[ComfyUI系列3]换装升级!保持模特不变,无需手动蒙版,实现自动抠图 换衣(附工作流)
上一篇介绍通过FLUX Redux 和Fill相结合实现一键模特换装,\[\[ComfyUI系列2\]AI 时代电商的福音!FLUX Redux 和Fill 相结合实现 模特换装\],但是这套工作流的模特是通过 输入prompt 生成的,在实际的生产业务中,企业往往有自己的模特原图,需要保持已有的模特不变,仅需要替换模特身上的衣服,本篇来介绍利用抠图插件LayerStyle,KJNodes结合FL
上一篇介绍通过FLUX Redux 和Fill相结合实现一键模特换装,[[ComfyUI系列2]AI 时代电商的福音!FLUX Redux 和Fill 相结合实现 模特换装],但是这套工作流的模特是通过 输入prompt 生成的,在实际的生产业务中,企业往往有自己的模特原图,需要保持已有的模特不变,仅需要替换模特身上的衣服,本篇来介绍利用抠图插件LayerStyle,`KJNodes,` `````结合` `````F` `````LUX Tool来实现一键换衣。`
首先看下整体效果:
图 1 是需要模特换的衣服(可以是衣服,也可以是模特图)。
图 2 是企业自有的模特图。
图 3 是换装后的效果图。
模特和服装细节还原度还是比较高的,另外也不会因为模特站姿不正,pose 的原因,导致服装失真,整体效果比较自然、真实。

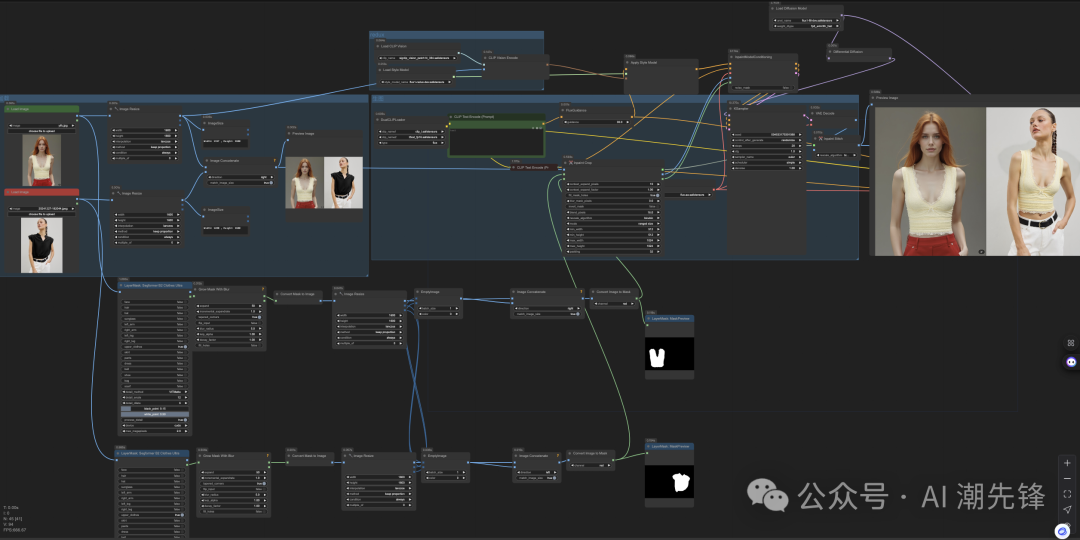
整体工作流如下:
这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

工作流拆解:
1、抠图节点:
要实现一键换衣,首先就得自动抠图,这里使用的插件LayerStyle的节点 LayerMask: Segformer B2 Clothes Ultra
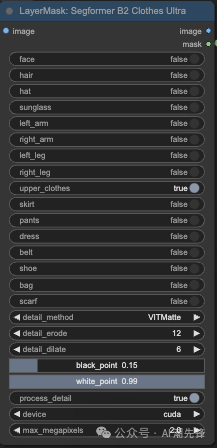
ComfyUI 插件 LayerStyle 中的节点 LayerMask: Segformer B2 Clothes Ultra 是一个图像分割掩码生成器。根据输入图像生成一个分割掩码 (mask),用于区分图像中的不同部分,例如衣服、头发、脸部等。掩码就是我们常说的遮罩
它使用 Segformer B2 模型来识别图像中的不同元素(例如脸、头发、衣服等),并生成一个掩码,项目右侧被标记为 true 的类别会在输出掩码中被包含。
它可以分割以下项目:
-
脸 (face)
-
头发 (hair)
-
帽子 (hat)
-
太阳镜 (sunglass)
-
左臂 (left arm)
-
右臂 (right arm)
-
左腿 (left leg)
-
右腿 (right leg)
-
上衣 (upper clothes)
-
裙子 (skirt)
-
裤子 (pants)
-
连衣裙 (dress)
-
腰带 (belt)
-
鞋子 (shoe)
-
包 (bag)
-
围巾 (scarf)
以下是各个参数的解释:
参数列表:
-
detail_method选择用于细节处理的算法。
VITMatte是一个用于图像抠图的算法,这里用于细化分割结果。 -
detail_erode腐蚀操作的迭代次数,用于去除掩码中的细小噪点。数值越大,去除的噪点越多,掩码边缘越粗糙。
-
detail_dilate膨胀操作的迭代次数,用于扩大掩码中的区域。数值越大,掩码区域越大,边缘越模糊。 (通常情况下,需要先进行腐蚀再进行膨胀,以去除噪点并保持边缘的清晰度。)
-
black_point控制掩码中黑色部分的阈值。数值越小,黑色区域越宽。
-
white_point控制掩码中白色部分的阈值。数值越大,白色区域越宽。
-
process_detail是否进行细节处理,设置为
true表示进行细节处理 (腐蚀和膨胀)。 -
device指定处理图像的设备,这里选择的是
cuda(GPU)。 -
max_megapixels限制处理图像的最大像素数,避免内存溢出,尤其是在处理高分辨率图像时非常重要。
2、遮罩处理
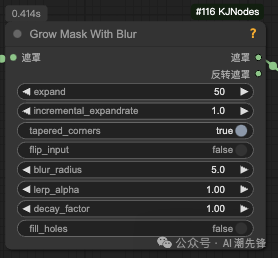
插件KJNodes的节点Grow Mask With Blur,用于扩展和模糊掩码(mask)。一句话总结,这个节点允许你通过调整参数来控制掩码的扩展范围、形状、模糊程度和边缘平滑度,从而实现各种图像处理效果。 建议通过实验不同的参数组合来找到最佳效果。
具体参数解释如下:
-
遮罩(mask):
这是输入的掩码图像。它决定了哪些区域会被扩展和模糊。 通常是一个黑白图像,白色部分代表需要处理的区域,黑色部分则不会被影响。
-
反向遮罩(mask_inverted):
这是一个布尔值(true/false)。如果设置为
true,则会反转输入的掩码。 这意味着原本白色区域会被视为黑色,黑色区域会被视为白色,然后进行扩展和模糊处理。 -
expand:
这是扩展的像素数量。数值越高,掩码扩展的范围越大。 这个值决定了最终掩码的尺寸。
-
incremental_expandrate:
这个参数控制扩展的速率,它影响扩展的形状。值越接近1,扩展就越均匀;值偏离1,扩展速率会变化,可能导致扩展边缘不均匀。 实验不同的值能得到不同的效果。
-
tapered_corners:
这是一个布尔值(true/false)。如果设置为
true,则扩展的边缘会更加平滑,角部过渡更自然,避免出现生硬的直角。如果设置为false,边缘扩展会比较生硬。 -
flip_input:
这是一个布尔值(true/false)。如果设置为
true,则会翻转输入的掩码(水平或垂直,具体取决于上下文,可能需要查看插件的更详细说明)。 -
blur_radius:
这是模糊半径。数值越高,模糊效果越明显。 这个参数控制最终掩码的模糊程度。
-
lerp_alpha:
这参数控制混合(lerp)的程度。具体来说,它控制着扩展的掩码和原始掩码之间的混合比例。 值为1.0表示完全使用扩展后的掩码,值越小,原始掩码的影响越大。
-
decay_factor:
这个参数控制扩展的衰减速率。 值越小,扩展的边缘衰减越快,边缘越清晰;值越大,扩展的边缘衰减越慢,边缘越模糊。
-
fill_holes:
这是一个布尔值(true/false)。如果设置为
true,则会填充掩码中的孔洞,使掩码区域成为一个连续的区域。
3、图像的智能裁剪和修复(Inpainting) --局部重绘的核心
插件Inpaint-CropAndStitch的节点✂️ Inpaint Crop。这个插件结合了图像裁剪和修复功能。你可以通过调整各种参数来控制修复区域的大小、形状、平滑度以及最终图像的尺寸。
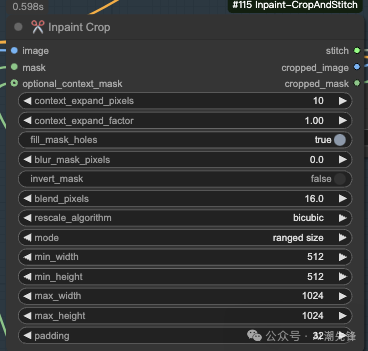
节点✂️ Inpaint Crop是在采样之前裁剪图像的节点。上下文区域可以通过掩码、扩展像素和扩展因子或通过单独的(可选)掩码来指定。
输入节点 (Inputs):
-
image:
这是插件的主要输入,即你需要进行处理的图像。
-
mask:
这是一个掩码图像,它决定了你需要修复(Inpaint)的区域。白色区域表示需要修复,黑色区域表示保留。
-
optional_context_mask:
这是一个可选的上下文掩码。它可以提供额外的信息来帮助修复过程,通常用于定义修复区域周围的上下文范围。
参数节点 (Parameters):
-
context_expand_pixels:
这个参数控制上下文掩码的扩张像素数。数值越大,修复时考虑的周围区域就越大。 如果你的
optional_context_mask为空,这个参数不起作用。 -
context_expand_factor:
这个参数控制上下文掩码的扩张倍数。它与
context_expand_pixels配合使用,可以更精细地控制上下文区域的大小。同样,如果你的optional_context_mask为空,这个参数不起作用。 -
fill_mask_holes:
这个布尔值参数决定是否填充掩码中的孔洞。如果设置为
true,插件会尝试填充掩码中不连续的区域;如果设置为false,则不会填充。 -
blur_mask_pixels:
这个参数控制对掩码进行模糊处理的像素数量。数值越大,掩码边缘越模糊,修复结果可能会更自然,但细节也可能丢失。
-
invert_mask:
这个布尔值参数控制是否反转掩码。如果设置为
true,则白色区域将被视为需要保留,黑色区域将被视为需要修复。 -
blend_pixels:
这个参数控制修复区域与原始图像的融合程度。数值越大,融合越平滑,但可能导致修复区域不够明显。
-
rescale_algorithm:
这个参数选择图像缩放算法。
bicubic是一种常用的高质量缩放算法。 -
mode:
这个参数选择裁剪模式。这里显示的是
ranged size,表示裁剪后的图像大小会在指定范围内。 -
min_width, min_height:
裁剪后图像的最小宽度和高度。
-
max_width, max_height:
裁剪后图像的最大宽度和高度。
-
padding:
在裁剪区域周围添加的填充像素数量。
输出节点 (Outputs):
-
stitch:
原始图像与修复后的图像的拼接结果。
-
cropped_image:
裁剪后的图像。
-
cropped_mask:
裁剪后的掩码。
总结一下,这个插件结合了图像裁剪和修复功能。你可以通过调整各种参数来控制修复区域的大小、形状、平滑度以及最终图像的尺寸。简单一点说,记住它只管裁剪就行。
工作流下载链接:
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)
👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)