VaDE论文笔记
VaDE(Variational Deep Embedding变分深度嵌入)是在VAE基础上利用GMM和DNN的无监督生成聚类方法(即只输入数据,就能生成新的数据同时还能聚类)。训练过程中两个神经网络的参数同时训练,但不共享,各自有自己的权重、偏置、层结构,不过一般设为对称结构,尤其在图像数据上,重构会更稳定,有助于还原原始数据。输入的是数据x和参数形式的先验,通过最大化ELBO训练模型,输出的是
论文链接:[1611.05148] Variational Deep Embedding: An Unsupervised and Generative Approach to Clustering

VaDE(Variational Deep Embedding变分深度嵌入)是在VAE基础上利用GMM和DNN的无监督生成聚类方法(即只输入数据,就能生成新的数据同时还能聚类)。
输入的是数据x和参数形式的先验,通过最大化ELBO训练模型,输出的是潜在参数、聚类标签以及生成的新数据
。
一、VaDE模型
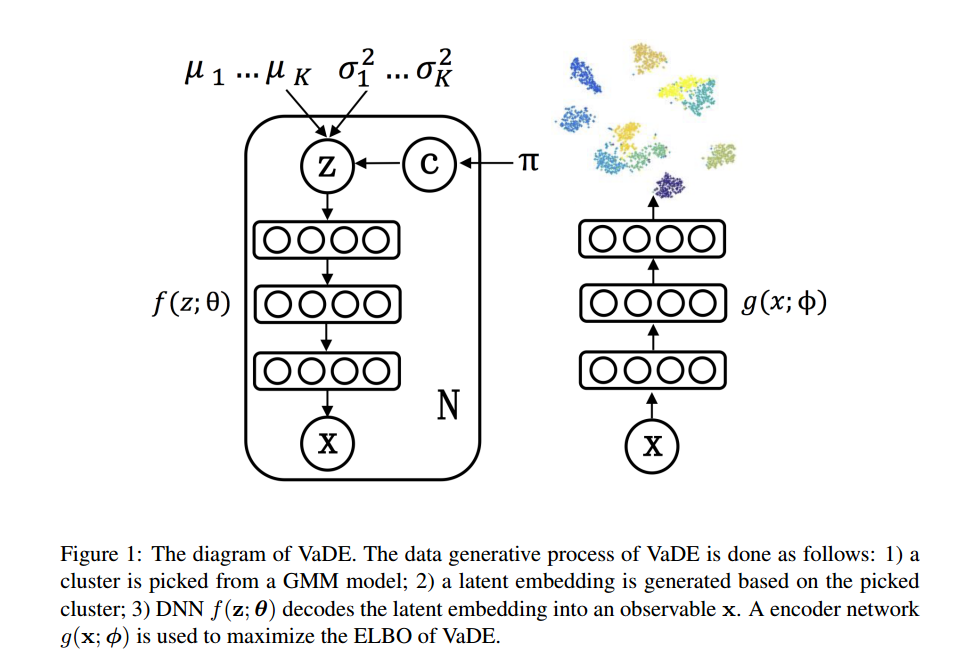
图中左边是数据生成过程:
1.首先数据有k个类别,每个聚类对应一个高斯分布(总共有k个聚类),k=10。从GMM(混合高斯分布)中选择一个聚类c。
是每个聚类的先验概率(权重):
比如表示有20%的样本属于类1,30%的样本属于类2,50%的样本属于类3。
一般初始为均匀分布,后期经过神经网络训练学习。
2.然后从聚类c对应的高斯分布中采样z,z是潜在变量,维数为10。
z 是由 多个高斯分布混合 而来的,每个高斯代表一个聚类。
3.将z通过神经网络解码为x
其数学描述如下:
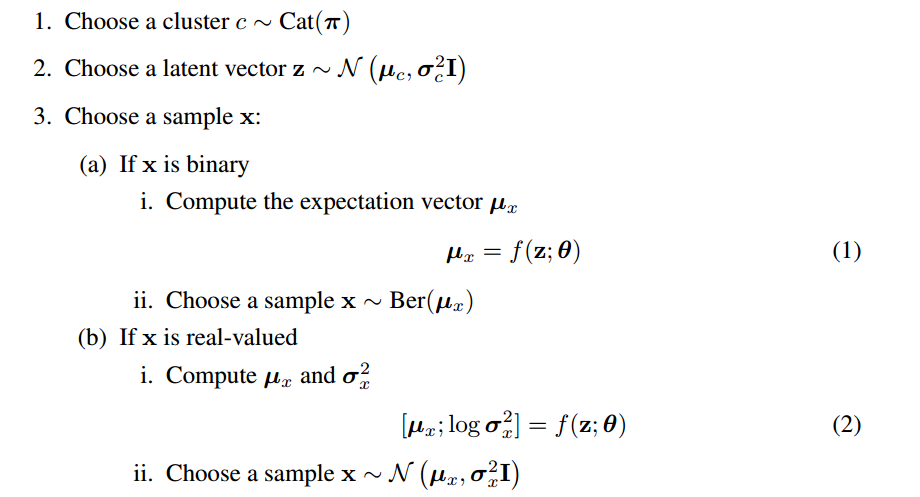
图中右边是数据的训练过程:
1.我们现在只有数据x和关于参数形式的一些先验,输入这些
2.利用编码器得到
:
3.利用重参数化技巧采样z:
4.使用贝叶斯公式计算“z 属于第 c 类的概率”:
5.解码器:
我们想看看解码出来的和原始数据x的差距有多大,通过最大化ELBO和反向传播来更新参数使得解码出来的
和原始数据x很相似,也就得到了我们想要的参数和聚类标签。
6.最大化ELBO:
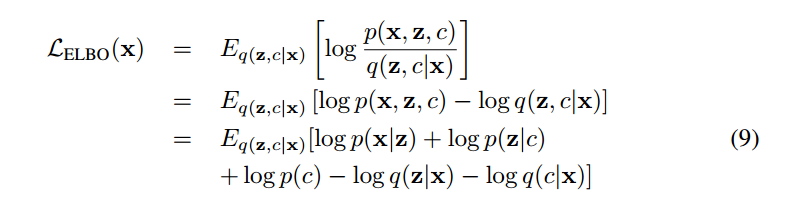
使用SGVB估计器和重新参数化技巧,ELBO重写为:

其中第一项为重建误差,衡量z解码生成的新样本 与原样本x的差距;第二项为KL 散度项(从 q(z|x) 到 p(z|c)),惩罚
z 的编码分布 q(z|x) 偏离了每个聚类的先验分布 p(z|c);第三项为样本的分类分布 q(c|x) 与先验分布 p(c) = π 的 KL 散度;第四项为q(z|x) 的熵项。(注:数学推导出来的,不太明白咋推导的!!!具体细节参考:变分深度嵌入(Variational Deep Embedding, VaDE) - 凯鲁嘎吉 - 博客园)
然后对全部参数反向传播更新参数。
训练完如何聚类:
对样本x,计算z=g(x),计算p(c|z),选最大概率对应的聚类作为最终聚类标签。
训练过程中两个神经网络的参数同时训练,但不共享,各自有自己的权重、偏置、层结构,不过一般设为对称结构,尤其在图像数据上,重构会更稳定,有助于还原原始数据。
代码里面训练停止是 固定训练轮数(epoch=300)达到上限。
我对代码做了一些改动,最终结果:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)