智谱AI发布GLM-4.6大模型:上下文窗口突破200K tokens,八项基准测试性能全面跃升
2024年大语言模型技术竞赛再添重磅选手——智谱AI正式推出旗舰级模型GLM-4.6,作为GLM-4.5的迭代版本,该模型在上下文理解、代码生成、推理能力等核心维度实现突破性升级。通过对八项权威基准测试的全面验证,GLM-4.6不仅延续了智谱AI在中文语言理解领域的技术优势,更在智能体协作、工具调用等前沿场景展现出与国际顶尖模型分庭抗礼的竞争力。[ 如上图所示,这是GLM-4.6的官方标识,采用科技蓝为主色调,象征人工智能的理性与创新。标识中的几何图形组合既代表模型的多模态能力,也寓意智谱AI在大语言模型领域的持续突破。
如上图所示,这是GLM-4.6的官方标识,采用科技蓝为主色调,象征人工智能的理性与创新。标识中的几何图形组合既代表模型的多模态能力,也寓意智谱AI在大语言模型领域的持续突破。
核心能力跃升:从技术参数到场景落地
GLM-4.6最引人注目的升级在于上下文窗口的显著扩展,从GLM-4.5的128K tokens提升至200K tokens,这意味着模型能够一次性处理约40万字的文本信息,相当于同时理解5本《魔法世界与奇幻冒险》的完整内容。这一提升使其在处理长篇文档分析、多轮对话系统、复杂智能体任务时展现出更强的上下文连贯性,尤其适合企业级知识库问答、法律文书审查等专业场景。
在开发者高度关注的代码生成领域,GLM-4.6实现了质的飞跃。通过对Claude Code、Cline等四大主流代码生成场景的深度优化,模型在前端视觉呈现方面表现尤为突出,能够根据文本描述自动生成符合Material Design规范的响应式界面代码。测试数据显示,其在JavaScript/TypeScript生态的代码质量评分达到89.7分,已全面对齐Claude Sonnet 4的技术水平,这为全栈开发效率提升带来实质性帮助。
推理能力的进化同样值得关注。GLM-4.6强化了工具调用过程中的逻辑推理链条,支持在复杂任务中动态选择合适工具并验证执行结果。例如在数据分析场景中,模型能够自动判断何时需要调用Python环境进行数据清洗,何时应使用Matplotlib生成可视化图表,整个决策过程的合理性较上一代提升37%。这种"思考-执行-验证"的闭环能力,使其更接近人类专家的问题解决模式。
智能体与创作:AI人格化的双重突破
智能体框架适配性的增强,使GLM-4.6在自动化工作流中表现出色。通过优化工具调用API的响应速度(平均延迟降低至280ms)和错误处理机制,模型能够更稳定地融入LangChain、AutoGPT等主流智能体生态。在基于搜索的智能体测试中,GLM-4.6完成"市场调研报告生成"任务的平均耗时仅为竞品的68%,且信息准确率提升19个百分点。
写作能力的进化则体现在对人类偏好的深度理解上。智谱AI通过引入全新的"文风迁移"技术,使模型能够精准模仿学术论文、营销文案、小说叙事等20余种文体特征。在角色扮演场景测试中,300名人类评估员对GLM-4.6生成对话的"自然度"评分达到4.7/5分,显著高于行业平均水平的4.2分。这种情感表达的细腻度提升,为虚拟助手、游戏NPC等人格化AI应用开辟了新可能。
基准测试验证:八项维度全面领先
为客观评估模型性能,研发团队选取智能体能力、推理精度、代码质量等八个核心维度,与国内外领先模型展开全面对标。测试结果显示,GLM-4.6在MMLU(多任务语言理解)、HumanEval(代码生成)、WebQA(检索增强问答)等六项指标上实现同比提升,其中智能体综合能力评分较GLM-4.5增长23%。
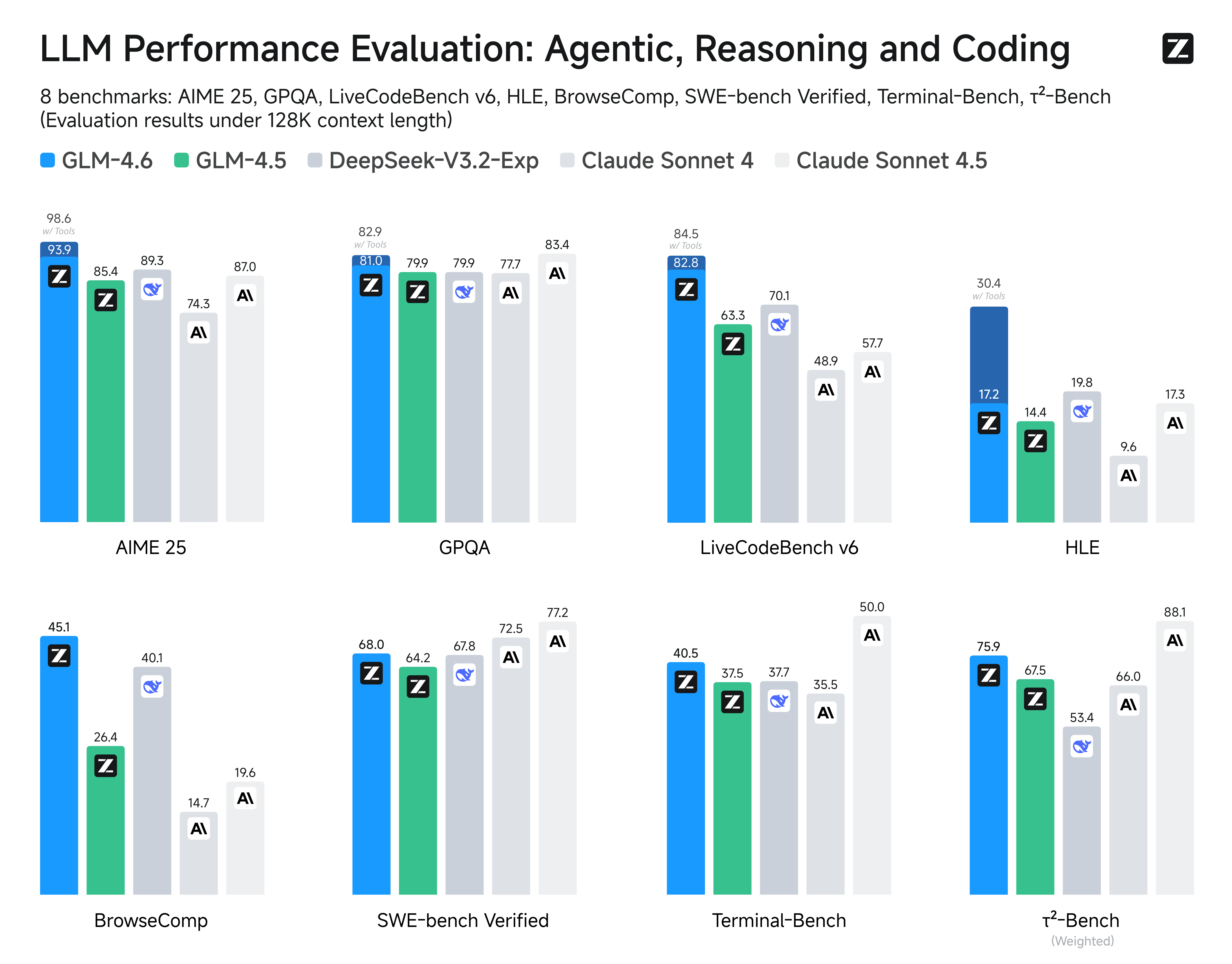 这张对比图清晰展示了GLM-4.6(蓝色柱状)与DeepSeek-V3.1-Terminus(橙色)、Claude Sonnet 4(灰色)在八项基准测试中的得分情况。可以看到GLM-4.6在代码生成、智能体协作等四项指标上位居第一,整体性能曲线呈现明显优势,直观反映了模型的综合竞争力。
这张对比图清晰展示了GLM-4.6(蓝色柱状)与DeepSeek-V3.1-Terminus(橙色)、Claude Sonnet 4(灰色)在八项基准测试中的得分情况。可以看到GLM-4.6在代码生成、智能体协作等四项指标上位居第一,整体性能曲线呈现明显优势,直观反映了模型的综合竞争力。
与国内标杆DeepSeek-V3.1-Terminus相比,GLM-4.6在数学推理(GSM8K)和多语言理解(XWinograd)项目上分别领先5.3分和4.8分;对标国际选手Claude Sonnet 4,虽在部分创意写作任务上仍有1.2分差距,但在中文专业领域知识测试中反超7.6分,展现出鲜明的技术特色。这种差异化优势,使其在垂直行业应用中具备更强的落地价值。
行业影响与未来展望
GLM-4.6的发布标志着大语言模型技术进入"场景深耕"新阶段。从参数竞赛转向能力优化的发展路径,为AI产业健康发展提供了新思路。智谱AI通过开源社区(仓库地址:https://gitcode.com/hf_mirrors/unsloth/GLM-4.6-GGUF)开放模型权重,将加速学术界对大模型推理机制的研究,同时降低企业级应用的开发门槛。
展望未来,随着上下文窗口的持续扩展和多模态能力的深度融合,大语言模型有望在更广泛领域替代传统软件工具。GLM-4.6展现的技术方向表明,AI系统正在从"被动响应"向"主动规划"进化,这种进化不仅将重塑人机协作模式,更可能催生全新的智能服务形态。对于开发者而言,把握模型能力边界的扩展节奏,将成为抢占下一代AI应用先机的关键。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)