【GitHub项目推荐--MOSS-TTSD:开源双语对话语音生成模型】
MOSS-TTSD(Text to Spoken Dialogue Generation)是一个开源的跨语言对话语音生成模型,支持中文和英文的双语对话语音合成。该模型能够将两个说话人之间的对话脚本转换为自然、富有表现力的对话语音,支持语音克隆和长语音生成,是AI播客制作、访谈和对话场景的理想选择。🔗 GitHub地址🌐 🚀 核心价值:对话语音合成 · 语音克隆 · 双语支持 ·
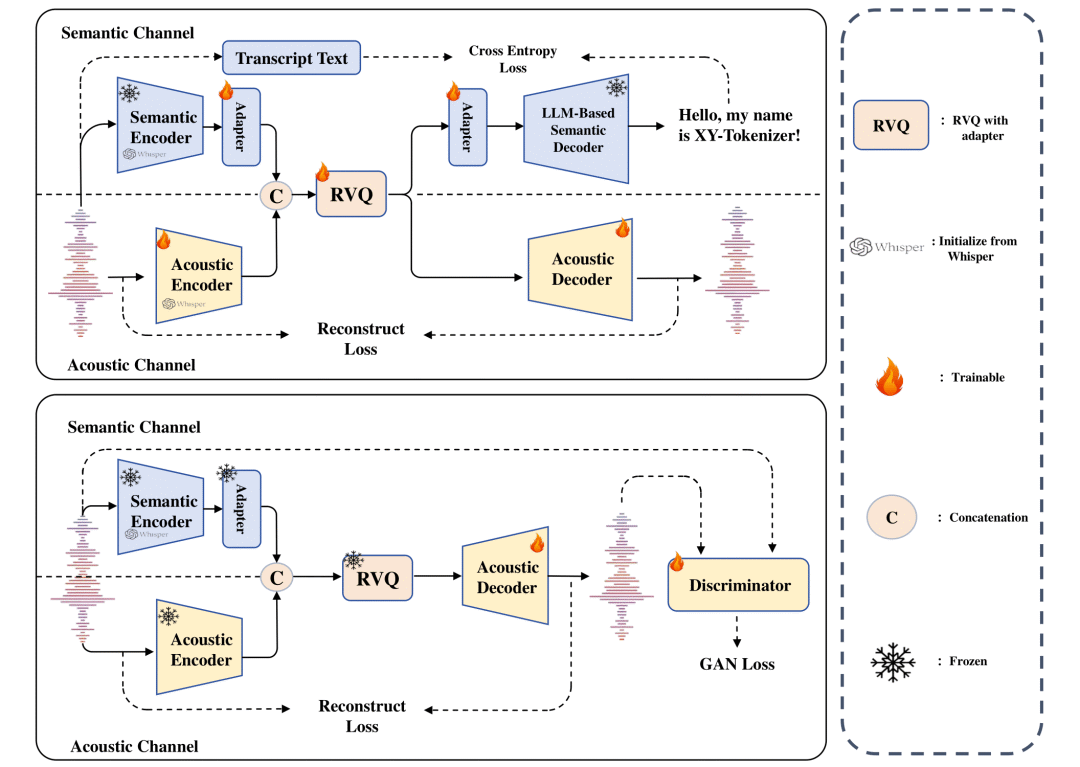
简介
MOSS-TTSD(Text to Spoken Dialogue Generation)是一个开源的跨语言对话语音生成模型,支持中文和英文的双语对话语音合成。该模型能够将两个说话人之间的对话脚本转换为自然、富有表现力的对话语音,支持语音克隆和长语音生成,是AI播客制作、访谈和对话场景的理想选择。
🔗 GitHub地址:
https://github.com/OpenMOSS/MOSS-TTSD
🌐 Hugging Face:
https://huggingface.co/fnlp/MOSS-TTSD-v0.5
🚀 核心价值:
对话语音合成 · 语音克隆 · 双语支持 · 开源免费 · 商业可用
项目背景:
-
语音合成需求:高质量语音合成需求增长
-
对话场景:对话式语音合成需求
-
多语言支持:中英文双语支持需求
-
开源生态:开源语音合成生态
-
商业应用:商业化语音合成需求
项目特色:
-
🎭 高表现力:富有表现力的对话语音
-
👥 双说话人:支持两个说话人对话
-
🌐 双语支持:中英文完美支持
-
⏱️ 长语音:支持长语音生成
-
🔓 开源免费:完全开源免费
技术亮点:
-
统一编解码器:语义-声学神经音频编解码
-
大语言模型:基于预训练大语言模型
-
海量数据:数百万小时训练数据
-
语音克隆:零样本语音克隆
-
优化框架:优化的训练推理框架
主要功能
1. 核心功能体系
MOSS-TTSD提供了一套完整的对话语音生成解决方案,涵盖语音合成、语音克隆、双语处理、长语音生成、批量处理、流式推理、API服务、微调训练等多个方面。
语音合成功能:
对话生成:
- 双人对话: 生成两人对话语音
- 自然流畅: 自然对话流畅度
- 情感表达: 丰富情感表达
- 节奏控制: 自然对话节奏
- 语音质量: 高质量语音输出
文本处理:
- 文本解析: 对话文本解析
- 说话人标记: 说话人标记识别
- 文本归一化: 文本归一化处理
- 多语言: 多语言文本支持
- 格式支持: 多种文本格式
输出控制:
- 音频格式: 多种音频格式
- 质量调整: 音质调整控制
- 长度控制: 生成长度控制
- 实时生成: 实时语音生成
- 批量生成: 批量处理支持语音克隆功能:
零样本克隆:
- 参考音频: 短参考音频支持
- 音色克隆: 准确音色克隆
- 说话风格: 说话风格复制
- 个性化: 个性化语音生成
- 快速克隆: 快速克隆能力
参考要求:
- 时长要求: 10-20秒参考音频
- 质量要求: 清晰参考音频
- 文本对应: 参考文本对应
- 多说话人: 多说话人支持
- 混合参考: 混合参考支持
克隆质量:
- 音色准确: 高音色准确性
- 稳定性: 克隆稳定性
- 适应性: 不同场景适应
- 自然度: 高自然度
- 可用性: 实际可用性2. 高级功能
双语支持功能:
中文支持:
- 普通话: 标准普通话支持
- 方言适应: 方言适应能力
- 语音自然: 自然中文语音
- 情感表达: 中文情感表达
- 文化适应: 文化语境适应
英文支持:
- 美式英语: 美式英语支持
- 英式英语: 英式英语适应
- 发音准确: 准确发音
- 语调自然: 自然英语语调
- 口音适应: 不同口音适应
混合对话:
- 中英混合: 中英文混合对话
- 无缝切换: 无缝语言切换
- 语音一致: 语音一致性
- 语境适应: 语境自适应
- 自然过渡: 自然语言过渡长语音功能:
长时生成:
- 长时间: 支持长时生成
- 稳定性: 长时稳定性
- 一致性: 语音一致性
- 内存优化: 内存使用优化
- 性能优化: 性能优化
应用场景:
- 播客生成: 长播客生成
- 有声书: 有声书制作
- 讲座录音: 讲座录音生成
- 会议记录: 会议记录生成
- 教育内容: 教育内容生成
技术优势:
- 低码率: 低码率编解码器
- 框架优化: 训练框架优化
- 效率提升: 生成效率提升
- 质量保持: 质量保持能力
- 资源控制: 资源使用控制处理功能:
批量处理:
- 批量输入: 支持批量输入
- 并行处理: 并行处理能力
- 效率优化: 处理效率优化
- 资源管理: 资源管理优化
- 进度监控: 处理进度监控
流式推理:
- 实时生成: 实时流式生成
- 低延迟: 低延迟生成
- 渐进输出: 渐进式输出
- 内存友好: 内存使用友好
- 体验优化: 用户体验优化
API服务:
- RESTful API: RESTful接口
- 云服务: 云服务支持
- 集成简单: 简单集成方式
- 扩展性强: 强扩展能力
- 商业支持: 商业应用支持安装与配置
1. 环境准备
系统要求:
硬件要求:
- GPU: NVIDIA GPU
- 显存: 8GB+ VRAM
- 内存: 16GB+ RAM
- 存储: 20GB+ 空间
- 系统: Linux推荐
软件要求:
- Python: 3.10+
- CUDA: 11.8+
- Conda: 环境管理
- pip: 包管理
- Git: 版本控制依赖安装:
# 创建Conda环境
conda create -n moss_ttsd python=3.10 -y
conda activate moss_ttsd
# 安装依赖
pip install -r requirements.txt
pip install flash-attn
# 下载XY Tokenizer
mkdir -p XY_Tokenizer/weights
huggingface-cli download fnlp/XY_Tokenizer_TTSD_V0_32k xy_tokenizer.ckpt --local-dir ./XY_Tokenizer/weights/2. 模型准备
模型下载:
# 下载主模型
huggingface-cli download fnlp/MOSS-TTSD-v0.5 --local-dir ./MOSS-TTSD-v0.5
# 或使用Git
git clone https://huggingface.co/fnlp/MOSS-TTSD-v0.5
# 下载Tokenizer
git clone https://huggingface.co/fnlp/XY_Tokenizer_TTSD_V0_32k_hf环境验证:
# 验证安装
python -c "import torch; print('PyTorch版本:', torch.__version__)"
python -c "import transformers; print('Transformers版本:', transformers.__version__)"
# 检查GPU
python -c "import torch; print('CUDA可用:', torch.cuda.is_available())"
python -c "import torch; print('GPU数量:', torch.cuda.device_count())"3. 配置说明
基础配置:
# 推理配置示例
inference_config = {
"model_path": "./MOSS-TTSD-v0.5",
"tokenizer_path": "./XY_Tokenizer_TTSD_V0_32k_hf",
"dtype": "bf16",
"attn_implementation": "flash_attention_2",
"use_normalize": True,
"silence_duration": 0.0
}性能配置:
# 性能优化配置
performance_config = {
"batch_size": 1,
"max_length": 960,
"chunk_size": 20,
"streaming": False,
"memory_fraction": 0.8
}API配置:
# API服务配置
api_config = {
"host": "0.0.0.0",
"port": 30000,
"workers": 4,
"timeout": 300,
"max_requests": 100
}使用指南
1. 基本工作流
使用MOSS-TTSD的基本流程包括:环境准备 → 模型下载 → 配置设置 → 输入准备 → 语音生成 → 结果处理 → 质量评估 → 应用部署。整个过程设计为完整高效。
2. 基本使用
本地推理使用:
1. 准备输入:
- 创建JSONL: 准备输入JSONL文件
- 对话文本: 编写对话文本内容
- 参考音频: 准备参考音频文件
- 说话人标记: 添加说话人标记
- 文本归一化: 文本归一化处理
2. 运行推理:
- 执行命令: 运行推理命令
- 参数设置: 设置推理参数
- 监控进度: 监控生成进度
- 处理错误: 处理可能错误
- 获取结果: 获取生成结果
3. 结果处理:
- 音频文件: 查看生成音频
- 质量检查: 检查音频质量
- 格式转换: 格式转换处理
- 批量处理: 批量结果处理
- 归档保存: 结果归档保存语音克隆使用:
单说话人克隆:
- 准备参考: 准备参考音频
- 参考文本: 准备参考文本
- 音色提取: 提取音色特征
- 生成语音: 生成克隆语音
- 质量验证: 验证克隆质量
双说话人克隆:
- 两人参考: 准备两人参考
- 分别处理: 分别处理两人
- 音色保持: 保持音色一致
- 对话生成: 生成对话语音
- 交互验证: 验证交互效果
质量优化:
- 参考选择: 选择优质参考
- 文本匹配: 文本内容匹配
- 参数调整: 调整克隆参数
- 多次尝试: 多次尝试优化
- 效果评估: 全面效果评估高级使用:
流式推理:
- 启动流式: 启动流式推理
- 实时生成: 实时生成语音
- 渐进输出: 渐进输出音频
- 低延迟: 体验低延迟
- 资源优化: 资源使用优化
API服务:
- 启动服务: 启动API服务
- 客户端: 客户端调用
- 集成应用: 集成到应用
- 批量请求: 处理批量请求
- 监控管理: 服务监控管理
微调训练:
- 数据准备: 准备训练数据
- 配置设置: 设置训练配置
- 启动训练: 启动训练过程
- 监控训练: 监控训练进度
- 模型验证: 验证模型效果3. 高级用法
播客生成使用:
内容准备:
- 文本内容: 准备播客文本
- 结构设计: 设计播客结构
- 说话人分配: 分配说话人角色
- 情感设计: 设计情感表达
- 节奏规划: 规划节奏变化
生成处理:
- 输入格式: 准备输入格式
- 参数优化: 优化生成参数
- 批量生成: 批量生成处理
- 质量检查: 检查生成质量
- 后期处理: 进行后期处理
发布应用:
- 格式导出: 导出发布格式
- 平台上传: 上传到平台
- 听众反馈: 收集听众反馈
- 持续优化: 持续优化改进
- 规模化: 规模化生产教育应用使用:
教学材料:
- 课程内容: 生成课程音频
- 多语言: 多语言课程
- 互动对话: 互动对话内容
- 个性化: 个性化学习材料
- 无障碍: 无障碍教育支持
语言学习:
- 发音学习: 发音学习材料
- 对话练习: 对话练习生成
- 情景模拟: 情景模拟对话
- 评估反馈: 发音评估反馈
- 个性化: 个性化学习
有声材料:
- 有声书: 生成有声书
- 教材音频: 教材音频版
- 辅助材料: 学习辅助材料
- 多版本: 多版本支持
- 质量保证: 教育质量保证商业应用使用:
客户服务:
- 语音助手: 语音助手开发
- 自动应答: 自动应答系统
- 多语言: 多语言客服
- 个性化: 个性化服务
- 效率提升: 服务效率提升
媒体制作:
- 广播节目: 广播节目制作
- 广告配音: 广告配音生成
- 内容创作: 音频内容创作
- 成本控制: 制作成本控制
- 快速迭代: 快速迭代能力
企业培训:
- 培训材料: 培训音频材料
- 多语言培训: 多语言培训
- 标准化: 内容标准化
- 一致性: 语音一致性
- 效果提升: 培训效果提升应用场景实例
案例1:AI播客制作
场景:自动化播客内容生产
解决方案:使用MOSS-TTSD生成播客内容。
实施方法:
-
内容准备:准备播客文本内容
-
角色分配:分配主持人嘉宾角色
-
语音克隆:克隆主持人声音
-
对话生成:生成对话内容
-
后期处理进行后期处理制作
播客价值:
-
生产效率:大幅提高生产效率
-
成本控制:有效控制成本
-
质量一致:保持质量一致性
-
多语言:支持多语言播客
-
个性化:高度个性化内容
案例2:教育音频内容
场景:教育机构音频材料生成
解决方案:使用MOSS-TTSD生成教育音频。
实施方法:
-
教材处理:处理教材文本内容
-
教师语音:克隆教师语音
-
课程生成:生成课程音频
-
多语言:生成多语言版本
-
学生使用:学生使用学习
教育价值:
-
学习资源:丰富学习资源
-
无障碍:支持无障碍学习
-
个性化:个性化学习体验
-
成本效益:成本效益高
-
质量保证:教育质量保证
案例3:企业培训系统
场景:企业培训材料生成
解决方案:使用MOSS-TTSD生成培训材料。
实施方法:
-
培训内容:准备培训文本内容
-
讲师语音:克隆讲师语音
-
多语言:生成多语言版本
-
员工培训:员工使用培训
-
效果评估:培训效果评估
企业价值:
-
培训效率:提高培训效率
-
一致性:内容一致性
-
多地区:支持多地区
-
成本优化:优化培训成本
-
标准化:培训标准化
案例4:无障碍服务
场景:视障人士服务支持
解决方案:使用MOSS-TTSD提供语音服务。
实施方法:
-
文本内容:准备服务文本内容
-
语音生成:生成服务语音
-
自然交互:自然语音交互
-
多场景:多场景应用
-
用户体验:优化用户体验
社会价值:
-
无障碍:促进无障碍服务
-
包容性:提高社会包容性
-
生活质量:改善生活质量
-
技术普惠:技术普惠应用
-
社会效益:显著社会效益
案例5:内容创作平台
场景:音频内容创作平台
解决方案:使用MOSS-TTSD赋能内容创作。
实施方法:
-
平台集成:集成到创作平台
-
用户使用:用户使用生成
-
多样化:支持多样化内容
-
质量保障保障内容质量
-
生态建设:建设创作生态
平台价值:
-
创作赋能:赋能内容创作
-
多样性:内容多样性
-
效率提升:创作效率提升
-
用户体验:良好用户体验
-
商业价值:显著商业价值
总结
MOSS-TTSD作为一个先进的对话语音生成模型,通过其高质量语音合成、精准语音克隆、双语支持、长语音生成、开源免费等特性,为语音合成领域提供了强大的解决方案。
核心优势:
-
🎵 高质量:高质量语音合成
-
👥 双说话人:自然对话生成
-
🌐 双语:中英文双语支持
-
⏱️ 长语音:长语音生成能力
-
🔓 开源:完全开源免费
适用场景:
-
AI播客制作
-
教育音频内容
-
企业培训系统
-
无障碍服务
-
内容创作平台
立即开始使用:
# 安装环境
conda create -n moss_ttsd python=3.10 -y
conda activate moss_ttsd
# 安装依赖
pip install -r requirements.txt
pip install flash-attn
# 下载模型
git clone https://huggingface.co/fnlp/MOSS-TTSD-v0.5资源链接:
-
📚 项目地址:GitHub仓库
-
🤗 模型仓库:Hugging Face
-
📖 文档:详细文档
-
💬 社区:社区讨论
-
🐛 问题:GitHub Issues
通过MOSS-TTSD,您可以:
-
语音生成:生成高质量语音
-
语音克隆:克隆特定音色
-
多语言:处理多语言内容
-
长音频:生成长音频内容
-
商业应用:商业场景应用
无论您是内容创作者、教育工作者、企业用户、开发者还是研究者,MOSS-TTSD都能为您提供强大、高效且高质量的语音生成解决方案!
特别提示:
-
💻 硬件准备:确保GPU配置
-
📋 依赖安装:正确安装依赖
-
📖 文档阅读:阅读使用文档
-
🐛 问题报告:报告遇到的问题
-
🤝 社区支持:利用社区帮助
通过MOSS-TTSD,体验语音生成的未来!
未来发展:
-
🚀 更多功能:持续添加新功能
-
🤖 更智能:更智能的生成
-
🌍 更广泛:更广泛的支持
-
⚡ 更快速:更快的生成速度
-
🔧 更易用:更简单的使用
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 社区: 加入社区讨论
- 反馈: 提供使用反馈
- 开发: 参与代码开发
- 推广: 帮助项目推广
社区价值:
- 技术交流学习
- 问题解答支持
- 功能建议讨论
- 使用经验分享
- 合作机会发现通过MOSS-TTSD,共同推动语音合成技术发展!
许可证:
Apache 2.0许可证
免费用于商业用途致谢:
特别感谢:
- 开发团队: OpenMOSS团队
- 贡献者: 代码贡献者
- 社区: 社区支持者
- 用户: 用户反馈支持
- 机构: 支持机构通过MOSS-TTSD,创造语音的无限可能!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献258条内容
已为社区贡献258条内容

所有评论(0)