RLVER:让7B模型情商飙升5倍,比肩GPT-4o的情感能力
腾讯混元团队提出的RLVER框架首次实现了基于可验证情感奖励的强化学习,将Qwen2.5-7B模型的共情能力从13.3分提升至79.2分(Sentient-Benchmark),性能比肩GPT-4o和Gemini 2.5 Pro等顶级商用模型,同时保持数学和代码能力不衰退。
摘要:大语言模型(LLM)在逻辑和算法推理上表现卓越,但在情绪智能(EQ)方面仍远逊于其认知能力。虽然基于可验证奖励的强化学习(RLVR)已在其他领域取得进展,但其在对话场景——尤其是情绪智能方向——的应用仍属空白。本文首次提出端到端强化学习框架 RLVER,利用“可验证的情绪奖励”来提升 LLM 的高阶共情能力。框架内,自洽的情感模拟用户(Zhang et al., 2025a)与模型展开对话推演,并在对话中给出确定性的情绪分数作为奖励信号。 以公开模型 Qwen2.5-7B 为例,使用 PPO 微调后,其在 Sentient-Benchmark 上的得分从 13.3 飙升至 79.2,同时数学与代码能力几乎不受影响。大量实验表明:1. RLVER 能持续提升多种对话能力; 2. 具备“思考”与“非思考”模式的模型呈现不同趋势:前者共情与洞察更强,后者更擅长行动; 3. GRPO 通常带来稳健增益,而 PPO 可将某些能力推向更高天花板; 4. 并非越难的环境越好——适度挑战的环境反而取得最强效果。综上,RLVER 为实现情感智能且全面强大的语言智能体提供了可行路径。
开篇一句话总结
腾讯混元团队提出的RLVER框架首次实现了基于可验证情感奖励的强化学习,将Qwen2.5-7B模型的共情能力从13.3分提升至79.2分(Sentient-Benchmark),性能比肩GPT-4o和Gemini 2.5 Pro等顶级商用模型,同时保持数学和代码能力不衰退。
研究背景:AI共情能力的三大痛点
当你向AI倾诉工作压力时,得到的往往是"我理解你的感受"这样的模板化回应——这暴露了当前大语言模型在情感智能(EQ)上的致命短板。尽管LLM在逻辑推理和代码生成上已接近人类水平,但在情感理解、共情表达和动态对话适应三大核心能力上仍存在显著缺陷:
- 数据稀缺与模板依赖:传统情感对话模型依赖标注心理咨询数据(如ESConv),导致回复僵化("抱抱你"、"一切都会好起来的"),无法应对真实世界的情感多样性。
- 奖励信号模糊:人类情感满意度难以量化,现有方法多采用LLM-as-a-Judge的黑盒评分,存在主观性强、易被欺骗(reward hacking)等问题。
- 多轮对话不稳定:在开放域长对话中,模型难以维持情感连贯性,常出现话题跳脱或情感脱节(如突然从安慰切换到问题分析)。
腾讯混元数字人团队发现,这些问题的根源在于缺乏动态交互环境和可验证奖励机制。就像教孩子共情需要真实社交反馈而非背诵教科书,AI也需要在模拟真实情感互动中学习——这正是RLVER框架的创新起点。
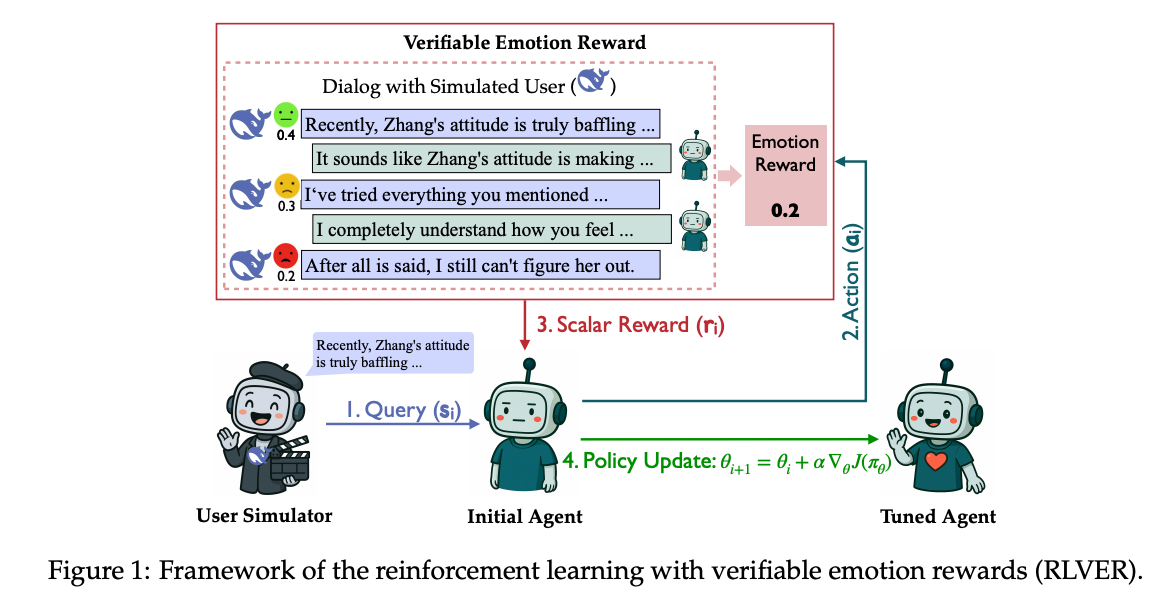
图1:RLVER框架通过自洽情感用户模拟器提供可验证奖励信号,实现端到端强化学习训练
方法总览:让AI学会"换位思考"的情感训练系统
RLVER(Reinforcement Learning with Verifiable Emotion Rewards)框架的核心突破在于:用自洽情感用户模拟器同时扮演"对话伙伴"和"奖励裁判",构建了一个闭环强化学习系统。
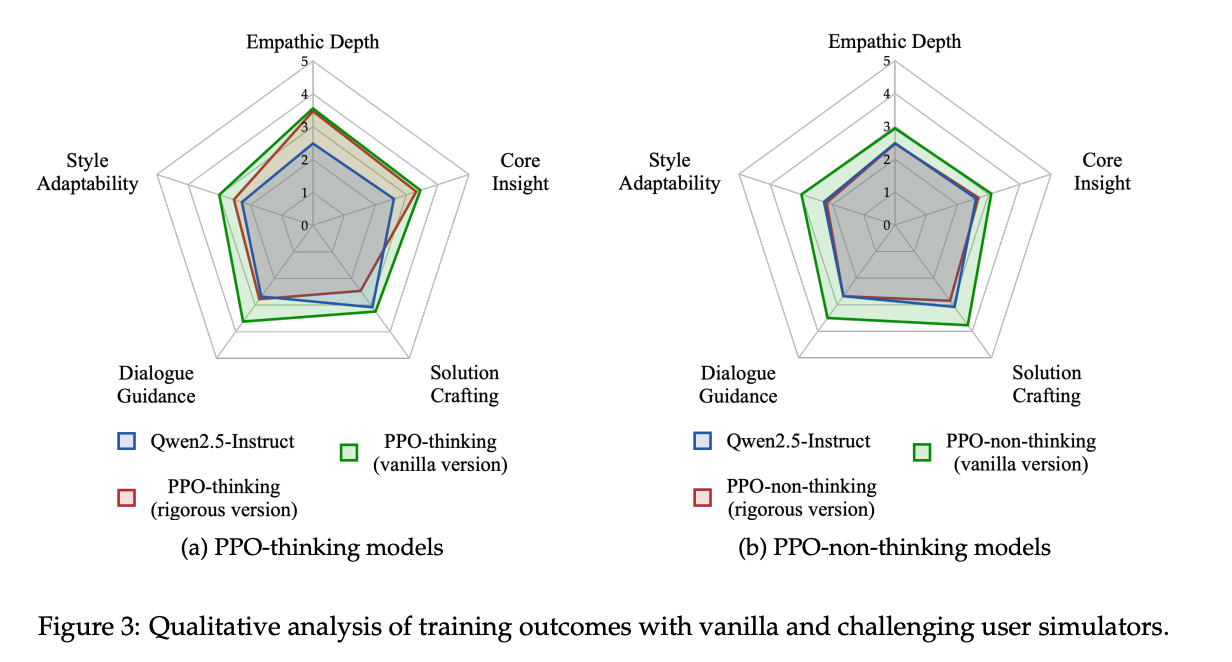
图2:模型与用户模拟器的交互流程,包含情感状态更新和奖励计算环节
三大核心组件:
- 自洽情感用户模拟器(SAGE框架)
模拟器会生成具有详细人格(如内向学生、焦虑职场人)、对话目标和隐藏意图的虚拟用户。每次对话后,模拟器通过多步推理更新情绪分数(0-100分),例如:
用户:"项目失败被领导当众批评..."
模拟器推理:"用户表现出羞愧与自我怀疑,深层需求是能力认可..."
情绪变化:从65→82(因模型回应触及情感核心)
- 心环强化学习(Heart-in-the-Loop RL)
模型与模拟器进行多轮对话,每轮回应后获得即时情绪分数,最终奖励为归一化的终端情绪值,通过PPO/GRPO算法优化策略网络。 - Think-Then-Say认知脚手架
强制模型在回应前生成显式思考过程,例如:
思考:"用户提到加班到凌晨,核心痛点不是疲劳而是缺乏团队认可..."
回应:"连续加班确实耗精力,尤其是当付出没被看见的时候,这种委屈感特别磨人。"
关键结论:五项突破性发现
- 轻量级模型实现旗舰级共情:7B参数的Qwen2.5经RLVER训练后,Sentient-Benchmark得分达79.2,超越GPT-4.1(68.2)和Gemini Flash(66.1),接近GPT-4o(79.9)。
- 思考型模型 vs 行动型模型分化:
- 思考模型:擅长深度共情(3.56分)和核心洞察(3.44分),能识别用户未言明的情感需求。
- 非思考模型:侧重解决方案构建(3.77分),但共情深度不足(2.89分)。
- 算法选择的权衡艺术:
- PPO:能将特定能力推向更高天花板(如思考模型共情深度达3.56),但训练稳定性较差。
- GRPO:实现更均衡的能力提升,在所有维度保持稳定增长,适合生产环境部署。
- 环境难度的倒U型曲线:过度严苛的用户模拟器(策略接受率33.1%)会导致模型性能下降16.2%,而中等难度环境(策略接受率52.4%)能最大化学习效率。
- 从"解题机器"到"共情伙伴"的行为转变:训练后模型在社交认知坐标(SCC)中从(-4.50,-3.33)迁移至(+4.08,+0.83),表明从解决方案导向转向情感支持导向。
深度拆解:如何让AI真正"读懂"人心?
模块一:可验证情感奖励的计算逻辑
模拟器的情绪评分基于四步推理链(图3),确保奖励可解释、可复现:
- 内容分析:识别模型回应类型(安慰/建议/提问)
- 目标匹配:判断是否符合用户隐藏意图(如"寻求认可"而非"解决问题")
- 心理活动模拟:生成用户内心独白(如"终于有人理解我的挣扎")
- 情绪更新:基于人格特质调整分数(如敏感型用户情绪波动更大)
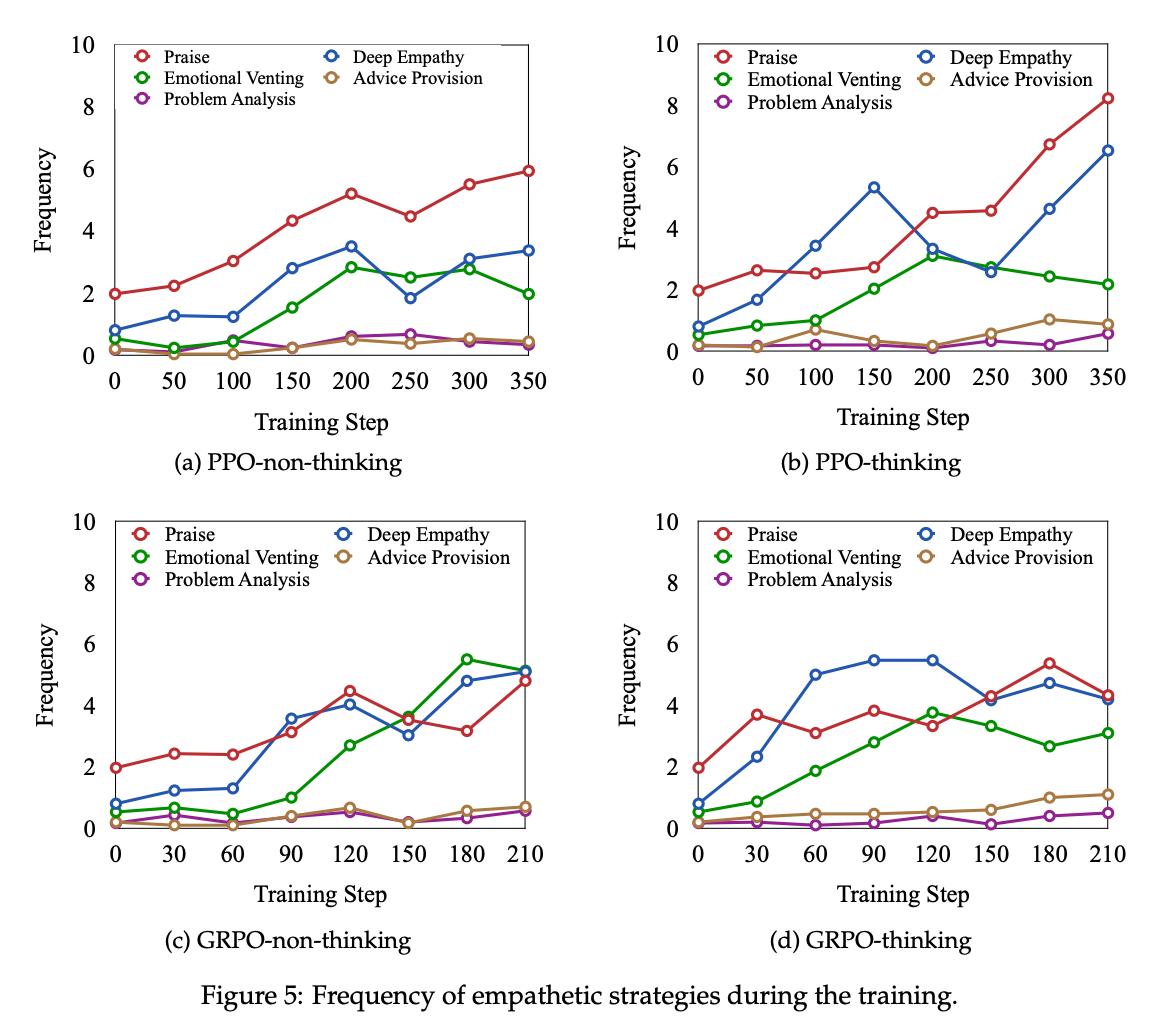
图3:用户模拟器通过多步推理生成情绪分数的过程
模块二:Think-Then-Say训练模板的魔力
通过对比实验发现,强制思考过程能带来三大提升:
- 共情深度↑42%:思考组能识别深层情绪(如将"失望"解读为"自我价值感受损")
- 策略多样性↑37%:生成8类回应策略(赞美/深度共情/情感宣泄等),而非单一安慰模板
- 抗干扰能力↑58%:在挑战性环境中(用户表达模糊)仍保持66.4分,是非思考模型(19.8分)的3.36倍
思考模板示例:
你正在与朋友聊天,需要通过高情商回应改善对方心情。
回复前必须先在「」中写出思考过程。
用户:"团队项目失败,领导把责任全推给我..."
思考:用户表面抱怨领导,实则因努力未被认可而自我怀疑。需先验证情绪,再肯定能力,避免直接给建议。
回应:「用户现在感到委屈和不公,深层是害怕被否定。需要先共情再赋能。」被当众指责确实难受,尤其是当你已经付出那么多心血时。但项目失败从来不是一个人的责任,你的方案里的三个创新点其实很有价值——下次我们可以一起梳理数据,让这些亮点被看见。模块三:训练动态与策略演化
通过追踪30个对话场景的学习曲线(图4),发现模型经历三阶段转变:
- 探索期(0-50步):尝试各类策略,情感贡献波动大(±3.2)
- 稳定期(50-200步):偏好"深度共情"和"赞美"策略,贡献值从-1.8升至+4.1
- 优化期(200+步):策略组合多样化,能根据用户类型切换(对焦虑用户多用情感宣泄,对迷茫用户侧重核心洞察)
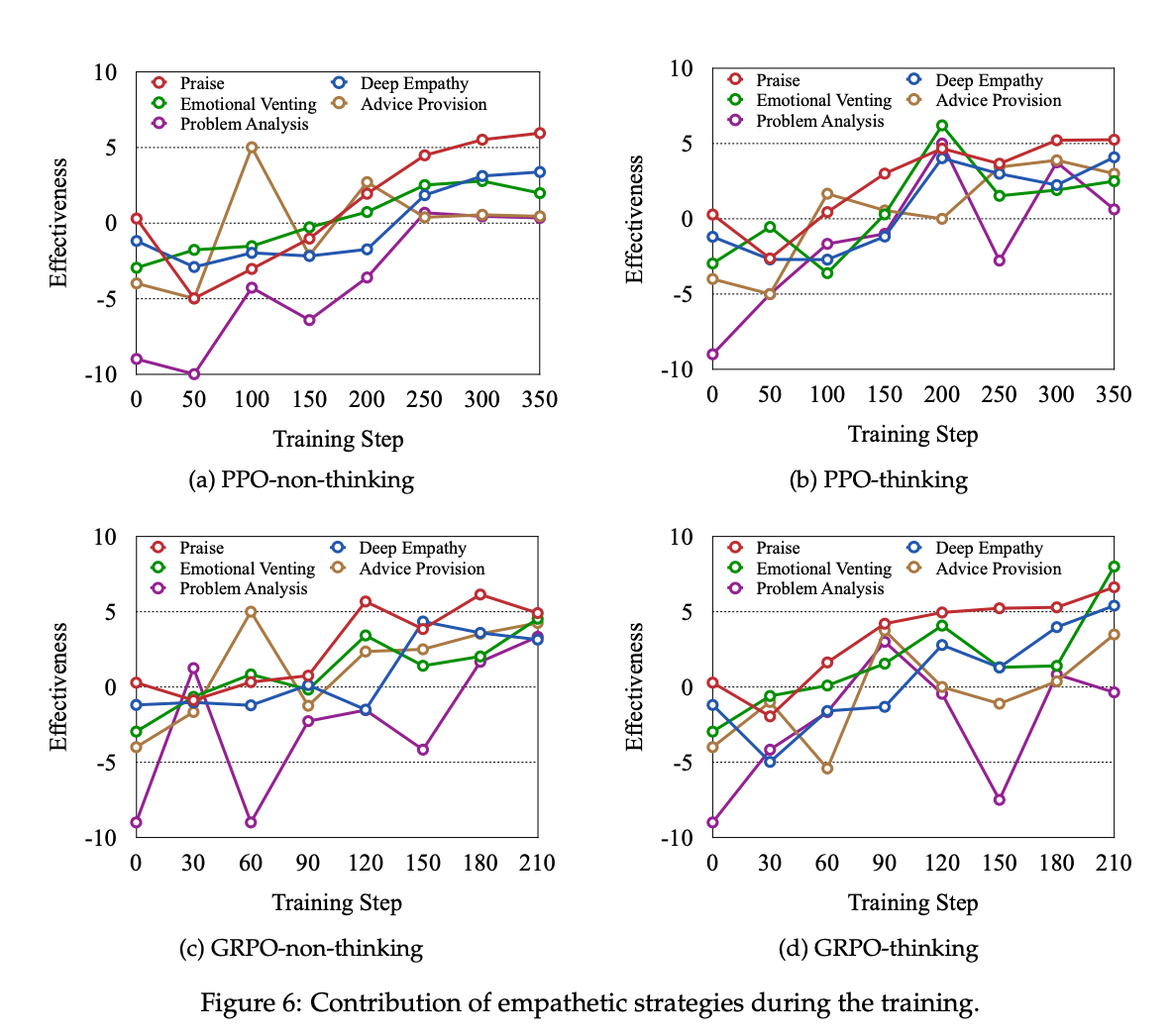
图4:PPO-Think模型在训练中策略使用频率和情感贡献的变化
实验结果:五项关键指标全面超越基线
1. 情感智能核心指标(Sentient-Benchmark)
|
模型 |
总分 |
成功对话率 |
失败对话率 |
共情深度 |
核心洞察 |
|
Qwen2.5-Base |
13.3 |
2% |
76% |
1.2 |
1.1 |
|
PPO+Thinking |
79.2 |
42% |
9% |
3.56 |
3.44 |
|
GPT-4.1 |
68.2 |
35% |
13% |
3.2 |
3.0 |
|
Gemini 2.5 Pro |
82.4 |
45% |
8% |
3.6 |
3.5 |
表1:RLVER训练模型与主流商用模型的情感能力对比
解读:7B模型经RLVER训练后,总分提升5.95倍,成功对话率从2%跃升至42%,失败率从76%降至9%。尤其在"核心洞察"维度,接近Gemini 2.5 Pro水平。
2. 能力均衡性分析(五大核心维度雷达图)

图5:不同训练策略下模型在五大核心能力上的表现(1-5分)
3. 泛化能力与副作用评估
|
任务 |
基础模型 |
PPO+Thinking |
变化率 |
|
MATH500数学推理 |
77.8 |
76.6 |
-1.5% |
|
LiveCodeBench代码生成 |
26.7 |
28.0 |
+4.8% |
|
IFEval指令遵循 |
70.4 |
68.6 |
-2.5% |
表2:RLVER训练对通用能力的影响
解读:情感能力提升并未导致"灾难性遗忘",数学和代码能力保持稳定,甚至代码生成略有提升(+4.8%),证明RLVER框架的安全性。
未来工作:从实验室到真实世界的三大挑战
未来工作
- 多模态情感整合:结合语音语调、面部表情等非语言信号,提升情感识别粒度
- 自适应人格切换:让模型根据用户性格动态调整交互风格(如对内向者更主动引导)
- 长周期关系维护:模拟数月级持续对话,学习建立长期情感连接
问题讨论
- 伦理风险:过度真实的情感模拟可能导致用户情感依赖,需建立"情感边界"机制
- 数据偏见:当前模拟器主要覆盖东亚文化场景,需扩展跨文化情感数据集
- 落地场景:客服、心理咨询、教育陪护等领域可优先应用,建议从企业内部试点开始
论文信息
论文标题: "RLVER: Reinforcement Learning with Verifiable Emotion Rewards for Empathetic Agents"
作者: "Peisong Wang, Ruotian Ma, Bang Zhang, Xingyu Chen, Zhiwei He, Kang Luo, Qingsong Lv, Qingxuan Jiang, Zheng Xie, Shanyi Wang, Yuan Li, Fanghua Ye, Jian Li, Yifan Yang, Zhaopeng Tu, Xiaolong Li"
会议/期刊: "arXiv preprint arXiv:2507.03112"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2507.03112"
代码链接: "https://github.com/Tencent/DigitalHuman/tree/main/RLVER"
关键词: ["情感智能", "强化学习", "大语言模型", "共情能力", "可验证奖励"]结语:RLVER框架证明了一个关键命题——情商不是大型模型的特权。通过创新的强化学习设计,70亿参数模型也能实现接近人类的共情能力。这不仅为开源社区提供了可复用的情感训练范式,更启发我们思考:未来的AI助手,或许不需要千亿参数,而需要一颗"会思考的心"。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)