【Golang玩转本地大模型实战(三):实现上下文记忆,让对话更连贯】
在本系列的前两篇文章中,我们已经完成了一个基于Golang与Ollama[第一篇]:《Golang玩转本地大模型实战(一):ollama部署模型及流式调用》,介绍如何在本地部署大模型并实现 Golang 端的 API 调用;[第二篇]:《Golang玩转本地大模型实战(二):基于Golang + Web实现AI对话页面》,实现了前后端结合的实时聊天功能,支持 WebSocket 与 SSE。缺乏上
文章目录
前言
在本系列的前两篇文章中,我们已经完成了一个基于 Golang 与 Ollama 部署的本地大模型 AI 聊天系统:
- [第一篇]:《Golang玩转本地大模型实战(一):ollama部署模型及流式调用》,介绍如何在本地部署大模型并实现 Golang 端的 API 调用;
- [第二篇]:《Golang玩转本地大模型实战(二):基于Golang + Web实现AI对话页面》,实现了前后端结合的实时聊天功能,支持 WebSocket 与 SSE。
目前系统已能实现基本的 AI 问答功能,但仍存在一个关键问题:缺乏上下文记忆。每次对话模型都只能“盲目作答”,无法结合历史对话内容生成连贯回应。
本篇我们将解决这个问题,实现多轮对话的“上下文记忆功能”,让聊天更加智能、自然。
一、为什么需要上下文记忆?
大模型的输出完全依赖于当前输入的 prompt。在没有上下文的情况下,模型无法“记住”之前的交流内容,导致回答缺乏连续性。
例如:
- 问:“我喜欢蓝色。”
- 接着问:“我喜欢什么颜色?”
- 模型会答:“我不知道。”
这就需要我们在构建 prompt 时,将历史对话一起发送给模型,形成具有“记忆”的对话体验。
二、实现上下文记忆的核心逻辑
为实现上下文记忆,系统需支持以下能力:
1. 会话上下文管理
每个用户/会话维护一组对话历史,结构如下:
type ChatMessage struct {
Role string `json:"role"` // user / assistant
Content string `json:"content"` // 对话内容
}
var sessionContexts = make(map[string][]ChatMessage)
通过 sessionID(如用户IP、UUID等)区分多个会话,并将历史内容与新问题拼接后一并传给模型。
2. 滑动窗口机制:限制对话长度
为了避免无限增长导致上下文超限,我们采用滑动窗口策略,仅保留最近 N 轮对话(用户+AI)。
const maxHistoryMessages = 10
func manageHistory(sessionID string, newMsg ChatMessage) {
history := append(sessionContexts[sessionID], newMsg)
if len(history) > maxHistoryMessages {
history = history[len(history)-maxHistoryMessages:]
}
sessionContexts[sessionID] = history
}
3. Token 数控制:防止模型上下文溢出
多数大模型(如 GPT)有最大 token 限制,我们需要估算当前上下文的 token 数,超限则裁剪:
func estimateTokens(msgs []ChatMessage) int {
tokens := 0
for _, m := range msgs {
tokens += len(m.Content) / 4 // 简化估算:4 字符约等于 1 token
}
return tokens
}
func manageTokens(sessionID string, msgs []ChatMessage) {
if estimateTokens(msgs) > 2048 {
sessionContexts[sessionID] = msgs[len(msgs)/2:] // 丢弃前半段
}
}
更严谨的实现可以使用如 tiktoken 的库做精确计算。
三、关键技术回顾
| 模块 | 作用 |
|---|---|
| sessionContexts | 存储每个会话的上下文 |
| 滑动窗口机制 | 限制历史消息数量,防止上下文溢出 |
| token 控制 | 防止 prompt 超出模型最大输入长度 |
四、后端实现代码示例
以下是上下文管理完整 WebSocket 聊天服务示例代码(使用 Ollama + Deepseek 模型):
package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"log"
"net/http"
"time"
"github.com/gorilla/websocket"
)
type ChatRequest struct {
Model string `json:"model"`
Stream bool `json:"stream"`
Messages []ChatMessage `json:"messages"`
}
type ChatMessage struct {
Role string `json:"role"`
Content string `json:"content"`
}
// 使用 sessionID 管理多个会话;demo 里简单用 IP 地址做区分
var sessionContexts = make(map[string][]ChatMessage)
// 设置最大上下文轮数(每轮是用户+AI)
const (
maxHistoryMessages = 10
maxTokenMessage = 102400
)
var upgrader = websocket.Upgrader{
CheckOrigin: func(r *http.Request) bool {
return true
},
}
func chatHandler(w http.ResponseWriter, r *http.Request) {
conn, err := upgrader.Upgrade(w, r, nil)
if err != nil {
log.Println("Upgrade error:", err)
return
}
defer conn.Close()
clientID := r.RemoteAddr
fmt.Println("New connection")
for {
_, msg, err := conn.ReadMessage()
if err != nil {
log.Println("Read error:", err)
break
}
fmt.Println("收到消息:", string(msg))
userInput := string(msg)
// 获取当前会话的上下文
history := sessionContexts[clientID]
// 拼接历史 + 当前用户消息
allMessages := append(history, ChatMessage{Role: "user", Content: userInput})
// 准备请求体
reqData := ChatRequest{
Model: "deepseek-r1:8b",
Stream: true,
Messages: allMessages,
}
jsonData, err := json.Marshal(reqData)
if err != nil {
http.Error(w, "json marshal error", http.StatusInternalServerError)
return
}
// 调用本地Ollama服务
resp, err := http.Post("http://localhost:11434/api/chat", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
http.Error(w, "call ollama error", http.StatusInternalServerError)
return
}
defer resp.Body.Close()
// 流式读取模型输出
scanner := bufio.NewScanner(resp.Body)
var fullReply string
for scanner.Scan() {
line := scanner.Text()
if line == "" {
continue
}
var chunk struct {
Message struct {
Content string `json:"content"`
} `json:"message"`
Done bool `json:"done"`
}
if err := json.Unmarshal([]byte(line), &chunk); err != nil {
continue
}
err = conn.WriteMessage(websocket.TextMessage, []byte(chunk.Message.Content))
if err != nil {
log.Println("Write error:", err)
break
}
fullReply += chunk.Message.Content
time.Sleep(50 * time.Millisecond)
if chunk.Done {
break
}
}
allMessages = append(allMessages, ChatMessage{Role: "assistant", Content: fullReply})
// 管理上下文大小
manageHistory(clientID, ChatMessage{Role: "user", Content: userInput})
manageHistory(clientID, ChatMessage{Role: "assistant", Content: fullReply})
// 如果超过 token 限制,裁剪历史
manageTokens(clientID, allMessages)
}
}
// 保证上下文不超过最大长度
func manageHistory(sessionID string, newMessage ChatMessage) {
history := sessionContexts[sessionID]
history = append(history, newMessage)
if len(history) > maxHistoryMessages {
sessionContexts[sessionID] = history[len(history)-maxHistoryMessages:]
} else {
sessionContexts[sessionID] = history
}
}
// 简单估算 token 数
func estimateTokens(messages []ChatMessage) int {
tokenCount := 0
for _, msg := range messages {
tokenCount += len(msg.Content) / 4
}
return tokenCount
}
// 如果 token 数过大,裁剪历史
func manageTokens(sessionID string, messages []ChatMessage) {
if estimateTokens(messages) > 2048 { // 假设最大 token 数为 2048
sessionContexts[sessionID] = sessionContexts[sessionID][len(sessionContexts[sessionID])/2:]
}
}
// 提供静态HTML页面
func homePage(w http.ResponseWriter, r *http.Request) {
http.ServeFile(w, r, "./static/index.html") // 当前目录的index.html
}
func main() {
http.HandleFunc("/", homePage) // 网页入口
http.HandleFunc("/ws", chatHandler) // WebSocket接口
log.Println("服务器启动,访问:http://localhost:8080")
log.Fatal(http.ListenAndServe(":8080", nil))
}
五、效果验证
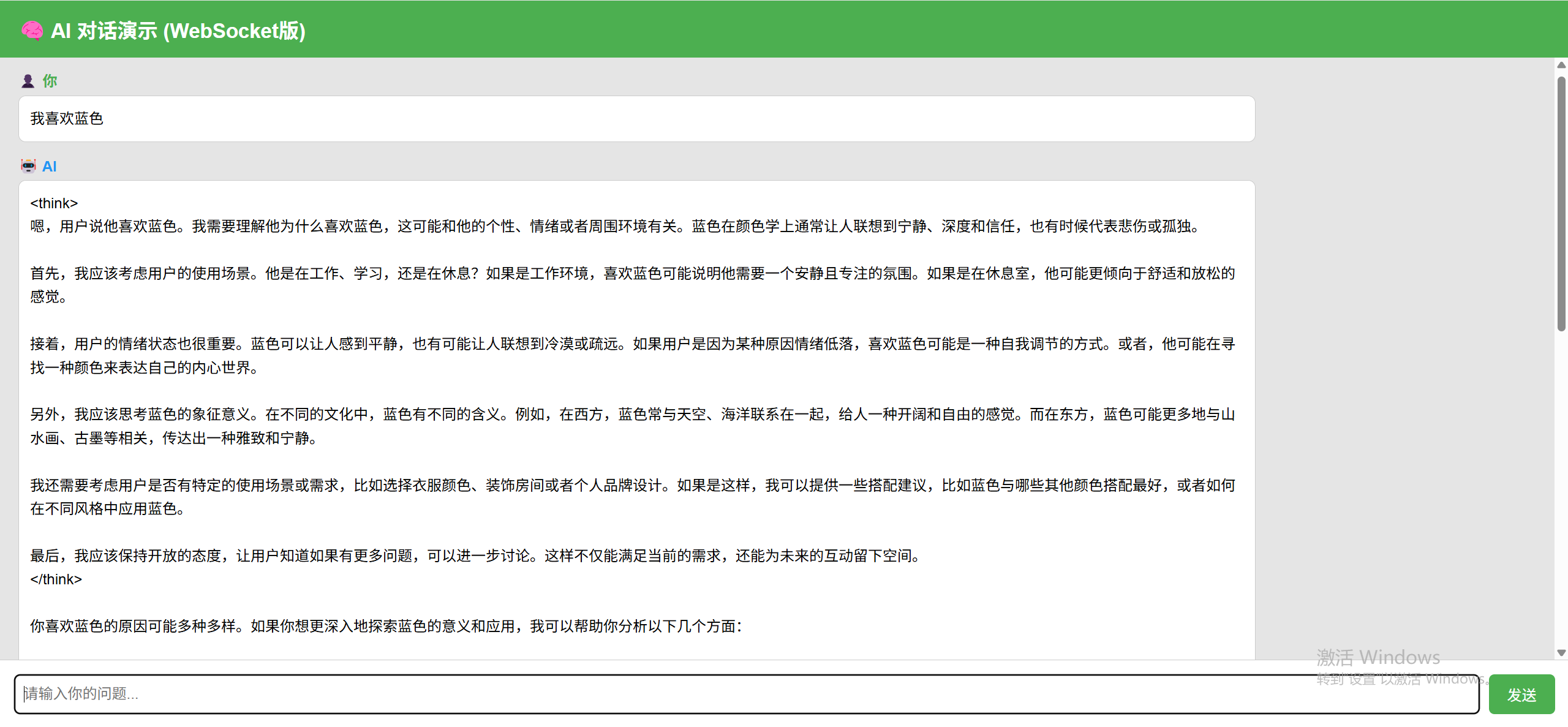
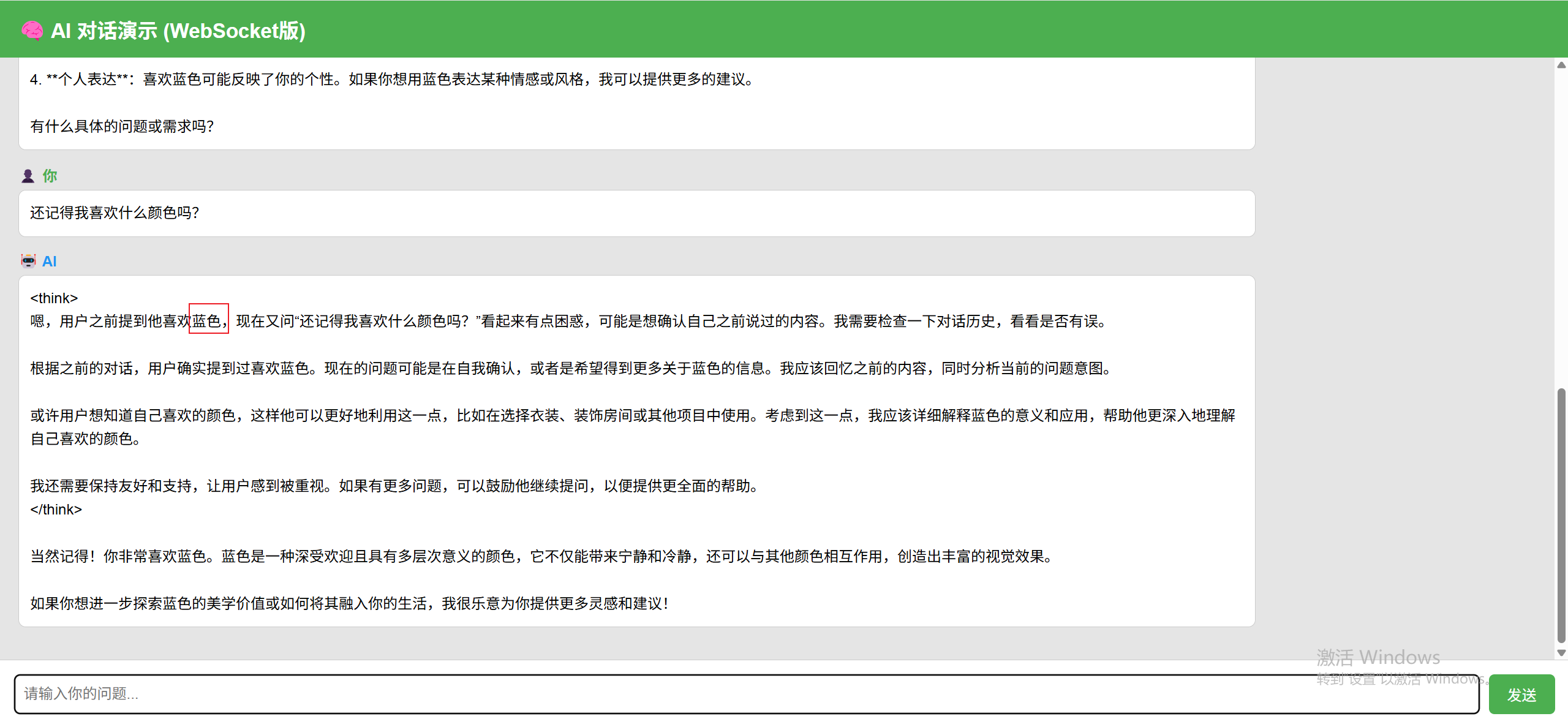
我们在前端发送两轮对话:
- “我喜欢蓝色”
- “我喜欢什么颜色?”
模型准确识别了“蓝色”作为用户喜好,说明上下文生效:
六、总结与展望
本文成果:
- 实现了 AI 聊天的 上下文记忆能力;
- 支持按会话维护历史;
- 实现滑动窗口 + token 限制,兼顾准确性与性能。
存在优化的空间:
由于本文仅仅是一个demo,所以存在很多需要优化的空间,这里简单列出,不做详细的代码实现了。
- 使用 Redis 持久化上下文,支持多实例部署;
- 引入上下文压缩(如摘要生成),提升信息保留能力;
- 实现“清空对话”与“会话多标签”等增强功能。
下一篇预告
Golang玩转本地大模型实战(四):我们将封装完整服务为 Docker 镜像,实现“一键部署”。
参考资料
【手把手教会你如何通过ChatGPT API实现上下文对话】
【Spring AI进阶:AI聊天机器人之ChatMemory持久化(二)】
【多轮对话中让AI保持长期记忆的8种优化方式(附案例和代码)】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)