免费在Colab运行Qwen3-0.6B——轻量高性能实战
Qwen一直在默默地接连推出新模型。每个模型都配备了如此强大的功能和高度量化的规模,让人无法忽视。
Qwen一直在默默地接连推出新模型。每个模型都配备了如此强大的功能和高度量化的规模,让人无法忽视。

继今年的QvQ、Qwen2.5-VL和Qwen2.5-Omni之后,Qwen团队现在发布了他们最新的模型系列——Qwen3。
这次他们不是发布一个而是发布了八个不同的模型——参数范围从6亿到2350亿不等——与OpenAI的o1、Gemini 2.5 Pro、DeepSeek R1等顶级模型展开竞争。
简介
Qwen3系列包含8个模型,其中两个是混合专家(Mixture-of-Expert, MoE)模型,而其他6个是密集模型。下表包含了所有这些模型的详细信息:
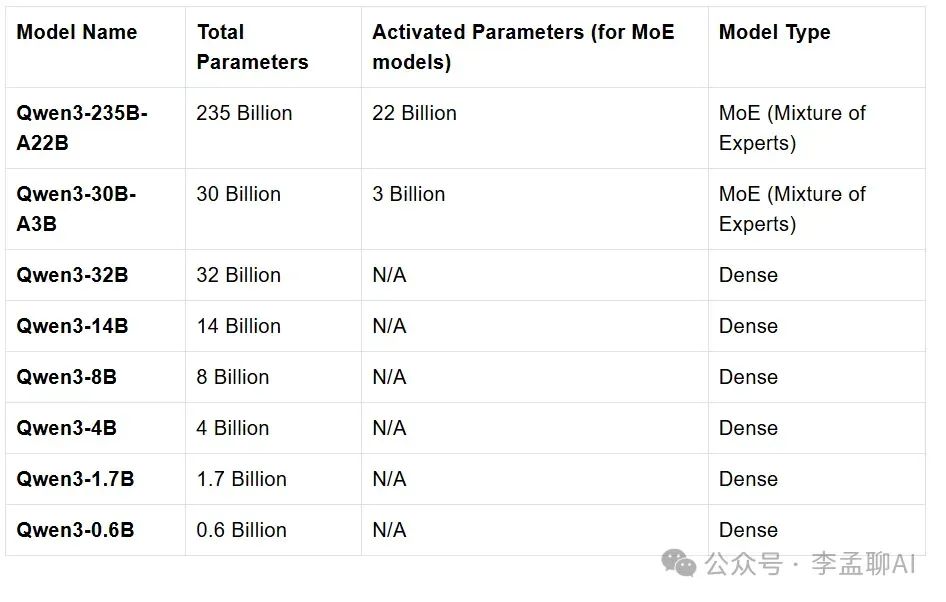
在像Qwen3-235B-A22B和Qwen3-30B-A3B这样的MoE模型中,网络的不同部分或"专家"根据各种输入被激活,使它们高效运行。在像Qwen3-14B这样的密集模型中,对于每个输入,网络的所有部分都会被激活。
Qwen3–0.6B
如果你正在寻找既高效又强大的语言模型,而又不会耗尽你的计算资源,Qwen3-0.6B值得关注。
仅有6亿参数,它带来了令人惊讶的推理能力、多语言灵活性和极快的速度——非常适合开发者、教育工作者和寻求轻量级本地推理的AI爱好者。
在本教程中,我将指导如何在Google Colab上使用Hugging Face的Transformers库免费运行Qwen3-0.6B。
为什么选择Qwen3-0.6B? 在我们深入代码之前,以下是Qwen3-0.6B值得尝试的原因:
-
⚡ 超高效率:仅6亿参数——非常适合Colab或低资源系统。
-
🧠 擅长推理:在STEM/逻辑任务上的表现可与更大的模型相媲美。
-
🌍 多语言支持:在119种语言的36万亿词元上训练。
-
🧩 模式切换:可以在"思考"和"非思考"模式之间切换,智能处理任务。
-
🆓 开源:Apache 2.0许可证——完全自由使用和调整。
步骤详解:在Google Colab上运行Qwen3-0.6B
1. 设置环境
打开一个新的Google Colab笔记本,确保你使用的是GPU(通过运行时 > 更改运行时类型 > GPU)。 安装所需的库:
!pip install transformers accelerate
2. 加载模型和分词器
以下是运行Qwen3-0.6B的核心代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6B"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
3. 生成回应
使用内置的聊天模板准备你的提示和输入格式:
prompt = "请简短介绍一下大型语言模型。"
messages = [
{"role": "user", "content": prompt}
]
# 使用"思考模式"格式化输入
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
4. 生成并解析输出现在,从模型生成文本并将内部"思考"内容与最终回应分开:
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析出思考内容(如果有)
try:
index = len(output_ids) - output_ids[::-1].index(151668) # </think>
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("🧠 思考内容:", thinking_content)
print("🗨️ 最终内容:", content)
⚡ 示例输出 你可能会看到类似这样的内容:
思考内容: <think>
好的,用户想要了解关于大型语言模型的简短介绍。让我首先回顾一下我对这些模型的了解。它们很大,对吧?所以我应该提到它们的规模和能力。也许先给出一个定义来奠定基础。
我需要包括关键点:它们是在海量数据集上训练的,能够理解和生成文本,并有各种任务。此外,可能还要提一下它们的局限性,比如无法回答所有问题或处理特定上下文。等等,我是否应该包括一些关于用例的内容?比如它们如何在不同行业中被使用?
让我检查一下是否遗漏了什么。用户没有指定任何特定行业,所以保持一般性会更好。尽可能避免技术术语,但既然他们要求的是简短介绍,这样是可以的。确保它简明扼要但涵盖主要方面。好的,让我把这些整合起来。
</think>
内容: 大型语言模型(LLM)是一种旨在理解和生成类人文本的人工智能。这些模型在庞大的数据集上进行训练,使它们能够理解复杂概念、回答问题并创建创意内容。它们可以协助完成各种任务,从写作论文到提供客户支持,但在特定上下文或处理模糊信息时有一定局限性。
你可以用Qwen3-0.6B构建什么
-
网站或应用的本地聊天机器人
-
STEM学科的教育助手
-
具有逻辑和推理能力的轻量级智能体
-
多语言内容生成器
结语
Qwen3-0.6B证明了较小的模型正变得更加智能。
它在其规模内表现出色,可以轻松在Colab上运行,并且采用开放使用许可。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献563条内容
已为社区贡献563条内容

所有评论(0)