PPTAGENT:重新定义AI驱动的演示文稿生成,从文本堆砌到专业级设计
PPTAGENT的突破,不仅是技术上的创新,更重新定义了“自动演示文稿生成”的目标——不再是“快速完成任务”,而是“生成真正有价值的沟通工具”。对于普通用户,这意味着无需掌握设计技巧,也能生成逻辑清晰、视觉舒适的PPT;对于研究者,它展示了“LLM+多模态分析+编辑式生成”的新范式,为内容创作自动化提供了新思路。随着技术迭代,或许不久的将来,我们只需输入一篇文档,AI就能生成一份堪比专业设计师的演
论文名称:PPTAGENT: Generating and Evaluating Presentations
Beyond Text-to-Slides
论文地址:https://arxiv.org/pdf/2501.03936
在数字化时代,演示文稿(PPT)是信息传递的核心载体——无论是学术报告、商业提案还是课堂教学,一份优质的PPT能让复杂信息变得直观易懂。但创作这样的PPT往往需要三重能力:清晰的逻辑架构、吸引人的视觉设计和精炼的内容提炼。对于大多数人而言,这意味着数小时的排版调整、图文匹配和逻辑梳理。
近年来,随着大语言模型(LLMs)和多模态大语言模型(MLLMs)的兴起,自动生成演示文稿成为研究热点。然而,现有工具往往陷入“文本转幻灯片”的范式:要么将文档摘要直接塞进固定模板,导致页面冗长乏味;要么依赖预设模板,缺乏灵活性。直到PPTAGENT的出现,这一局面终于被打破。
一、为什么传统自动PPT生成工具不够用?
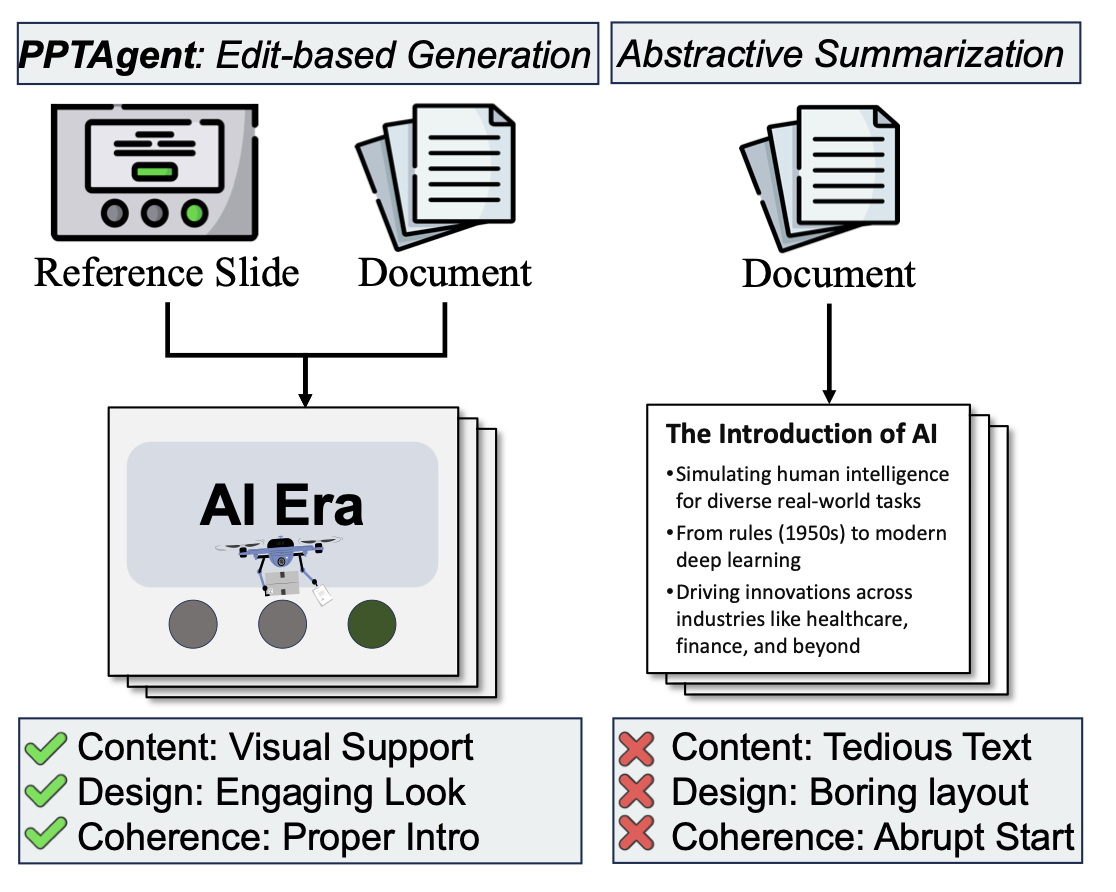
想象这样一个场景:你用某款AI工具生成PPT,输入一篇关于“无人机技术发展”的文档,得到的结果却是满页文字——标题下方堆着密密麻麻的段落,配图是随机挑选的“无人机图片”,甚至前后幻灯片的配色、字体都不统一。这样的PPT不仅无法吸引观众,反而可能因为信息过载降低沟通效率。
这正是传统自动生成工具的通病。论文中指出,现有方法存在三大局限:
- 重内容轻设计:将PPT生成简化为“文本摘要+模板填充”,忽略了PPT的视觉本质。例如,DocPres等规则驱动工具专注于文本提取,生成的幻灯片往往文字密集、缺乏视觉层次;
- 结构连贯性差:幻灯片之间的逻辑跳转生硬,缺乏开场、过渡、总结等结构性元素,观众难以跟上思路;
- 评估维度单一:现有评估只关注文本准确性(如与原文的相似度),忽略了设计美感和整体连贯性,导致“看似准确却不好用”的PPT。
究其根源,这些问题源于对“演示文稿创作逻辑”的误解:人类制作PPT时,很少从零开始——我们会参考优秀案例的结构(如开场页怎么设计)、模仿排版风格(如要点页用图标+短句),再结合自己的内容进行修改。这种“参考-编辑”的工作流,正是PPTAGENT的灵感来源。
二、PPTAGENT:像人类一样“参考-编辑”,而非“从零创作”
PPTAGENT的核心创新在于:将演示文稿生成定义为“基于参考的编辑任务”,而非“从头生成的创作任务”。它通过两阶段流程——演示文稿分析与演示文稿生成,复刻人类制作PPT的思路,最终生成既符合内容逻辑、又具备视觉吸引力的幻灯片。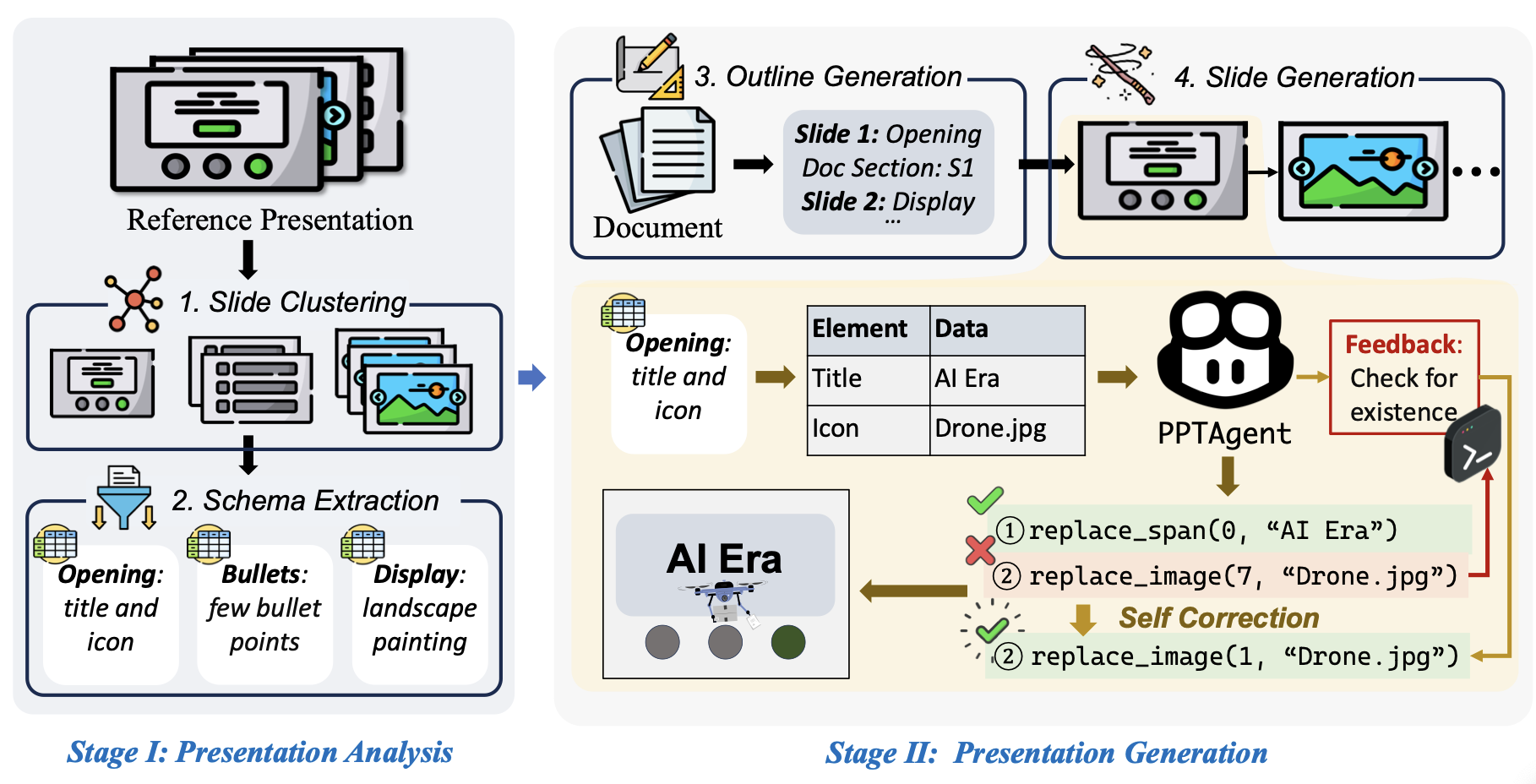
第一阶段:吃透参考,建立“PPT创作字典”
在开始生成新PPT前,PPTAGENT会先“学习”参考演示文稿的规律,就像设计师研究优秀案例一样。这一阶段分为两大步骤:
1. 幻灯片聚类:给幻灯片“贴标签”
PPTAGENT会将参考PPT中的幻灯片分类,就像图书馆给书籍分大类。具体分为:
- 结构性幻灯片:负责串联整个演示的“骨架”,如开场页(标题+副标题)、目录页(章节列表)、过渡页(章节标题)、结束页(感谢语)等;
- 内容性幻灯片:承载具体信息的“血肉”,如要点页(短句+图标)、图文页(图片+说明)、数据页(图表+分析)等。
分类方法结合了LLM的文本理解能力和MLLM的视觉分析能力:结构性幻灯片通过文本功能(如“感谢观看”出现在结尾)识别;内容性幻灯片则先转为图片,再通过视觉相似度聚类(如“左图右文”布局归为一类)。
2. Schema提取:拆解幻灯片的“构成公式”
聚类后,PPTAGENT会进一步拆解每类幻灯片的“构成要素”,形成可复用的模板。例如,一个“开场页”的schema可能是:
{
"标题": {"类型": "文本", "作用": "概括主题", "内容": "AI时代的技术变革"},
"副标题": {"类型": "文本", "作用": "补充说明", "内容": "从规则引擎到深度学习"},
"背景图": {"类型": "图片", "作用": "烘托氛围", "内容": "科技感城市剪影"}
}
这些schema就像“PPT语法”,明确了每类幻灯片该包含哪些元素、各自的作用是什么,为后续生成提供精准指导。
第二阶段:按图施工,用“编辑动作”生成新PPT
基于第一阶段提炼的“规则”,PPTAGENT进入生成环节,分为三步:
1. 大纲生成:规划每一页的“剧本”
首先,PPTAGENT会分析输入文档(如一篇关于“无人机应用”的文章),生成一份详细大纲。大纲中每一条目对应一张幻灯片,明确:
- 这张幻灯片的功能(如“介绍无人机在农业中的应用”);
- 参考哪类结构性/内容性幻灯片(如用“要点页”模板);
- 需要从文档中提取的核心信息(如“播种效率提升30%”“减少农药使用量”)。
2. 编辑API:像“编辑软件”一样修改幻灯片
有了大纲和参考模板,PPTAGENT不会从头画幻灯片,而是通过一系列“编辑动作”修改参考幻灯片。例如,用“开场页”模板生成新开场页时,可能执行:
replace_span(0, "无人机技术应用"):将原标题替换为新标题;replace_image(1, "farm_drone.jpg"):将原背景图替换为农业无人机图片。
这些API基于HTML格式操作(而非复杂的PPT XML格式),降低了修改难度。就像用简单的代码指令修改网页元素,LLM能更精准地完成替换、删除、复制等操作。
3. 自我校正:给AI加个“校对员”
即使是AI,也可能犯错——比如替换图片时选错位置,或文字超出版心。PPTAGENT引入“自我校正机制”:每次执行编辑动作后,系统会检查结果(如“图片是否超出边界”“文字是否完整显示”),并反馈给LLM;LLM根据反馈调整指令,直到生成合格的幻灯片。
这种“尝试-检查-修正”的循环,让PPTAGENT的生成成功率超过95%,远高于传统模板工具(如KCTV的88%)。
三、PPTEVAL:给PPT“全面体检”的评估框架
生成效果好不好,需要科学的评估标准。传统方法只看“文字对不对”,但PPT的价值远不止于此。为此,论文提出PPTEVAL评估框架,从三个维度给PPT“打分”: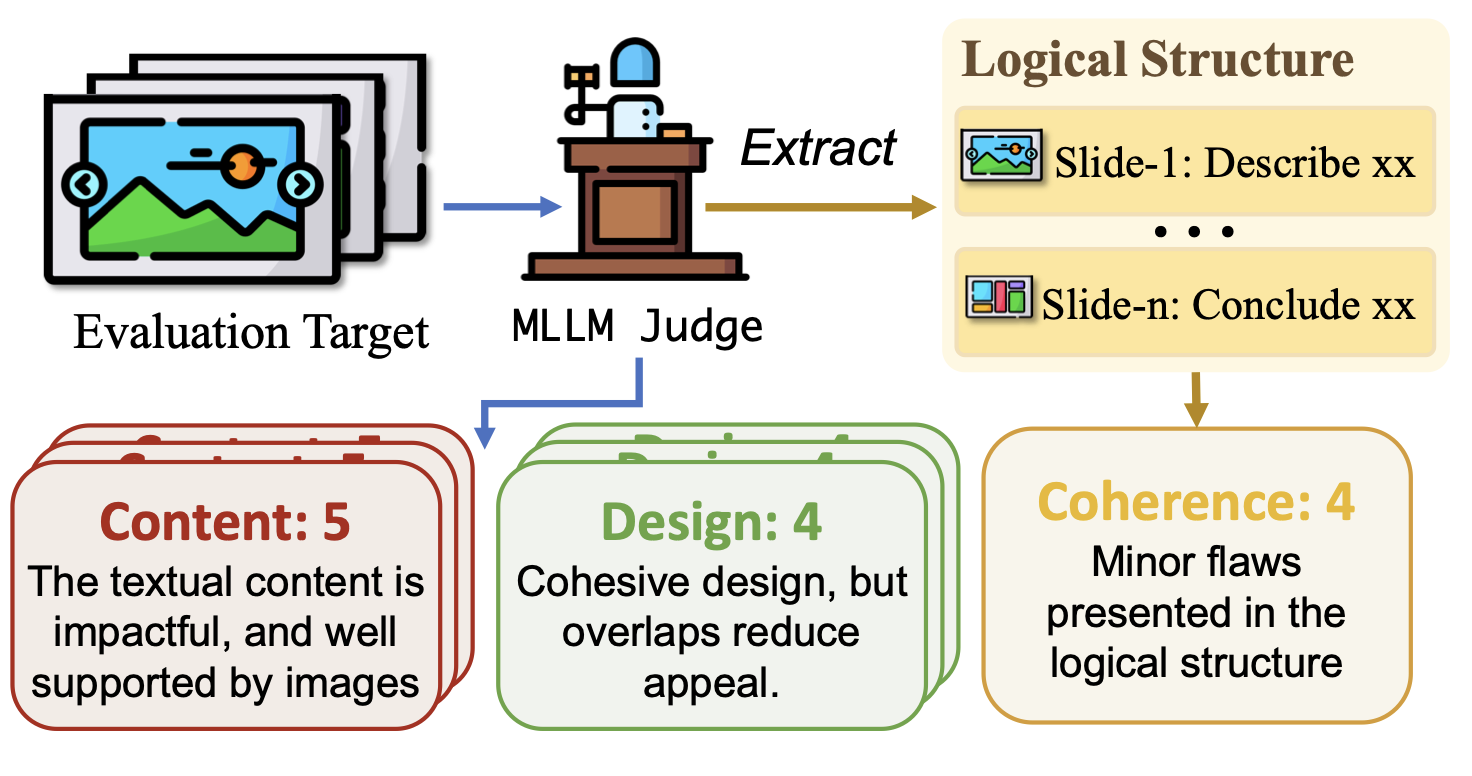
1. 内容(Content):信息传递是否精准?
- 文字是否简洁、无语法错误?(如避免大段文字,用短句+关键词);
- 图片是否与内容相关?(如讲“无人机物流”时配送货无人机图片,而非航拍风景)。
2. 设计(Design):视觉呈现是否专业?
- 配色是否和谐?(如对比色突出标题,同色系统一页面);
- 布局是否清晰?(如避免元素重叠,留白合理);
- 视觉元素是否丰富?(如图标、几何图形增强吸引力)。
3. 连贯性(Coherence):整体逻辑是否流畅?
- 结构是否完整?(如包含开场、主体、结尾);
- 过渡是否自然?(如章节之间有过渡页提示);
- 背景信息是否充足?(如开头说明演讲主题,结尾总结核心观点)。
PPTEVAL采用“MLLM作为评委”的模式(如用GPT-4o),对每个维度打1-5分,并给出具体理由(如“设计得3分:配色和谐但缺乏图标”)。人类评估验证显示,其结果与人类判断的一致性达71%(Pearson相关系数),远超传统指标(如ROUGE只关注文本相似度,与实际质量相关性极低)。
四、实验数据:PPTAGENT到底有多强?
论文在5个领域(文化、教育、科学、社会、科技)的50份文档上做了测试,对比了PPTAGENT与传统工具(DocPres、KCTV)的效果,结果令人惊喜: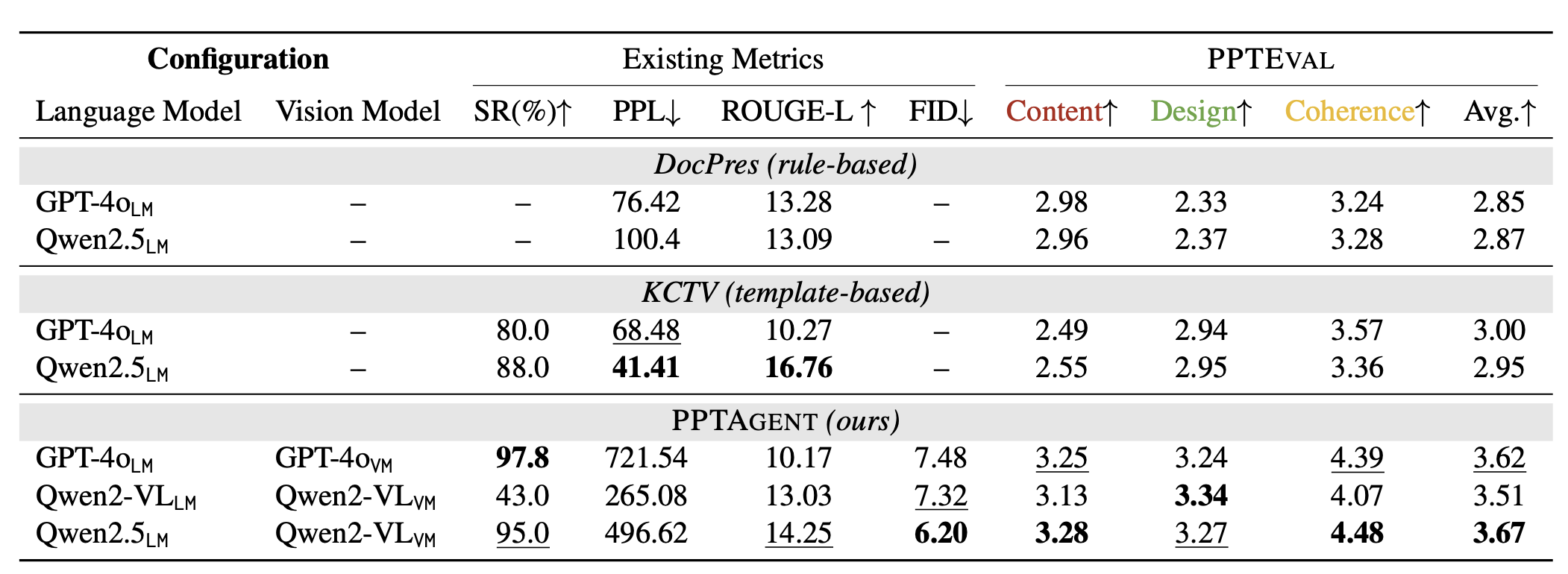
1. 全面碾压的评估得分
在PPTEVAL的三个维度上,PPTAGENT均显著领先:
- 设计维度:PPTAGENT得3.34分,DocPres仅2.37分(+40.9%),KCTV2.95分(+13.2%);
- 内容维度:PPTAGENT得3.28分,DocPres2.98分(+12.1%),KCTV2.55分(+28.6%);
- 连贯性维度:PPTAGENT得4.48分,DocPres3.57分(+25.5%),KCTV3.28分(+36.6%)。
这意味着,PPTAGENT生成的PPT不仅文字更精炼、图片更贴切,整体逻辑也更像“人做的”——有开场、有过渡、有总结,观众更容易跟上思路。
2. 近乎完美的生成稳定性
PPTAGENT的成功率(无错误生成)高达95%-97.8%,而KCTV仅88%。这得益于自我校正机制:即使首次生成有小问题(如文字超界),也能通过1-2次修正解决。
3. 跨领域的通用性
在科技、教育等不同领域,PPTAGENT的表现始终稳定。例如,在“科技”领域,其平均得分3.74分;在“科学”领域也达3.56分,证明它能适应不同主题的表达需求。
五、背后的“功臣”:Zenodo10K数据集
好模型离不开好数据。现有PPT数据集要么格式混乱(如PDF丢失排版信息),要么领域单一(多为AI学术报告)。为此,论文团队构建了Zenodo10K数据集:
- 包含10,448份来自Zenodo平台的演示文稿,覆盖文化、科技、教育等多领域;
- 保留完整的PPT结构信息(文字位置、图片尺寸、配色方案等),而非单纯的图片或文本;
- 所有数据均符合开源许可,可放心用于研究和开发。
这一数据集为PPT生成研究提供了“高质量素材库”,也让PPTAGENT的训练更贴近真实场景。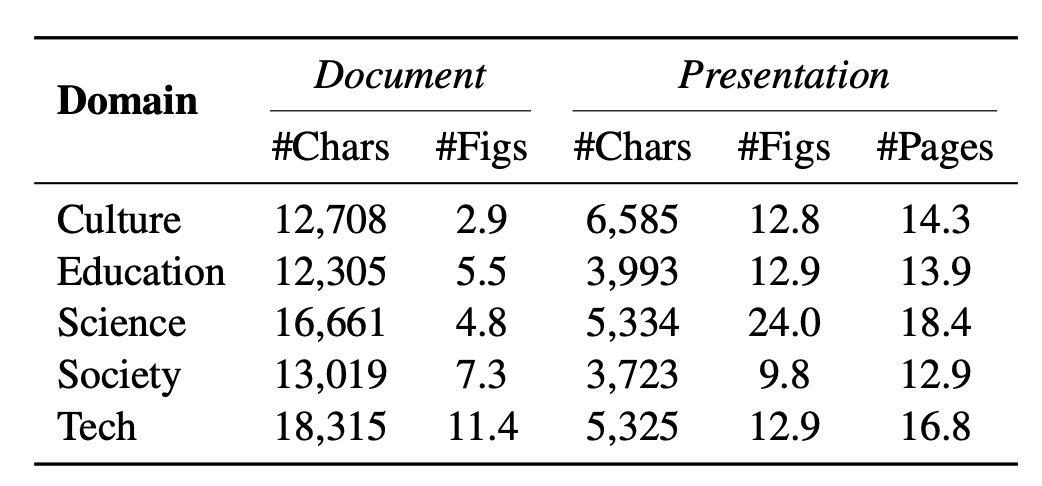
六、未来展望:从“能用”到“好用”
尽管表现出色,PPTAGENT仍有提升空间:
- 减少对参考的依赖:目前生成质量受参考PPT影响较大,未来可通过学习更多样化的案例,增强“无参考创作”能力;
- 优化视觉细节:偶尔出现元素重叠等设计瑕疵,需进一步结合视觉模型(如检测图片是否清晰、配色是否和谐);
- 适配更多场景:如动态PPT(含动画)、交互式PPT(可点击跳转)的生成,拓展应用边界。
七、结语:让每个人都能做出专业级PPT
PPTAGENT的突破,不仅是技术上的创新,更重新定义了“自动演示文稿生成”的目标——不再是“快速完成任务”,而是“生成真正有价值的沟通工具”。
对于普通用户,这意味着无需掌握设计技巧,也能生成逻辑清晰、视觉舒适的PPT;对于研究者,它展示了“LLM+多模态分析+编辑式生成”的新范式,为内容创作自动化提供了新思路。
随着技术迭代,或许不久的将来,我们只需输入一篇文档,AI就能生成一份堪比专业设计师的演示文稿——让每个人都能专注于内容本身,而非排版细节。而PPTAGENT,正是这一愿景的重要一步。
(论文代码与数据已开源:https://github.com/icip-cas/PPTAgent,感兴趣的读者可自行探索。)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)