第1期:PaddleOCR-VL与主流模型对比:为何能在复杂场景中脱颖而出?
本期我们将PaddleOCR-VL与MinerU2.5、MonkeyOCR、GPT-4o等主流模型进行全方位对比,用事实数据与识别结果,揭示PaddleOCR-VL脱颖而出的秘密。如果你正在寻找一个在复杂真实场景下依然稳定、精准、高效的文档解析工具,PaddleOCR-VL无疑是当前最具竞争力的选择。将视觉图表转换为结构化数据,是更高阶的文档理解任务,也是PaddleOCR-VL的突出亮点。为您深

在文档智能领域,各类模型百花齐放。然而,在复杂的真实场景中,谁才是更可靠的选择?
本期我们将PaddleOCR-VL与MinerU2.5、MonkeyOCR、GPT-4o等主流模型进行全方位对比,用事实数据与识别结果,揭示PaddleOCR-VL脱颖而出的秘密。
1.复杂版面布局:稳定精准,告别“幻觉”
在处理多栏、图文混杂等复杂版面时,许多端到端VLM模型容易出现布局错乱或内容“幻觉”(生成不存在的内容)。
✅ PaddleOCR-VL表现:
-
得益于前置的版面分析能力,能够稳定、准确地检测出页面中的所有元素(文本、表格、公式、图像、图表等)和阅读顺序。
❌ 其他模型典型问题:
-
布局遗漏:漏掉页面中的部分元素,如侧边栏、图表等。
-
布局错误:错误预测布局的类别和坐标。
-
顺序错乱:无法正确预测复杂文档的阅读顺序,导致输出内容逻辑混乱。
-
内容幻觉:由于无法确定复杂版面的布局,导致出现预测内容的幻觉。
🥇版面分析与其他模型效果对比:


左右滑动查看更多
结论:在文档解析的“第一步”——布局分析上,PaddleOCR-VL的分离式架构展现了更强的稳定性和准确性。
2.多语言文本识别:精准区分,拒绝“张冠李戴”
多语言混合文档是全球化业务中的常见挑战,在面对小语种文本时容易误识别。
✅ PaddleOCR-VL表现:
-
支持109种语言,并能精准区分不同语种。
-
对俄语、阿拉伯语、希腊语、日语、韩语等109种语言的文档识别准确率高。
❌ 其他模型典型问题:
-
不支持多语言:大多数的多模态模型仅仅针对中英文文档场景,未支持其他语言。
-
语种误判:将俄语、印地语等文字错误地识别为类似形状的英文字母或乱码。
-
编码错误:输出结果出现乱码,可读性差。
🥇多语种文本识别与其他模型效果对比:



左右滑动查看更多
结论:PaddleOCR-VL的多语言能力并非虚名,其精准的语种区分和文字识别能力,使其在国际化场景中表现尤为可靠。
3.手写体与竖排文本:攻克OCR的“顽固堡垒”
手写体和竖排文本是传统OCR的难点,对模型的泛化能力要求极高。
✅ PaddleOCR-VL表现:
-
手写体:对中英文手写文字保持高识别率,字迹工整或略微潦草均能较好处理。
-
竖排文本:完美支持中文竖排古籍、报纸的识别,并能正确保持从上到下、从右到左的阅读顺序。
❌ 其他模型典型问题:
-
手写体:出现丢字、错字现象,识别结果不通顺。
-
竖排文本:
-
-
顺序错误:将竖排文本按从左到右的顺序识别,导致内容完全混乱。
-
识别失败:将竖排文字错误地识别为独立的、无意义的单字。
-
🥇手写体与竖排文本识别与其他模型效果对比:


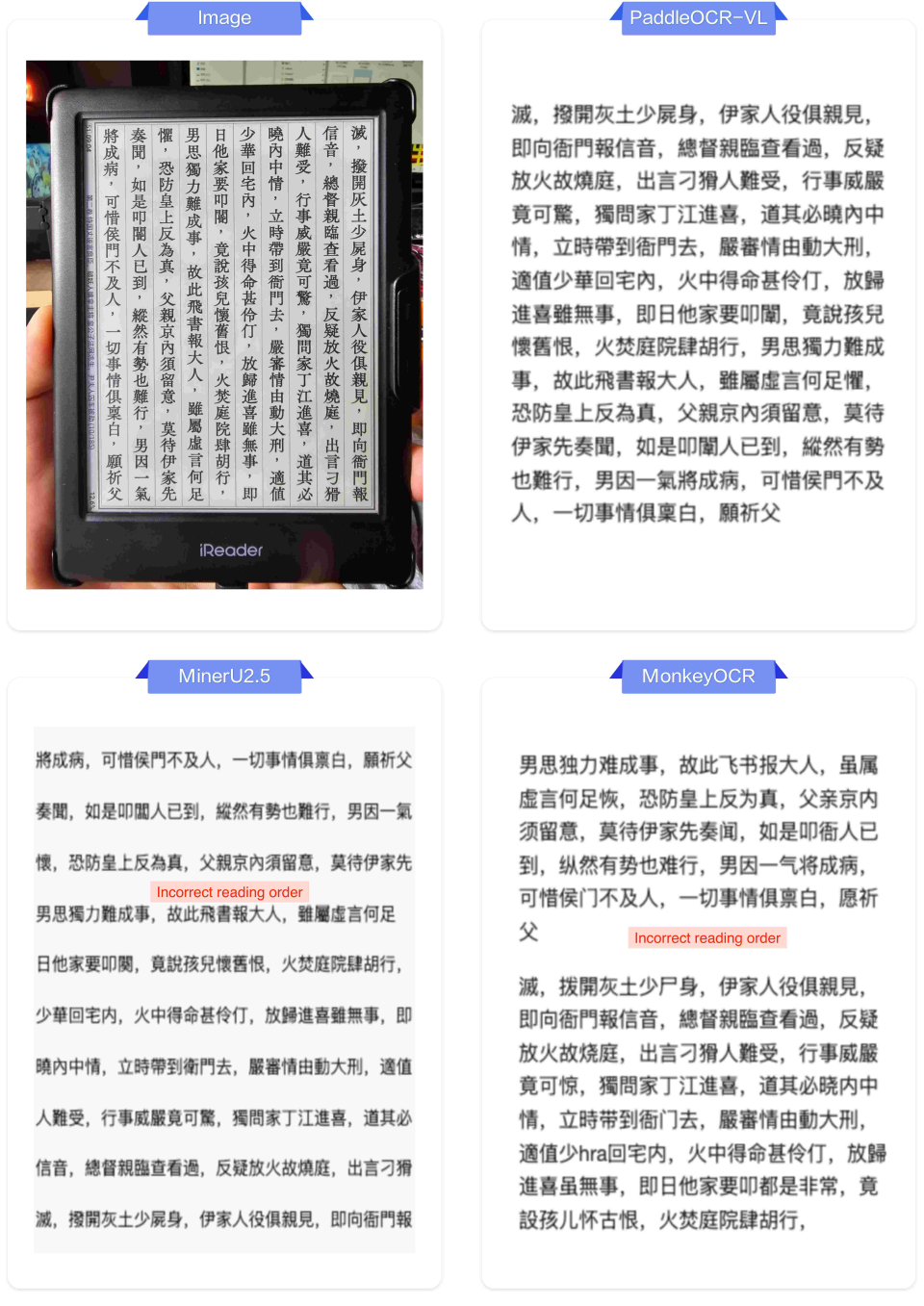
左右滑动查看更多
结论:无论是随性的手写笔迹,还是古老的竖排版式,PaddleOCR-VL都能从容应对,展现出强大的泛化能力和文化适应性。
4.复杂表格与公式:结构理解深远
表格和公式蕴含了文档中最具价值的结构化信息,也是评估模型理解能力的关键。
1. 表格识别
-
✅ PaddleOCR-VL:能准确还原合并单元格、表格标题、行列结构,表格中的公式和图像,输出规整的Markdown或HTML格式,逻辑清晰。
-
❌ 其他模型:常出现结构坍塌、合并单元格识别错误、内容错位等问题,导致表格数据无法使用。
2. 公式识别
-
✅ PaddleOCR-VL:对复杂的数学符号、上下标、分式、矩阵甚至手写公式等都能精准转换为LaTeX代码,格式规范。
-
❌ 其他模型:常出现符号缺失、结构错误(如分式识别错误)、甚至将公式误识别为普通文本。
🥇复杂表格与公式识别与其他模型效果对比:
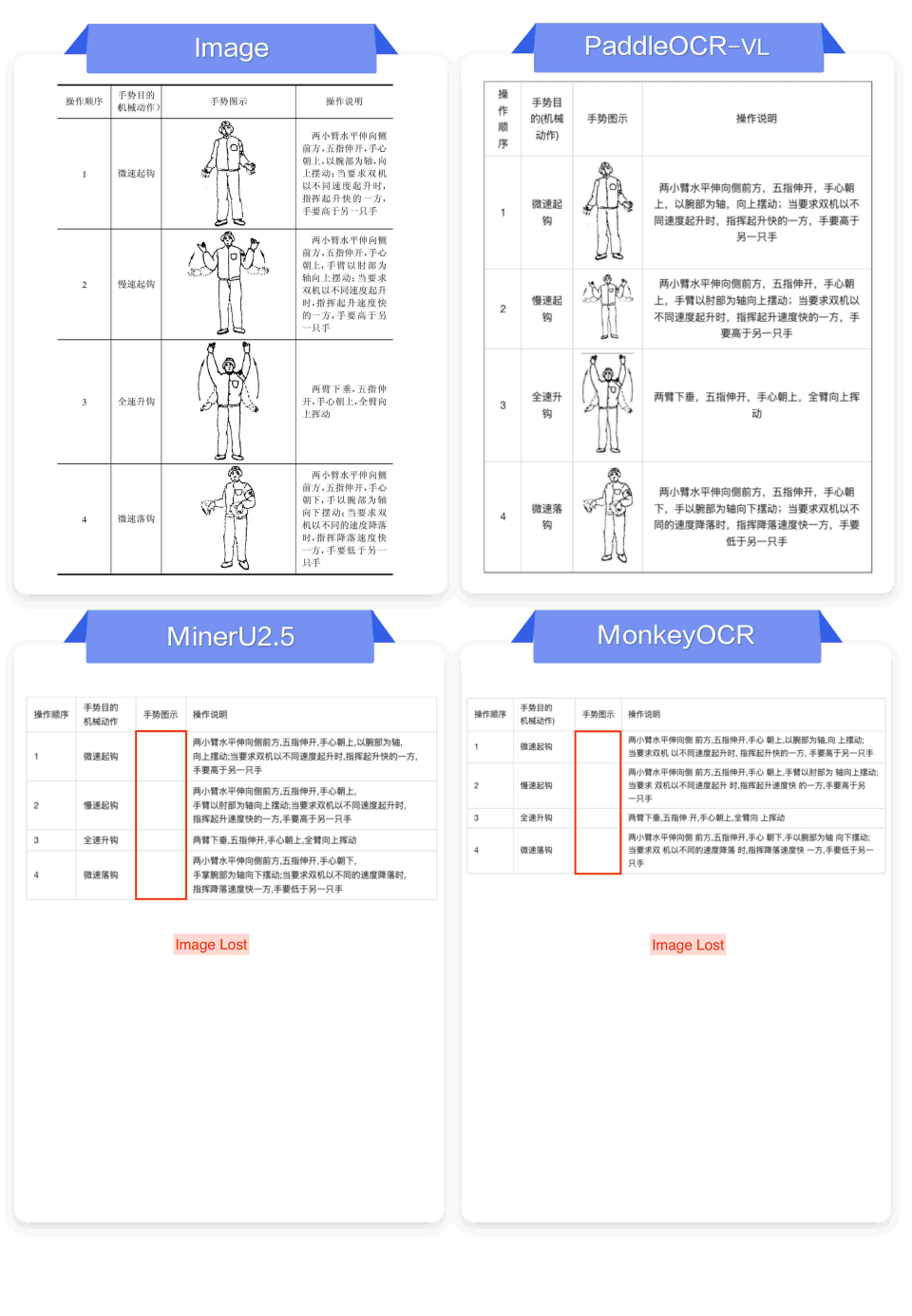

左右滑动查看更多
结论:在需要深度理解的表格和公式任务上,PaddleOCR-VL展现出了接近人类的结构化信息提取能力。
5.图表信息提取:超越OCR的认知能力
将视觉图表转换为结构化数据,是更高阶的文档理解任务,也是PaddleOCR-VL的突出亮点。
✅ PaddleOCR-VL表现:
-
能够理解条形图、折线图、饼图等常见图表,并准确提取其中的数据,生成对应的数据表格(Markdown格式)。
-
能识别坐标轴标签、图例等信息。
❌ 其他模型典型问题:
-
仅描述视觉元素:只能输出“这是一个柱状图,显示了不同类别的数值”,但无法给出具体数据。
-
数据提取错误:提取的数值与图表实际值严重不符。
-
忽略关键信息:漏掉单位、图例或坐标轴标签。
🥇图表信息提取与其他模型效果对比:
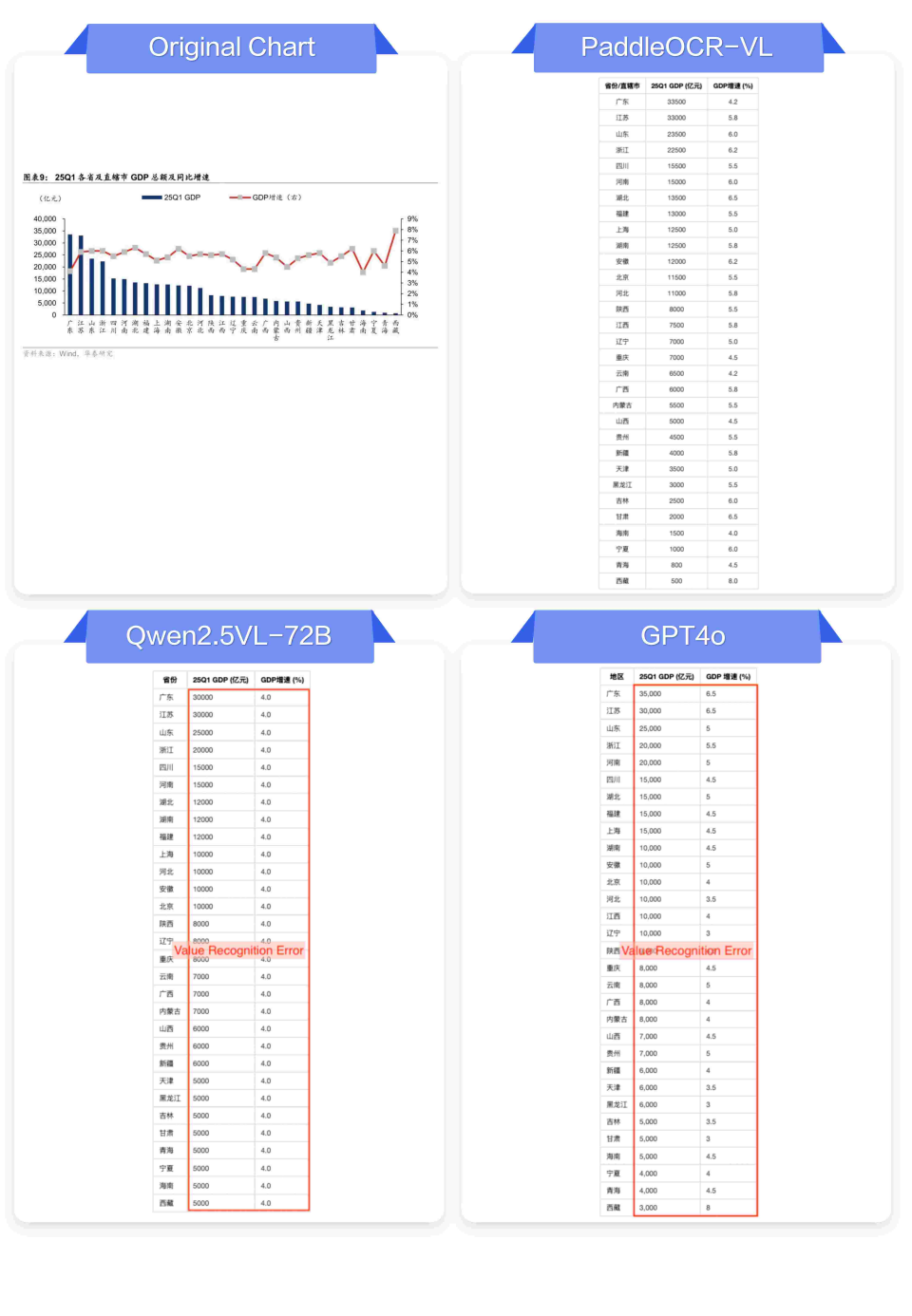
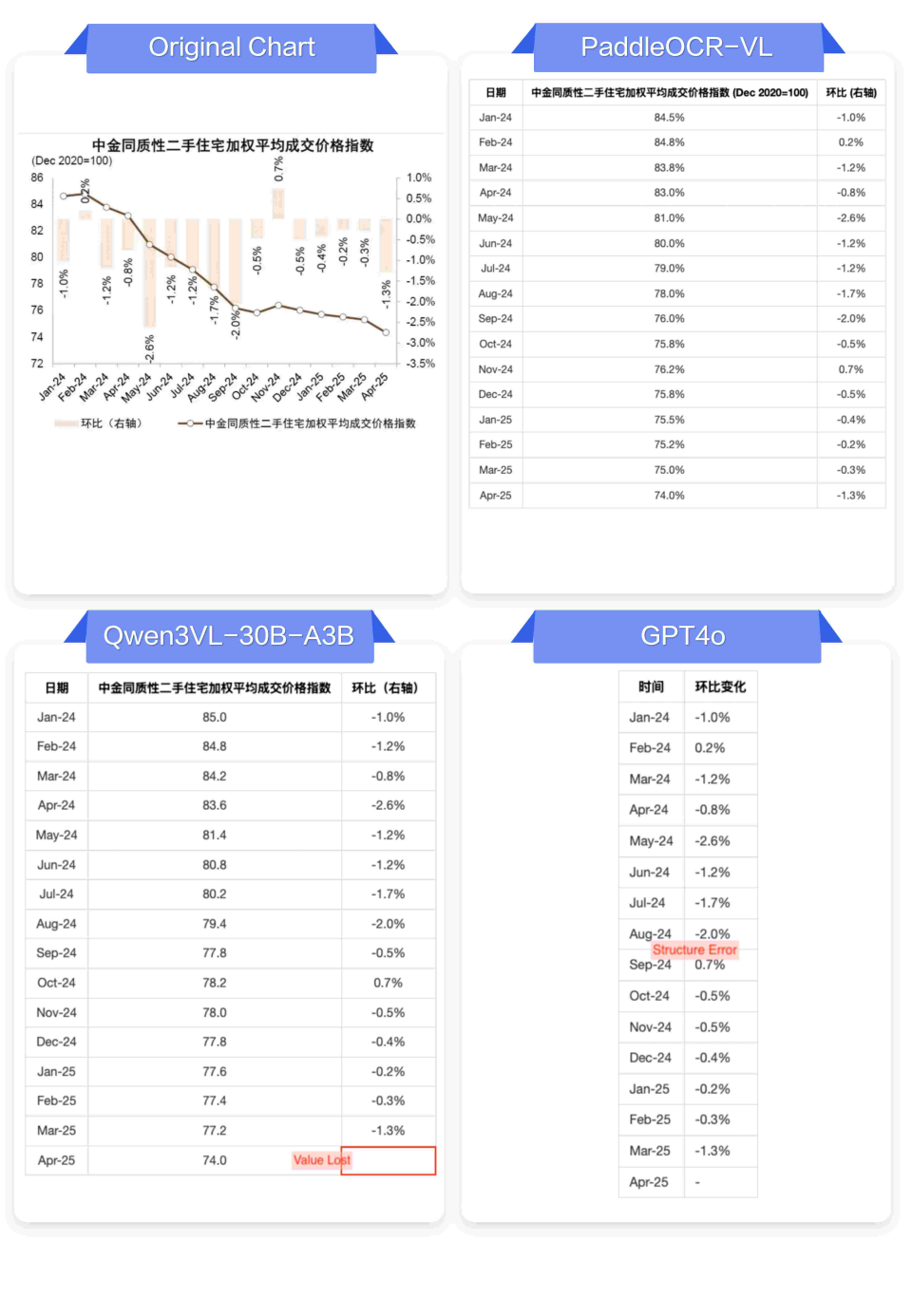
左右滑动查看更多
结论:PaddleOCR-VL不仅仅“看到”了图表,更“理解”了图表,实现了从感知到认知的跨越。
总结:PaddleOCR-VL为何能脱颖而出?
通过以上五大维度的对比,PaddleOCR-VL的核心优势已然清晰:
1.架构优势:“布局分析+元素识别”的两阶段设计,解耦了复杂任务,兼顾了布局的稳定性与识别的精准度。
2.数据优势:背后是超过3000万高质量、多场景、多语言的训练数据,并通过困难样本挖掘持续优化,模型泛化能力极强。
3.性能优势:仅0.9B的超轻量参数,却在多项基准测试中全面超越包括数十亿参数模型在内的竞争对手,实现了精度与效率的完美平衡。
4.全栈能力:提供了从多语言文本、手写体、竖排文本,到复杂表格、公式、图表的解决方案,是当前文档解析领域中能力最全面的模型之一。
如果你正在寻找一个在复杂真实场景下依然稳定、精准、高效的文档解析工具,PaddleOCR-VL无疑是当前最具竞争力的选择。
【下一篇预告】
强大的性能背后,是精妙的架构设计。PaddleOCR-VL为何要采用“两阶段”模型?独立的布局分析模型如何工作?0.9B的超轻量视觉语言模型又如何精准识别四大元素?敬请关注下一期硬核解析:《揭秘PaddleOCR-VL架构设计:两阶段模型如何实现高效文档解析》。
【直播预告】
为了帮助您迅速且深入地了解并掌握PaddleOCR-VL多模态文档解析SOTA方案的技术理论及实战技巧,百度高级工程师将于10月23日(周四)18:00为您深度解析本次技术升级。此外,我们还将开设针对PaddleOCR-VL多模态文档解析方案的产业场景实战营,手把手带您体验基于PaddleOCR-VL的整页文档解析和单个元素识别的强大能力。
机会难得,立即扫描海报中的二维码进行预约吧!

【互动话题】您在文档解析过程中遇到过哪些“棘手”的难题?是复杂的财务报表,还是多语言的研究论文?欢迎在评论区留言,与我们分享您的挑战!



关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)