Ant Design X牵手QWen大模型:前端开发的AI新玩法
文章目录
一、引言
在当今数字化时代,前端开发领域不断涌现新的技术与工具,为开发者带来更多创新可能。Ant Design X 作为专为 AI 界面而生的 React UI 库,通过构建系统性的 AI 产品设计理论和方法 ——《RICH 设计范式》,为开发者提供了先进的交互体验、多样化的组件选择以及即插即用的模型集成等核心优势,助力快速构建个性化 AI 交互页面。
而 Qwen 大模型则是由阿里云推出的具有强大语言处理能力的大模型,在自然语言处理、代码生成、知识问答等多个领域展现出卓越性能。它能够理解和生成自然语言,实现智能对话、文本生成、摘要提取等功能,为众多应用场景提供智能支持。
当 Ant Design X 与 Qwen 大模型相结合,犹如为前端开发注入了强大的智能引擎。一方面,Ant Design X 提供的丰富组件和便捷工具,使前端界面的搭建更加高效和灵活,能够快速构建出美观、易用的交互界面;另一方面,Qwen 大模型的智能能力为应用赋予了更强大的语义理解和交互能力,实现智能对话、智能推荐等功能。这种结合不仅提升了前端应用的智能化水平,还为用户带来了全新的交互体验,开创了前端开发与 AI 融合的新局面。接下来,让我们深入探讨如何在前端开发中实现 Ant Design X 与 Qwen 大模型的巧妙结合。
二、Ant Design X 基础入门

(一)Ant Design X 简介
官网地址:https://x.ant.design/index-cn
Ant Design X 是一个基于 Ant Design 体系的创新解决方案,专门为构建高效的 AI 交互界面而设计 。它集成了智能对话组件和 API 服务,致力于简化 AI 界面的开发流程。通过遵循现代设计原则,Ant Design X 提供了丰富的组件和模板,并利用 TypeScript 提供全面的类型支持,极大地增强了开发的体验和可靠性。其构建的《RICH 设计范式》,涵盖 Role(角色)、Intention(意图)、Conversation(对话)、Hybrid UI(混合界面)四个设计要素,逐步确定意图、角色、会话等隐形的体验规则,同时界定融合了自然语言会话等多种交互模式的混合界面形态,为用户带来前所未有的交互体验。
(二)核心优势
- 企业级最佳实践:基于 RICH 交互范式,深度优化 AI 交互体验,充分满足企业级应用在复杂业务场景下的需求,为企业打造专业、高效的 AI 界面提供有力支持。
- 丰富原子组件:拥有丰富多样的原子组件,全面覆盖大多数 AI 对话场景。无论是简单的聊天界面,还是复杂的多轮对话、智能客服等场景,开发者都能借助这些组件快速搭建出个性化的 AI 交互界面,大大提高开发效率。
- 开箱即用模型集成:支持轻松对接符合 OpenAI 标准的模型推理服务,如 Qwen 大模型。开发者无需复杂的配置和开发,即可快速将强大的 AI 模型集成到自己的应用中,实现智能对话、文本生成等功能,极大地简化了开发流程。
- 高效数据流管理:提供强大的数据流管理工具,如 useXAgent、useXChat 等钩子函数,帮助开发者轻松管理 AI 对话应用中的数据流。这些工具简化了对话数据的处理和传递,使开发者能够专注于业务逻辑的实现,提高开发效率和代码的可维护性。
- 深度主题定制:支持细粒度的样式调整,开发者可以根据项目需求和用户喜好,对组件的颜色、字体、布局等进行个性化定制,满足多样化的设计需求,打造独特的用户界面风格。
(三)安装与引入
安装:
使用 npm 安装:在项目根目录下的命令行中执行
npm install @ant - design/x --save
使用 yarn 安装:执行
yarn add @ant - design/x
使用 pnpm 安装:执行
pnpm add @ant - design/x
引入:
浏览器引入:在浏览器中使用时,可以通过
<script src="antd.min.js"></script>
<link rel="stylesheet" href="antd.min.css">
项目中引入:在 React 项目中,通常在需要使用 Ant Design X 组件的文件中进行引入。例如,引入消息气泡组件Bubble和发送框组件Sender:
import React from'react';
import { Bubble, Sender } from '@ant - design/x';
通过以上步骤,就完成了 Ant Design X 的安装与引入,为后续结合 Qwen 大模型进行开发做好了准备。
三、QWen 大模型探秘
(一)QWen 大模型简介
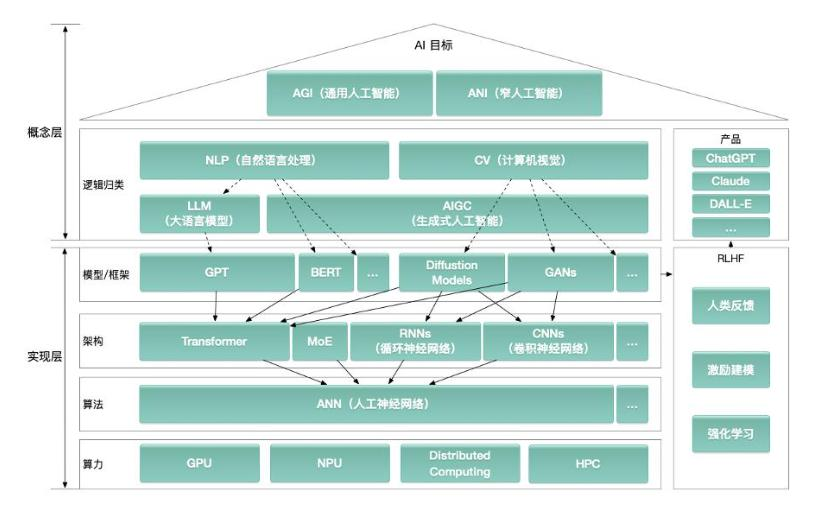
QWen 是阿里巴巴达摩院开发的开源大语言模型系列,在自然语言处理领域表现卓越。它基于 Transformer 架构构建,经过大规模数据的训练,具备强大的语言理解和生成能力。通过对海量文本的学习,QWen 能够理解上下文语境,生成自然流畅、逻辑连贯的文本内容。其在多任务处理方面表现出色,能够灵活应对各种自然语言处理任务,如文本生成、问答系统、对话交互、翻译以及文本分类等。无论是日常对话场景中的智能问答,还是专业领域的文档分析,QWen 都能凭借其出色的语言处理能力提供准确、有效的解决方案。
(二)核心特点
- 多任务处理能力:QWen 模型经过广泛的训练,适用于各种自然语言任务,如文本生成、问答、对话、翻译、文本分类等。它能够处理多个不同领域的问题,且具有很强的泛化能力。例如,在智能客服场景中,它可以快速理解用户的问题,并根据问题的类型和语境提供准确的回答,无论是技术咨询、产品介绍还是售后问题,都能应对自如。
- 大规模训练和高效架构:采用 Transformer 架构,并进行了大规模数据训练,拥有数十亿参数(例如 Qwen-7B 有 70 亿参数,Qwen-14B 有 140 亿参数)。这些模型在文本生成和理解方面表现出色,并且能通过微调适应特定领域的任务。大规模的数据训练使得 Qwen 模型学习到了丰富的语言知识和语义表达,能够生成高质量的文本内容;而 Transformer 架构的高效性则保证了模型在处理大规模数据时的计算效率和性能表现。
- 支持多模态:除了自然语言处理,Qwen 的多模态模型(例如 Qwen-VL)支持处理图像和文本的联合任务。这使得模型在对话中不仅能理解文字,还可以结合视觉信息,提供跨模态的智能问答和交互。比如,在图像问答任务中,用户可以上传一张图片并提出相关问题,Qwen-VL 能够分析图片内容,并结合问题给出准确的回答,实现了图像与文本信息的融合处理。
- 开放与社区支持:阿里巴巴将 Qwen 模型开源,使得研究者和开发者可以自由下载、使用和微调这些模型。开源的 Qwen 还带来了较好的社区支持,开发者可以在本地部署模型并将其集成到应用中。社区成员可以分享自己的使用经验、模型优化方法和应用案例,促进了 Qwen 模型的不断发展和创新。同时,开源也降低了开发者使用大模型的门槛,推动了大模型技术在各个领域的应用和普及。
- 可扩展性和部署:Qwen 模型系列可以在多种硬件上进行部署,包括 GPU 集群和本地计算资源,提供了灵活的规模扩展能力。对于企业应用,Qwen 可以通过微调适应特定场景下的需求。企业可以根据自身的业务规模和计算资源,选择合适的硬件平台来部署 Qwen 模型,并通过微调使其更好地满足企业特定业务场景的需求,如电商推荐系统、金融风险评估等。
- 中文语言优势:作为由阿里巴巴达摩院开发的模型,Qwen 在中文语言处理任务上表现尤其出色,并对中文语料库进行了深度的预训练。同时,Qwen 也具备处理多语言的能力,能支持多种语言的任务。在处理中文文本时,Qwen 能够准确理解中文的语义、语法和文化背景,生成符合中文表达习惯的文本内容,在中文语言处理方面具有明显的优势。
(三)代表性模型及应用场景
- Qwen - 7B:参数量为 70 亿,适用于中小型应用,具有较高的灵活性和资源效率。它适合文本生成、对话和问答任务,在一些对计算资源要求不高,但需要快速响应的场景中表现出色。例如,在智能聊天机器人中,Qwen - 7B 可以快速理解用户的问题,并生成自然流畅的回答,为用户提供即时的交互体验。同时,由于其较小的参数量,它能够在有限的硬件资源上运行,降低了部署成本,适合中小企业和个人开发者使用。
- Qwen - 14B:拥有 140 亿参数,适用于大规模应用和多任务场景,能够提供更高质量的文本生成和理解能力。在需要处理大量文本数据、进行复杂语义分析和多任务处理的场景中,Qwen - 14B 展现出强大的性能优势。比如在智能写作辅助工具中,它可以根据用户输入的主题和要求,生成内容丰富、逻辑严谨的文章,帮助用户提高写作效率和质量。对于大型企业和科研机构,Qwen - 14B 能够满足其对高性能和高精度的需求,为其业务发展和科研创新提供有力支持。
- Qwen - VL:这是 Qwen 的多模态版本,支持图像和文本输入,适合跨模态任务,如图像问答和对话场景。在处理复杂任务时,它可以结合图像和文本信息生成更加全面的结果。例如,在智能教育领域,学生可以通过上传图片并提问,Qwen - VL 能够分析图片内容并解答相关问题,帮助学生更好地理解知识。在图像识别和图像描述生成等任务中,Qwen - VL 也能发挥重要作用,实现多模态信息的融合和交互。
四、Ant Design X 邂逅 QWen 大模型
(一)结合的技术原理
Ant Design X 与 QWen 大模型的结合,主要借助其提供的 useXAgent 和 XRequest 等工具,来对接符合 OpenAI 标准的 QWen 模型推理服务。其核心原理在于通过这些工具,实现前端应用与 QWen 模型服务之间的通信和数据交互。
useXAgent 是 Ant Design X 提供的一个运行时工具,它在前端应用中扮演着管理对话流程和与模型交互的关键角色。它负责接收用户输入的消息,并将这些消息组织成符合模型输入格式的请求数据。在与 QWen 模型对接时,useXAgent 会将用户的问题或指令作为请求的一部分,发送给 QWen 模型推理服务。同时,它还能处理模型返回的响应数据,将其转化为前端应用能够理解和展示的格式,例如对话消息气泡的内容。
XRequest 则是用于创建和管理 HTTP 请求的工具。在对接 QWen 模型时,它通过设置特定的请求参数,如 baseURL(指定 QWen 模型推理服务的地址)、dangerouslyApiKey(用于身份验证的 API 密钥)和 model(指定使用的 QWen 模型版本)等,来构建与 QWen 模型服务的通信通道。通过 XRequest,前端应用可以向 QWen 模型发送 POST 请求,请求中包含用户的对话消息等信息。模型在接收到请求后,会进行相应的处理,并返回包含生成的回答或其他相关信息的响应。XRequest 还负责处理请求过程中的各种事件,如请求成功、失败或流更新等,以便前端应用能够根据不同的情况进行相应的处理,例如展示加载状态、显示错误信息或实时更新对话内容。
(二)关键技术要点
参数设置:
- baseURL:这是 QWen 模型推理服务的基础 URL,例如https://dashscope.aliyuncs.com/compatible-mode/v1 。准确设置 baseURL 是确保前端应用能够与正确的模型服务进行通信的关键。如果 baseURL 设置错误,前端应用将无法找到模型服务,导致请求失败。
- dangerouslyApiKey:这是用于身份验证的 API 密钥,用于验证前端应用对 QWen 模型服务的访问权限。在实际应用中,应妥善保管此密钥,避免泄露。例如,可以将其存储在环境变量中,通过process.env[‘DASHSCOPE_API_KEY’]的方式获取,而不是直接硬编码在代码中。
- model:指定要使用的 QWen 模型版本,如qwen-plus。不同的模型版本可能在性能、功能和适用场景上有所差异,开发者应根据具体需求选择合适的模型版本。例如,如果对模型的语言生成能力要求较高,可能选择参数更多、能力更强的模型版本;如果对计算资源有限,可能选择相对轻量级的模型版本。
请求处理:
- 消息格式:在向 QWen 模型发送请求时,需要将用户的对话消息组织成特定的格式。通常,消息会以数组的形式传递,每个元素包含role(角色,如user表示用户消息,assistant表示模型回复)和content(消息内容)等字段。例如:
{
messages: [
{
role: 'user',
content: '你好,今天天气如何?'
}
]
}
-
流式处理:为了实现实时交互,提高用户体验,Ant Design X 支持与 QWen 模型进行流式交互。通过设置stream: true,模型会在处理过程中逐步返回结果,而不是等待整个处理完成后再返回。前端应用可以实时接收这些部分结果,并进行展示,例如实现打字机效果的实时对话显示。在处理流式响应时,需要注意对返回的数据流进行正确的解析和处理,以确保能够准确地提取和展示模型的回复内容。
-
响应处理:
-
- 成功响应:当 QWen 模型成功处理请求并返回响应时,前端应用需要根据响应数据更新对话界面。例如,从响应中提取模型生成的回答内容,并将其展示在消息气泡中。响应数据的结构可能因模型和请求设置而异,开发者需要根据实际情况进行解析。例如,对于 QWen 模型的响应,可能需要从choices数组中提取delta.content字段来获取模型的回复内容:
const data = JSON.parse(chunk.data);
content += data?.choices[0].delta.content;
- 成功响应:当 QWen 模型成功处理请求并返回响应时,前端应用需要根据响应数据更新对话界面。例如,从响应中提取模型生成的回答内容,并将其展示在消息气泡中。响应数据的结构可能因模型和请求设置而异,开发者需要根据实际情况进行解析。例如,对于 QWen 模型的响应,可能需要从choices数组中提取delta.content字段来获取模型的回复内容:
-
-
错误处理:在请求过程中,可能会出现各种错误,如网络故障、模型服务不可用或请求参数错误等。前端应用需要对这些错误进行妥善处理,例如显示友好的错误提示信息,告知用户请求失败的原因,并提供重试或其他解决方案。可以通过try…catch语句捕获请求过程中的错误,并在catch块中进行相应的处理:
try { // 发送请求代码 } catch (error) { // 处理错误,如显示错误信息 console.log('error', error); }
-
五、实战:用 Ant Design X 调用 QWen 大模型
本地部署效果图示例:
(一)准备工作
- 安装 Ant Design X:如果尚未安装,在 React 项目的根目录下打开终端,使用 npm 进行安装,执行命令npm install @ant - design/x --save 。也可以使用 yarn 或 pnpm 进行安装,分别执行yarn add @ant - design/x和pnpm add @ant - design/x 。
- 获取 DashScope API Key:由于 Qwen 模型通过 DashScope 平台提供服务,需要获取 API Key 以进行身份验证。获取步骤如下:
- 访问 DashScope 管理控制台,前往控制台 。
- 在控制台 “总览” 页下,单击 “去开通”。
- 阅读服务协议,确认无误后单击 “立即开通”。
- 开通后,在控制台左侧导航栏单击 “管理中心 - API-KEY 管理”,在页面单击 “创建新的 API-KEY” 。系统创建生成 API-KEY,并在弹出的对话框中展示,单击复制按钮将 API-KEY 的内容复制保存。复制并在安全的地方保存 API-KEY 后,单击 “我已保存”,关闭对话框。
- 了解 Qwen 模型版本及特点:Qwen 模型有多个版本,如 Qwen-7B、Qwen-14B、Qwen-plus 等。不同版本在参数量、性能和适用场景上有所不同。例如,Qwen-7B 适用于资源有限的场景,而 Qwen-14B 适用于对性能要求较高的复杂任务。在实际应用中,根据项目的需求和资源情况选择合适的模型版本。比如,如果项目对响应速度要求较高,且计算资源有限,可以选择 Qwen-7B;如果项目需要处理复杂的文本生成任务,且有足够的计算资源支持,则可以选择 Qwen-14B 或 Qwen-plus 等更强大的模型版本。同时,了解各版本模型在语言理解、生成能力、多模态支持等方面的特点,以便更好地发挥模型的优势。
(二)代码实现步骤
- 引入相关模块:在 React 项目的组件文件中,引入useXAgent、Sender、XRequest等模块。这些模块是 Ant Design X 中用于与模型进行交互和管理对话的关键工具。useXAgent用于模型调度,Sender用于实现用户输入的发送,XRequest用于创建和管理 HTTP 请求。示例代码如下:
import React from'react';
import { useXAgent, Sender, XRequest } from '@ant - design/x';
- 配置请求:通过XRequest创建请求实例,配置baseURL、apiKey和模型等关键参数。baseURL指定 Qwen 模型推理服务的地址,如https://dashscope.aliyuncs.com/compatible-mode/v1 ;dangerouslyApiKey设置为获取的 DashScope API Key,用于身份验证;model指定要使用的 Qwen 模型版本,如qwen-plus 。示例代码如下:
const { create } = XRequest({
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
dangerouslyApiKey: process.env['DASHSCOPE_API_KEY'],
model: 'qwen-plus'
});
这里使用process.env[‘DASHSCOPE_API_KEY’]从环境变量中获取 API Key,以提高安全性,避免在代码中直接暴露敏感信息。
- 设置模型调度:使用useXAgent设置请求逻辑,处理输入信息和回调。在useXAgent的request函数中,接收用户输入的消息,并通过create函数向 Qwen 模型发送请求。同时,处理请求过程中的各种回调,如onSuccess(请求成功)、onError(请求失败)和onUpdate(流更新)。示例代码如下:
const [agent] = useXAgent({
request: async (info, callbacks) => {
const { messages, message } = info;
const { onUpdate } = callbacks;
let content: string = '';
try {
create({
messages: [
{
role: 'user',
content: message
}
],
stream: true
},
{
onSuccess: (chunks) => {
console.log('sse chunk list', chunks);
},
onError: (error) => {
console.log('error', error);
},
onUpdate: (chunk) => {
console.log('sse object', chunk);
const data = JSON.parse(chunk.data);
content += data?.choices[0].delta.content;
onUpdate(content);
}
});
} catch (error) {
// 处理错误
}
}
});
- 实现用户输入与交互:利用Sender组件实现用户输入提交,触发模型请求。当用户在输入框中输入内容并提交时,调用agent.request方法,将用户输入的消息发送给模型进行处理。示例代码如下:
function onRequest(message: string) {
agent.request({ message }, {
onUpdate: () => { },
onSuccess: () => { },
onError: () => { }
});
}
return <Sender onSubmit={onRequest} />;
(三)代码示例与解释
下面是一个完整的使用 Ant Design X 调用 Qwen 大模型的 React 组件代码示例:
import React from'react';
import { useXAgent, Sender, XRequest } from '@ant - design/x';
const { create } = XRequest({
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
dangerouslyApiKey: process.env['DASHSCOPE_API_KEY'],
model: 'qwen-plus'
});
const Component: React.FC = () => {
const [agent] = useXAgent({
request: async (info, callbacks) => {
const { messages, message } = info;
const { onUpdate } = callbacks;
let content: string = '';
try {
create({
messages: [
{
role: 'user',
content: message
}
],
stream: true
},
{
onSuccess: (chunks) => {
console.log('sse chunk list', chunks);
},
onError: (error) => {
console.log('error', error);
},
onUpdate: (chunk) => {
console.log('sse object', chunk);
const data = JSON.parse(chunk.data);
content += data?.choices[0].delta.content;
onUpdate(content);
}
});
} catch (error) {
// 处理错误
}
}
});
function onRequest(message: string) {
agent.request({ message }, {
onUpdate: () => { },
onSuccess: () => { },
onError: () => { }
});
}
return <Sender onSubmit={onRequest} />;
};
export default Component;
创建请求实例:
const { create } = XRequest({
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
dangerouslyApiKey: process.env['DASHSCOPE_API_KEY'],
model: 'qwen-plus'
});
这部分代码通过XRequest创建了一个请求实例,配置了baseURL(Qwen 模型推理服务的地址)、dangerouslyApiKey(从环境变量中获取的 DashScope API Key)和model(指定使用的 Qwen 模型版本为qwen-plus)。create函数用于创建具体的请求,后续将使用它来向模型发送请求。
2. 使用useXAgent管理请求逻辑:
const [agent] = useXAgent({
request: async (info, callbacks) => {
const { messages, message } = info;
const { onUpdate } = callbacks;
let content: string = '';
try {
create({
messages: [
{
role: 'user',
content: message
}
],
stream: true
},
{
onSuccess: (chunks) => {
console.log('sse chunk list', chunks);
},
onError: (error) => {
console.log('error', error);
},
onUpdate: (chunk) => {
console.log('sse object', chunk);
const data = JSON.parse(chunk.data);
content += data?.choices[0].delta.content;
onUpdate(content);
}
});
} catch (error) {
// 处理错误
}
}
});
useXAgent用于管理模型调度和请求逻辑。在request函数中:
接收info和callbacks参数,info包含用户输入的消息message和对话历史messages;callbacks包含各种回调函数,这里主要使用onUpdate用于实时更新对话内容。
使用create函数向 Qwen 模型发送请求,请求中包含用户输入的消息,格式为{role: ‘user’, content: message} ,并设置stream: true开启流式处理,以便实时获取模型的响应。
在请求的回调函数中:
- onSuccess在请求成功完成时触发,chunks参数包含解析后的响应数据块,这里通过console.log打印日志。
- onError在请求发生错误时触发,error参数包含错误信息,同样通过console.log打印日志。
- onUpdate在流更新时触发,每次接收到模型返回的部分响应数据时,解析数据并将模型生成的内容累加到content中,然后调用onUpdate(content)实时更新对话内容。
处理用户输入并触发请求:
function onRequest(message: string) {
agent.request({ message }, {
onUpdate: () => { },
onSuccess: () => { },
onError: () => { }
});
}
return <Sender onSubmit={onRequest} />;
onRequest函数在用户提交输入时被调用,它调用agent.request方法,将用户输入的消息message发送给模型进行处理,并传递了onUpdate、onSuccess和onError回调函数,这里暂时为空,可根据实际需求进行处理。最后,通过将onRequest函数绑定到Sender组件的onSubmit事件上,实现用户输入提交后触发模型请求的功能。
六、优化与拓展
(一)性能优化
- 网络请求优化:在前端与 Qwen 模型服务进行通信时,网络请求的性能对整体应用的响应速度有着关键影响。可以采用以下优化措施:
- 合并请求:在一次对话中,可能会有多个小的请求发送给模型服务。例如,用户连续输入多个简短的问题,每次输入都触发一次请求。可以通过一定的策略,将这些小请求合并为一个大请求。比如,设置一个定时器,当用户输入结束后的一定时间内(如 500 毫秒),如果没有新的输入,就将这段时间内的所有输入合并成一个请求发送给模型服务。这样可以减少网络请求的次数,降低网络开销,提高响应速度。
- 缓存请求结果:对于一些频繁出现且答案相对固定的问题,可以在前端设置缓存机制。例如,常见问题解答(FAQ)类型的问题,当用户首次提问并得到模型的回答后,将问题和答案缓存起来。当下次用户提出相同问题时,直接从缓存中获取答案,而不需要再次向模型服务发送请求。可以使用浏览器的本地存储(localStorage)或内存缓存(如 JavaScript 中的对象)来实现缓存功能。例如:
const cache = {};
async function getAnswerFromModel(prompt) {
if (cache[prompt]) {
return cache[prompt];
}
// 发送请求到模型服务获取答案
const response = await sendRequestToModel(prompt);
const answer = response.data.answer;
cache[prompt] = answer;
return answer;
}
- 缓存策略:除了缓存请求结果,还可以对模型相关的数据进行缓存,以减少重复计算和数据传输。
- 模型参数缓存:对于一些常用的模型参数配置,可以在前端缓存起来。例如,模型的版本信息、一些固定的超参数设置等。当应用重新启动或切换页面时,如果模型参数没有发生变化,就可以直接从缓存中读取,而不需要再次从服务器获取。这样可以加快应用的初始化速度,提高用户体验。
- 对话历史缓存:将用户的对话历史缓存起来,不仅可以在用户重新打开应用时恢复之前的对话状态,还可以在进行多轮对话时,快速获取之前的对话信息,避免重复向模型服务发送相同的对话历史。可以使用 IndexedDB 等浏览器数据库来存储较长的对话历史,对于较短的近期对话历史,可以使用内存缓存。例如,使用 IndexedDB 存储对话历史:
// 打开IndexedDB数据库
const request = window.indexedDB.open('chatHistoryDB', 1);
request.onsuccess = function (event) {
const db = event.target.result;
// 获取对话历史
const transaction = db.transaction(['chatHistory'], 'readonly');
const store = transaction.objectStore('chatHistory');
const historyRequest = store.get('historyKey');
historyRequest.onsuccess = function (event) {
const chatHistory = event.target.result;
if (chatHistory) {
// 使用缓存的对话历史
}
};
};
- 模型配置优化:合理调整 Qwen 模型的配置参数,也可以在一定程度上提升性能。
调整生成参数:模型的生成参数,如temperature(温度系数)、top_p(核采样参数)等,会影响生成文本的质量和速度。temperature值越高,生成的文本越具有随机性和创造性,但也可能导致生成结果的稳定性下降;top_p值决定了从概率分布中选择下一个词的范围,较小的top_p值会使生成的文本更加保守和确定性。在实际应用中,可以根据具体需求和场景,适当调整这些参数。例如,在需要快速获取简洁、准确回答的场景中,可以降低temperature值,提高top_p值,以加快生成速度并保证回答的准确性。 - 选择合适的模型版本:Qwen 模型有多个版本,不同版本在参数量、性能和适用场景上有所不同。如果应用对响应速度要求较高,且对模型的语言处理能力要求不是特别高,可以选择参数量较小的模型版本,如 Qwen - 7B。这样可以减少模型计算的时间和资源消耗,提高响应速度。但如果应用需要处理复杂的自然语言任务,如长篇文本生成、复杂语义理解等,则需要选择参数量较大、能力更强的模型版本,如 Qwen - 14B 或 Qwen - plus,虽然可能会牺牲一些响应速度,但能获得更准确和高质量的结果。
(二)功能拓展
增加多轮对话管理:目前的实现可能只是简单的一轮对话,即用户输入一个问题,模型返回一个回答。为了实现更自然、流畅的交互体验,可以增加多轮对话管理功能。
对话历史记录与关联:记录每一轮对话的内容,包括用户的提问和模型的回答。在新的一轮对话中,将之前的对话历史作为上下文信息传递给模型,使模型能够更好地理解用户的意图。例如,在用户连续提问时,模型可以根据之前的问题和回答,更准确地回答后续问题。可以使用一个数组来存储对话历史,每个元素包含用户和模型的消息:
const conversationHistory = [];
function addToConversationHistory(userMessage, modelAnswer) {
conversationHistory.push({ role: 'user', content: userMessage });
conversationHistory.push({ role: 'assistant', content: modelAnswer });
}
- 对话状态跟踪:跟踪对话的状态,例如是否正在进行某个特定的任务或主题讨论。根据对话状态,调整模型的回答策略和提供的信息。比如,在用户进行旅游规划的多轮对话中,模型可以根据之前讨论的目的地、时间、预算等信息,逐步完善旅游方案的推荐。可以使用一个状态机来管理对话状态,根据不同的用户输入和模型输出,切换对话状态:
// 定义对话状态
const CONVERSATION_STATE = {
START: 'START',
DESTINATION_SELECTED: 'DESTINATION_SELECTED',
DATE_SELECTED: 'DATE_SELECTED',
// 其他状态...
};
let currentState = CONVERSATION_STATE.START;
function updateConversationState(input, output) {
// 根据输入和输出更新对话状态
if (currentState === CONVERSATION_STATE.START && input.includes('想去旅游')) {
currentState = CONVERSATION_STATE.DESTINATION_SELECTED;
}
// 其他状态更新逻辑...
}
- 支持更多模型参数设置:在现有基础上,进一步拓展支持更多的模型参数设置,让开发者能够根据具体需求灵活调整模型的行为。
- 增加参数设置界面:在前端应用中,提供一个可视化的参数设置界面,让用户或开发者可以方便地调整模型参数。例如,在一个智能写作辅助工具中,用户可以根据自己的写作风格和需求,调整模型的temperature、max_tokens(最大生成词数)等参数。可以使用 Ant Design X 的表单组件来创建参数设置界面,用户在表单中输入参数值,然后通过点击提交按钮将参数应用到模型请求中。
- 动态参数调整:允许在对话过程中动态调整模型参数。例如,在用户对模型生成的文本不满意时,可以让用户通过点击按钮或输入特定指令,动态调整temperature参数,重新生成文本。这样可以提高用户对模型输出的控制能力,满足不同用户的多样化需求。可以在前端代码中监听用户的操作事件,根据用户的选择动态修改模型请求中的参数:
function handleParameterChange(parameter, value) {
// 根据用户选择的参数和值,更新模型请求参数
if (parameter === 'temperature') {
requestParams.temperature = value;
}
// 其他参数处理...
}
- 集成语音交互:为了提供更便捷、多样化的交互方式,可以集成语音交互功能,实现语音输入和语音输出。
- 语音输入:利用浏览器的 Web Speech API,实现语音识别功能,将用户的语音输入转换为文本,然后发送给 Qwen 模型进行处理。例如,在一个智能客服应用中,用户可以通过语音提问,无需手动输入文字,提高交互效率。在前端代码中,使用SpeechRecognition对象来实现语音识别:
const recognition = new window.SpeechRecognition();
recognition.lang = 'zh - CN';
recognition.interimResults = false;
recognition.onresult = function (event) {
const userSpeech = event.results[0][0].transcript;
// 将语音识别结果发送给模型
sendMessageToModel(userSpeech);
};
recognition.start();
- 语音输出:使用SpeechSynthesis对象,将模型返回的文本回答转换为语音输出,让用户可以通过听来获取答案。例如,在一个智能语音助手应用中,用户可以在不方便看屏幕时,通过语音输出获取信息。在前端代码中,创建SpeechSynthesisUtterance对象,并设置相关属性,如语音、语速、音量等,然后使用speechSynthesis.speak()方法播放语音:
function speakAnswer(answer) {
const utterance = new window.SpeechSynthesisUtterance(answer);
utterance.lang = 'zh - CN';
utterance.volume = 1;
utterance.rate = 1;
utterance.pitch = 1;
window.speechSynthesis.speak(utterance);
}
七、总结与展望

(一)总结
在本次探索中,我们深入了解了 Ant Design X 与 QWen 大模型结合的强大潜力。Ant Design X 凭借其基于 RICH 交互范式的设计,为 AI 界面开发提供了丰富的原子组件、高效的数据流管理以及开箱即用的模型集成能力,大大简化了 AI 交互界面的搭建过程。而 QWen 大模型作为强大的语言处理工具,具备多任务处理能力、大规模训练和高效架构等优势,能够准确理解和生成自然语言,为前端应用注入了强大的智能交互能力。
通过将 Ant Design X 与 QWen 大模型相结合,我们成功实现了前端界面与智能模型的无缝对接。在实战过程中,通过配置请求参数、设置模型调度以及实现用户输入与交互等步骤,完成了用 Ant Design X 调用 QWen 大模型的功能。用户可以在前端界面输入问题,QWen 大模型能够快速给出准确的回答,实现了智能对话的效果。同时,我们还对性能进行了优化,通过网络请求优化、缓存策略以及模型配置优化等措施,提高了应用的响应速度和用户体验。在功能拓展方面,增加了多轮对话管理、支持更多模型参数设置以及集成语音交互等功能,进一步提升了应用的实用性和交互性。
(二)展望
未来,随着技术的不断发展,Ant Design X 与 QWen 大模型的结合将在更多复杂场景中展现出巨大的应用潜力。在智能客服领域,通过持续优化多轮对话管理和语义理解能力,能够实现更加智能、高效的客户服务,快速准确地解答用户的问题,提高客户满意度。在智能写作辅助方面,借助 QWen 大模型强大的语言生成能力,结合 Ant Design X 的交互组件,可以为用户提供更加智能、便捷的写作体验,例如实时语法检查、内容推荐、文章润色等功能,帮助用户提高写作效率和质量。
在技术发展方向上,一方面,随着硬件性能的提升和算法的优化,QWen 大模型将不断进化,具备更强的语言处理能力和更广泛的应用场景适应性。这将使得 Ant Design X 与之结合的应用能够实现更加复杂和智能的功能,如智能图像生成、数据分析与可视化等跨领域应用。另一方面,Ant Design X 也将不断完善和扩展其功能,提供更多样化的组件和更灵活的定制化选项,以满足不同开发者和用户的需求。同时,随着人工智能技术的普及,Ant Design X 与 QWen 大模型的结合将在更多行业得到应用,推动各行业的数字化转型和智能化升级。
八、参考资料
Ant Design X 官方文档
Qwen 大模型官方文档
DashScope 平台文档

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)