基于刘焕勇医药问答系统详解
该项目构建了一个基于医疗知识图谱的智能问答系统,主要包含以下内容:1) 从寻医问药网站爬取医疗数据,构建包含4.4万实体和30万关系的知识图谱;2) 采用双向最大匹配算法进行医疗文本分词;3) 系统包含问题分类、解析、搜索三个核心模块,实现医疗问题的自动解答;4) 需要配置MongoDB和Neo4j数据库环境。该系统完整展示了从数据采集到智能问答的流程,为医疗领域知识图谱应用提供了参考框架。
该项目是一个以寻医问药网站为数据来源、以疾病为核心构建的医疗知识图谱问答系统,涵盖从数据采集、知识图谱构建到智能问答的全流程。项目构建了包含7 类 4.4 万知识实体(疾病、药品、症状等)和11 类约 30 万实体关系的知识图谱,其中涵盖 8000 多种疾病(肝病相关 200 多种),最终实现医疗问题的智能解答。
项目地址:https://github.com/liuhuanyong/QASystemOnMedicalKG
如果想要吧此代码下载到自己电脑上可以选择将这一部分文件先添加到自己的仓库中,然后使用Github Desktop从仓库复制到自己电脑上,但是注意这一步需要挂代理,否则可能加载不进去。
一、项目介绍
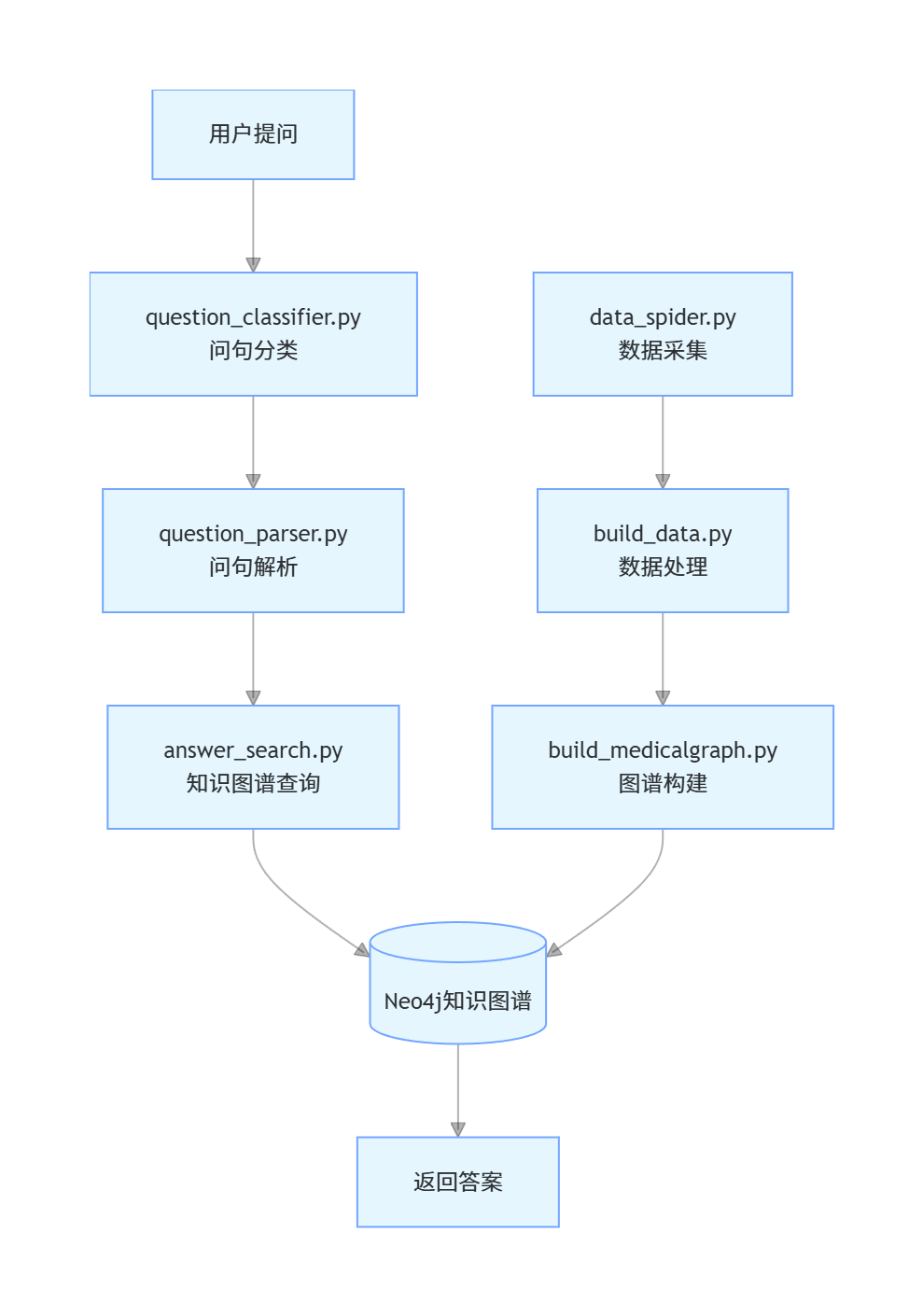
1.数据准备阶段
该项目的数据来自寻医问药网站,在数据准备阶段使用爬虫data_spider.py进行数据爬取并保存到medical.json,使用build_data.py构建知识图谱,最后使用max_cut.py进行字段分割。
数据准备阶段文件:
├── QASystemOnMedicalKG/prepare_data
├── build_data.py # 数据库操作脚本
├── data_spider.py # 数据采集脚本
├── max_cut.py # 基于词典的最大前向/后向匹配
2.医药知识问答阶段
在医药知识问答阶段中主要使用answer_search.py进行问题查询及返回,build_medicalgraph.py将结构化的json数据导入到neo4j中,
├── QASystemOnMedicalKG
├── answer_search.py # 问题查询及返回
├── build_medicalgraph.py # 将结构化json数据导入neo4j
├── chatbot_graph.py # 问答程序脚本
├── QASystemOnMedicalKG/data
├── hepatopathy.json # 肝病知识数据
├── medical.json # 全科知识数据
├── QASystemOnMedicalKG/dict
├── check.txt # 诊断检查项目实体库
├── deny.txt # 否定词库
├── department.txt # 医疗科目实体库
├── disease.txt # 疾病实体库
├── drug.txt # 药品实体库
├── food.txt # 食物实体库
├── producer.txt # 在售药品库
├── symptom.txt # 疾病症状实体库
├── QASystemOnMedicalKG/prepare_data
├── build_data.py # 数据库操作脚本
├── data_spider.py # 数据采集脚本
├── max_cut.py # 基于词典的最大前向/后向匹配
├── question_classifier.py # 问句类型分类脚本
├── question_parser.py # 问句解析脚本
大致流程图如下:
二、容易踩的坑
在这个项目运行的前提就是需要配置MongDB数据库以及Neo4j内存配置。
1.MongDB数据库配置
MongoDB 是一个开源的、面向文档的 NoSQL 数据库。它不是传统的关系型数据库(如 MySQL、PostgreSQL),而是以类似 JSON 的 BSON(Binary JSON)格式存储数据,这使得它非常灵活,不需要预定义固定的表结构。
步骤一:下载安装包
在Windows上,访问MongDB官网下载中心:Download MongoDB Community Server | MongoDB选择适合Windows的版本(推荐MSI安装包),下载并安装程序。
步骤二:安装MongDB
安装MongDB,选择“Complete”完整安装,可选择MongDB Compass(图形化管理工具),按照向导完成安装。
步骤三:配置环境变量
将 MongoDB 的 bin 目录(通常是C:\Program Files\MongoDB\Server\版本号\bin)添加到系统环境变量PATH中
步骤四:创建数据目录
mkdir C:\data\db
mkdir C:\data\log步骤五:启动MongDB服务
# 方式1:作为控制台应用启动
mongod --dbpath C:\data\db
# 方式2:安装为Windows服务
mongod --dbpath C:\data\db --logpath C:\data\log\mongod.log --install
net start MongoDB步骤六:连接MongDB
mongo
# 或使用MongoSH(新版)
mongosh验证与结果
启动成功后,你可以通过mongosh或mongo命令连接到 MongoDB,输入show dbs命令可以查看现有数据库,验证连接是否成功,MongoDB 默认监听端口为27017。另外,MongoDB 启动后默认以无认证模式运行,生产环境中建议配置安全认证和其他参数。
2.Neo4j配置
Neo4j的配置主要分为两部分,一部分是Java环境的配置,另一部分是对Neo4j的下载以及启动服务。
步骤一:Java环境的配置
Neo4j必须现在系统中配置Java环境,可以直接在Java官网:Java | Oracle直接下载,并在下载完成后解压缩,解压的位置可以自定义。
随后将Java配置到系统变量中,在控制面板中找到系统环境变量,也可以直接开始界面直接搜索。
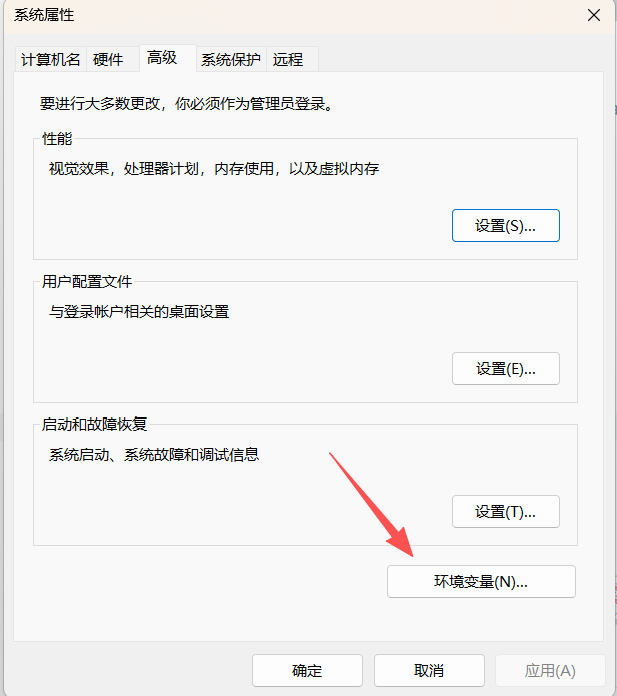
接着在系统变量中点金新建,变量名设为JAVA_HOME,变量值为刚刚解压完成后的jdk文件位置,随后点击确定。
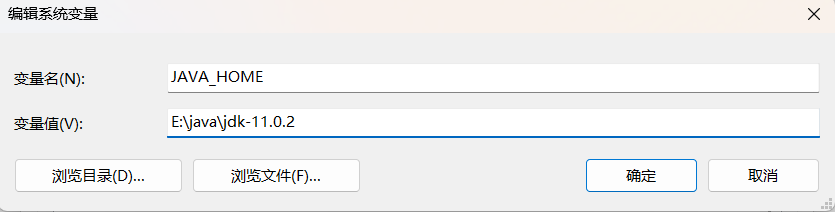
选中系统变量中的Path,点击编辑按钮。
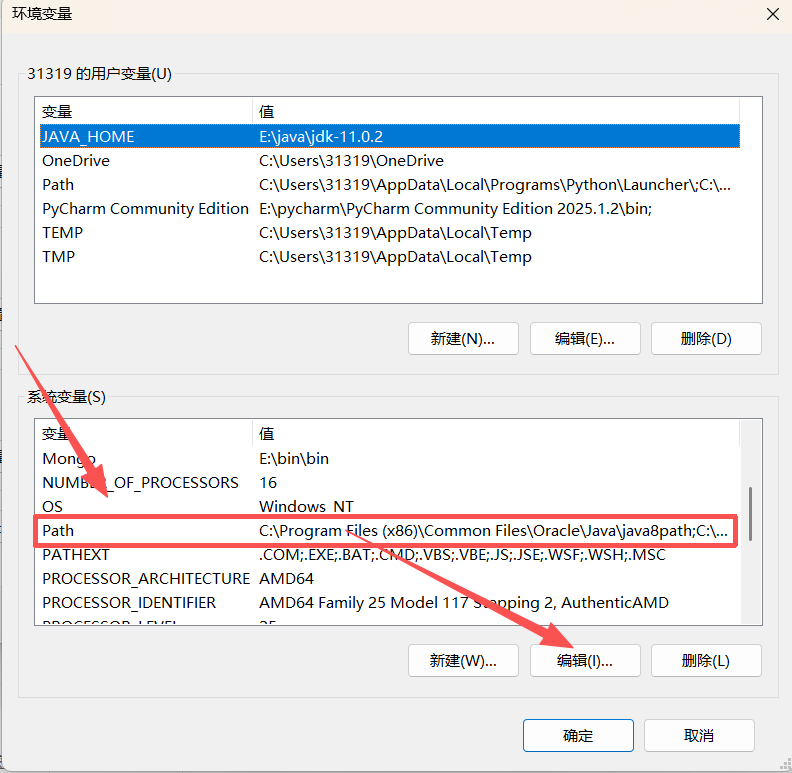
点击新建,把Java文件夹下的jdk文件夹的bin文件位置写入,完成后点击确定。
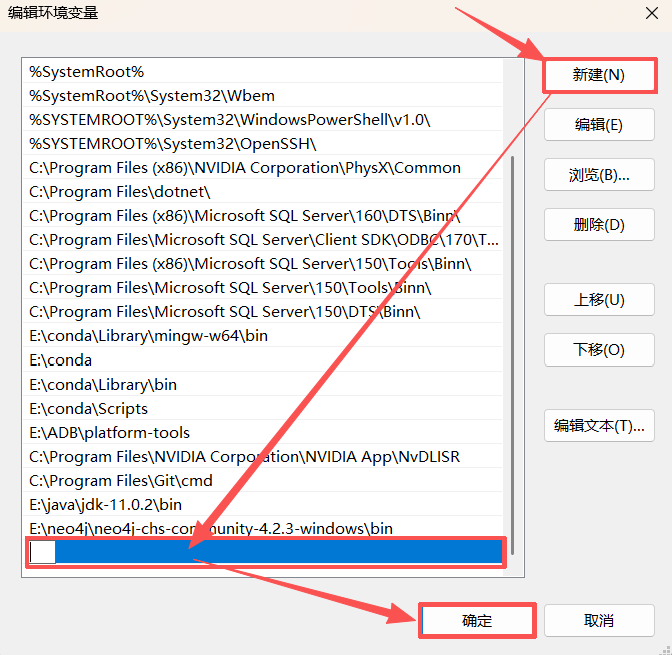
最后,依次点击确定退出。
步骤二:Neo4j服务的连接
建议下载Neo4j Desktop,这是最简单、最直接的方式。
1.访问官网下载页面
直接访问 Neo4j 的官方下载中心:https://neo4j.com/download/
2.选择 Neo4j Desktop
在页面上,您会看到几个选项。找到 “Neo4j Desktop” 并点击 “Download” 按钮。
4.填写信息并下载
需要填写一张表格,内容包括姓名、公司邮箱等信息,选择适合您操作系统的版本(Windows、macOS 或 Linux),勾选同意许可协议,点击下载按钮。
5.安装并运行
下载完成后,运行安装程序,按照提示完成安装(基本都是“下一步”即可),首次启动时,系统会提示您创建一个新的 Neo4j 账户或登录(默认的账号密码是neo4j),随后可以改为自己的想使用的密码。
三、部分代码解释
1.数据部分
在data_spider.py部分中在寻医问药网站主要爬取了八类医疗信息,它们分别是疾病的基本信息、病因、预防、症状、检查、治疗、饮食以及药品,需要注意的是饮食部分分为宜食和忌食。
# 采集8类医疗信息
basic_url = 'http://jib.xywy.com/il_sii/gaishu/%s.htm' % page # 基本信息
cause_url = 'http://jib.xywy.com/il_sii/cause/%s.htm' % page # 病因
prevent_url = 'http://jib.xywy.com/il_sii/prevent/%s.htm' % page # 预防
symptom_url = 'http://jib.xywy.com/il_sii/symptom/%s.htm' % page # 症状
inspect_url = 'http://jib.xywy.com/il_sii/inspect/%s.htm' % page # 检查
treat_url = 'http://jib.xywy.com/il_sii/treat/%s.htm' % page # 治疗
food_url = 'http://jib.xywy.com/il_sii/food/%s.htm' % page # 饮食
drug_url = 'http://jib.xywy.com/il_sii/drug/%s.htm' % page # 药品并且有着统一的数据清洗流程。
# 统一的数据清洗流程
info = p.xpath('string(.)').replace('\r', '').replace('\n', '').replace('\xa0', '').replace(' ','').replace('\t', '')最后将它们按照一定的结构存入到MongDB中。
data = {
'url': basic_url,
'basic_info': {...}, # 基本信息
'cause_info': '...', # 病因信息
'prevent_info': '...', # 预防信息
'symptom_info': [...], # 症状信息
'inspect_info': [...], # 检查信息
'treat_info': [...], # 治疗信息
'food_info': {...}, # 饮食信息
'drug_info': [...] # 药品信息
}
self.col.insert_one(data) # 存入MongoDB其中max_cut.py部分不需要单独执行,作为了工具模块被build_data.py调用。在max_cut.py主要使用了三种匹配方法,分别是正向最大匹配、逆向最大匹配以及作为核心的双向最大匹配。
正向最大匹配是从左到右扫描文本,每次取最大可能长度的词进行匹配,匹配失败则按单字切分。
def max_forward_cut(self, sent):
cutlist = []
index = 0
while index < len(sent):
matched = False
# 从最大词长到1递减尝试匹配
for i in range(self.max_wordlen, 0, -1):
cand_word = sent[index: index + i]
if cand_word in self.word_dict:
cutlist.append(cand_word)
matched = True
break
# 未匹配则按单字切分
if not matched:
i = 1
cutlist.append(sent[index])
index += i
return cutlist逆向最大匹配是从右到左扫描文本,同样采用最大匹配原则,最终结果需要反转以保持原顺序。
def max_backward_cut(self, sent):
cutlist = []
index = len(sent)
max_wordlen = 5
while index > 0:
matched = False
for i in range(self.max_wordlen, 0, -1):
tmp = (i + 1)
cand_word = sent[index - tmp: index]
if cand_word in self.word_dict:
cutlist.append(cand_word)
matched = True
break
if not matched:
tmp = 1
cutlist.append(sent[index - 1])
index -= tmp
return cutlist[::-1] # 结果反转双向最大匹配中有两种决策规则一种是“词数不同 → 选择分词数量少的”,另一种是“词数相同 → 选择单字数量少的”。
def max_biward_cut(self, sent):
# 分别进行正向和逆向分词
forward_cutlist = self.max_forward_cut(sent)
backward_cutlist = self.max_backward_cut(sent)
count_forward = len(forward_cutlist)
count_backward = len(backward_cutlist)
def compute_single(word_list):
num = 0
for word in word_list:
if len(word) == 1:
num += 1
return num
# 决策规则
if count_forward == count_backward:
# 词数相同时选择单字较少的
if compute_single(forward_cutlist) > compute_single(backward_cutlist):
return backward_cutlist
else:
return forward_cutlist
elif count_backward > count_forward:
return forward_cutlist # 选择词数较少的
else:
return backward_cutlist双向最大匹配决策规则详解
# 规则1:词数不同 → 选择分词数量少的
if count_backward > count_forward:
return forward_cutlist # 正向分词词数少
else:
return backward_cutlist # 逆向分词词数少
# 规则2:词数相同 → 选择单字数量少的
if compute_single(forward_cutlist) > compute_single(backward_cutlist):
return backward_cutlist # 逆向分词单字少
else:
return forward_cutlist # 正向分词单字少这种匹配规则优点是基于词典的匹配,实现简单,通过双向比较解决歧义问题,使用医疗领域词典(disease.txt),适合医疗文本分词;缺点为,分词质量完全依赖词典覆盖度,无法识别词典外的新词,缺乏语义理解能力。
在build_data.py部分,数据处理部分采用了渐进式处理,逐文档处理,避免内存溢出;采用try-catch保护,单文档失败不影响整体以及使用了进度监控,用计数器显示处理进度。在数据质量方面首先将格式统一:中文字段转英文标识,随后进行内容清洗:去除空白字符、特殊格式,其次进行无效过滤:停用词过滤、空值跳过,最后完成结构化处理:文本分割、分词处理。
在build_data.py主要分为了三个模块,这三个模块分别是主处理流程collecct_medical()、检查get_inspect()和数据更新modify_jc()。
在build_data.py中有停用词系统,可以过滤无效字符,提高数据质量。
# 读取姓氏文件作为停用词
first_words = [i.strip() for i in open(os.path.join(cur_dir, 'first_name.txt'))]
# 定义英文字母和数字作为停用词
alphabets = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y', 'z']
nums = ['1','2','3','4','5','6','7','8','9','0']
# 合并所有停用词
self.stop_words = first_words + alphabets + nums2.问答部分
知识图谱构建部分
该部分用于构建一个医疗知识图谱,通过解析 JSON 格式的医疗数据,在 Neo4j 图数据库中创建实体节点(如疾病、药品、症状等)和实体间的关系(如疾病 - 症状、疾病 - 药品等),并支持数据导出。
初始化部分计算当前文件目录,拼接医疗数据(medical.json)的路径,并建立与 Neo4j 数据库的连接(需本地启动 Neo4j 服务,账号密码需匹配)。
class MedicalGraph:
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.data_path = os.path.join(cur_dir, 'data/medical.json') # 医疗数据路径
self.g = Graph(
"bolt://localhost:7687",
auth=("neo4j", "neo4j") # Neo4j数据库连接信息
)
在build_medicalgraph.py中定义了七类节点,十种关系类型。
# 共7类节点
drugs = [] # 药品
foods = [] # 食物
checks = [] # 检查
departments = [] # 科室
producers = [] # 药品厂商
diseases = [] # 疾病
symptoms = [] # 症状
# 关系类型(共10类)
rels_department = [] # 科室-科室(层级关系)
rels_noteat = [] # 疾病-忌吃食物
rels_doeat = [] # 疾病-宜吃食物
rels_recommandeat = [] # 疾病-推荐食物
rels_commonddrug = [] # 疾病-通用药品
rels_recommanddrug = [] # 疾病-热门药品
rels_check = [] # 疾病-检查
rels_drug_producer = [] # 厂商-药物
rels_symptom = [] # 疾病-症状
rels_acompany = [] # 疾病-并发症
rels_category = [] # 疾病-所属科室
节点创建(create_graphnodes及辅助方法)疾病节点包含丰富属性(描述、预防、病因等),其他节点仅需名称属性。通过py2neo.Node定义节点,调用graph.create写入数据库。
# 创建普通节点(药品、食物等)
def create_node(self, label, nodes):
for node_name in nodes:
node = Node(label, name=node_name) # 定义节点标签和名称属性
self.g.create(node) # 写入Neo4j
# 创建疾病节点(含详细属性)
def create_diseases_nodes(self, disease_infos):
for disease_dict in disease_infos:
node = Node("Disease",
name=disease_dict['name'],
desc=disease_dict['desc'], # 疾病描述
prevent=disease_dict['prevent'], # 预防措施
# 其他属性:病因、易感人群、治疗方式等...
)
self.g.create(node)
# 统一创建所有节点
def create_graphnodes(self):
# 读取所有实体数据
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, ... = self.read_nodes()
self.create_diseases_nodes(disease_infos) # 创建疾病节点
self.create_node('Drug', Drugs) # 创建药品节点
self.create_node('Food', Foods) # 创建食物节点
# 其他节点:检查、科室、厂商、症状...关系创建(create_graphrels及辅助方法),关系创建前需去重(通过字符串拼接 + 集合去重),使用 Cypher 语句匹配两个节点,然后创建带类型和名称的关系。
def export_data(self):
# 读取所有实体数据
Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, ... = self.read_nodes()
# 导出到文本文件
with open('drug.txt', 'w+') as f_drug:
f_drug.write('\n'.join(list(Drugs)))
# 其他实体文件:food.txt、check.txt等...问答部分
该系统是一个基于知识图谱的医疗问答系统,主要由 4 个核心模块组成:问题分类器(question_classifier.py):识别问题中的实体(疾病、症状等)和问题类型(如 “疾病的症状是什么”)、问题解析器(question_parser.py):将分类结果转换为知识图谱查询语句(Cypher)、答案搜索器(answer_search.py):执行查询并格式化返回结果以及主程序(chatbot_graph.py):串联上述模块,实现问答流程。
1. 问题分类器(question_classifier.py)
这一部分是从用户问题中提取医疗实体(如疾病、症状),并判断问题类型。使用了 AC 自动机(多模式匹配算法)快速识别文本中的医疗实体,基于关键词匹配判断问题类型(如 “原因” 对应病因查询),处理否定词(如 “不”“忌”)影响问题类型。
# AC自动机构建(快速匹配实体)
def build_actree(self, wordlist):
actree = ahocorasick.Automaton()
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word)) # 添加词到自动机
actree.make_automaton() # 构建自动机
return actree
# 实体提取(过滤重复/包含关系的实体)
def check_medical(self, question):
region_wds = []
for i in self.region_tree.iter(question): # 匹配问题中的实体
wd = i[1][1]
region_wds.append(wd)
# 去除被包含的短实体(如“感冒”包含于“重感冒”则保留后者)
stop_wds = [wd1 for wd1 in region_wds for wd2 in region_wds if wd1 in wd2 and wd1 != wd2]
final_wds = [i for i in region_wds if i not in stop_wds]
return {i: self.wdtype_dict.get(i) for i in final_wds} # 实体-类型映射
# 问题类型判断
def classify(self, question):
data = {"args": self.check_medical(question)} # 提取实体
if not data["args"]:
return {}
types = [t for ts in data["args"].values() for t in ts] # 实体类型集合
question_types = []
# 示例:判断“疾病-症状”类型(含“症状”关键词且实体含疾病)
if self.check_words(self.symptom_qwds, question) and "disease" in types:
question_types.append("disease_symptom")
# 其他类型判断逻辑...
data["question_types"] = question_types
return data2. 问题解析器(question_parser.py)
这一部分是将分类结果(实体 + 问题类型)转换为知识图谱的 Cypher 查询语句。根据问题类型生成对应的查询模板,支持多实体批量查询(如同时查多种疾病的症状),处理双向关系(如并发症需查询 “A 并发 B” 和 “B 并发 A”)。
# 构建实体字典(按类型分组)
def build_entitydict(self, args):
entity_dict = {}
for arg, types in args.items():
for type in types:
entity_dict.setdefault(type, []).append(arg) # 如{"disease": ["感冒", "发烧"]}
return entity_dict
# 生成Cypher查询
def sql_transfer(self, question_type, entities):
if not entities:
return []
sql = []
# 示例1:查询疾病症状(匹配关系has_symptom)
if question_type == "disease_symptom":
sql = [
f"MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where m.name = '{i}' return m.name, r.name, n.name"
for i in entities
]
# 示例2:查询并发症(双向关系)
elif question_type == "disease_acompany":
sql1 = [f"MATCH (m:Disease)-[r:acompany_with]->(n:Disease) where m.name = '{i}' return ..." for i in entities]
sql2 = [f"MATCH (m:Disease)-[r:acompany_with]->(n:Disease) where n.name = '{i}' return ..." for i in entities]
sql = sql1 + sql2 # 合并双向查询
# 其他类型查询模板...
return sql3. 答案搜索器(answer_search.py)
这一部分是执行 Cypher 查询,格式化结果为自然语言回答。连接了 Neo4j 知识图谱并执行查询,根据问题类型使用不同模板格式化答案,去重和结果截断(避免信息过载)。
def __init__(self):
# 连接Neo4j数据库
self.g = Graph("bolt://localhost:7687", auth=("neo4j", "lpf123456"))
self.num_limit = 20 # 结果最大数量限制
# 执行查询并处理结果
def search_main(self, sqls):
final_answers = []
for sql_ in sqls:
question_type = sql_["question_type"]
for query in sql_["sql"]:
ress = self.g.run(query).data() # 执行Cypher查询
final_answer = self.answer_prettify(question_type, ress)
if final_answer:
final_answers.append(final_answer)
return final_answers
# 答案格式化(按问题类型模板输出)
def answer_prettify(self, question_type, answers):
if not answers:
return ""
# 示例:疾病症状格式化
if question_type == "disease_symptom":
symptoms = list(set([i["n.name"] for i in answers]))[:self.num_limit] # 去重+截断
return f"{answers[0]['m.name']}的症状包括:{';'.join(symptoms)}"
# 示例:宜食食物格式化(区分“宜吃”和“推荐食谱”关系)
elif question_type == "disease_do_food":
do_food = [i["n.name"] for i in answers if i["r.name"] == "宜吃"]
recommand_food = [i["n.name"] for i in answers if i["r.name"] == "推荐食谱"]
return f"{answers[0]['m.name']}宜食:{';'.join(do_food)}\n推荐食谱:{';'.join(recommand_food)}"
# 其他类型格式化模板...4. 主程序(chatbot_graph.py)
这一部分功能主要是串联分类、解析、搜索模块,实现完整问答流程。
class ChatBotGraph:
def __init__(self):
self.classifier = QuestionClassifier() # 初始化分类器
self.parser = QuestionPaser() # 初始化解析器
self.searcher = AnswerSearcher() # 初始化搜索器
def chat_main(self, sent):
answer = "默认回答(无法识别时返回)"
res_classify = self.classifier.classify(sent) # 1. 分类
if not res_classify:
return answer
res_sql = self.parser.parser_main(res_classify) # 2. 生成查询
final_answers = self.searcher.search_main(res_sql) # 3. 执行查询
return "\n".join(final_answers) if final_answers else answer总结
该项目是一个典型的领域知识图谱问答系统,完整展示了从数据获取到智能问答的全流程实现。其核心价值在于将非结构化医疗数据转化为结构化知识图谱,并通过规则式方法实现医疗问题的自动解答,为医疗领域的智能问答系统构建提供了可参考的框架。同时,项目也暴露了规则式方法的局限性,未来可结合机器学习模型优化实体识别和意图分类,提升系统的泛化能力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)