多智能体如何实现协同决策与控制
多智能体系统(Multi-Agent Systems, MAS)中的协同决策与控制是实现复杂任务(如自动驾驶车队、无人机编队、智能制造、智能电网等)的关键。其核心目标是让多个具有自主性、局部感知能力和决策能力的智能体,在信息有限、环境动态甚至存在冲突的情况下,通过交互与协调达成全局或局部一致的目标。使用分布式一致性算法(如平均一致性、最大一致性)使所有智能体对某个变量(如目标位置、速度)达成一致。
多智能体系统(Multi-Agent Systems, MAS)中的协同决策与控制是实现复杂任务(如自动驾驶车队、无人机编队、智能制造、智能电网等)的关键。其核心目标是让多个具有自主性、局部感知能力和决策能力的智能体,在信息有限、环境动态甚至存在冲突的情况下,通过交互与协调达成全局或局部一致的目标。
以下是实现多智能体协同决策与控制的主要方法和技术路径:
一、协同机制设计
通信机制
显式通信:智能体之间通过消息传递交换状态、意图或策略(如基于FIPA ACL、ROS话题/服务)。
隐式通信:通过观察其他智能体的行为或环境变化间接推断信息(如强化学习中的对手建模)。
通信拓扑:全连接、环形、星型、图神经网络(GNN)结构等,影响信息传播效率和鲁棒性。
共识与一致性协议
使用分布式一致性算法(如平均一致性、最大一致性)使所有智能体对某个变量(如目标位置、速度)达成一致。
典型算法:Paxos、Raft(用于离散决策),或连续一致性协议(如基于拉普拉斯矩阵的分布式控制律)。
角色分配与任务分解
将整体任务分解为子任务,并动态分配给合适的智能体(如基于拍卖机制、合同网协议、市场机制)。
可引入领导者-跟随者(Leader-Follower)架构,由Leader协调,Follower执行。
二、决策方法
集中式 vs 分布式决策
集中式:中央控制器收集所有信息并做决策(计算高效但单点故障风险高)。
分布式:每个智能体基于局部信息独立决策,通过协调机制保证整体性能(可扩展性强,更鲁棒)。
博弈论方法
将智能体视为博弈参与者,通过纳什均衡、帕累托最优等概念求解协作或竞争策略。
合作博弈中可使用Shapley值进行收益分配。
多智能体强化学习(MARL)
独立学习(IQL):每个智能体独立训练,忽略其他智能体的策略变化(非平稳性问题)。
联合行动学习(JAL):考虑联合动作空间,但维度爆炸。
值分解方法:如VDN、QMIX、QTRAN,将全局Q函数分解为局部Q函数之和/混合。
Actor-Critic架构:如MADDPG,中心化训练+去中心化执行(CTDE)。
基于通信的MARL:如TarMAC、IC3Net,学习何时通信及传递什么信息。
规划与推理
分布式约束优化问题(DCOP):将协同问题建模为带约束的优化问题。
多智能体POMDP(Dec-POMDP):处理部分可观测下的序贯决策,但计算复杂度高。
三、控制策略
分布式控制律
基于图论的编队控制:利用拉普拉斯矩阵设计控制输入,实现队形保持、避障、聚合等。
示例:ui=∑j∈Ni(xj−xi) 实现一致性。
分层控制架构
高层:任务分配与路径规划(离散决策)。
低层:轨迹跟踪与避碰(连续控制)。
中间层:协调器处理冲突消解(如速度障碍法VO、RVO)。
安全与鲁棒性保障
引入屏障函数(Barrier Functions)、李雅普诺夫函数确保安全性。
对抗扰动或恶意智能体时,采用鲁棒共识、拜占庭容错等机制。
四、典型应用场景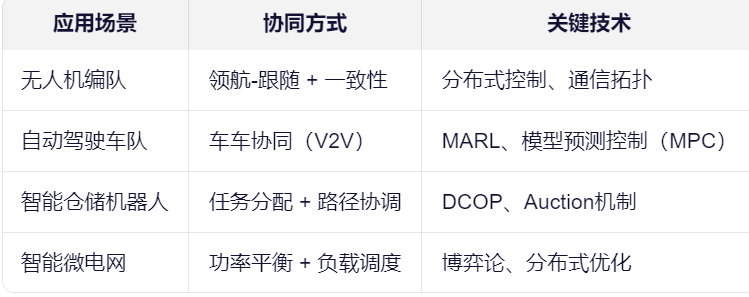
五、挑战与前沿方向
可扩展性:智能体数量增加导致通信与计算开销剧增。
部分可观测性与非平稳性:其他智能体策略变化导致环境动态不可预测。
异构智能体协同:不同能力、目标、通信协议的智能体如何协作。
人机协同:将人类纳入多智能体系统,需理解人类意图与偏好。
可信与可解释性:尤其在安全关键系统中,需提供决策依据。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)