AI大模型Agent RFT强化微调教程(非常详细)从零基础入门到精通,收藏这一篇就够了!
RFT 的核心启发是:有时候,最好的优化来自放手让模型自己探索。我们习惯把 Agent 的每一步都规定好,生怕它走错路。但 RFT 告诉我们,只要给它一个明确的目标(奖励函数)和足够的工具,它可能会找到你想不到的优化策略。如果你想尝试 RFT,建议:1从小规模开始:几十到几百个样本就够了。2把精力投在评估器上:这比优化 Prompt 重要得多。3同时优化准确性和效率:用多维度评分。4定期检查奖励欺
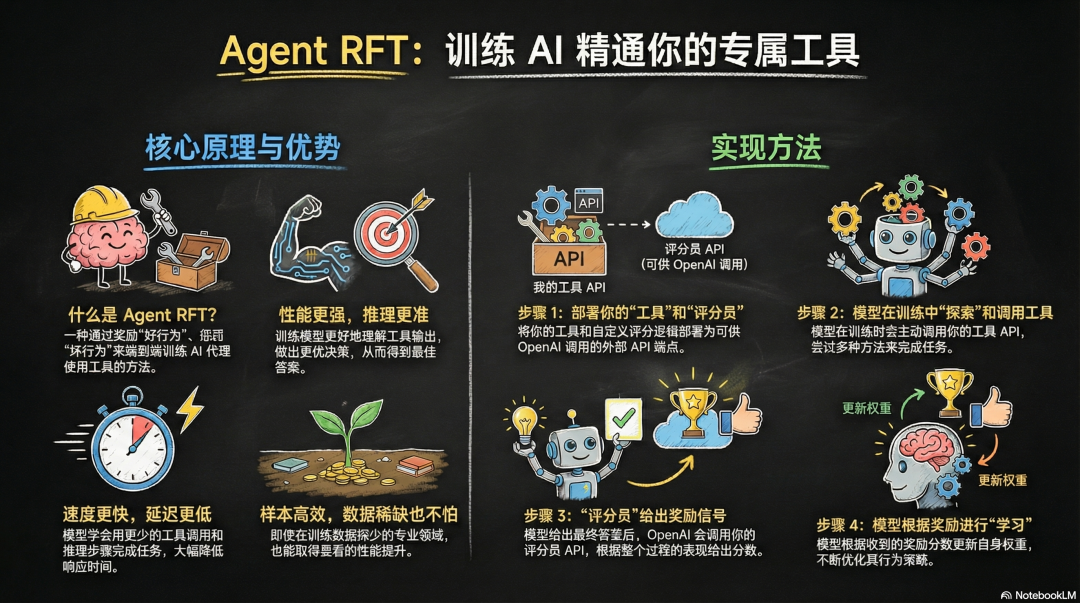
文章核心内容是介绍OpenAI的Agent RFT(强化微调)技术,这是一种让Agent通过自身试错、根据奖励信号调整策略的优化方法。与传统人工调优不同,RFT让Agent在实际任务中学习,自主寻找最优解决方案。文章详细解释了RFT的原理、训练过程、评估器设计原则、适用场景及实际效果,并提供了API使用指南。RFT特别适合需要优化效率的任务。
做过 Agent 开发的朋友应该都有体会,调 Prompt 真是个细活儿。有时候就改了几个词,模型的表现就可能天差地别。工具描述写得不够清楚,工具数量一多,模型就不知道该怎么选择了。任务定义稍微含糊一点,输出就开始极不稳定。这也是为什么很多 Agent 产品发布都很惊艳,但实际场景一上手就完全是另外一回事了。
最近看到 OpenAI 在 Build Hour 上聊了个新东西,叫 Agent RFT,强化微调。走的是另外一条完全不同的路,也就是不再人工调优,而是让 Agent 自己去实际任务里试错,做对了就奖励,做错了就惩罚,这样 Agent 自己就可以找到最优的道路。本文是 Agent RFT 视频的一些学习笔记,推荐观看原视频 https://www.youtube.com/watch?v=1s_7RMG4O4U。
NotebookLM生成的原理图
Agent 的本质
Agent 的本质是工具调用循环,它能够和外部世界互动,独立完成任务,不需要总是等着人工介入。
为了把事情做好,Agent 就必须能访问工具。编程 Agent 需要访问终端、代码解释器,甚至整个代码库。客服 Agent 可能需要访问内部软件,查找客户记录、管理退款,或者决定要不要升级给人工处理。
Agent 与外部世界的所有交互都会流回它的上下文窗口。Agent 根据工具的输入输出进行推理,进而再调用另一个工具,周而复始,直到完成整个循环。
传统 Agent 优化方法
当 Agent 性能不够好时,大家通常会尝试三板斧:
1
Prompt 工程:优化提示词,引导模型更好地完成任务。
2
工具优化:增减工具,改进工具本身,调整工具的描述和命名。
3
任务简化:简化任务,添加护栏,提高成功率。
这三板斧在很多场景下确实有用。但当你把它们都用完了,性能还是不够好怎么办?
OpenAI 给出的新答案就是 Agent RFT。它能够端到端地训练 Agent,根据用户指定的奖励信号来改变模型的权重。奖励信号教会模型哪些是好的行为,哪些是不够好的行为。
Agent RFT
Agent RFT 的核心是强化学习,其核心思想很简单:Agent 尝试做某件事,环境给出奖励或惩罚,Agent 根据反馈调整策略。这就像训练小狗。不需要你告诉它每个动作细节,只需要在它做对时给奖励,做错时不给。经过无数次尝试后,小狗自然就学会了。
RFT = 强化学习 + 微调。具体来说:
1
模型会对同一个问题生成多个不同的答案;
2
你定义的评估器会给答案打分;
3
训练算法会强化高分答案对应的推理路径,抑制低分答案的路径;
4
经过多轮迭代,模型逐渐学会生成高分答案。
与 SFT 的区别
传统的监督微调(SFT)是什么样的?你给模型一堆“问题-答案”对,让它死记硬背。
而 RFT 完全不同。它不告诉模型“正确答案是什么”,而是告诉模型“什么是好的行为”。
这种差异也就导致:
•
SFT:模型学会了在特定场景下输出特定答案,但举一反三能力有限。
•
RFT:模型学会了如何更好地使用工具、如何更高效地推理,能力可以迁移到类似任务。
Will 和 Theo 在分享里提到一个特别好的观点:SFT 就像让学生死记硬背教科书,而 Agent RFT 则是让学生进入实验室,允许他们犯错,尝试不同的解题路径,最后根据结果来打分。
RFT 的训练过程
OpenAI 把 RFT 的训练过程比喻成登山,特别贴切。
假如你在一个完全被迷雾笼罩的山上,看不见山顶,也不知道自己在哪。你唯一能感知的,就是脚下的地形——每走一步,能判断自己的位置升高了还是降低了。
你会怎么做?往不同方向试探性地走几步,感受哪个方向让位置升高,然后继续朝那个方向走。不断重复,无数次试探后,自然就会站在山顶上。
RFT 的训练过程就是这样。模型不知道“最优策略”是什么,但它知道每次尝试能拿多少分。它会尝试不同的工具调用顺序,看看哪种顺序得分高,然后逐渐倾向于使用高分策略。经过无数次迭代,找到最优解。
RFT 的效果
OpenAI 团队为了展示 RFT 的实际效果,选择了极具挑战的 FinQA 基准测试,并故意把任务改得更难:不给模型任何财务报告,只给问题,让模型自己在 2800 份财务报告中搜索,还必须在 10 次工具调用内找到答案。
RFT 训练仅 10 个步骤后,平均奖励就从 0.59 提升到 0.63(提高 7%),工具调用次数从 8-9 次降到 4.2 次(减少 53%),平均延迟减少 10%,Token 数减少 40%。也就是说,在没有人教它顺序的情况下,RFT 训练让模型后学会了“精准搜索→确认路径→读取内容”的最高效组合。
除了 FinQA 基准,OpenAI 一些客户公司的案例同样也很精彩:
•
Cognition 的 Devin AI 工程师通过 RFT 学会了并行操作,规划阶段的交互次数从 8-10 次降到 4 次。
•
Ambience 用 RFT 优化 ICD-10 医疗编码任务,F1 分数提升 10%,响应时间减少 18%。
•
GenSpark 通过设计同时评判内容和视觉的评估器,让幻灯片创建 Agent 的性能在不良案例中提升了 88%。
•
MAKO 用仅仅 100 个 PyTorch 提示就让 GPT-4o 学会为新硬件编写 GPU 内核,性能超越现有技术 72%。
•
Rogo 遇到了奖励欺骗问题——模型发现了评估器的漏洞疯狂刷分,修复后核心性能提高 21%,这个教训告诉我们:做 RFT 的核心不是训练模型,而是设计好评估器。
评估器设计
通过前面的案例,可以看到,评估器的设计是 RFT 成功的关键。
OpenAI 团队总结了评估器设计的几个核心原则:
1. 提供梯度奖励
反例(二元评分):0/1 评分方式会让模型困惑:“我明明很接近了,为什么还是零分?”
正确做法(梯度奖励):0-1 浮点分,让模型知道怎么做会拿更高的分。
2. 评估器要能抵抗欺骗
评估器必须能抵抗“奖励欺骗”,比如要能防范下面这些常见的欺骗方式:
•
输出特定格式骗取高分(Rogo 遇到的问题)
•
通过运气猜对答案,但推理过程是错的
•
输出大量信息,把正确答案淹没在其中
设计技巧:
•
使用 Model Grader 而不是简单的字符串匹配
•
检查推理过程,而不只是最终答案
•
对“幸运猜对”给予低分
•
设计多维度评分(如 GenSpark 同时评判内容和视觉)
3. 符合领域知识
评估器的评判标准必须与人类专家保持一致。检验方法:
•
让人类专家评判一批样本
•
让评估器评判同样的样本
•
计算两者的一致性(如 Cohen’s Kappa)
如果一致性低,说明评估器的标准有问题,需要调整。
4. 明确评分维度
对于复杂任务,最好使用多维度评分。OpenAI 提供了 Multi-Grader 配置:
{ "type": "multi", "graders": { "accuracy": { "type": "score_model", "weight": 0.5 }, "efficiency": { "type": "string_check", "weight": 0.3 }, "format": { "type": "text_similarity", "weight": 0.2 } }, "calculate_output": "0.5 * accuracy + 0.3 * efficiency + 0.2 * format"}
这样可以同时优化多个目标。
5. 考虑效率因素
除了准确性,RFT 还可以优化效率。方法是在奖励函数中添加效率惩罚:
reward = accuracy_score - 0.01 * num_tool_calls - 0.001 * num_tokens
这种设计会鼓励模型:
•
用更少的工具调用
•
生成更简洁的推理过程
•
在保持准确率的前提下提升效率
这就是为什么 FinQA 案例中,模型自发地减少了工具调用次数。
什么时候适合用 RFT
RFT 虽然强大,但不是万能的。什么时候该考虑使用 RFT 呢?OpenAI 给出了四个关键信号:
1. 任务明确且受约束
任务需要具备领域知识或审美方面的共识。
好的例子:
•
医疗编码:有明确的 ICD10 标准
•
数学问题:有确定的正确答案
•
代码正确性:可以通过测试验证
不好的例子:
•
创意写作:没有绝对的正确答案
•
情感分析:主观性太强
•
开放式头脑风暴:目标不明确
2. 有非零的基线性能
模型必须有时能做对。如果基线成功率是 0%,RFT 也无能为力。
检验方法:
•
对每个样本运行多次(如 3-5 次)
•
看看"最佳轨迹"的平均性能
•
如果最佳轨迹的准确率 > 20%,RFT 有戏
3. 有足够的方差
如果模型每次运行的结果都一样,RFT 没有空间去学习“什么是好的”。
理想情况:
•
同一个问题,模型多次运行会有不同表现
•
有些运行能得高分,有些得低分
•
RFT 会推动所有运行向高分运行看齐
4. 你需要优化效率,不只是准确率
如果你只是想提高准确率,传统的 SFT 可能就够了。
但如果你还想:
•
减少工具调用次数
•
降低延迟
•
减少 Token 消耗
那 RFT 就是理想选择。
RFT 不适用的场景
以下情况不建议使用 RFT:
•
任务太简单:单次 LLM 调用就能搞定的任务,没必要 RFT
•
没有评判标准:无法定义"什么是好的"
•
基线性能为零:模型完全不会做任务
•
数据太少且质量差:虽然 RFT 样本高效,但也需要一定的数据量
工作流建议
OpenAI 给出的优化流程是:
1
构建高质量数据集:确保训练集和评估集紧密匹配你的生产流量。
2
建立基线:运行评估,了解基线性能。
3
非 RFT 优化:先尝试 Prompt 工程、工具优化等简单方法。
4
转向 RFT:当简单方法到瓶颈时,再使用 RFT。
记住:只有在明确改善结果时,才应该增加复杂性。
动手试试:API 使用指南
OpenAI 已经把示例代码放到了 Github 上,你可以到 https://github.com/openai/build-hours/tree/main/20-agent-rft 下载尝试。
基本配置
创建 RFT 任务需要:
1
训练数据和测试数据文件 ID
2
定义评估器
3
基础模型(比如 gpt-5-2025-08-07)
4
可选:JSON Schema(如果使用 Structured Outputs)
5
可选:超参数配置
简单示例
1. 上传训练和测试数据
from openai import OpenAIclient = OpenAI()training_file = client.files.create( file=open("training_data.jsonl", "rb"), purpose="fine-tune")validation_file = client.files.create( file=open("validation_data.jsonl", "rb"), purpose="fine-tune")
2. 定义评估器
GRADER_OBJECT: dict = { "type": "score_model", "name": "gpt41_score_model_1", "input": [ { "role": "system", "content": """## System Prompt — Numerical GraderYou will be provided with the following information:- the Reference Answer- a value containing the Model's Answer.Your job is to score the Model's Answer.### Scoring RulesReturn a score of 1 if both are true:- Model's Answer contains only the final numeric answer (no extra words)- The numeric value matches the Reference Answer within slight unit differencesUnit/format variations that still count as correct:- Currency symbols (e.g., $, USD)- Magnitude suffixes (e.g., M, million, K)- Percent formats (e.g., 7% vs 0.07)- Commas and whitespace differencesReturn a score of 0.5 if the Model's Answer is very close to the Reference Answer, but is off by a tenth of a percent or less or appears to be a true rounding error.Return a score of 0 in all other cases.Please only return the numerical score, and nothing else.""" }, { "role": "user", "content": """- Reference Answer: {{item.reference_answer}}.- Model's Answer: {{sample.output_text}}.""" } ], "pass_threshold": 0.75, "model": "gpt-4.1-2025-04-14", "range": [0, 1], "sampling_params": { "temperature": 0, },}
3. 创建 RFT 任务
model = "gpt-5-2025-08-07"reasoning_effort = "medium"n_epochs = 1seed = 42grader = GRADER_OBJECTresponse_format = Nonecompute_multiplier = 1eval_samples = 2eval_interval = 5batch_size = 16max_episode_steps = 50suffix = f"{project}-max_episode_steps_{max_episode_steps}"job = client.fine_tuning.jobs.create( training_file=training_file.id, validation_file=validation_file.id, model=model, suffix=suffix, method=dict( type="reinforcement", reinforcement=dict( tools=JOB_LEVEL_TOOLS, grader=GRADER_OBJECT, response_format=RESPONSE_FORMAT_COMPLETIONS, max_episode_steps = max_episode_steps, hyperparameters=dict( compute_multiplier=compute_multiplier, eval_samples=eval_samples, eval_interval=eval_interval, n_epochs=n_epochs, reasoning_effort=reasoning_effort, batch_size=batch_size ) ) ), seed=seed)print(f"RFT Job ID: {job.id}")
4. 监控训练
# 获取任务状态job_status = client.fine_tuning.jobs.retrieve(job.id)print(f"Status: {job_status.status}")# 获取训练指标events = client.fine_tuning.jobs.list_events( fine_tuning_job_id=job.id, limit=10)for event in events.data: if event.type == "metrics": print(f"Step {event.data['step']}") print(f"Train Reward: {event.data['train_reward_mean']}") print(f"Valid Reward: {event.data['full_valid_mean_reward']}")
5. 使用微调后的模型
# 训练完成后,使用微调模型response = client.chat.completions.create( model="ft:o4-mini-2025-04-16:org:custom:job-id", messages=[ {"role": "user", "content": "你的问题"} ])print(response.choices[0].message.content)
写在最后
RFT 的核心启发是:有时候,最好的优化来自放手让模型自己探索。我们习惯把 Agent 的每一步都规定好,生怕它走错路。但 RFT 告诉我们,只要给它一个明确的目标(奖励函数)和足够的工具,它可能会找到你想不到的优化策略。
如果你想尝试 RFT,建议:
1
从小规模开始:几十到几百个样本就够了。
2
把精力投在评估器上:这比优化 Prompt 重要得多。
3
同时优化准确性和效率:用多维度评分。
4
定期检查奖励欺骗:模型可能会钻评估器的漏洞。
最后一点很重要:不是所有场景都需要 RFT,先尝试上下文工程、工具优化、任务优化这些传统方法,达到一定瓶颈之后才需要 RFT。
相关链接:
•
视频:https://www.youtube.com/watch?v=1s_7RMG4O4U
•
Agentic RFT 示例代码:https://github.com/openai/build-hours/tree/main/20-agent-rft
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 1
1 0
0- 0



 已为社区贡献180条内容
已为社区贡献180条内容

所有评论(0)