
子集 |
| 单动作 | GPT-4o | 23.4%23.4 \%23.4% | 10.00 | 30 | 22.4%22.4 \%22.4% | 13.30 | 10 |
| 投机性多动作 | GPT-4o | 23.4%23.4 \%23.4% | 8.78 | | 24.5%24.5 \%24.5% | 7.40 | |
| 单动作 | o1 | 25.3%25.3 \%25.3% | 9.95 | 32 | 24.5%24.5 \%24.5% | 6.80 | 10 |
| 投机性多动作 | o1 | 24.7%24.7 \%24.7% | 8.85 | | 26.5%26.5 \%26.5% | 3.30 | |
表6比较了两个基准测试中整体SR和PRRs,突显了知识集成带来的显著性能改进。无论是实时帮助文档检索还是自我经验总结都带来了明显的收益,减少了高达17.7%17.7 \%17.7%的计划失败。值得注意的是,使用更强模型(o1)进行的自我经验增强在两个基准测试中都表现出一致的改进,强调了利用先前成功进行自适应改进的有效性。虽然帮助文档偶尔会带来适度的收益,但其有效性取决于任务复杂性和文档具体性。
这些发现强调了系统知识集成的价值,证明持续增强代理的知识库可以显著提高其在实际部署中的鲁棒性、可扩展性和适应性。此外,随着UFO 2{ }^{2}2随着时间积累执行经验和文档,它本质上朝着更高的可靠性和改进的自主性发展,为桌面自动化的持续改进明确了路径。
6.6 投机多动作执行的有效性
接下来,我们评估投机多动作执行(第3.7节)对任务完成率和效率的影响。表7比较了两种模式下的UFO2\mathrm{UFO}^{2}UFO2:每次推理生成并执行一个动作(单动作)与一步推断多个连续动作(投机多动作)。为了确保公平比较,我们仅在两种模式都能成功完成的任务子集中计算平均完成步骤(ACS)。
结果显示,投机多动作执行保留了与单动作模式相当的成功率(SR),同时显著减少了平均步骤——在WAA上最多减少10%10 \%10%,在OSWorld-W上令人印象深刻地减少51.5%51.5 \%51.5%。由于每步都需要调用LLM,减少步骤数量显著降低了延迟和成本。这一发现证实了投机多动作规划提高了效率而不损害可靠性,进一步凸显了UFO2\mathrm{UFO}^{2}UFO2优化实际桌面自动化资源利用的能力。
案例研究。图22说明了投机多动作执行在实践中如何操作。当用户请求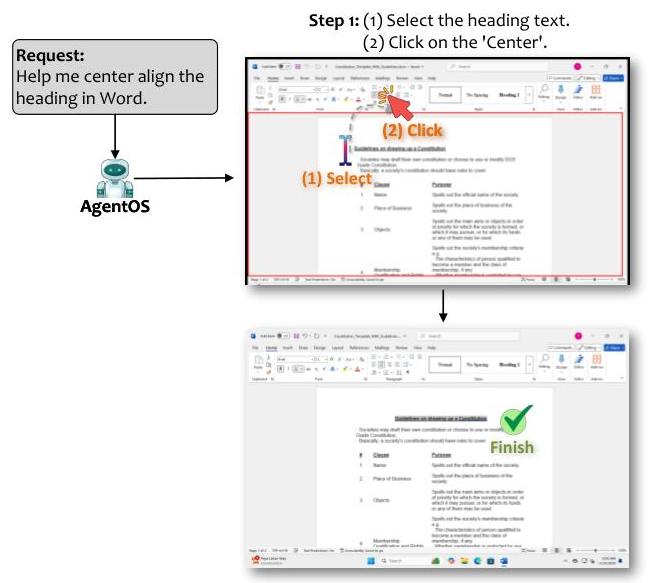
图22. 投机多动作执行成功案例研究。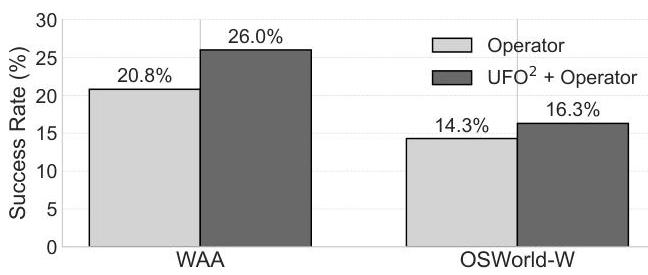
图23. Operator与UFO2+\mathrm{UFO}^{2}+UFO2+ Operator在WAA和OSWorld-W上的对比。
让UFO2\mathrm{UFO}^{2}UFO2在Word文档中居中对齐标题时,通常需要依次选择标题文本然后点击居中图标。这些动作是顺序依赖的,但不会相互干扰。与其将每个动作视为单独的LLM推理,UFO2\mathrm{UFO}^{2}UFO2通过投机多动作规划预测了这两个动作。因此,它只需一次LLM调用即可完成任务,显著提高了效率同时保持了准确性。
6.7 Operator作为AppAgent
为了展示“一切皆为AppAgent”能力(第5.3节),我们进行了一个实验,其中UFO2\mathrm{UFO}^{2}UFO2的HostAgent协调器仅使用Operator作为AppAgent。换句话说,所有本地AppAgent都被禁用,只留下Operator接受子任务并通过标准UFO2\mathrm{UFO}^{2}UFO2消息协议通信。对Operator感知层的唯一调整是将其限制为所选应用程序窗口的截图,而不是整个桌面。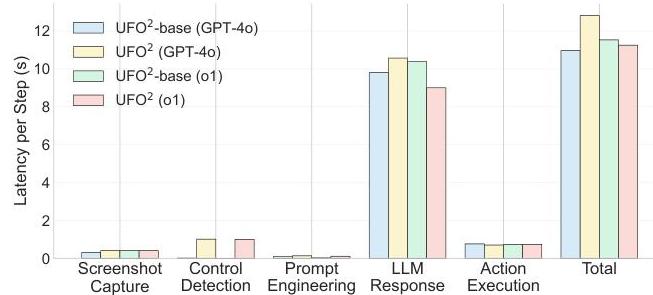
图24. 单次执行步骤的各阶段平均时间成本。
图23显示UFO2+\mathrm{UFO}^{2}+UFO2+ Operator比单独运行Operator实现了更高的成功率,特别是在WAA上(26.0%26.0 \%26.0% vs. 20.8%20.8 \%20.8%)。我们将这些收益归因于三个关键因素。首先,HostAgent将复杂的用户指令分解为更清晰的单应用子任务,减少了歧义。其次,HostAgent的消息包含额外的提示,改善了Operator的决策。最后,将Operator的视图限制在单个活动应用程序窗口中减少了视觉噪音并简化了控件检测。综合来看,这些结果强调了UFO2\mathrm{UFO}^{2}UFO2多代理设计的优势,同时展示了“一切皆为AppAgent”如何提升现有CUA的性能。
6.8 效率分析
为了全面了解UFO2\mathrm{UFO}^{2}UFO2的性能特征,我们详细分析了任务执行效率,重点关注步数和延迟。
步数分析。表8总结了HostAgent和AppAgents在两个基准套件中执行的平均步数。报告的步数是在所有模型配置下成功完成的任务上计算的,以确保公平比较。两个关键见解浮现:
首先,完全集成的UFO2\mathrm{UFO}^{2}UFO2配置相比基线(UFO2\mathrm{UFO}^{2}UFO2-base)始终减少了所需的平均步数,最高可达50%50 \%50%。这种显著的效率提升展示了深度OS集成,特别是混合GUI-API动作编排和高级控制检测策略,如何显著简化执行路径。
其次,使用更强大的推理模型(例如o1相对于GPT-40)进一步减少了步数,表明增强的推理能力使代理能够识别和利用更高效的行动序列。例如,更强的模型可以更好地利用直接API交互或避免不必要的中间GUI交互。这强调了稳健系统集成和高级LLM推理在最小化执行开销中的互补作用。
表8. UFO2\mathrm{UFO}^{2}UFO2的步数统计。
| 代理 | 模型 | WAA | OSWorld-W | ||||||
|---|---|---|---|---|---|---|---|---|---|
| HostAgent | AppAgent | 总数 | 成功 子集 |
HostAgent | AppAgent | 总数 | 成功 子集 |
||
| UFO2\mathrm{UFO}^{2}UFO2-base | GPT-40 | 2.21 | 8.11 | 10.32 | 31 | 1.80 | 10.80 | 12.60 | 7 |
| UFO2\mathrm{UFO}^{2}UFO2 | GPT-40 | 2.32 | 7.89 | 10.21 | 2.80 | 7.20 | 10.00 | ||
| UFO2\mathrm{UFO}^{2}UFO2-base | o1 | 2.14 | 7.00 | 9.14 | 34 | 2.50 | 8.83 | 11.33 | 8 |
| UFO2\mathrm{UFO}^{2}UFO2 | o1 | 2.00 | 4.05 | 6.05 | 2.00 | 3.50 | 5.50 |
延迟细分。图24提供了UFO2\mathrm{UFO}^{2}UFO2每次执行步骤的平均延迟细分,分为五个关键阶段:(i) 截屏捕获,(ii) 通过UIA API(和)OmniParser-v2进行控件检测,(iii) 提示准备,包括相关帮助文档和历史执行经验的检索,(iv) LLM推理,和(v) 在目标应用程序上执行动作。
在所有配置中,LLM推理阶段主导总延迟,平均每次推理约需10秒。这个瓶颈明确指出了通过部署更小、专门化的模型或使用更强大的推理硬件进行优化的机会——这些策略目前可行但在我们的评估范围之外。
排除LLM推理开销后,基础系统(UFO2\mathrm{UFO}^{2}UFO2-base)实现了高度高效的执行,平均每步耗时约10秒。相比之下,完全集成的UFO2\mathrm{UFO}^{2}UFO2在其混合控件检测流水线中每步仅增加1秒,主要由于OmniParser-v2视觉解析。这种额外开销代表了一个深思熟虑的权衡,在适度延迟成本下显著增强了GUI控件检测的鲁棒性和准确性。
综合来看,这些结果表明,每项任务所需的总步数大幅减少,确保了总体任务完成时间仍然实用(大约每项任务1分钟)。这些剖析洞察强化了UFO2\mathrm{UFO}^{2}UFO2全面的系统级集成平衡延迟、准确性和效率,提供了一个可扩展且高效的现实世界桌面自动化解决方案。
6.9 模型消融
表25比较了UFO2\mathrm{UFO}^{2}UFO2和UFO2\mathrm{UFO}^{2}UFO2-base在四种大型语言模型上的表现。GPT-4V和GPT-4o生成直接答案而不暴露明确的CoT,而Gemini 2.0(Flash Thinking)和o1则在产生最终输出前内部嵌入推理步骤。总体而言,内置推理的模型通常实现更高的成功率(SR),突显了在桌面自动化中更多考虑性或CoT驱动过程的价值[52]。
这一结果突显了CUAs的一个有希望的方向:针对桌面自动化任务微调先进的推理模型。通过允许代理制定和细化多步计划——尤其是在与更深的OS级信号结合时——UFO2\mathrm{UFO}^{2}UFO2可以更可靠地应对复杂或模糊的情况。随着基于LLM的推理继续成熟,我们预计UFO2\mathrm{UFO}^{2}UFO2的模型无关设计将在准确性和通用性方面取得进一步的提升。
7 讨论与未来工作
延迟和响应速度。UFO2\mathrm{UFO}^{2}UFO2当前在每个决策步骤调用LLM推理,造成每动作几秒到几十秒的延迟。尽管经过各种工程优化,由多个连续动作组成的复杂任务累积执行时间可能达到1-2分钟,这虽然可以接受,但仍不如熟练的人类表现。为减轻用户感知的延迟,我们引入了画中画(PiP)接口,使UFO2\mathrm{UFO}^{2}UFO2能够在隔离的虚拟桌面内不引人注目地执行任务,从而大大减少了长时间运行自动化期间给用户带来的不便。在未来的工作中,我们旨在通过研究部署专门的轻量级大型动作模型(LAMs)[13]来进一步降低延迟,这些模型针对特定任务推理进行了优化,以提高响应速度和可扩展性。
缩小与人类水平表现的差距。我们的全面评估表明,尽管UFO2\mathrm{UFO}^{2}UFO2稳健且有效,但它尚未在所有Windows应用程序中始终达到人类水平的表现。弥补这一差距将需要在两个关键维度上取得进展。首先,通过在广泛的GUI交互数据集上进行微调来增强基础视觉语言模型,将显著提高代理在不同应用程序中的能力和泛化能力。其次,与OS级API、原生应用程序接口和全面结构化文档源的更紧密集成将加深情境理解并加强执行可靠性。鉴于UFO 2^{2}2的模块化架构,这些增强功能可以逐步采用,不断改进在多种应用场景中向人类等效能力发展的性能。
跨操作系统的一般化。尽管UFO 2^{2}2由于其广泛市场采用(超过70%70 \%70%市场份额2{ }^{2}2)而针对Windows OS,模块化、分层系统设计便于轻松适应其他桌面平台,如Linux和macOS。核心方法——利用类似Windows UI Automation(UIA)的可访问性框架——在Linux(AT-SPI [53])和macOS(Accessibility API [54])上有直接对应物。因此,现有的设计原则、代理分解策略和统一GUI-API协调模型自然一般化,支持快速、平台特定定制。探索跨平台部署将是未来工作的重要领域,可能为跨越多样操作系统环境的统一桌面自动化解决方案生态系统奠定基础。
8 相关工作
将LLMs集成到OS中是一个正在增长但尚处于起步阶段的研究领域。在本节中,我们讨论了与我们在系统级集成多模态LLM驱动的桌面自动化代理方面的研究相关的先前工作。
8.1 计算机使用代理(CUAs)
最近多模态LLMs的发展极大地加速了计算机使用代理(CUAs)的发展,这些代理通过模拟OS级别的GUI交互来自动化桌面工作流。早期的先锋系统,如UFO [10],结合了多模态模型(如GPT-4V [20])和UIA API来解释图形界面并通过自然语言指令执行复杂任务。UFO显著引入了多代理架构,增强了CUA处理跨应用和长期工作流的可靠性和能力。
随后的努力主要集中在改进底层多模态模型和扩展平台功能。例如,CogAgent [55] 基于视觉语言模型CogVLM [56],专注于跨多个平台(PC、Web、Android)的GUI理解,是最早的专用多模态CUAs之一。行业兴趣也随着Anthropic的Claude-3.5(计算机使用)[11]的出现而加速,这是一种完全依赖基于屏幕截图的GUI交互的代理,以及OpenAI的Operator [12],它通过高级多模态推理显著提高了桌面自动化性能。
然而,这些现有的CUA大多仍停留在原型演示阶段,常常缺乏与OS和本地应用程序功能的深度集成。相反,我们的UFO 2^{2}2工作通过模块化AgentOS架构、深度OS和API集成、混合GUI检测和非侵入式执行模型直接解决了这些基本的系统级限制,弥合了概念CUA与实际桌面自动化之间的差距。
8.2 面向操作系统的LLMs
另一个有前途的研究方向是将LLMs直接嵌入OS架构中,旨在大幅提升自动化、适应性和可用性。Ge等人首次提出了AIOS的概念框架[57],将LLM置于OS设计的核心位置,以协调高层次的用户互动和自动决策。在他们的设想中,代理类似于OS应用程序,每个都暴露出可通过自然语言访问的专门能力,有效地使用户能够直观地“编程”其OS。
在此概念基础上,Mei等人[58]将AIOS实现为具体原型,将LLM交互和工具API封装在特权OS内核中。该设计提供了核心OS功能,如进程调度、内存管理、I/O处理和访问控制,利用LLMs通过专用SDK简化代理开发。Rama等人[59]扩展了这一范式,通过基于AIOS的代理在传统OS环境中引入语义文件管理功能,进一步展示了实际的系统级集成。
补充这些高层次的OS集成,AutoOS [60] 将LLMs应用于Linux内核级参数的自动调优,通过自主探索和优化取得了显著的效率提升。这突显了另一维度,即LLM集成可以直接增强核心系统性能和管理。
集体而言,这些研究努力展示了LLMs成为操作系统不可或缺组件的新兴范式转变,实现强大自动化、增强用户互动和自适应系统行为。我们的UFO 2^{2}2工作将此研究线路特别扩展到桌面自动化,提供了一个深度融合、可扩展且实用的AgentOS,结合多模态LLMs与稳健的OS级机制。
9 结论
我们介绍了UFO 2^{2}2,这是一个实用的、OS集成的Windows桌面自动化AgentOS,将CUA从概念原型转变为稳健、面向用户的解决方案。
2{ }^{2}2 https://gs.statcounter.com/os-market-share/desktop/worldwide/ #monthly-202301-202301-bar
与之前的CUA不同,UFO 2{ }^{2}2通过由集中HostAgent和应用专业化的AppAgent组成的模块化多代理架构,利用深层系统级集成。每个AppAgent无缝结合GUI交互与本地API,并持续整合应用特定知识,显著提高了可靠性和执行效率。UFO2\mathrm{UFO}^{2}UFO2可以在PiP虚拟桌面界面操作,进一步增强了可用性,使用户和代理的工作流程可以并发进行而不受干扰。
我们在超过20个实际的Windows应用程序上进行全面评估,证明了UFO 2{ }^{2}2在鲁棒性、准确性和可扩展性方面相较于最先进的CUA有了显著的改进。值得注意的是,通过将我们的集成框架与稳健的OS级特性相结合,即使是较少专业的基础模型(如GPT-4o)也能超越专门的CUA,如Operator。
参考文献
[1] UiPath. Uipath: 自动化平台,2025年。获取日期:2025-03-18。
[2] Automation Anywhere. Automation anywhere: Automation 360 平台,2025年。获取日期:2025-03-18。
[3] Microsoft. Microsoft power automate, 2025年。获取日期:2025-03-18。
[4] Peter Hofmann, Caroline Samp, 和 Nils Urbach. 机器人流程自动化。Electronic markets, 30(1):99-106, 2020年。
[5] Somayya Madakam, Rajesh M Holmukhe, 和 Durgesh Kumar Jaiswal. 未来的数字劳动力:机器人流程自动化(RPA)。JISTEM-Journal of Information Systems and Technology Management, 16:e201916001, 2019年。
[6] Dhanya Pramod. 行业中的机器人流程自动化:采用状况、优势、挑战和研究议程。Benchmarking: an international journal, 29(5):1562-1586, 2022年。
[7] 张朝云,何世霖,钱家旭,李博文,李立群,秦思,康宇,马明华,刘国越,林清伟,等。大型语言模型大脑的GUI代理:综述。arXiv预印本 arXiv:2411.18279, 2024年。
[8] 赵欣新,周昆,李俊一,唐天一,王潇蕾,侯玉鹏,闵英建,张贝晨,张俊杰,董子灿,等。大型语言模型综述。arXiv预印本 arXiv:2303.18223, 1(2), 2023年。
[9] 张杜珍,余雅涵,董嘉华,李辰兴,苏丹,储晨辉,余东。MM-LLMS:多模态大语言模型的最新进展。arXiv预印本 arXiv:2401.13601, 2024年。
[10] 张朝云,李立群,何世霖,张旭,乔博,秦思,马明华,康宇,林清伟,Rajmohan Saravan,等。Ufo:用于Windows OS交互的UI聚焦代理。arXiv预印本 arXiv:2402.07939, 2024年。
[11] Anthropic. 引入计算机使用,一个新的Claude 3.5十四行诗,和Claude 3.5俳句,2024年。获取日期:2024-10-26。
[12] OpenAI. 计算机使用代理:引入人工智能与数字世界互动的通用界面。2025年。
[13] 王路,杨方凯,张朝云,卢军庭,钱家旭,何世霖,赵普,乔博,黄雷,秦思,等。大规模动作模型:从构想到实施。arXiv预印本 arXiv:2412.10047, 2024年。
[14] 秦雨佳,叶尹宁,方俊杰,王浩鸣,梁世豪,田世卓,张俊达,李佳昊,李云新,黄世觉,等。Uitars:开创性的自动化GUI交互原生代理。arXiv预印本 arXiv:2501.12326, 2025年。
[15] 郑洁妮,王璐,杨方凯,张朝云,梅玲蕊,尹文杰,林清伟,张东美,Rajmohan Saravan,张琦。Vem:无需环境的探索以训练具有价值环境模型的GUI代理。arXiv预印本 arXiv:2502.18906, 2025年。
[16] 牛润良,李金东,王世琪,傅亚丽,胡锡远, LENG Xueyuan,孔赫,常毅,王琦。Screenagent:由视觉语言模型驱动的计算机控制代理。在第三十三届国际人工智能联合会议论文集,页码6433-6441, 2024年。
[17] 张朝云,何世霖,李立群,秦思,康宇,林清伟,张东美。API代理与GUI代理:分歧与趋同,2025年。
[18] 吕亚东,杨健维,沈益龙,Ahmed Awadallah。Omniparser for pure vision based gui agent。arXiv预印本 arXiv:2408.00203, 2024年。
[19] Julia Siderska,Lili Aunimo,Thomas Süße,John von Stamm,Damian Kedziora,Suraya Nabilah Binti Mohd Aini。迈向智能自动化(IA):关于机器人流程自动化(RPA)的演变、其挑战和未来趋势的文献回顾。生产和服务中的工程管理,15(4),2023年。
[20] 杨政元,李琳杰,Kevin Lin,王剑锋,林忠承,刘子诚,王丽娟。LMMS的曙光:GPT-4V (ision) 的初步探索。arXiv预印本 arXiv:2309.17421, 9(1):1, 2023年。
[21] David N Gray,John Hotchkiss,Seth LaForge,Andrew Shalit,Toby Weinberg。现代语言和微软的组件对象模型。ACM通讯,41(5):55-65, 1998年。
[22] Yao Shunyu,Zhao Jeffrey,Yu Dian,Du Nan,Shafran Izhak,Narasimhan Karthik,Cao Yuan。React:协同推理和动作的语言模型。在国际学习表示会议(ICLR),2023年。
[23] 乔博,李立群,张旭,何世霖,康宇,张朝云,杨方凯,董航,张珏,王路,等。Taskweaver:一种代码优先的代理框架。arXiv预印本 arXiv:2311.17541, 2023年。
[24] 韩珊珊,张启凡,姚雨航,金威昭,许兆卓,何超阳。LLM多代理系统:挑战与开放问题。arXiv预印本 arXiv:2402.03578, 2024年。
[25] 王磊,马晨,冯雪洋,张泽宇,杨昊,张景森,陈志远,唐佳凯,陈旭,林彦凯,等。基于大型语言模型的自主代理调查。计算机科学前沿,18(6):186345, 2024年。
[26] 张泽宇,Bo Xiaobe,马晨,李瑞,陈旭,戴全宇,朱杰明,董振华,文吉荣。基于大型语言模型代理的记忆机制调查。arXiv预印本 arXiv:2404.13501, 2024年。
[27] 杨健维,张昊,李峰,邹学艳,李春媛,高建峰。Set-of-mark 提示释放了GPT-4V中的非凡视觉定位。arXiv预印本 arXiv:2310.11441, 2023年。
[28] Jason Wei,王雪智,Dale Schuurmans,Maarten Bosma,Fei Xia,Ed Chi,Le Quoc V,Denny Zhou,等。链式思维提示激发了大型语言模型中的推理。神经信息处理系统进展,35:24824-24837, 2022年。
[29] 丁若萌,张朝云,王路,许勇,马明华,张伟,秦思,Saravan Rajmohan,林清伟,张东美。万物思想:违背彭罗斯三角定律的思想生成。在ACL 2024计算语言学协会发现,页码1638-1662, 2024年。
[30] Cheng Kanzhi,Sun Qiushi,Chu Yougang,Xu Fangzhi,Li YanTao,Zhang Jianbing,Wu Zhiyong。Seeclick:利用GUI定位进行高级视觉GUI代理。在计算语言学协会第62届年度会议论文集(第一卷:长篇论文),页码9313-9332, 2024年。
[31] Gou Boyu,Wang Ruohan,Zheng Boyuan,Xie Yanan,Chang Cheng,Shu Yiheng,Sun Huan,Su Yu。像人类一样导航数字世界:GUI代理的通用视觉定位。arXiv预印本 arXiv:2410.05243, 2024年。
[32] Reis Dillon,Kupec Jordan,Hong Jacqueline,Daoudi Ahmad。实时飞行物体检测与YOLOv8。arXiv预印本 arXiv:2305.09972, 2023年。
[33] Xiao Bin,Wu Haiping,Xu Weijian,Dai Xiyang,Hu Houdong,Lu Yumao,Zeng Michael,Liu Ce,Yuan Lu。Florence-2:推进各种视觉任务的统一表示。在IEEE/CVF计算机视觉与模式识别会议论文集,页码4818-4829, 2024年。
[34] Song Yueqi,Fank Xu,Zhou Shuyan,Neubig Graham。超越浏览:基于API的Web代理。arXiv预印本 arXiv:2410.16464, 2024年。
[35] Dong Qingxiu,Li Lei,Dai Damai,Zheng Ce,Ma Jingyuan,Li Rui,Xia Heming,Xu Jingjing,Wu Zhiyong,Chang Baobao,等。关于上下文学习的调查。在2024年实证方法在自然语言处理会议论文集,页码1107-1128, 2024年。
[36] Min Sewon,Lyu Xinxi,Holtzman Ari,Artetxe Mikel,Lewis Mike,Hajishirzi Hannaneh,Zettlemoyer Luke。重新思考示范的作用:是什么使上下文学习起作用?在2022年实证方法在自然语言处理会议论文集,页码11048-11064, 2022年。
[37] Zhang Chaoyun,Ma Zicheng,Wu Yuhao,He Shilin,Qin Si,Ma Minghua,Qin Xiaoting,Kang Yu,Liang Yuyi,Gou Xiaoyu,等。Allhands:通过大型语言模型在大规模逐字反馈中问我任何事。arXiv预印本 arXiv:2403.15157, 2024年。
[38] Man Luo,Xin Xu,Liu Yue,Pasupat Panupong,Kazemi Mehran。语言模型中的上下文学习与检索示范:调查。机器学习研究交易。
[39] Wang Siyuan,Long Zhuohan,Fan Zhihao,Huang Xuan-Jing,Wei Zhongyu。基准自进化:动态LLM评估的多代理框架。在第31届国际计算语言学会议论文集,页码3310-3328, 2025年。
[40] Patrick Lewis,Ethan Perez,Aleksandra Piktus,Fabio Petroni,Vladimir Karpukhin,Naman Goyal,Heinrich Küttler,Mike Lewis,Wen-tau Yih,Tim Rocktäschel,等。检索增强生成用于知识密集型NLP任务。神经信息处理系统进展,33:9459-9474, 2020年。
[41] Liu Jun,Zhang Chaoyun,Qian Jiaxu,Ma Minghua,Qin Si,Bansal Chetan,Lin Qingwei,Rajmohan Saravan,Zhang Dongmei。大型语言模型可以提供准确且可解释的时间序列异常检测。arXiv预印本 arXiv:2405.15570, 2024年。
[42] Gao Yunfan,Xiong Yun,Gao Xinyu,Jia Kangxiang,Pan Jinliu,Bi Yuxi,Dai Yi,Sun Jiawei,Wang Haofen,Wang Haofen。检索增强生成用于大型语言模型:调查。arXiv预印本 arXiv:2312.10997, 2, 2023年。
[43] Jiang Yuxuan,Zhang Chaoyun,He Shilin,Yang Zhihao,Ma Minghua,Qin Si,Kang Yu,Dang Yingnong,Rajmohan Saravan,Lin Qingwei,等。Xpert:通过大型语言模型推荐查询以增强事件管理。在IEEE/ACM第46届国际软件工程会议论文集,页码1-13, 2024年。
[44] Karissa Miller 和 Mahmoud Pegah. 虚拟化:几乎就在桌面。在第35届年度ACM SIGUCCS秋季会议论文集,页码255-260, 2007年。
[45] Aditya Venkataraman 和 Kishore Kumar Jagadeesha. 进程间通信机制的评估。架构, 86(64), 2015年。
[46] Nils Reimers 和 Iryna Gurevych. Sentence-BERT: 使用Siamese BERT网络的句子嵌入。在2019年经验方法在自然语言处理会议和第九届国际自然语言处理联合会议(EMNLPΓJCNLP)论文集, 页码3982-3992, 2019年。
[47] Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, Segev Shlomov. ST-WebAgentBench: 用于评估Web代理安全性和可信度的基准。arXiv预印本arXiv:2410.06703, 2024.
[48] 陈东平,陈若曦,张世霖,王瑶晨,刘阴诺,周慧驰,张启辉,万瑶,周潘,孙立超。MLLM-as-a-judge: 使用视觉语言基准评估多模态LLM-as-a-judge。在第四十一届国际机器学习会议上,2024.
[49] Rogerio Bonatti, Dan Zhao, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Keunho Jang, 等。Windows Agent Arena: 大规模评估多模态OS代理。在NeurIPS 2024 Workshop on Open-World Agents.
[50] 谢天宝,张丹阳,陈纪轩,李晓川,赵思恒,曹瑞升,涂景华,程周军,申东灿,雷方宇,等。OSWorld: 在真实计算机环境中针对开放式任务的多模态代理基准测试。神经信息处理系统进展,37:52040-52094, 2024.
[51] Saaket Agashe, Han Jiuzhou, Gan Shuyu, Yang Jiachen, Li Ang, Wang Xin Eric. Agent S: 一种像人类一样使用计算机的开放代理框架。在第十三届国际学习表示会议.
[52] 卢正西,柴玉祥,郭雅萱,尹曦,刘亮,王浩,熊冠京,李洪胜。UI-R1: 通过强化学习增强GUI代理的动作预测,2025.
[53] Linux From Scratch. AT-SPI - 辅助技术服务提供商接口。https://www.linuxfromscratch.org/blfs/view/5.1/gnome/atspi.html. 获取日期:2025-03-31.
[54] Apple Inc. Accessibility API. https://developer.apple.com/ documentation/accessibility/accessibility-api, 2025. 获取日期:2025-03-31.
[55] Hong Wenyi, Wang Weihan, Lv Qingsong, Xu Jiazheng, Yu Wenmeng, Ji Junhui, Wang Yan, Wang Zihan, Dong Yuxiao, Ding Ming, 等. Cogagent: 一种用于GUI代理的视觉语言模型。在IEEE/CVF计算机视觉和模式识别会议论文集,页码14281-14290, 2024.
[56] Wang Weihan, Lv Qingsong, Yu Wenmeng, Hong Wenyi, Qi Ji, Wang Yan, Ji Junhui, Yang Zhuoyi, Zhao Lei, Song XiXuan, 等. Cogvlm: 预训练语言模型的视觉专家。神经信息处理系统进展,37:121475-121499, 2024.
[57] Ge Yingqiang, Ren Yujie, Hua Wenyue, Xu Shuyuan, Tan Juntao, Zhang Yongfeng. LLM作为OS,代理作为应用:设想AIOS及其代理生态系统。arXiv预印本arXiv:2312.03815, 2023.
[58] Mei Kai, Zhu Xi, Xu Wujiang, Hua Wenyue, Jin Mingyu, Li Zelong, Xu Shuyuan, Ye Ruosong, Ge Yingqiang, Zhang Yongfeng. AIOS: LLM代理操作系统。arXiv预印本arXiv:2403.16971, 2024.
[59] Balaji Rama, Kai Mei, Yongfeng Zhang. Cerebrum (AIOS SDK): 一个用于代理开发、部署、分发和发现的平台,2025.
[60] Chen Huilai, Wen Yuanbo, Cheng Limin, Kuang Shouxu, Liu Yumeng, Li Weijia, Li Ling, Zhang Rui, Song Xinkai, Li Wei, 等. AutoOS: 利用大型语言模型让你的操作系统更强大。在第四十一届国际机器学习会议,2024.
参考论文:https://arxiv.org/pdf/2504.14603

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)