Qwen-Image网络结构与位置编码解读
这两年图像生成任务做的越来越好,应该马上就能满足实际需求了,达到普通人难以分辨的程度。随着算力和显存的提升,模型越来越倾向于将所有输入直接token化,然后定制位置编码后直接整个送入transformer。后续视频生成任务估计也会有类似的发展趋势,本文中的VAE用Wan 2.1 估计就是为此铺路的。不过视频消耗的资源还是太多了,何况transformer的复杂度是n的平方,估计一两年内还是做不到像
简介
Qwen-Image目标是图像生成的基础模型,能够实现图片生成/编辑任务。结构方面能够看到采用了纯双流的方案。同时位置编码部分应该有参考Flux,但也做了一定程度的改进。
注:本文仅关注网络结构与位置编码,对于数据、训练策略等并不关注。
方法
结构
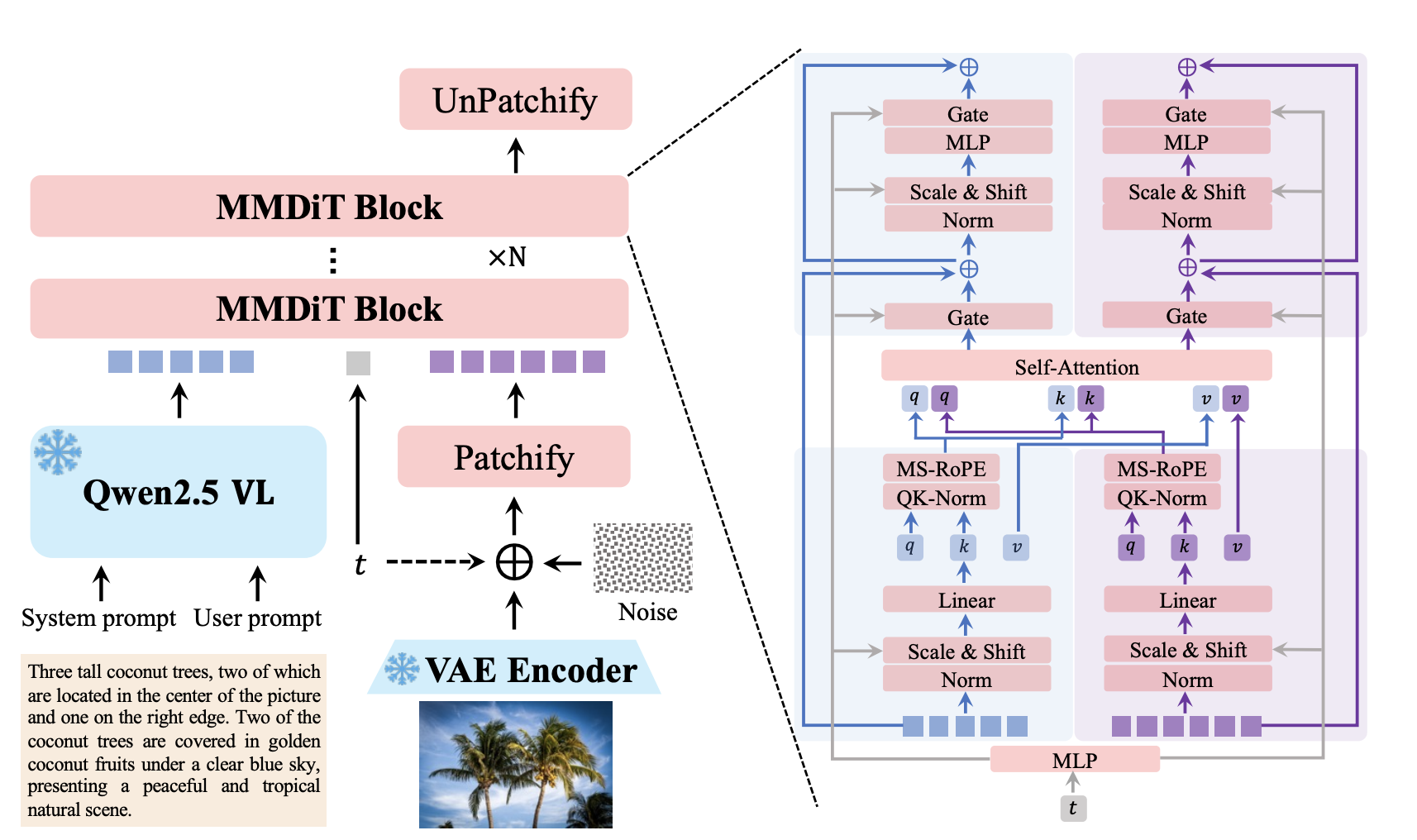
可以看到就是纯双流的方法来融合文本和图片特征。文本特征编码器直接用Qwen2.5 VL,VAE则是用Wan 2.1 的VAE,其中Wan 2.1 VAE的编码器冻结,解码器会经过微调。
位置编码
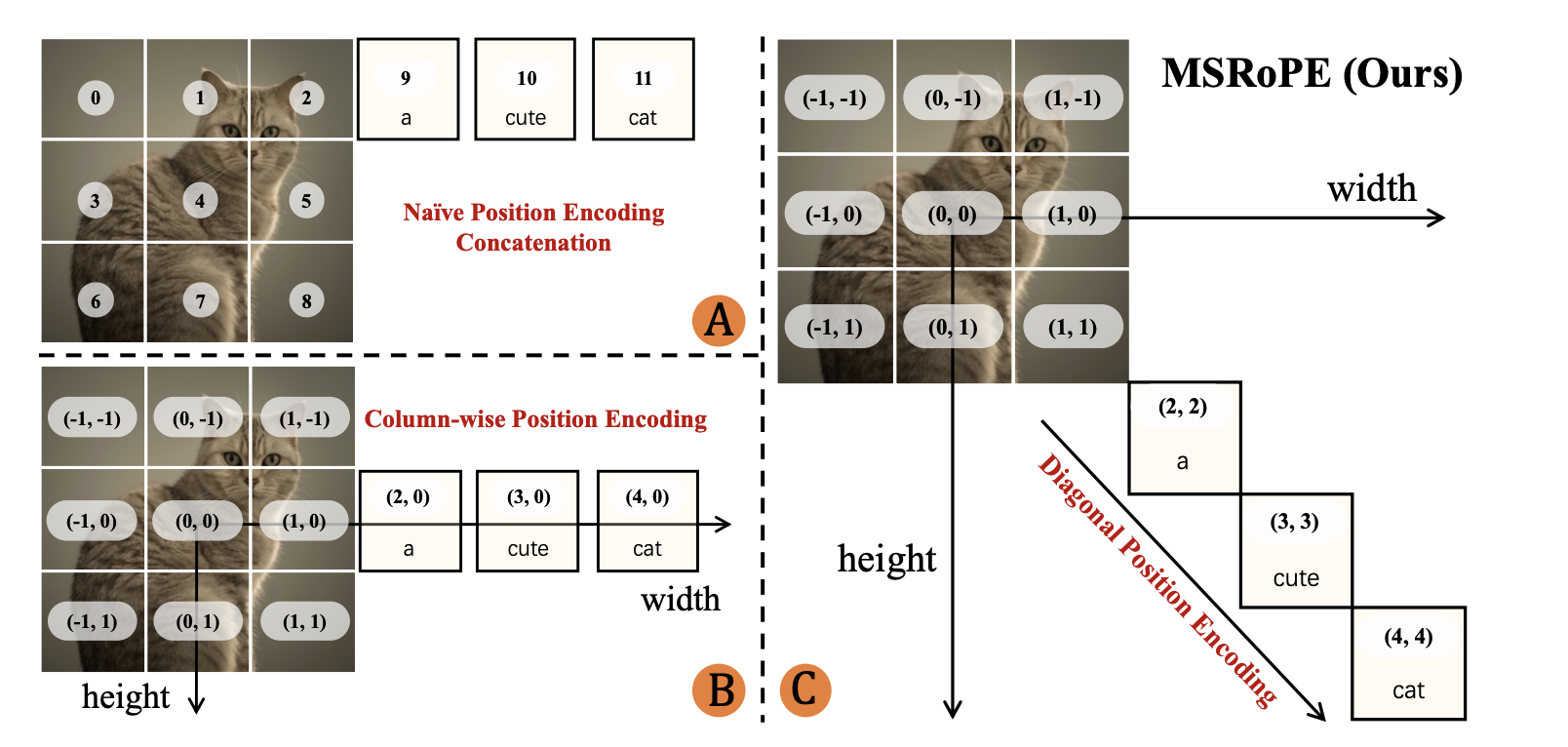
其中C是Qwen-Image真正的位置编码方案,虽然编码实现时有所区别,但也有一定的参考价值。可以看到,文本编码的位置是在图像的位置编码的对角线上。这种方法有其合理之处,直接上感觉能够更好地对齐视觉与文本特征。
简介中我有提到,位置编码有参考Flux,那么具体是怎么参考的呢?请看下图: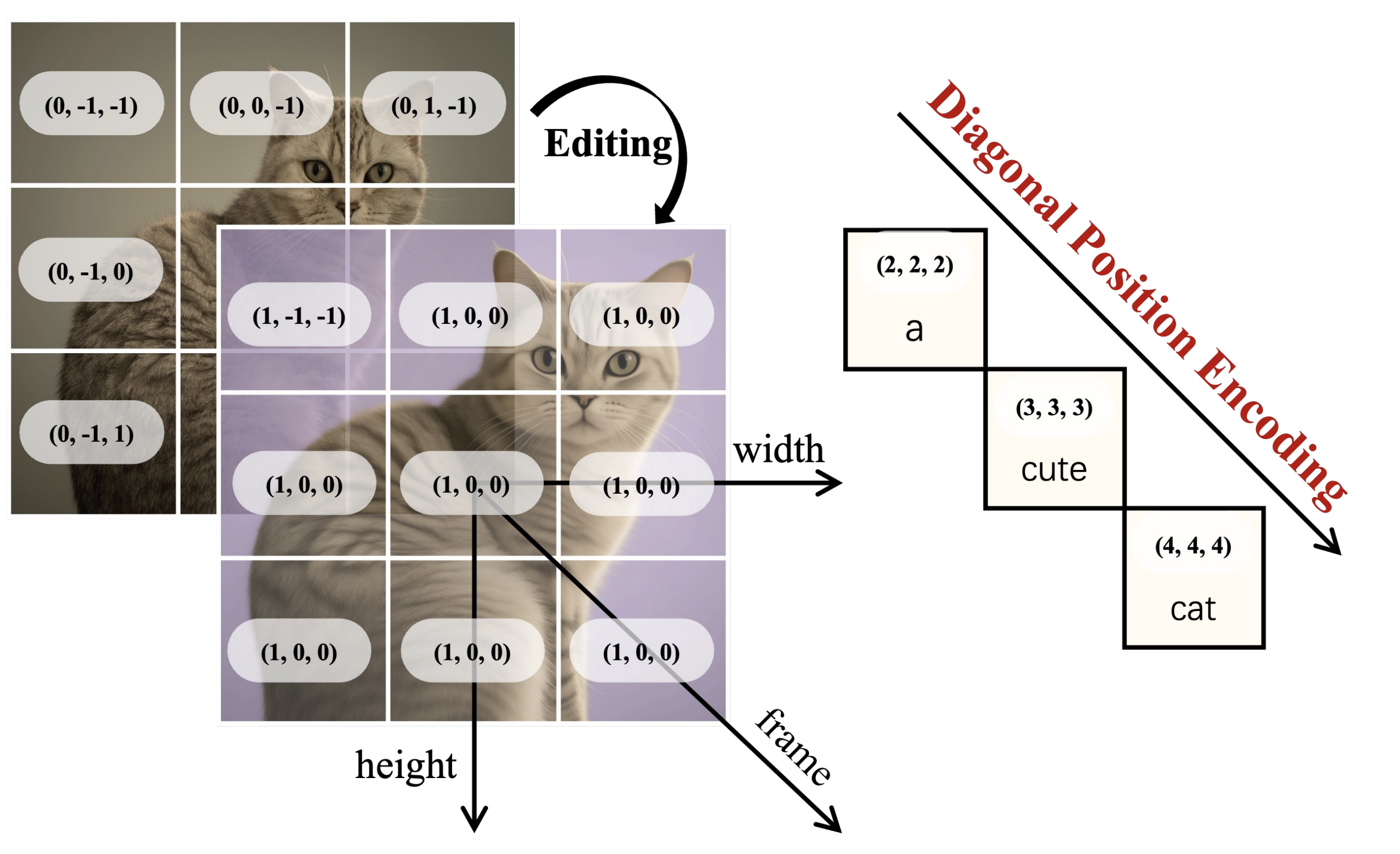
如图是Qwen Image真正的编码方案。与Flux类似,采用3D位置编码进行。其中每张图片占用单独的一个维度。文本则处于3D空间的对角线上。
这样一来,模型也能够支持多图片输入了,进一步能够支持更复杂的图片编辑任务。
总结
这两年图像生成任务做的越来越好,应该马上就能满足实际需求了,达到普通人难以分辨的程度。随着算力和显存的提升,模型越来越倾向于将所有输入直接token化,然后定制位置编码后直接整个送入transformer。后续视频生成任务估计也会有类似的发展趋势,本文中的VAE用Wan 2.1 估计就是为此铺路的。不过视频消耗的资源还是太多了,何况transformer的复杂度是n的平方,估计一两年内还是做不到像图像生成一样。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)