激荡三十年:推荐系统从协同过滤到大模型时代
引言:推荐无处不在
当你打开淘宝,首页的商品为什么恰好是你想要的?当你刷抖音,为什么总能看到让你停不下来的视频?当你登录youtube,那些“为你推荐”的电影为何如此精准?这背后,都是推荐系统在发挥作用。
推荐系统(Recommender System)是一类帮助用户从海量信息中发现感兴趣内容的智能算法。它的核心任务是预测用户对特定物品的偏好程度,并据此生成个性化推荐列表。从最初的邮件过滤,到今天无处不在的内容分发、商品推荐、社交匹配,推荐系统已经深度融入我们的数字生活,成为互联网产品不可或缺的基础设施。
推荐系统的重要性体现在多个维度。对用户而言,它解决了信息过载问题——在数以亿计的商品、视频、新闻中快速找到自己需要的那一个;对平台而言,它是用户留存和变现的核心引擎——亚马逊曾公开表示,其约40%的销售额来自推荐系统,而今日头条、抖音等产品更是将推荐算法作为核心竞争力。据Gartner统计,在主流电商平台上,推荐系统贡献的成交额占比普遍在30%-40%之间,在视频平台这一比例更高,YouTube有超过70%的观看时长来自推荐。
从技术演进的角度看,推荐系统走过了三十余年的发展历程,经历了几次关键的范式转移。1992年,Xerox PARC提出的Tapestry系统首次应用协同过滤算法,标志着推荐系统的诞生。此后的十余年间,协同过滤成为主流方法,GroupLens、MovieLens、亚马逊的Item-to-Item协同过滤等系统相继问世。2006年,Netflix Prize竞赛掀起了推荐算法研究的高潮,矩阵分解、集成学习等技术迅速发展,特征工程成为这一时期的关键词。2016年后,深度学习全面进入推荐系统,Wide & Deep、DeepFM、DIN等模型层出不穷,工业界形成了召回-粗排-精排-重排的标准架构,推荐系统进入成熟期。而2023年以来,大语言模型(LLM)的崛起再次改变了推荐系统的技术图景,生成式推荐、提示学习、检索增强生成等新范式正在涌现。
本文将以时间为轴,系统回顾推荐系统从诞生到今天的完整历程,重点关注每个阶段的核心技术突破、代表性系统案例以及技术演进的内在逻辑。我们将这段历史划分为四个阶段:
● 起源篇(1992-2005)讲述协同过滤的诞生与早期探索;
● 发展篇(2006-2015)聚焦Netflix Prize带来的方法论革新和特征工程时代;
● 成熟篇(2016-2022)剖析深度学习如何重塑推荐系统并推动工业应用的大规模落地;
● 未来篇(2023-至今)展望大模型时代推荐系统的新方向。
通过这段技术编年史,我们希望帮助读者建立完整的知识体系,理解技术演进背后的驱动力,并对未来趋势形成洞察。
(全文约2万字,阅读时间约40分钟)
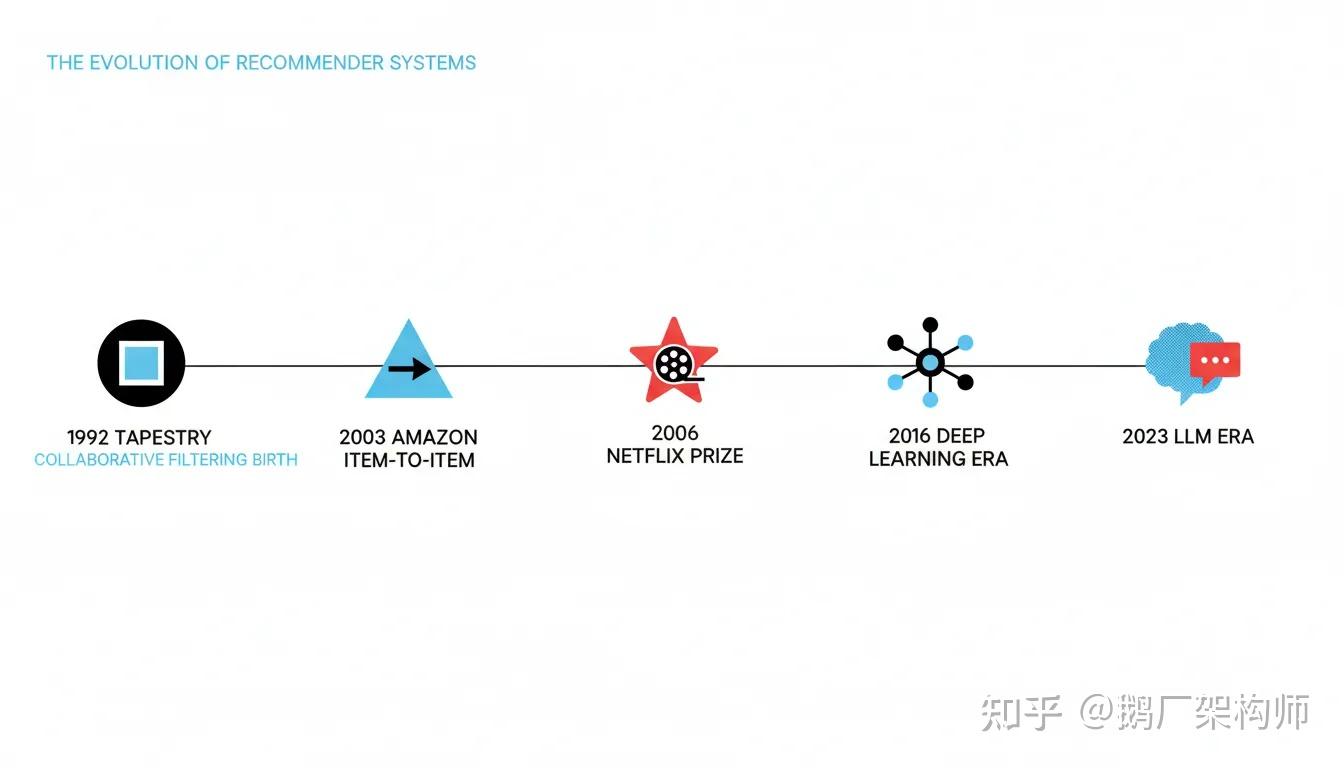
图1:推荐系统三十年演进时间线(1992-2024)
起源篇:协同过滤的黎明(1992-2005)
信息过载与推荐系统的诞生
1990年代初期,互联网正在经历一场静悄的革命。电子邮件、Usenet新闻组、网络论坛迅速普及,但随之而来的是信息过载问题。在Xerox公司的帕罗奥多研究中心(Xerox PARC)——这个诞生了图形用户界面、以太网等众多重要发明的地方——员工们每天收到数百封电子邮件和大量的Usenet消息,无法有效筛选和分类。
这促使研究人员开发实验性系统。他们意识到,仅靠关键词匹配或主题分类并不能有效解决问题——不同用户对同一主题的内容有着差异化的需求,而且内容质量往往难以通过简单的文本匹配来判断。一个关键洞察是:人类的评价和偏好是最可靠的过滤信号。如果能捕捉用户之间的相似性,利用“与你相似的人喜欢什么,你也可能喜欢什么”这一逻辑,就能实现个性化的信息过滤。
Tapestry:协同过滤的首次实践
1992年9月,Xerox PARC的David Goldberg、David Nichols、Brian Oki和Douglas Terry发表了具有里程碑意义的论文《Using Collaborative Filtering to Weave an Information Tapestry》,正式提出了“协同过滤”(Collaborative Filtering)这一概念。论文介绍的Tapestry系统主要用于处理电子邮件、新闻故事和NetNews文章的过滤。
Tapestry的核心思想是让人类参与到过滤过程中。用户可以对文档进行注释(annotation),表明自己认为这篇文章是否有价值。这些注释不仅包括显式的评论,还包括隐式的行为反馈——例如回复一封邮件就表明这封邮件可能很重要。其他用户可以利用这些注释来过滤自己的信息流。例如,用户可以定义这样的过滤器:“显示所有Bob认为有趣或者Alice回复过的邮件”。
Tapestry系统实现了几个重要的创新:
● 协同过滤的概念:首次明确提出利用用户间的协作来帮助彼此进行信息过滤
● 显式与隐式反馈:系统同时支持用户主动的注释和自然产生的行为数据
● 连续查询语义:Tapestry实现了一种新的查询语义,能够在新数据到达时自动重新执行查询,确保过滤结果的实时性
Tapestry的局限性在于它主要针对单一组织内部的小规模场景,且需要用户编写查询表达式,技术门槛较高。但它的意义在于首次在实际系统中证明了协同过滤的可行性,为后续研究指明了方向。
GroupLens:自动化的协同过滤
1994年,明尼苏达大学双城分校计算机系的GroupLens研究组发表了论文《GroupLens: An Open Architecture for Collaborative Filtering of Netnews》,介绍了他们开发的新闻推荐系统GroupLens。这一系统在Tapestry的基础上实现了几个关键突破。
自动化的协同过滤:GroupLens的最大创新是实现了自动化的推荐。用户只需要对新闻文章给出1-5星的评分,系统就能自动计算用户间的相似度,并预测用户对未读文章的评分。这种自动化的方式使得系统可以扩展到更大的用户群体。
算法原理:GroupLens采用了基于用户的协同过滤(User-Based Collaborative Filtering)算法。其核心思想可以用一个简单的公式表示。对于用户u对物品i的评分预测:
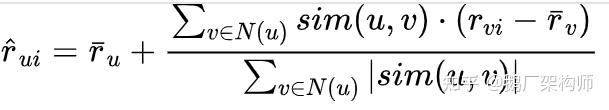
其中,
是与u相似的用户集合,
是用户u和v的相似度(通常使用余弦相似度或皮尔逊相关系数),
是用户u的平均评分。
跨网络的分布式架构:与Tapestry不同,GroupLens被设计成一个分布式的、跨网络的系统。它采用客户端-服务器架构,多个新闻阅读器可以连接到同一个GroupLens服务器,分享评分数据。这种设计使得系统可以服务于更广泛的用户群体。
GroupLens项目的成功证明了协同过滤可以在大规模、开放网络环境中应用。后续基于GroupLens技术诞生了MovieLens电影推荐系统,该系统至今仍在运行,并为推荐系统研究提供了广泛使用的公开数据集。
图2:协同过滤概念图解——用户通过相似的评分历史相互连接,系统可以预测用户对未知物品的偏好
亚马逊的工业化突破
如果Tapestry和GroupLens证明了协同过滤的可行性,那么亚马逊则将其推向了工业化应用的高峰。2003年,亚马逊的Greg Linden、Brent Smith和Jeremy York在IEEE Internet Computing上发表了著名的论文《http://Amazon.com Recommendations: Item-to-Item Collaborative Filtering》。这篇论文介绍的Item-to-Item协同过滤算法成为电子商务推荐系统的里程碑。
从用户到物品的范式转变:传统User-Based协同过滤需要在线时计算用户间的相似度,在用户数量庞大时计算复杂度极高。亚马逊的关键创新是转而计算物品间的相似度。对于亚马逊这样的电商平台,商品数量虽然庞大但相对稳定,而用户数量则增长迅速。通过计算物品相似度,可以将最耗时的计算移到离线进行。
算法流程:
● 离线阶段:遍历所有物品对,根据购买/评分过同一商品的用户集合来计算物品相似度。对于每个物品i,生成一个相似物品表。
● 在线阶段:当用户u访问时,查找用户历史购买/评分的所有物品,利用预计算的相似物品表快速生成推荐列表。
这种设计使得在线计算复杂度仅与用户的历史行为数量有关,而与用户总数、商品总数无关,实现了真正的工业级可扩展性。
业务影响:亚马逊在论文中指出,Item-to-Item协同过滤能够在毫秒级别生成推荐结果,并且推荐质量优秀。亚马逊公开声称,其约40%的销售额来自推荐系统。这一数字让整个电商行业意识到推荐系统的商业价值,也推动了推荐系统的广泛应用。
对后续影响:Item-to-Item的思想影响深远。它启发研究者们思考如何将最耗时的计算移到离线,这一思路成为后续工业推荐系统架构设计的基本原则。此外,“购买了这个商品的用户还购买了…”这种推荐形式成为电商平台的标配。
基于内容的推荐与混合方法
在协同过滤快速发展的同时,另一条技术路线——基于内容的推荐(Content-Based Filtering)——也在平行推进。这类方法通过分析物品的属性和用户的历史偏好,推荐与用户过往喜好相似的物品。
例如,在新闻推荐中,可以提取文章的关键词、主题、作者等特征,并根据用户过往阅读的文章构建用户兴趣模型。在音乐推荐中,可以基于歌曲的风格、歌手、旋律特征等进行匹配。
优势:
● 解决冷启动问题:对于新物品,只要有内容描述就能进行推荐
● 可解释性强:可以明确解释为什么推荐某个物品
局限:
● 过度专业化:只能推荐与用户历史相似的物品,缺乏惊喜和新颖性
● 特征工程复杂:需要针对不同领域设计不同的特征提取方法
有鉴于此,混合推荐系统(Hybrid Recommender Systems)逐渐成为主流。它们结合协同过滤和基于内容的方法,取长补短。常见的混合策略包括加权组合、级联和特征组合。
这一时期的遗产与挑战
尽管取得了这些进展,早期的推荐系统仍面临许多挑战:
● 数据稀疏性:大规模系统中的评分矩阵极其稀疏(通常低于1%的密度)
● 冷启动问题:新用户和新物品缺乏历史数据
● 可扩展性:User-Based协同过滤的计算复杂度为O(MN)
● 商业化探索:如何平衡推荐精准度与商业目标
尽管存在诸多挑战,这一时期奠定了推荐系统的理论基础和基本范式。协同过滤的核心思想——利用群体智慧进行个性化推荐——成为后续所有方法的基础。亚马逊的成功也让整个互联网行业看到了推荐系统的商业价值,为后续的爆发式增长铺平了道路。
发展篇:Netflix Prize与特征工程时代(2006-2015)
Netflix Prize:改变游戏规则的竞赛
2006年10月2日,Netflix宣布启动一项全球性竞赛,奖金高达100万美元。竞赛的目标很简单:将Netflix自身的Cinematch推荐算法的预测准确性提高10%以上。这一看似不起眼的数字,却吸引了全球超过48,000支团队参与,来自182个国家。
Netflix提供的训练数据集包含100,480,507个评分,来自480,189个用户对17,770部电影。每个评分是1-5星的整数。竞赛以RMSE(Root Mean Squared Error)作为评价指标,Cinematch的基准RMSE为0.9525,而获奖线是0.8572。
竞赛进程:在近三年的时间里,数百支团队展开了激烈的竞争。前期领先的团队包括BellKor、BigChaos、Pragmatic Theory等。2009年6月26日,由这三个团队合并而成的“BellKor’s Pragmatic Chaos”达到了10.05%的提升,触发了最终30天的“最后通报”期。在这个紧张的月份里,另一支团队“The Ensemble”也达到了10.09%的提升。最终,由于提交时间早了20分钟,BellKor团队获得了大奖。
技术突破:Netflix Prize的真正价值不在于奖金,而在于它激发的技术创新。赢奖方案结合了超过100个不同的预测器,包括矩阵分解、近邻域模型、时间动态模型以及梯度提升决策树(GBDT)混合算法。最终测试集RMSE为0.8567,较Cinematch提升10.06%。
矩阵分解:推荐系统的黄金标准
Netflix Prize期间,矩阵分解(Matrix Factorization)技术迅速成为推荐系统的核心技术。2009年,Yehuda Koren、Robert Bell和Chris Volinsky在IEEE Computer上发表了著名的综述论文《Matrix Factorization Techniques for Recommender Systems》,系统地介绍了该技术。
基本思想:矩阵分解将用户-物品评分矩阵R分解为两个低维矩阵的积:
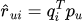
其中
代表物品i在隐藏因子空间中的向量,
代表用户u的偏好向量。该模型通过最小化正则化平方误差来学习参数:
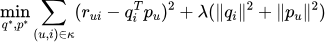
偏置项模型:为了提高准确性,研究者们进一步引入了偏置项(biases)来抓住用户和物品的系统偏好:
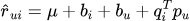
其中
是全局平均评分,
和
分别为物品和用户的偏置。这一设计能够捕捉"这部电影普遍受欢迎"或"这个用户总是给高分"等系统性趣味。
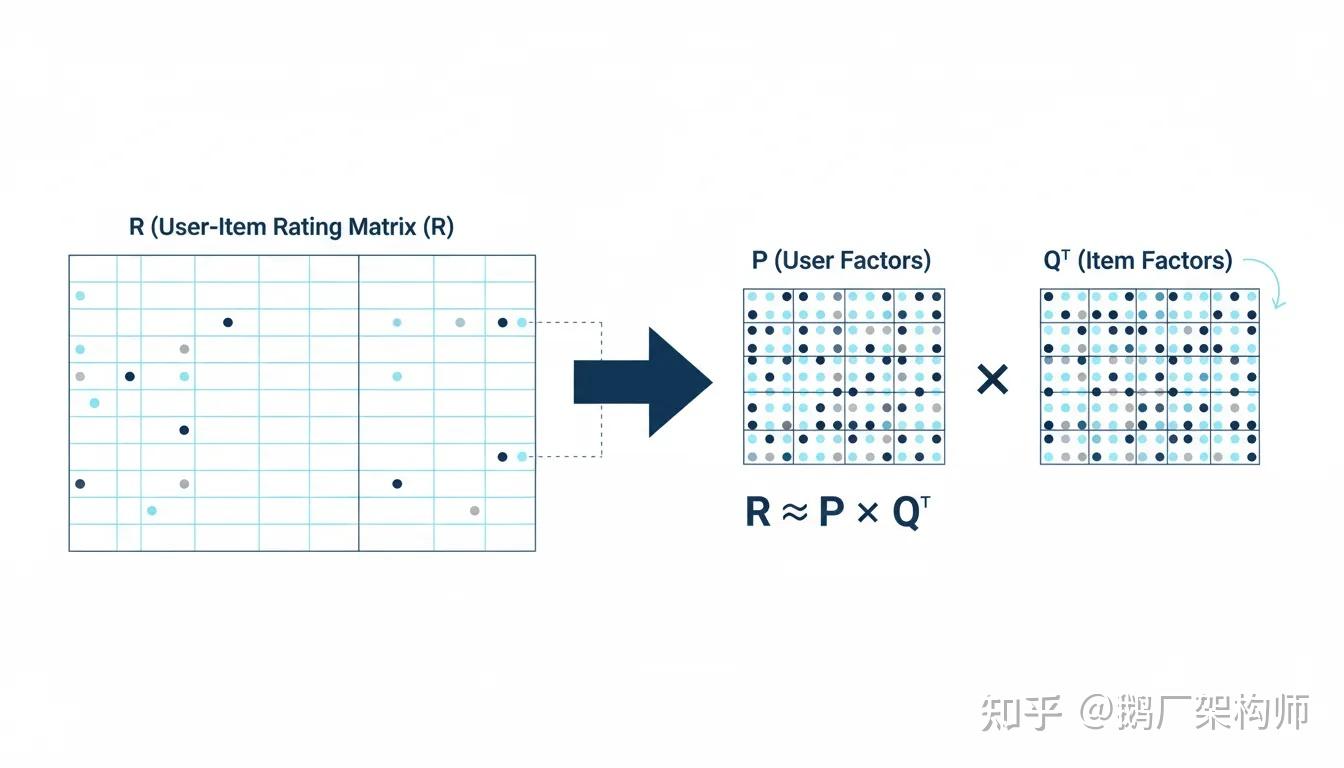
图3:矩阵分解可视化——将稀疏的用户-物品评分矩阵分解为两个稠密的低维矩阵
优势:
● 处理稀疏数据:通过隐藏因子建模,能够在极其稀疏的评分矩阵上进行预测
● 可扩展性:训练过程可以高效并行化
● 灵活性:易于引入各种额外信息(如时间动态、隐式反馈等)
矩阵分解技术在Netflix Prize后成为推荐系统的黄金标准,广泛应用于各种推荐场景。
隐式反馈处理
在实际应用中,显式评分(如电影星级评分)通常稀疏,而隐式反馈(如浏览、购买、收藏等行为)则更为丰富。2008年,Yifan Hu、Yehuda Koren和Chris Volinsky发表了论文《Collaborative Filtering for Implicit Feedback Datasets》,为隐式反馈的处理提供了重要理论基础。
隐式反馈的特点:
● 没有负反馈:用户没有点击不代表不喜欢,可能是没有看到
● 本质是噪声的:一次点击可能是误操作或好奇
● 数值代表置信度:重复行为更可靠(如多次购买、长时观看)
模型设计:论文将每个观测分为偏好
(0或1)和置信度
两部分。例如,对于观看时长,可以设定:
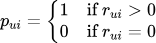
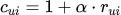
这种建模方式使得系统能够更好地处理大规模的隐式反馈数据,在工业界得到了广泛应用。
GBDT+LR:特征工程的黄金时代
2014年,Facebook提出的GBDT+LR模型成为点击率预测(CTR)的标准方法,标志着特征工程时代的到来。
核心思想:结合GBDT的特征转换能力和LR的高效训练。GBDT自动挖掘特征交互,将这些交叉特征作为LR的输入,提高模型表达能力。
工作流程:
- GBDT训练:在原始特征上训练GBDT模型
- 特征转换:将每个样本经过GBDT后落入的叶子节点编码为one-hot向量
- LR训练:在转换后的特征上训练逻辑回归模型
- 在线预测:结合GBDT特征和LR预测进行最终输出
这一时期,特征工程成为推荐系统成功的关键。工程师们花费大量时间构造各种特征:用户特征、物品特征、交叉特征、统计特征等。特征质量直接决定了模型效果。
工业界的大规模实践
这一时期,各大互联网公司开始大规模应用推荐系统:
YouTube:2008年开始建立视频推荐系统。早期主要基于视频元数据和观看历史,后期采用协同过滤和内容推荐相结合的方法。
淘宝与京东:中国电商巨头在2008年开始大力发展个性化推荐。淘宝基于用户的浏览、收藏、购买行为,通过协同过滤和内容推荐相结合的方法推荐商品。
社交网络:Facebook在好友推荐、内容分发上广泛应用推荐算法。LinkedIn重点关注职业网络推荐,利用用户的职业经历、技能标签等信息推荐联系人。
技术平台转变:从单机计算到分布式计算框架(Hadoop、Spark),再到专门的机器学习库(Mahout),为大规模推荐系统的实现提供了可能。
这一时期的总结
2006-2015年是推荐系统的黄金十年。Netflix Prize将推荐系统推向了学术和工业界的前沿,矩阵分解、隐式反馈、特征工程等技术成为业界标准。这一时期的成果为后续深度学习时代奠定了坚实基础——许多核心思想(如Embedding、特征交互、多目标优化)在深度学习模型中得到了延续和发展。
同时,这一时期也暴露了传统方法的局限:手工特征工程费时费力、模型表达能力有限、难以处理高维稀疏数据等。这些问题呼唤着新的技术范式,而答案即将在深度学习时代揭晓。
成熟篇:深度学习的全面统治(2016-2022)
Wide & Deep:深度学习的破冰
2016年,Google发表的Wide & Deep Learning模型标志着深度学习正式进入推荐系统领域。这篇发表在RecSys 2016的论文《Wide & Deep Learning for Recommender Systems》成为深度学习推荐的开山之作。
核心思想:结合Wide线性模型的“记忆能力”(memorization)和Deep神经网络的“泛化能力”(generalization)。
模型结构:
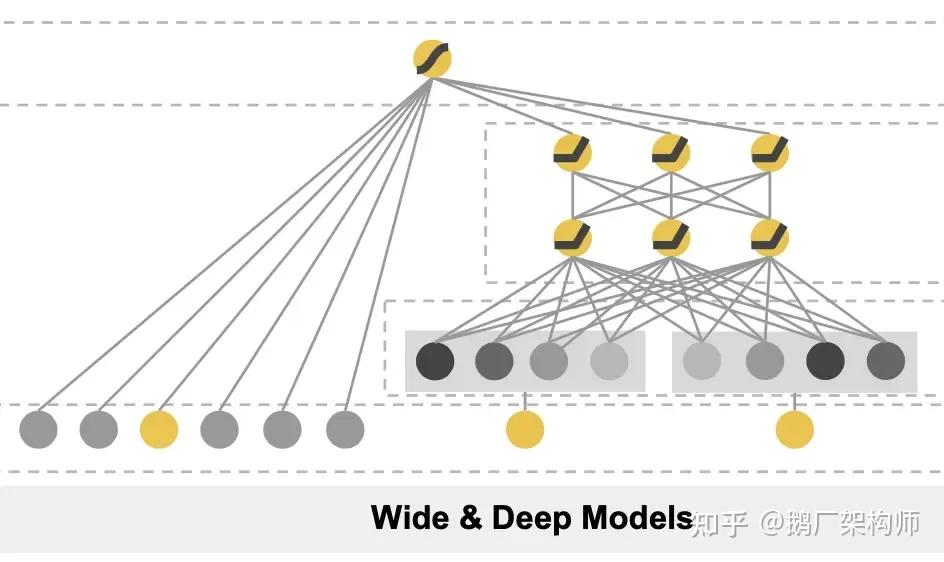
图4:wide&&Deep模型结构示意
● Wide部分:线性模型,接收原始特征和交叉特征,能够快速学习并记忆历史规则
● Deep部分:多层神经网络,对稀疏特征进行Embedding后学习复杂的特征组合
● 联合训练:两部分同时训练,最终结合输出
优势:
● 自动学习特征交互,减少人工特征工程
● 兼顾精准匹配和泛化能力
● 在Google Play应用推荐上取得显著效果提升
Wide & Deep的成功让业界看到了深度学习在推荐系统中的潜力,此后各种深度学习模型层出不穷。
DeepFM:终结FM与深度网络
2017年,华为和哈尔滨工业大学联合提出的DeepFM模型进一步简化了模型架构。与Wide & Deep需要人工设计Wide部分的交叉特征不同,DeepFM实现了端到端的学习。
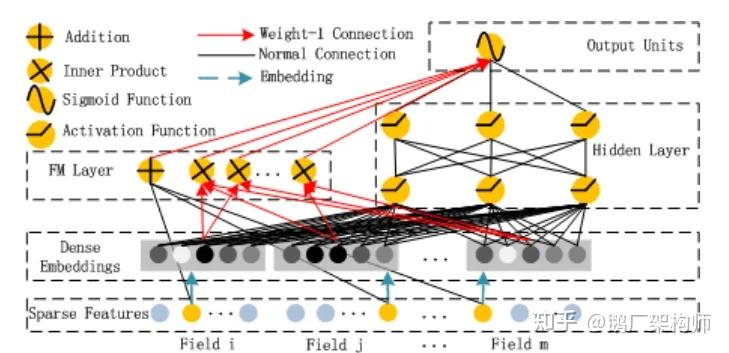
图5:DeepFM模型结构示意
核心创新:
● FM部分:因子分解机(Factorization Machine)自动学习二阶特征交互
● Deep部分:深度网络学习高阶特征交互
● 共享Embedding:两部分共享同一套Embedding层,减少参数量
数学表达:
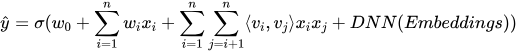
DIN:注意力机制的引入
2018年,阿里巴巴提出的Deep Interest Network(DIN)引入了注意力机制,成为推荐系统领域的重要创新。
问题背景:传统方法将用户历史行为简单聚合(pooling)为固定长度的向量,但实际上用户对不同历史行为的兴趣强度不同。例如,用户在查看一个电子产品时,历史上购买的手机比购买的食品更相关。
核心思想:利用注意力机制(Attention),根据当前候选物品动态计算用户各个历史行为的权重,实现个性化的用户表示。
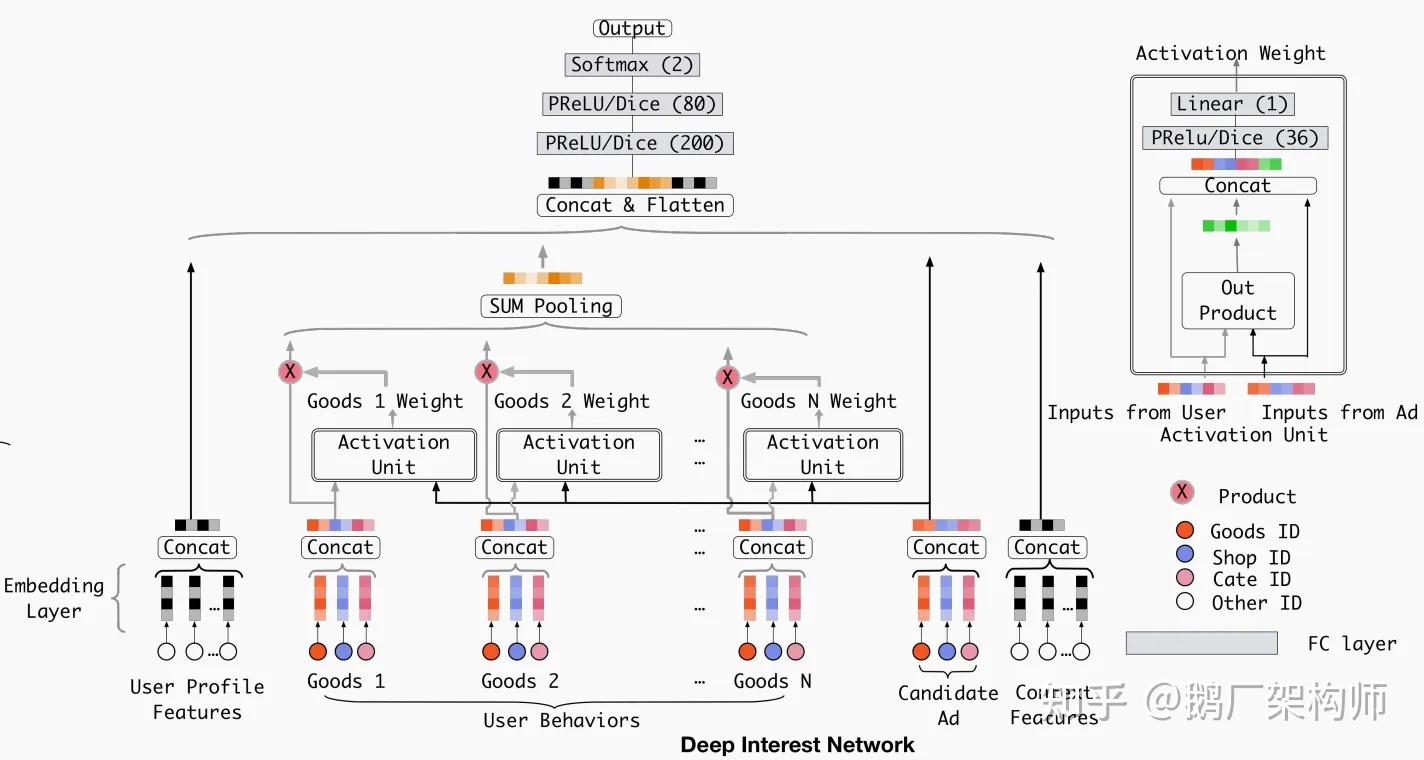
图6:DIN模型结构示意
注意力计算:
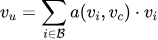
其中
是候选物品的Embedding,
是用户历史行为集合,
是注意力函数,计算各历史行为与当前候选的相关性。
DIN在阿里巴巴的显示广告系统上取得了显著效果,CTR提升超过10%。此后,注意力机制成为推荐系统的标配技术。
YouTube推荐系统的深度学习升级
2016年,Google发表的论文《Deep Neural Networks for YouTube Recommendations》详细介绍了YouTube如何将深度学习应用于视频推荐。这篇论文成为工业界推荐系统设计的经典参考。
两阶段架构:
● 召回阶段(Candidate Generation):从百万级视频库中快速筛选出数百个候选视频。使用深度协同过滤模型,将用户和视频映射到同一个Embedding空间,通过相似度搜索找到相关视频。
● 排序阶段(Ranking):对候选视频进行精细排序。使用更复杂的深度神经网络,融合更多特征(如视频详情、用户上下文等),预测用户对每个视频的点击概率和观看时长。
工程挑战:
● 极大规模:处理数亿用户和百万视频
● 新鲜度:每分钟上传数百小时视频,系统需快速适应
● 噪声:用户行为数据充满噪声,需要精心建模
效果:YouTube声称,超过70%的观看时长来自推荐系统。这一系统的成功让整个视频行业看到了推荐算法的巨大价值。
工业界的标准架构:召回-粗排-精排-重排
在深度学习时代,工业界逐渐形成了一套标准的多阶段推荐架构。这一架构平衡了精准度、效率和业务目标。
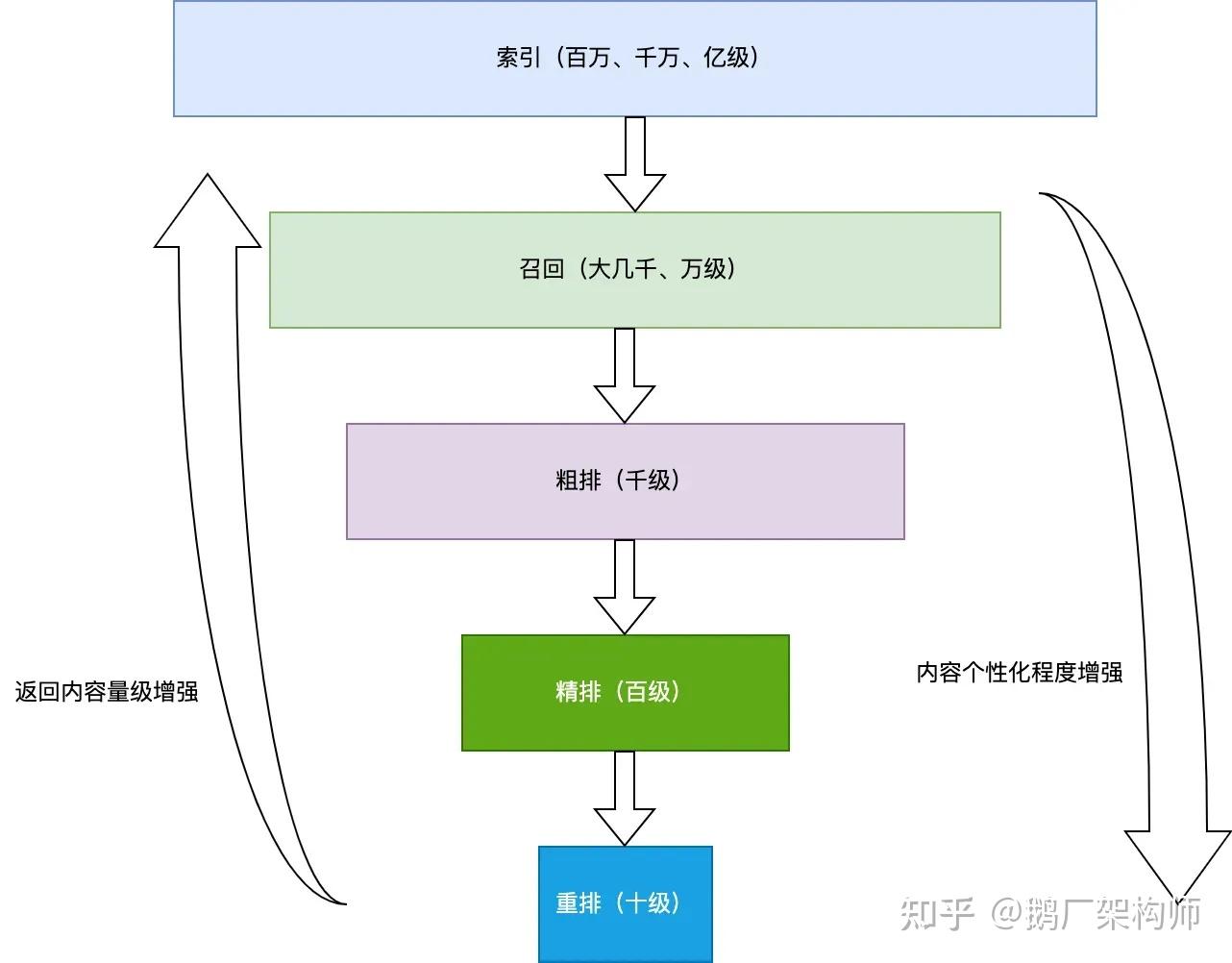
图7:推荐系统多阶段架构——从亿级候选逐步筛选到数十个最终推荐
召回阶段(Retrieval):
● 目标:从亿级全量物品库中快速筛选出数千到数万个候选
● 方法:多路召回策略,包括协同过滤、热门推荐、个性化推荐、内容匹配等
● 效率要求:毫秒级响应,通常使用简单高效的算法
粗排阶段(Coarse Ranking):
● 目标:从数千候选中筛选出数百个
● 方法:使用轻量级模型(如三层DNN)进行初步打分
● 特点:模型相对简单,但比召回阶段更精细
精排阶段(Ranking):
● 目标:从数百候选中选出数十个最优结果
● 方法:使用复杂的深度模型(如Wide & Deep、DeepFM、DIN)进行精细排序
● 特点:融合大量特征,多目标优化(CTR、CVR、时长等)
重排阶段(Re-ranking):
● 目标:基于业务规则和多样性需求调整最终顺序
● 方法:引入业务规则(如类目打散、新鲜度控制)、多样性优化(DPP、MMR)等
● 目的:提升用户体验,平衡精准度与多样性
这一架构已成为工业界的事实标准,被广泛应用于电商、视频、新闻、社交等各种推荐场景。
图神经网络的尝试
近年来,图神经网络(Graph Neural Networks, GNN)在推荐系统中也受到关注。用户-物品交互天然形成了一个二部图,GNN能够利用图结构信息提升推荐效果。
代表性工作:
● PinSage(Pinterest, 2018):基于GraphSAGE的大规模GNN推荐系统
● LightGCN(2020):简化的图卷积网络,去除了特征转换和非线性激活
● NGCF(2019):神经图协同过滤,在图上传播嵌入信息
GNN能够捕捉复杂的高阶连接模式,但在大规模工业应用中仍面临计算效率和可扩展性的挑战。
中国互联网的实践
这一时期,中国互联网公司在推荐系统领域取得了世界级的成就:
字节跳动:今日头条和抖音将推荐算法作为产品核心。其推荐系统融合了协同过滤、内容理解、实时特征等多种技术,实现了极高的用户粘性。
阿里巴巴:在电商推荐、广告系统上持续创新,提出DIN、DIEN等多个影响力论文。淘宝的推荐系统处理亿级商品和数亿用户,在双11等大促期间稳定运行。
腾讯:在社交、视频、新闻等多个场景应用推荐算法。微信看一看、腾讯新闻的推荐系统服务于数亿用户。
快手与小红书:分别在短视频和生活方式分享领域取得成功,其推荐算法融合了内容理解、社交关系、用户画像等多个维度。
这一时期的总结
2016-2022年是深度学习在推荐系统中全面统治的时期。从特征工程到特征学习,从DNN到Attention,从单模型到多阶段架构,深度学习带来了性能的飞跃。工业界形成了成熟的方法论和工程体系,推荐系统真正成为互联网产品的基础设施。
然而,这一时期的技术范式也面临着新的挑战:模型越来越复杂但性能提升逐渐边际递减、冷启动问题依然存在、可解释性不足、对长尾内容支持不够等。而大语言模型的崛起,即将为这些问题带来新的解决思路。
未来篇:大模型时代的范式转移(2023-至今)
大语言模型的崛起
2022年末,ChatGPT的发布标志着大语言模型(LLM)时代的全面到来。LLM强大的语言理解、生成和推理能力,为推荐系统带来了新的可能性。一个重要的转变是:推荐不再只是从固定候选集中排序,而是能够理解用户意图并生成个性化内容。
LLM的优势:
● 强大的语义理解:能够理解用户查询和物品描述的深层含义
● 零样本泛化:在没有历史数据的情况下也能进行推荐
● 可解释性:能够生成自然语言的推荐理由
● 多模态融合:能够处理文本、图片、视频等多种模态
生成式推荐的新范式
传统推荐系统是“判别式”(discriminative)的——从固定的候选集中选择最佳项。而LLM带来了“生成式”(generative)的新范式。
代表性工作:
● GenRec(2023):第一个系统地将推荐任务定义为生成问题,直接生成物品ID或标签
● P4R(2024):通过提示学习(prompt learning)将推荐任务转化为语言生成
● Text-to-Rec:将用户查询直接转化为推荐结果
优势与挑战:
● 优势:更灵活的交互方式、更好的冷启动处理、能够生成解释
● 挑战:如何融入用户行为信号、如何保证实时性、如何控制计算成本
提示学习与检索增强生成
提示学习在推荐中的应用:通过精心设计的提示(prompt),可以将推荐任务转化为语言生成任务。例如:
用户:一个25岁的程序员,喜欢科幻电影和游戏 历史:最近观看了《流浪地球》、《三体》 任务:为该用户推荐三部电影,并解释理由。
检索增强生成(RAG):RAG将LLM与传统检索系统结合,成为推荐系统的新范式。流程是:
● 检索:根据用户查询检索相关物品
● 增强:将检索到的物品信息作为上下文输入LLM
● 生成:LLM生成个性化的推荐列表和解释
2025年提出的ARAG(代理式RAG)进一步引入了自主代理(agent)机制,能够自主决定检索策略和排序方式。
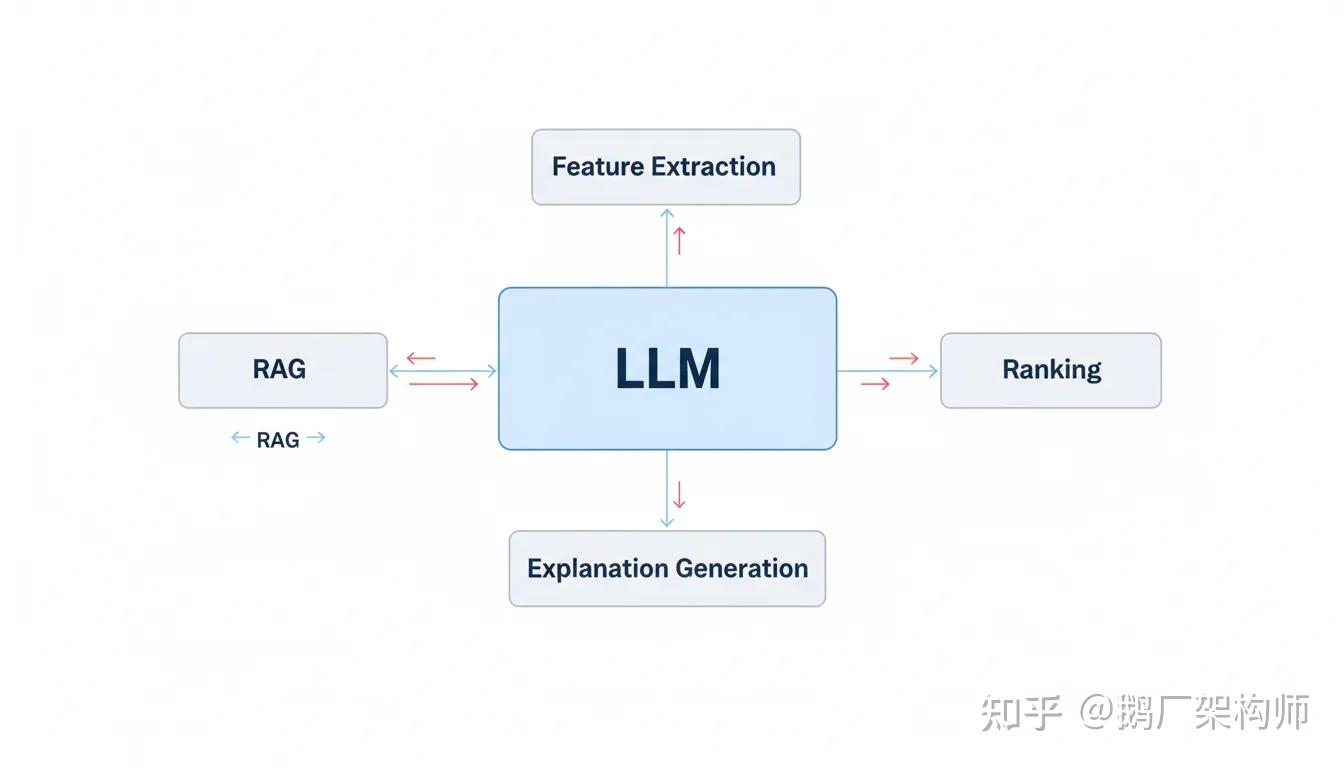
图8:LLM与传统推荐系统的融合架构——LLM作为中心组件连接特征提取、排序、解释生成等模块
LLM赋能推荐系统的多种方式
根据2024年的综述论文,LLM能够以多种方式赋能推荐系统:
-
作为特征提取器:LLM可以提取物品和用户的语义特征,输入传统推荐模型。例如,对于电影推荐,LLM可以理解剧情、主题、情感色彩等高层次信息。
-
作为排序模型:直接使用LLM对候选物品进行排序。通过精心设计的提示,LLM可以理解用户偏好并比较不同物品的适配度。
-
作为分析和解释器:LLM可以为推荐结果生成自然语言的解释,提高可解释性和用户信任度。例如:“推荐这部电影是因为它与你最近喜欢的科幻类型相符,且有类似的导演风格。”
-
作为对话式推荐接口:LLM能够实现更自然的对话式推荐交互。用户可以用自然语言表达需求,系统通过多轮对话精准把握用户意图。
-
作为代理协调器:LLM可以作为智能代理,协调多个推荐模块(如协同过滤、内容推荐、知识图谱),根据情境动态选择最优策略。
工业界的最新实践:从概念到落地
2024年,多家国内外互联网巨头纷纷将生成式推荐从实验室带到生产环境,取得了显著的业务成果。这些实践为行业提供了宝贵的经验和参考。
Meta的HSTU:万亿参数级生成式推荐器
2024年5月,Meta AI发表了一篇里程碑式的论文《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》,提出了\分层序列转导单元(Hierarchical Sequential Transduction Units, HSTU)\架构。
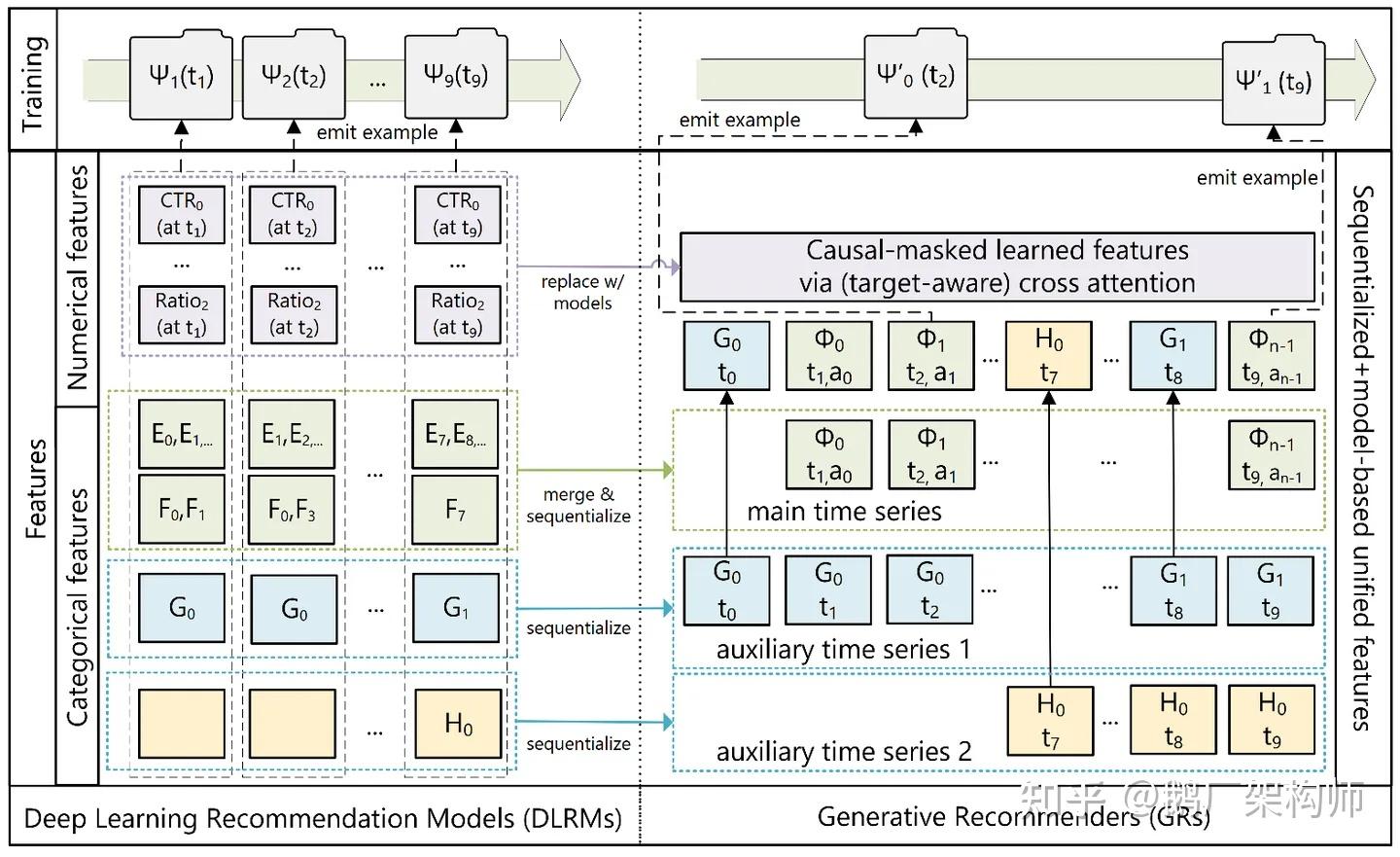
图9:meta 生成式推荐示意
核心创新:
● 序列转导范式:将推荐问题重新定义为序列转导任务,类似于大语言模型处理语言。将用户的点击、购买、滚动等行为视为一种“语言”来理解和预测
● 超大规模:模型参数量达到1.5万亿,与主流LLM相当
● 高效架构:HSTU比FlashAttention2基于的Transformer快5.3-15.2倍,特别适合长序列处理
业务效果:
● 在Meta平台的在线A/B测试中实现12.4%的改进
● 在公开数据集上NDCG指标提升高达65.8%
● 已在Facebook和Instagram的多个推荐场景中全面部署
这一突破被认为是推荐系统领域的“ChatGPT时刻”,展示了生成式模型在大规模推荐中的巨大潜力。
快手One-Rec:端到端生成式推荐
同样在2024年,快手推出了One-Rec系统,实现了从传统多阶段架构到统一生成模型的全面转型。
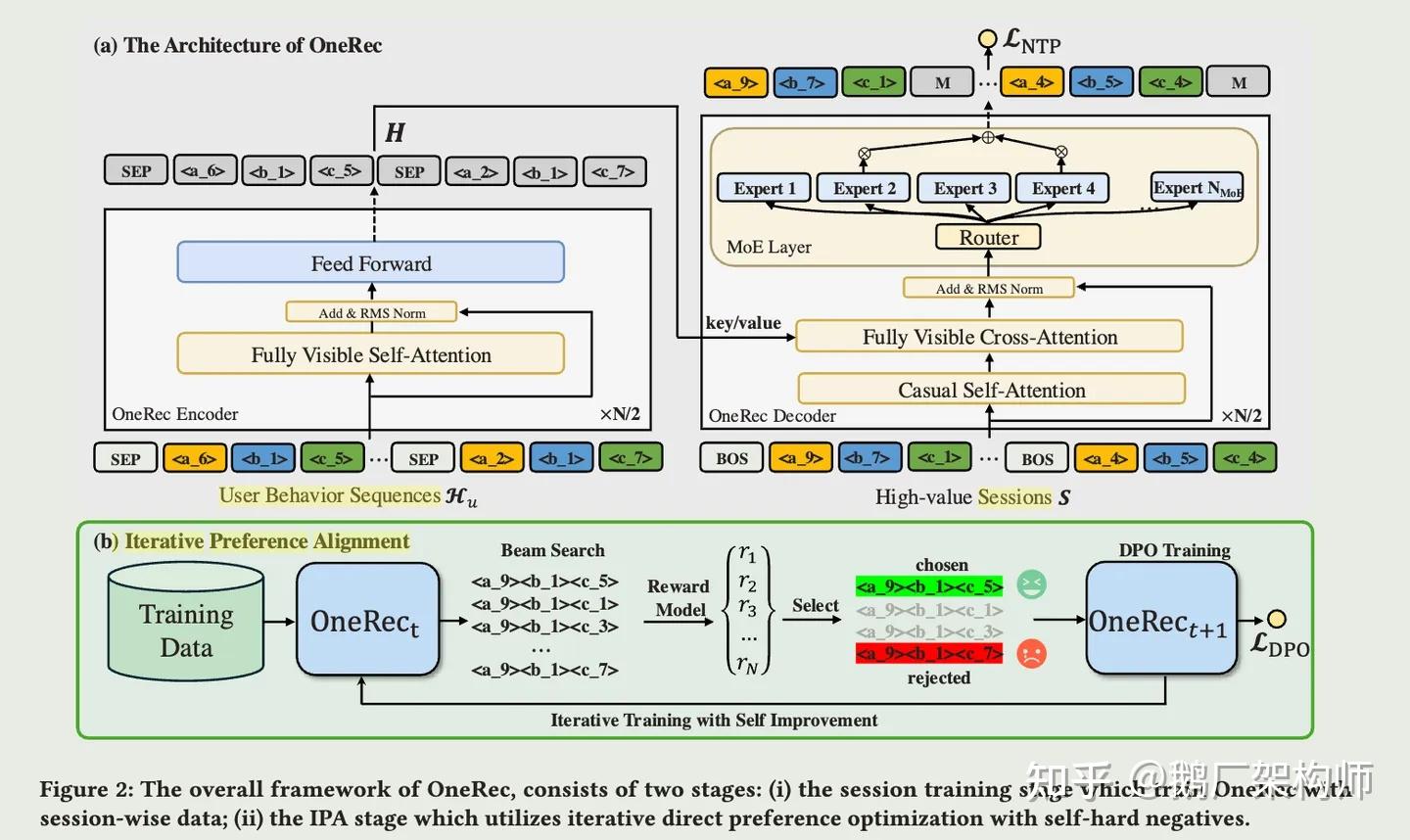
图10: one-rec架构示意
技术特点:
● Encoder-Decoder架构:编码器理解用户历史行为序列,解码器自回归地生成一个会话内的推荐内容
● 稀疏混合专家(MoE):在不显著增加计算量的前提下扩展模型容量,更好地建模用户多元兴趣
● 会话级生成:一次性生成整个推荐列表,比逐个生成更能捕捉上下文信息
● 迭代式偏好对齐:结合DPO直接偏好优化和强化学习,使推荐更符合用户真实偏好
业务成果:
● 总观看时长提升1.68%,平均观看时长提升6.56%
● 目前承接快手约25%的QPS(每秒请求量)
● 运营成本仅为传统方案的10.6%,节约近90%
● 算力利用率(MFU)训练达23.7%,推理达28.8%,远高于传统模型
One-Rec的成功证明了端到端生成式推荐在短视频场景的可行性,为行业提供了重要的工程化参考。
阿里巴巴:电商搜推广的AI化升级
阿里巴巴通过“大模型+传统模型”的混合架构,系统性地升级其庞大的电商搜推广体系。
关键实践:
● LMA广告专属大模型:阿里妈妈研发的广告领域专属大模型,迭代分支涵盖认知、推理和决策,全面改造了召回、排序、创意等核心模块
● URM通用召回大模型:整合LLM与电商知识,专注提升推荐系统的召回能力
● 商品库重构:利用AI Agent理解20亿商品的属性与关系,重构数据结构
● 多模态能力:在用户端推出“万能搜”、多模态拍照搜索等功能
业务提升:
● 复杂搜索词的相关性提升约20个百分点
● 推荐点击率提升10%
● 广告投资回报率(ROI)显著改善
字节跳动:分层大语言模型HLLM
字节跳动提出的\分层大语言模型(Hierarchical Large Language Model, HLLM)\专注于序列推荐场景。
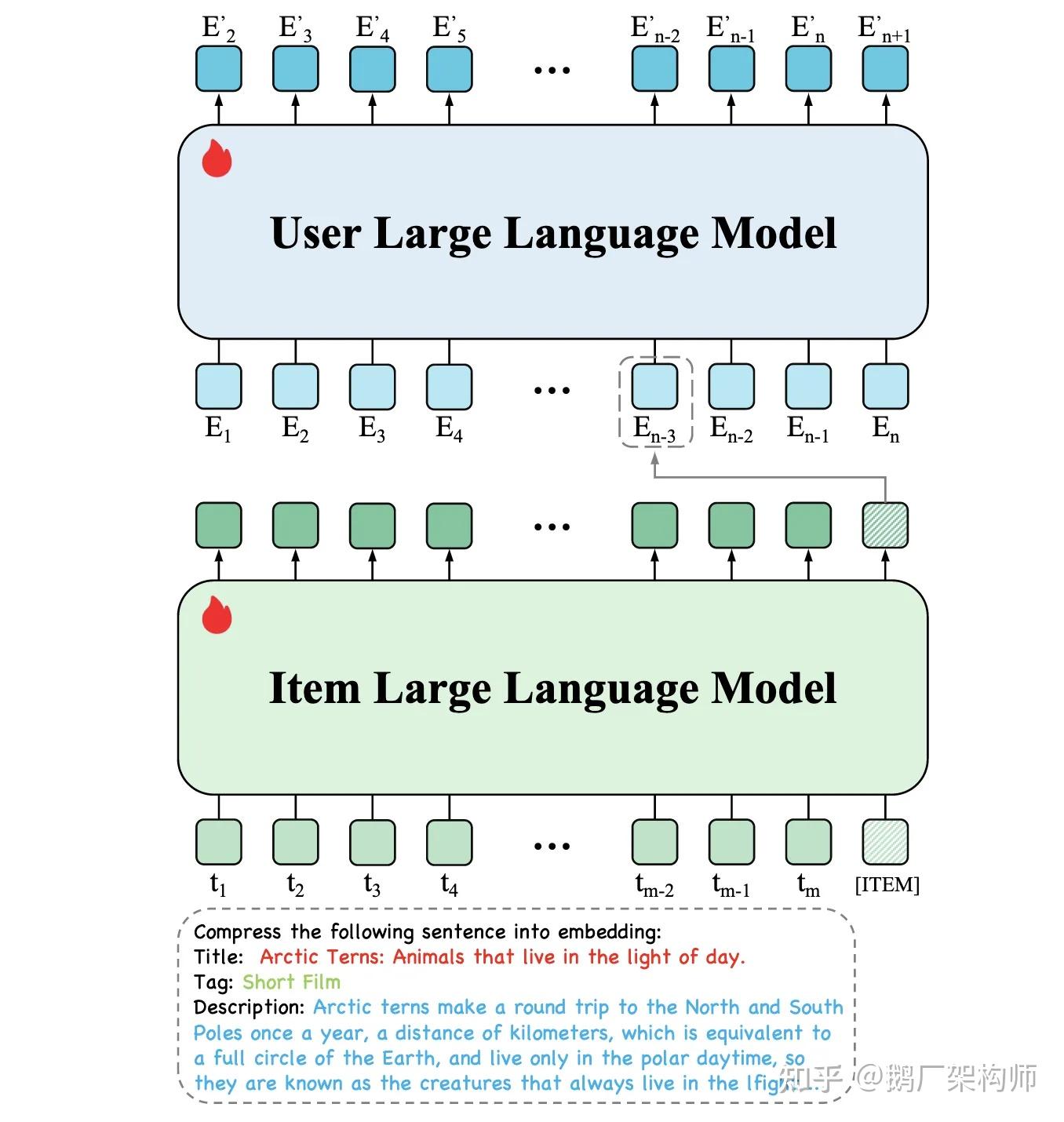
图11: 字节HLLM架构示意
架构设计:
● Item LLM:从项目文本描述中提取详细特征,生成简洁而信息丰富的嵌入
● User LLM:处理Item LLM生成的嵌入序列,对用户行为建模并预测未来交互
● 分层设计:通过分离项目和用户建模,降低计算复杂性,高效处理新项目和新用户
主要优势:
● 解决传统ID-based模型在冷启动场景下表现不佳的问题
● 更好地建模用户复杂且多样的兴趣
● 将“豆包”大模型与电商生态深度融合,实现从“种草”到“下单”的全链路打通
亚马逊Rufus:AI购物助手
2024年初,亚马逊推出了Rufus AI购物助手,将生成式AI应用于电商购物场景。
核心能力:
- 对话式交互:用户可用自然语言提问,如“什么耳机适合运动时使用?”
- 商品比较:自动总结多个商品的关键差异
- 评价总结:提供用户评价的AI生成摘要
- 个性化推荐:基于购物车、心愿单和历史购买提供建议
实践启示:Rufus在处理具体产品查询时表现良好,但在更个性化的或抽象的查询上仍有改进空间。这显示出生成式推荐在电商场景中处于早期阶段,需要持续迭代优化。
其他案例
Netflix Unicorn:统一上下文排序器,可处理搜索、“类似推荐”等多种任务,性能与专用模型相当甚至更优。
YouTube Semantic IDs:采用基于内容的语义ID替代传统哈希ID,更好地支持新视频和长尾内容的推荐。
Etsy统一嵌入:探索搜索和推荐的统一嵌入表示,简化架构并促进任务间的知识迁移。
工业化落地的共同规律
通过分析这些最新实践,我们可以总结出生成式推荐工业化落地的几个共同规律:
-
混合架构是主流:几乎所有成功案例都采用了“大模型+传统模型”的混合方式,而非完全替换。这既能利用LLM的语义理解能力,又能保持系统的高效性。
-
端到端生成成为趋势:快手One-Rec和Meta HSTU都展示了用单一生成模型替代多阶段级联架构的可能性,这能显著简化系统复杂度并降低成本。
-
序列建模是关键:无论是HSTU的序列转导、One-Rec的会话级生成,还是字节HLLM的分层序列模型,都将用户行为序列作为核心建模对象。
-
效率问题必须解决:成功的案例都在算力效率上取得了突破。HSTU的高效架构、One-Rec的90%的成本节约,都证明了工程优化的重要性。
-
领域特化比通用LLM更有效:阿里的LMA、字节的HLLM等都是针对推荐场景专门训练的模型,而非直接使用通用LLM。
-
冷启动问题得到缓解:基于语义的推荐方法能够更好地处理新用户、新物品和长尾内容,这是传统协同过滤难以解决的痛点。
这些实践案例表明,生成式推荐已经从概念阶段进入大规模工业化应用阶段,并在多个领域取得了显著成效。随着技术的持续迭代,我们有理由相信,2025年将会看到更多创新的应用场景和更成熟的解决方案。
当前挑战与未来方向
尽管LLM带来了巨大潜力,但在推荐系统中的应用仍面临诸多挑战:
技术挑战:
● 计算成本:LLM的推理成本远高于传统模型,难以应用于高并发场景
● 实时性:如何将用户的实时行为反馈到LLM中
● 长尾物品:如何处理没有文本描述的长尾物品
● 评估体系:如何评估生成式推荐的效果
伦理与安全:
● 幻觉问题:LLM可能生成不存在的物品或错误信息
● 偏见放大:LLM可能放大训练数据中的偏见
● 隐私保护:如何保护用户隐私同时利用LLM
未来方向:
● 混合架构:结合传统推荐模型的高效和LLM的灵活性
● 小型化与专用化:开发针对推荐场景优化的小型语言模型
● 多模态融合:结合文本、图片、视频等多种模态的推荐
● 个性化LLM:为每个用户调优LLM,实现真正的个性化
大语言模型的引入正在重塑推荐系统的范式。从判别到生成,从静态候选集到动态内容创造,从黑盒决策到可解释交互,推荐系统正在进入一个全新的时代。
结语:技术演进的启示
回顾推荐系统三十余年的发展历程,我们见证了一条清晰的技术演进路径。从1992年Tapestry的实验性尝试,到今天基于LLM的生成式推荐,这一领域经历了多次范式转移。每一次转移都不是突然出现的,而是在解决前一阶段痛点的过程中自然涌现的。
数据与算法的协同进化
推荐系统的发展深刻体现了数据与算法的协同进化。早期,数据稀缺且稀疏,算法相对简单。随着互联网的普及,用户行为数据爆发式增长,但同时也带来了数据稀疏性问题——矩阵分解等技术应运而生。深度学习时代,数据规模进一步扩大,算法也变得更加复杂和强大。而大模型时代,预训练数据的引入使得系统能够利用更广泛的知识,缓解了冷启动等长期问题。
这一过程启示我们:技术的进步往往与数据的积累相互促进。在实际应用中,我们需要根据自身的数据资产选择合适的技术路线,而不是盲目追逐最新技术。
学术与工业的相互促进
推荐系统是学术与工业结合最紧密的领域之一。学术界提供了理论基础和创新算法——矩阵分解、深度学习、注意力机制等都源于学术研究。而工业界则提供了真实场景和大规模数据——YouTube、阿里、字节的实践推动了技术的落地和迭代。
Netflix Prize是这种互动的佳话。它让学术界能够接触到真实的大规模数据,也让工业界看到了学术研究的价值。这种协作模式应该被继续发扬——工业界开放数据和问题,学术界提供创新解法,共同推动领域进步。
技术伦理与社会责任
随着推荐系统的普及,其社会影响也越来越深远。算法偏见、信息茧房、隐私泄漏、用户操纵等问题已经引起广泛关注。这些问题不仅是技术问题,更是伦理问题。
工业界需要在追求商业效果的同时,承担起社会责任。这包括:在算法设计中引入公平性约束、保护用户隐私、提供算法透明度、增加用户对推荐内容的控制权等。在大模型时代,这些问题可能变得更加复杂,需要我们更加谨慎地对待。
对从业者的启示
对于推荐系统的从业者,这段历史提供了几点启示:
打好基础:矩阵分解、特征工程、深度学习等经典技术仍然是业务的基石。新技术往往是在经典方法之上的发展,理解基础才能更好地掌握新技术。
关注工程实现:学术论文中的算法与工业落地之间往往有巨大鸿沟。多阶段架构、工程优化、系统设计等实际问题与算法创新同样重要。
保持学习:这是一个快速变化的领域。从深度学习到大模型,新的技术范式不断涌现。保持对新技术的敏感度,并能够快速学习和适应,是从业者的必备素质。
以用户为中心:技术是手段,用户体验是目的。不管技术如何变化,帮助用户发现感兴趣的内容这一核心使命始终未变。
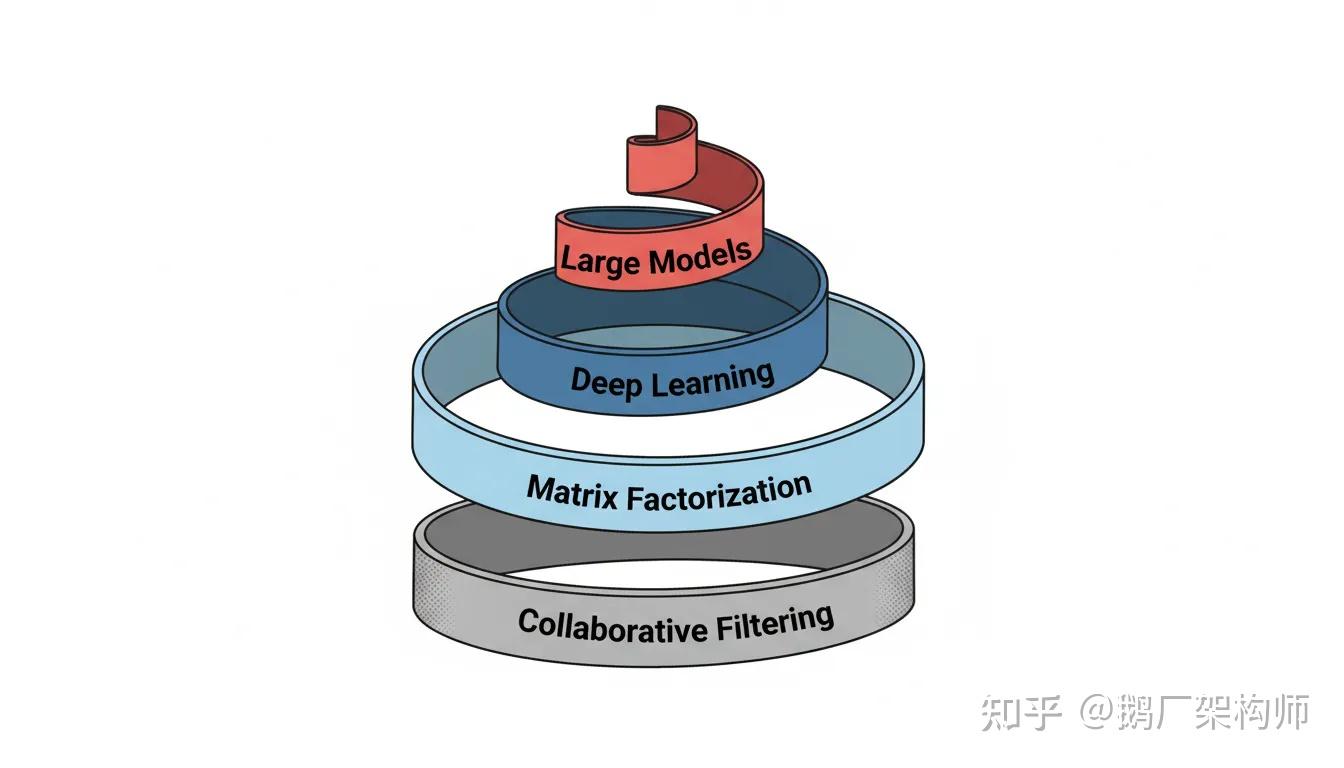
图12:技术演进的螺旋上升——每一代技术都在前人的肩膀上向前迈进
结语
从协同过滤到大模型,从简单的相似度计算到复杂的神经网络,再到强大的语言模型,推荐系统已经走过了三十余年的旅程。这三十年里,我们见证了技术的进步、工业的发展,也面临着新的挑战和机遇。未来,推荐系统将继续演进。或许下一个重大突破将来自多模态融合,或许将来自个性化LLM,又或许是我们现在还无法预见的方向。但有一点是确定的:只要信息过载问题存在,只要人们需要从海量信息中发现感兴趣的内容,推荐系统就将继续存在并不断进化。
提供创新解法,共同推动领域进步。
技术伦理与社会责任
随着推荐系统的普及,其社会影响也越来越深远。算法偏见、信息茧房、隐私泄漏、用户操纵等问题已经引起广泛关注。这些问题不仅是技术问题,更是伦理问题。
工业界需要在追求商业效果的同时,承担起社会责任。这包括:在算法设计中引入公平性约束、保护用户隐私、提供算法透明度、增加用户对推荐内容的控制权等。在大模型时代,这些问题可能变得更加复杂,需要我们更加谨慎地对待。
对从业者的启示
对于推荐系统的从业者,这段历史提供了几点启示:
打好基础:矩阵分解、特征工程、深度学习等经典技术仍然是业务的基石。新技术往往是在经典方法之上的发展,理解基础才能更好地掌握新技术。
关注工程实现:学术论文中的算法与工业落地之间往往有巨大鸿沟。多阶段架构、工程优化、系统设计等实际问题与算法创新同样重要。
保持学习:这是一个快速变化的领域。从深度学习到大模型,新的技术范式不断涌现。保持对新技术的敏感度,并能够快速学习和适应,是从业者的必备素质。
以用户为中心:技术是手段,用户体验是目的。不管技术如何变化,帮助用户发现感兴趣的内容这一核心使命始终未变。
[外链图片转存中…(img-xw3Al1YI-1763461892123)]
图12:技术演进的螺旋上升——每一代技术都在前人的肩膀上向前迈进
结语
从协同过滤到大模型,从简单的相似度计算到复杂的神经网络,再到强大的语言模型,推荐系统已经走过了三十余年的旅程。这三十年里,我们见证了技术的进步、工业的发展,也面临着新的挑战和机遇。未来,推荐系统将继续演进。或许下一个重大突破将来自多模态融合,或许将来自个性化LLM,又或许是我们现在还无法预见的方向。但有一点是确定的:只要信息过载问题存在,只要人们需要从海量信息中发现感兴趣的内容,推荐系统就将继续存在并不断进化。
让我们一起期待推荐系统的下一个三十年。
如果你也想系统学习AI大模型技术,想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习*_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 4
4 1
1- 0



 已为社区贡献144条内容
已为社区贡献144条内容

所有评论(0)