【CVPR 2025】即插即用EfficientViM:新架构让视觉Mamba快得离谱,速度精度双碾压!
为了在资源受限的环境中部署神经网络,以往的研究通过结合卷积(捕获局部依赖)和注意力机制(捕获全局依赖)来构建轻量级架构。然而,注意力机制的二次方计算复杂度成为其效率瓶颈。近期,**状态空间模型(State Space Model, SSM)**因其在处理长序列时具有线性计算复杂度的优势而备受关注。尽管如此,现有的视觉Mamba模型在实际应用中速度仍不及顶尖的轻量级模型,其主要瓶颈在于对输入序列的线
为了在资源受限的环境中部署神经网络,以往的研究通过结合卷积(捕获局部依赖)和注意力机制(捕获全局依赖)来构建轻量级架构。然而,注意力机制的二次方计算复杂度成为其效率瓶颈。
近期,**状态空间模型(State Space Model, SSM)**因其在处理长序列时具有线性计算复杂度的优势而备受关注。尽管如此,现有的视觉Mamba模型在实际应用中速度仍不及顶尖的轻量级模型,其主要瓶颈在于对输入序列的线性投射操作。
针对这一挑战,本文提出了一个全新的高效视觉Mamba架构——EfficientViM。该架构的核心是一种名为**基于隐藏状态混合器的状态空间对偶(Hidden State Mixer-based State Space Duality, HSM-SSD)**的新型层。HSM-SSD通过将高计算量的通道混合操作从原始的图像特征空间转移到压缩后的隐藏状态空间中进行,从而有效降低了计算成本。
此外,作者还引入了**多阶段隐藏状态融合(Multi-stage hidden-state Fusion, MSF)**机制来增强隐藏状态的表征能力,并通过优化宏观设计以减少内存密集型操作,最终在ImageNet-1k等任务上实现了当前最先进的速度-精度权衡。
01 论文基本信息

- 标题: EfficientViM: Efficient Vision Mamba with Hidden State Mixer based State Space Duality
- 核心模块:
- 基于隐藏状态混合器的状态空间对偶 (HSM-SSD)
- 多阶段隐藏状态融合 (MSF)
- 深度可分离卷积 (DWConv)
02 算法框架与核心模块
2.1 算法框架
本文提出的EfficientViM是一个分层的视觉骨干网络。参考论文图4,其算法框架如下:输入图像首先经过一个由卷积层构成的Stem模块,进行初步的特征提取和4倍下采样。随后,特征图依次通过三个阶段(Stage)的EfficientViM模块堆叠进行处理。每个阶段末尾通过一个下采样层来缩小特征图尺寸并增加通道数,以构建层级化的特征表示。最后,通过分类头输出结果,并在训练时利用MSF机制融合各阶段的隐藏状态信息以辅助最终预测。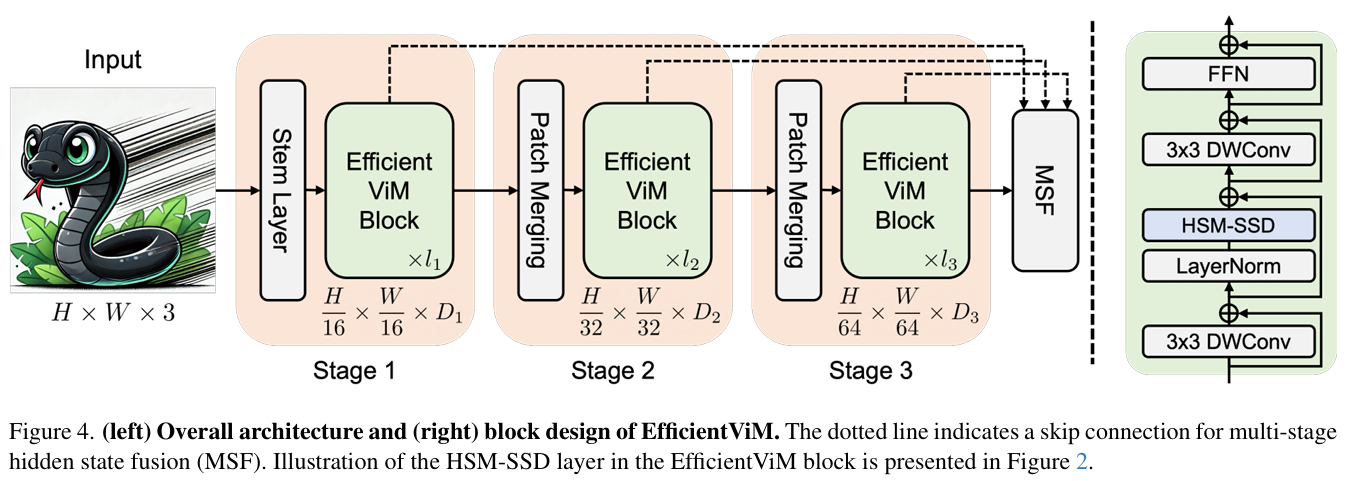
2.2 核心模块
模块一:基于隐藏状态混合器的状态空间对偶 (HSM-SSD)
-
核心功能: 旨在解决标准非因果状态空间对偶 (Non-Causal State Space Duality, NC-SSD) 层中计算复杂度为
O(LD²)的线性投射所带来的性能瓶颈。 -
实现逻辑: 传统NC-SSD首先通过输入
x计算得到输出y,再对y进行门控和线性投射等通道混合操作。HSM-SSD的核心思想是将这些计算密集型操作转移到维度更低的隐藏状态空间中。它首先通过输入序列x_in计算出一个压缩的中间隐藏状态h_in,然后在一个名为隐藏状态混合器 (Hidden State Mixer, HSM) 的模块内对h_in执行门控和线性投射,得到更新后的隐藏状态h。最后,用h和选择性矩阵C重建最终输出x_out。
其核心近似逻辑如下:
x out = Linear ( y ⊙ σ ( z ) ) ≈ C ( ( h ⊙ σ ( h in W z ) ) W out ) = C f ( h ) \mathbf{x}_{\text{out}} = \text{Linear}(\mathbf{y} \odot \sigma(\mathbf{z})) \approx \mathbf{C}((\mathbf{h} \odot \sigma(\mathbf{h}_{\text{in}}\mathbf{W}_z))\mathbf{W}_{\text{out}}) = \mathbf{C}f(\mathbf{h}) xout=Linear(y⊙σ(z))≈C((h⊙σ(hinWz))Wout)=Cf(h)
其中,y是传统NC-SSD的输出,f表示在隐藏状态空间中进行的门控和线性投射操作。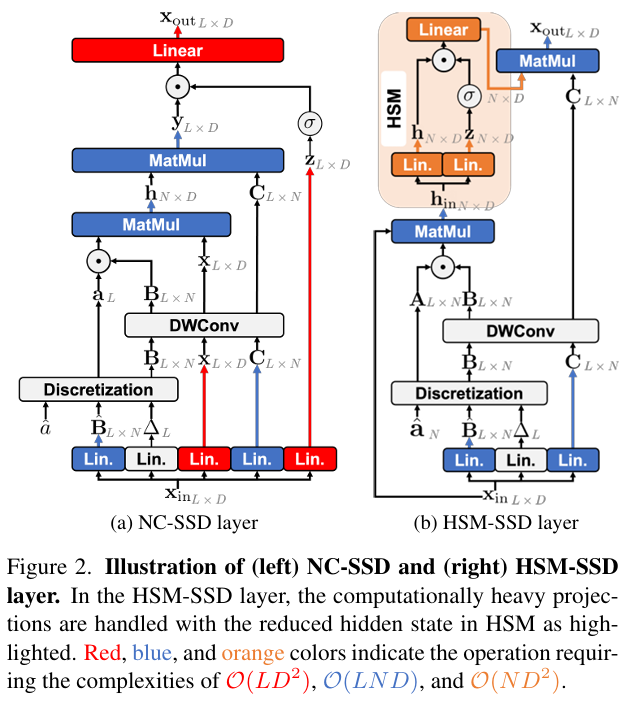
-
优势: 该设计将原先主要的计算复杂度从
O(LD²)(L为序列长度,D为通道数)降低到O(ND²)(N为状态数)。由于N通常远小于L,这一改变使得层的主要开销变得可控,显著提升了模型的计算效率和可扩展性,尤其是在处理高分辨率图像时优势更为明显。
模块二:多阶段隐藏状态融合 (MSF)
-
核心功能: 在训练过程中,通过显式地利用网络不同阶段的隐藏状态来增强模型的最终预测能力和泛化性。
-
实现逻辑: MSF机制从每个阶段的最后一个模块中提取隐藏状态
h^(s),并通过对隐藏状态取平均得到一个全局表征ĥ^(s)。随后,将这个全局表征通过一个线性层映射为分类的 logitsz^(s)。最终模型的输出 logitsz是由原始主干网络输出的 logitsz^(0)和所有阶段的辅助 logitsz^(s)的加权和构成。
其计算公式如下:
z = ∑ s = 0 S β ^ ( s ) z ( s ) , β ^ ( s ) = exp ( β ( s ) ) ∑ i = 0 S exp ( β ( i ) ) \mathbf{z} = \sum_{s=0}^{S} \hat{\beta}^{(s)}\mathbf{z}^{(s)}, \quad \hat{\beta}^{(s)} = \frac{\exp(\beta^{(s)})}{\sum_{i=0}^{S}\exp(\beta^{(i)})} z=s=0∑Sβ^(s)z(s),β^(s)=∑i=0Sexp(β(i))exp(β(s))
其中,β^(s)是一个可学习的标量权重。 -
优势: 这种类似深度监督的机制,强制网络在较浅的层也学习有判别性的特征。同时,它融合了从低层次细节到高层次语义的多尺度信息,起到了类似模型集成的效果,从而有效提升了模型的最终性能。
03 模块适用任务
- 核心应用场景: 本文方法主要针对图像分类任务,并验证了其在目标检测、实例分割和语义分割等密集预测任务上的有效性与可扩展性。它特别适用于需要高吞吐量和低延迟的资源受限场景。
- 方法论核心: 其最本质的思想是计算重分配:识别出模型中的计算瓶颈(即对高维序列的线性操作),并将其重新分配到维度更低的压缩空间(即隐藏状态)中执行,从而在保持全局感受野能力的同时,大幅提升计算效率。
- 启发性拓展:
- 递归隐藏状态混合: HSM-SSD模块本身可以作为其内部
隐藏状态混合器的实现,形成一种在深度上展开的递归结构,这可能进一步降低计算复杂度。 - 高分辨率图像应用: 由于HSM-SSD的线性复杂度优势,该方法在处理超高分辨率图像(如医学影像、卫星图像分析)时具有巨大潜力,能够以更快的速度处理更大的输入,这一点在论文的实验分析中已初步得到验证。
- 递归隐藏状态混合: HSM-SSD模块本身可以作为其内部
04 实验结果与可视化分析
核心实验与结论
本文最能体现其贡献的核心实验是在ImageNet-1K数据集上与现有高效视觉骨干模型的速度-精度对比
-
实验目的: 该实验旨在验证EfficientViM系列模型是否能在实际硬件(NVIDIA RTX 3090 GPU)上,相较于其他SOTA轻量级CNN和Transformer模型,实现更优的速度-精度权衡。
-
关键结果:
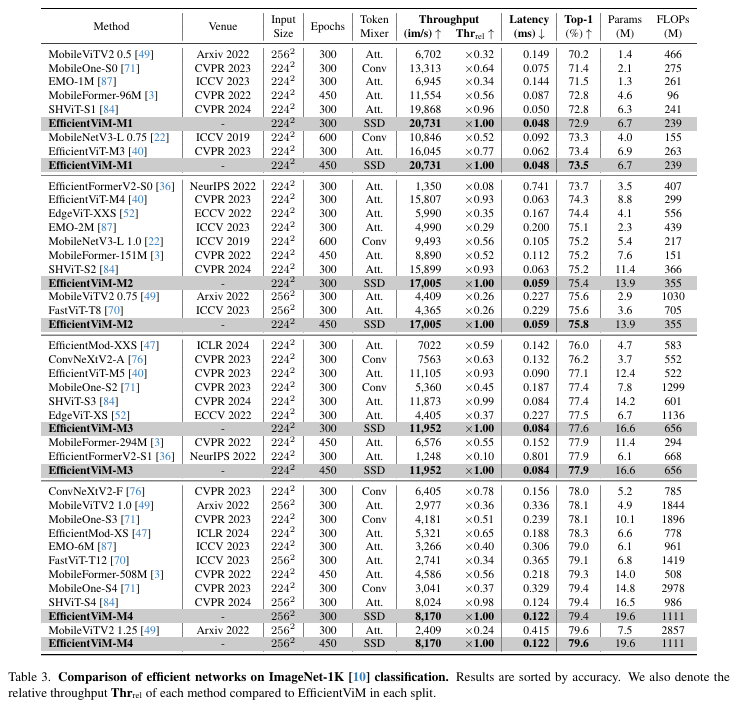
- 如表3所示,在相似的精度水平下,EfficientViM模型家族展现出显著的速度优势。例如,EfficientViM-M2在达到75.4% Top-1准确率的同时,吞吐量达到17,005 img/s,远高于同精度区间的其他模型如SHViT-S2(15,899 img/s)、MobileNetV3-L 1.0(9,493 img/s)等。
- 相较于之前的SOTA模型SHViT,EfficientViM在所有模型尺寸上都取得了更高的吞吐量和相当甚至更高的准确率。
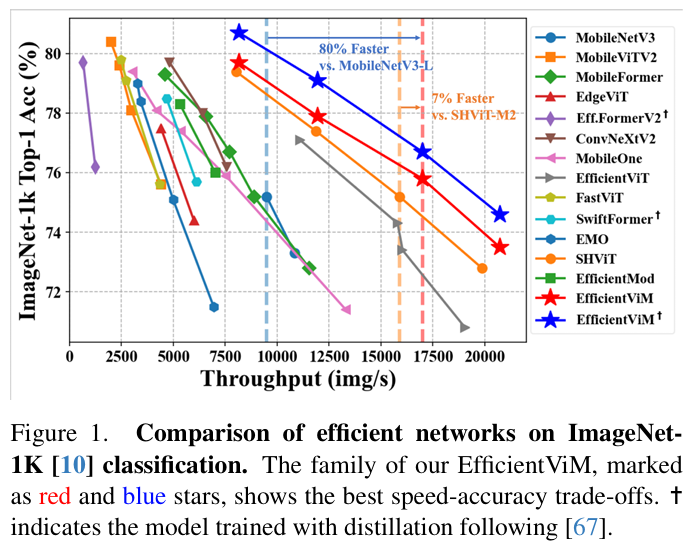
- 如图1所示,在速度-精度散点图中,EfficientViM家族的模型(红色和蓝色五角星)构成了一个新的帕累托前沿,清晰地表明了其在当前轻量级模型中的领先地位。
-
作者结论: 基于这些实验结果,作者得出结论:通过HSM-SSD和一系列宏观设计优化,EfficientViM成功地构建了一种新的、高效的视觉Mamba架构,它在速度和精度之间取得了目前最先进的平衡,特别是在实际部署场景中展现出卓越的性能。
05 即插即用模块
6.1 隐藏状态混合器状态空间对偶(HSM-SSD)
-
核心功能:将原本在高维特征空间进行的通道混合和门控运算迁移到低维的隐藏状态空间,以实现更低的计算与内存开销。
-
核心优势:将主要复杂度从 O(L·D²) 降为 O(N·D²),其中隐藏状态数 N 远小于序列长度 L,更友好于实际硬件吞吐与显存占用。
-
核心代码(片段):
# 低维隐藏状态空间的投影与混合(简化示意) def forward(self, x): B, _, L = x.shape H = int(math.sqrt(L)) # 计算 B, C, dt 三个状态通道参数 BCdt = self.dw(self.BCdt_proj(x).view(B, -1, H, H)).flatten(2) Bm, Cm, dt = torch.split(BCdt, [self.state_dim]*3, dim=1) # 非因果SSD的状态权重 A(随位置软最大) A = (dt + self.A.view(1, -1, 1)).softmax(-1) # 隐藏状态混合:在低维空间做通道混合,替代原始高维 y 上的重运算 h = x @ (A * Bm).transpose(-2, -1) # 门控与输出投影(隐藏状态维度内完成) h, z = torch.split(self.hz_proj(h), [self.d_inner]*2, dim=1) h = self.out_proj(h * self.act(z) + h * self.D) # 回投到原始空间得到输出 y y = h @ Cm return y.view(B, -1, H, H), h
6.2 多阶段隐藏状态融合(MSF)
-
核心功能:从各阶段提取隐藏状态 h,经全局聚合与独立分类头产生阶段预测,并通过可学习的软权重进行融合,得到最终 logits。
-
核心优势:以极低额外成本实现深度监督与多尺度语义集成,显著提升性能与稳定性。
-
核心代码(片段):
# 多阶段隐藏状态融合(简化示意) def forward(self, x): x = self.patch_embed(x) weights = self.weights.softmax(-1) # 学习的融合权重 z = torch.zeros((x.shape[0], self.num_classes), device=x.device) for i, stage in enumerate(self.stages): x, x_out, h = stage(x) # 取出阶段末尾的隐藏状态 h h = self.norm[i](h) h = torch.nn.functional.adaptive_avg_pool1d(h, 1).flatten(1) z = z + weights[i] * self.heads[i](h) # 阶段预测加权累加 # 最后阶段的空间特征也参与融合(主干末尾监督) x = self.norm[3](x) x = torch.nn.functional.adaptive_avg_pool2d(x, 1).flatten(1) z = z + weights[3] * self.heads[3](x) return z
6.3 单头 HSM-SSD(Single-head HSM-SSD)
-
核心功能:以单头形态(ssd_expand=1)实例化 HSM-SSD,保持极简的参数与计算规模,同时保留隐藏状态空间的高效混合优势。
-
核心优势:在移动与边缘设备场景中,单头配置提供最佳的速度/显存占用/实现复杂度平衡,易于集成与迁移。
-
核心代码(片段):
# 在 Block 中以单头(ssd_expand=1)方式实例化 HSM-SSD(简化示意) class EfficientViMBlock(nn.Module): def __init__(self, dim, mlp_ratio=4., ssd_expand=1, state_dim=64): # ... self.mixer = HSMSSD(d_model=dim, ssd_expand=ssd_expand, state_dim=state_dim) # LayerScale 等宏观设计提升稳定性与性能 self.alpha = nn.Parameter(1e-4 * torch.ones(4, dim), requires_grad=True) # 以单头配置注册不同规模的模型族(均 ssd_expand=1) def EfficientViM_M1(pretrained=False, **kwargs): return EfficientViM(embed_dim=[128, 192, 320], depths=[2, 2, 2], mlp_ratio=4., ssd_expand=1., state_dim=[49, 25, 9], **kwargs) def EfficientViM_M2(pretrained=False, **kwargs): return EfficientViM(embed_dim=[128, 256, 512], depths=[2, 2, 2], mlp_ratio=4., ssd_expand=1., state_dim=[49, 25, 9], **kwargs) def EfficientViM_M3(pretrained=False, **kwargs): return EfficientViM(embed_dim=[224, 320, 512], depths=[2, 2, 2], mlp_ratio=4., ssd_expand=1., state_dim=[49, 25, 9], **kwargs) def EfficientViM_M4(pretrained=False, **kwargs): return EfficientViM(embed_dim=[224, 320, 512], depths=[3, 4, 2], mlp_ratio=4., ssd_expand=1., state_dim=[64, 32, 16], **kwargs)
说明与使用建议:
- 在自有项目中,如需快速集成高效通道混合能力,直接将 HSM-SSD 作为替换或增益模块插入到骨干网络的卷积或注意力层之间,保持输入输出形状与接口一致即可。
- 若需要更强表征力并保持硬件友好,可先以单头(ssd_expand=1)验证,再根据性能需求适度增大 state_dim 或引入多头(提高 ssd_expand)的设计。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)