自回归新范式!TransDiff:将扩散模型和自回归Transformer结合
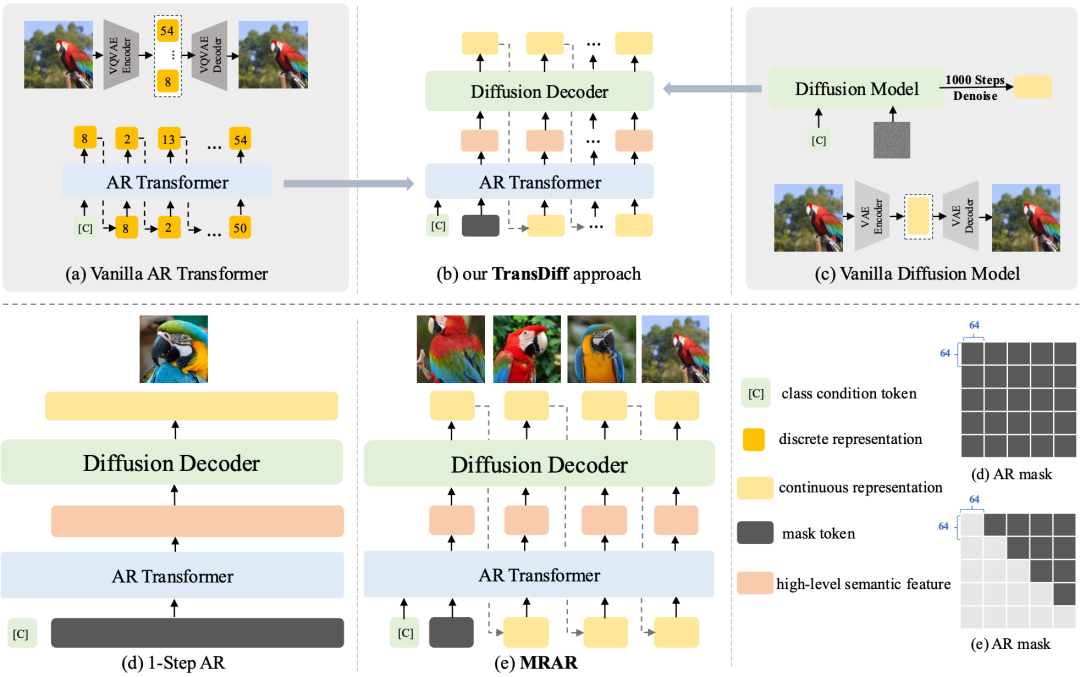
首先,MAR是在像素(或patch)上生成,没有显性的语义表征,其次由于MAR使用的Diffusion Deocder过于简单(n层MLP Layer)导致decoder表现力有制约。但是对比能够搜集到的所有单纯Diffusion和AR Transformer方法,TransDiff在Benchmark上还是有一定优势,至少是“打的有来有回”。此范式类似NLP领域的In-context Learn
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

大家好,今天给大家分享一个图像生成的新工作—-Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression,后面我们简称TransDiff。

首先,TransDiff是目前最简洁的、将AR Transformer与Diffusion结合用于图像生成方法。TransDiff将离散输入(如类别、文本等)、连续输入(图像等)经过AR Transformer 编码 为图像语义表征,而后将表征通过一个较小的Diffusion Deocder 解码 为图片。
其次,我们提出了一种新的自回归范式-- MRAR(Multi-Reference Autoregression)。此范式类似NLP领域的In-context Learning(ICL):通过学习上文同类别图片生成质量更好、更多样的图片,唯一的区别是上文的图片是模型自己生成的。
Paper: https://arxiv.org/pdf/2506.09482
Code:https://github.com/TransDiff/TransDiff
Model: https://huggingface.co/zhendch/Transdiff具体介绍
为了节省读者的时间,抛弃论文的结构,用Q&A这种更简介的方式介绍TransDiff。
问:为什么使用Transformer?我们工作中AR Transformer编码出了什么信息?
答:早期的CLIP工作以及后来大模型时代层出不穷的VL模型已经证明Transformer在图像理解领域的优势。尤其是在CLIP工作中,ViT模型可以将图片的表征对齐到语义空间(文字bert表征与图片的ViT表征cosine相似度)。
相似的,实验证明:TransDiff中AR Transformer也是将类别和图片编码至图片的高级(对比像素)语义空间。以下将不同类别的256维特征随机进行拼接后生成得到图片,不同于其他模型(VAR、LlamaGen等)的像素编辑,定性实验展现出了模型的语义编辑能力。

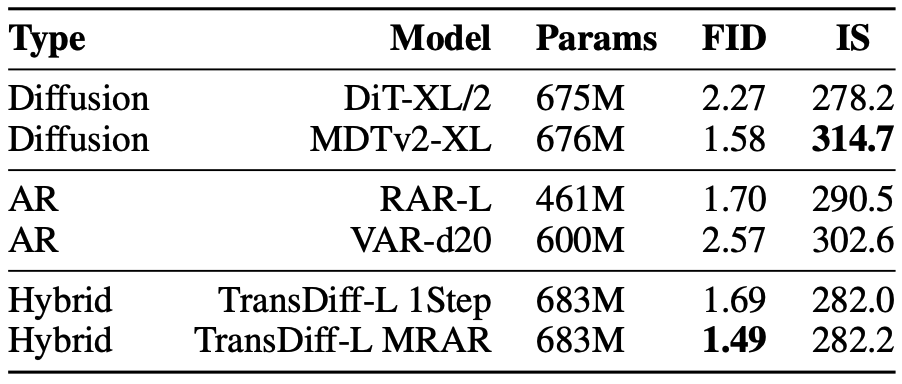
问:TransDiff使用较小Diffusion Deocder是否有制约? 是否优于单纯Diffusion和AR Transformer方法?
答:TransDiff的deocder使用DiT结构,使用Flow Matching范式。diffusion占总体参数的1/3,参数量显著低于主流diffusion模型。但是对比能够搜集到的所有单纯Diffusion和AR Transformer方法,TransDiff在Benchmark上还是有一定优势,至少是“打的有来有回”。
问:TransDiff很像MAR,是否只是MAR的简单模仿?
答:TransDiff与MAR虽然结构上很像,但是模型展现的特点截然不同。首先,MAR是在像素(或patch)上生成,没有显性的语义表征,其次由于MAR使用的Diffusion Deocder过于简单(n层MLP Layer)导致decoder表现力有制约。 因此,从下图可以看出:MAR无法 “一步生图”,且图像patch是在自回归过程中逐步迭代“完善”。

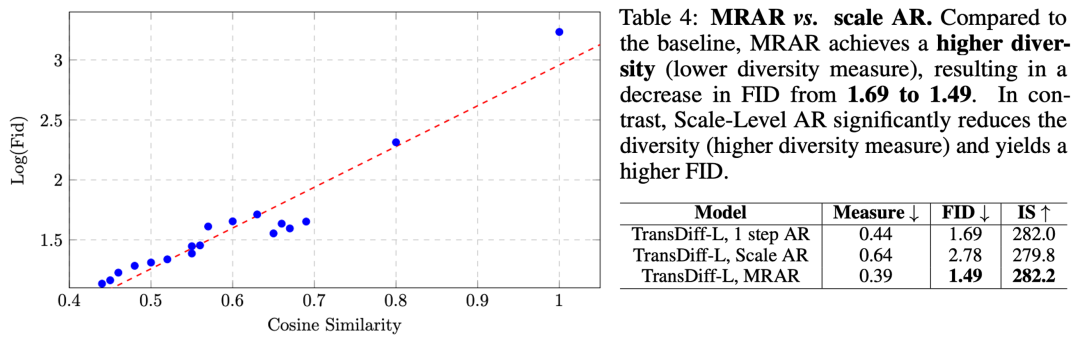
问:MRAR好在哪里? 对比AR Transformer中常用的Token-Level AR 和 Scale-Level AR优势吗?
答:首先对比Token-Level AR和Scale-Level AR,TransDiff with MRAR在在Benchmark上有着较大的优势。其次,我们发现 语义表征多样性越高,图像质量越高。而MRAR相较于Scale-Level AR可以显著提升语义表征多样性。
最后放一些demo

One More Thing
TransDiff with MRAR在未经视频数据训练的情况下,展现出了连续帧生成的潜力。 所以后续也会将TransDiff应用在视频生成领域,大家敬请期待。

何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集
CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。 一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习
▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)人数破万!如果你想要了解最新最快最好的CV/DL/AI论文、实战项目、行业前沿、从入门到精通学习教程等资料,一定要扫描下方二维码,加入CVer知识星球!最强助力你的科研和工作!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)