CoRL2025 爆火!12 篇 Oral 论文拆解具身智能突破:灵巧抓取、仿人平衡,真实机器人任务成功率飙升
CoRL 2025(Conference on Robot Learning 2025)作为聚焦机器人与机器学习交叉领域的旗舰会议,近日于 2025 年 9 月 27 日至 30 日在韩国首尔 COEX 会展中心举办CoRL与同馆联办形成 “机器人学习 + 人形机器人” 的交流场景,会议主题涵盖操作、感知、规划与安全、运动控制、人形机器人与硬件等方向,9 月 27 日为工作坊,28 日至 30 日
CoRL 2025(Conference on Robot Learning 2025)作为聚焦机器人与机器学习交叉领域的旗舰会议,近日于 2025 年 9 月 27 日至 30 日在韩国首尔 COEX 会展中心举办
CoRL与 IEEE-RAS Humanoids 2025 同馆联办形成 “机器人学习 + 人形机器人” 的交流场景,会议主题涵盖操作、感知、规划与安全、运动控制、人形机器人与硬件等方向,9 月 27 日为工作坊,28 日至 30 日为主会。

下面我给大家介绍几篇精彩的Oral论文~有需要更多CoRL2025会议论文可领取
一、灵巧抓取与杂乱场景操作
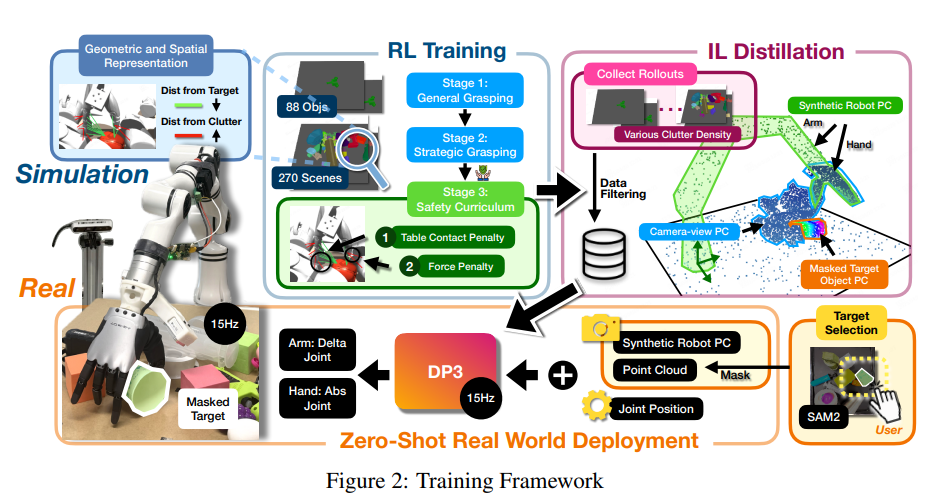
1、ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
作者:Zeyuan Chen, Qiyang Yan, Yuanpei Chen, Tianhao Wu, Jiyao Zhang, Zihan Ding, Jinzhou Li, Yaodong Yang, Hao Dong
亮点:提出两阶段师生框架,教师策略在仿真中通过杂乱密度课程学习训练,融合几何与空间嵌入场景表示及安全课程;学生策略为基于部分点云观测的3D扩散策略(DP3),实现杂乱场景下目标导向灵巧抓取的零样本Sim-to-Real闭环部署,是该领域首个此类系统。
关键词:Cluttered Scene(杂乱场景), Dexterous Grasping(灵巧抓取), Sim-to-Real(仿真到现实迁移)
论文:https://openreview.net/forum?id=4XKKUifQ9c#discussion
代码:https://clutterdexgrasp.github.io/
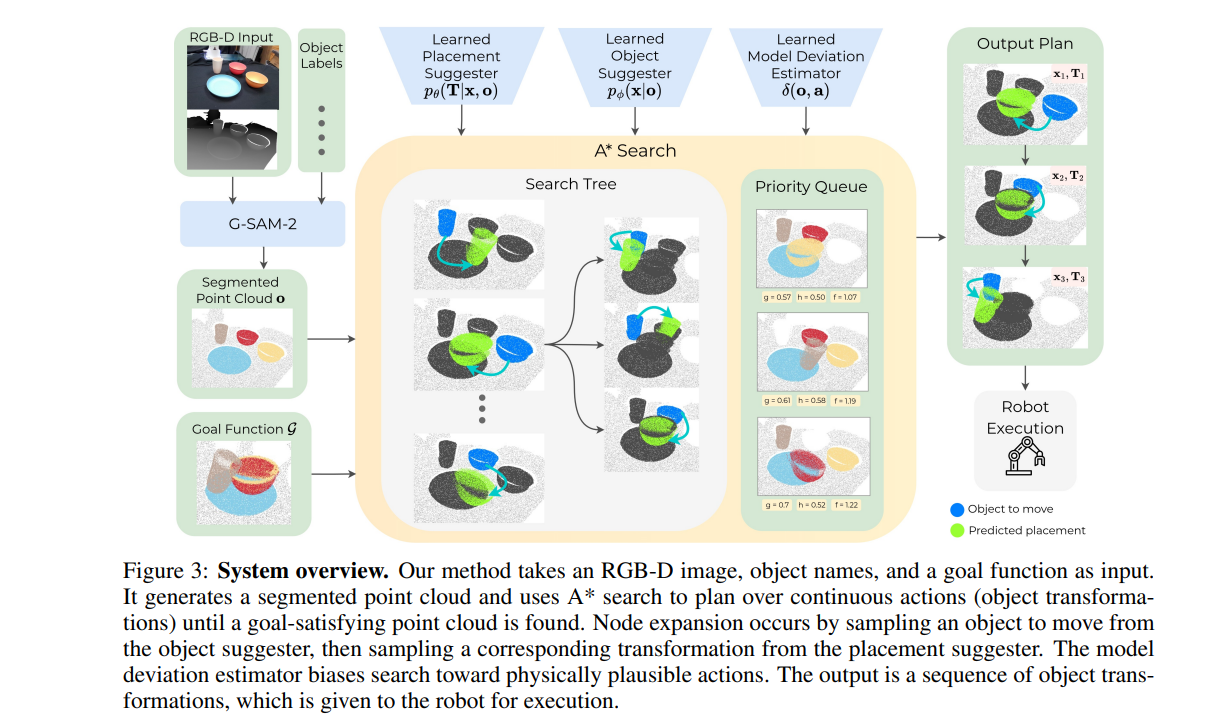
2、Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement
作者:Kallol Saha, Amber Li, Angela Rodriguez-Izquierdo, Lifan Yu, Ben Eisner, Maxim Likhachev, David Held
亮点:无需离散化动作或物体关系,直接以部分观测点云作为输入,将规划问题转化为A*搜索,通过学习的领域特定先验采样点云变换,寻找从初始状态到目标状态的变换序列,在真实多步骤餐桌清理和仿真积木堆叠任务中表现优于策略学习方法。
关键词:Robot Learning(机器人学习), Robot Planning(机器人规划)
论文:https://openreview.net/forum?id=XF69ltYlMU
代码:https://planning-from-point-clouds.github.io/
二、关节物体识别与操作
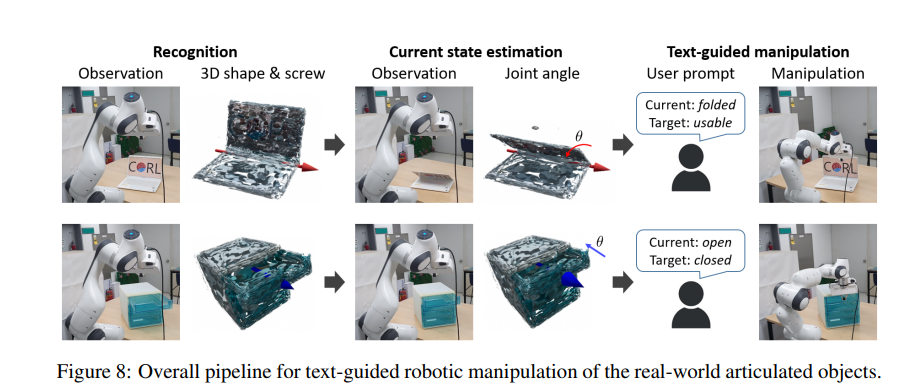
3、ScrewSplat: An End-to-End Method for Articulated Object Recognition
作者:Seungyeon Kim, Junsu HA, Young Hun Kim, Yonghyeon Lee, Frank C. Park
亮点:仅依赖RGB观测的端到端框架,通过随机初始化螺旋轴并迭代优化恢复物体运动学结构,结合高斯溅射(Gaussian Splatting)同步重建3D几何形状并将物体分割为刚性可动部件,在多种关节物体上实现最先进识别精度,还支持基于恢复运动学模型的零样本文本引导操作。
关键词:Articulated objects(关节物体), Gaussian splatting(高斯溅射), Screw theory(螺旋理论)
论文:https://openreview.net/forum?id=gD6YV5OuW3
三、仿人机器人控制与平衡
4、Visual Imitation Enables Contextual Humanoid Control
作者:Arthur Allshire, Hongsuk Choi, Junyi Zhang, David McAllister, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, Angjoo Kanazawa
亮点:提出VideoMimic的Real-to-Sim-to-Real流水线,挖掘日常人类运动视频,联合重建人类与环境,生成仿人机器人全身控制策略;在真实仿人机器人上实现楼梯上下、桌椅坐姿切换等鲁棒上下文控制,单一策略可响应环境与全局根指令完成多种动态全身技能。
关键词:Visual Imitation(视觉模仿), Humanoids(仿人机器人), Reinforcement Learning(强化学习), Reconstruction(重建), Real2Sim2Real(现实到仿真再到现实)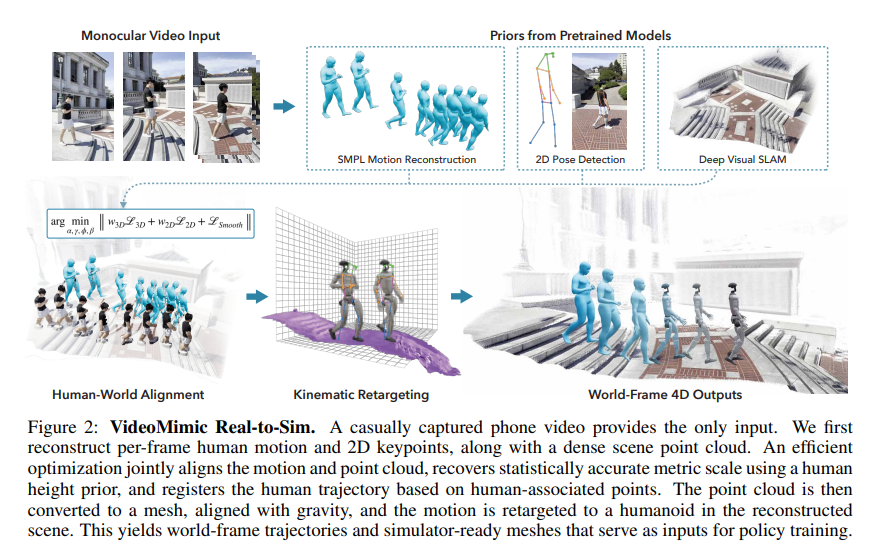
论文:https://openreview.net/forum?id=C6VxzSpjrv
代码:https://videomimic.net/
5、HuB: Learning Extreme Humanoid Balance
作者:Tong Zhang, Boyuan Zheng, Ruiqian Nai, Yingdong Hu, Yen-Jen Wang, Geng Chen, Fanqi Lin, Jiongye Li, Chuye Hong, Koushil Sreenath, Yang Gao
亮点:针对仿人机器人平衡密集任务的三大挑战(参考运动误差导致的不稳定性、形态不匹配导致的学习困难、传感器噪声与未建模动力学导致的Sim-to-Real差距),提出集成参考运动优化、平衡感知策略学习、Sim-to-Real鲁棒性训练的统一框架;在Unitree G1机器人上完成“燕子平衡”“李小龙踢腿”等极端单腿姿态任务,且能抵抗强力干扰。
关键词:Humanoid Whole-body Control(仿人机器人全身控制), Balance Control(平衡控制), Reinforcement Learning(强化学习)
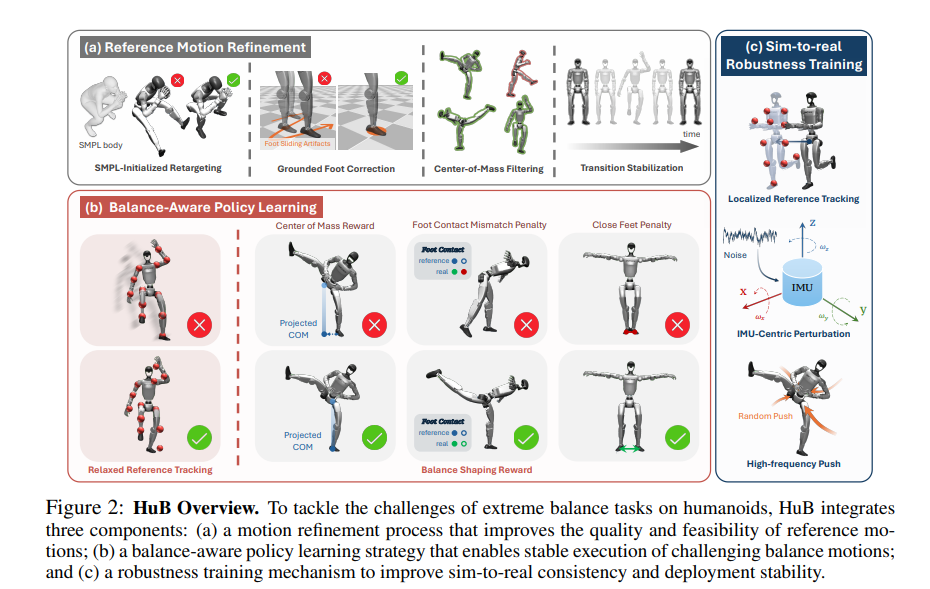
论文:https://openreview.net/forum?id=FCpYuGtN4j
项目:https://hub-robot.github.io/
四、Sim-to-Real迁移与系统识别
6、Sampling-based System Identification with Active Exploration for Legged Sim2Real Learning
作者:Nikhil Sobanbabu, Guanqi He, Tairan He, Yuxiang Yang, Guanya Shi
亮点:提出SPI-Active两阶段框架,通过大规模并行采样鲁棒识别腿式机器人关键物理参数,最小化仿真与现实轨迹的状态预测误差;引入主动探索策略,通过优化探索策略输入指令最大化采集轨迹的Fisher信息,在四足和仿人机器人多种运动任务中,Sim-to-Real迁移性能比基线提升42%-63%。
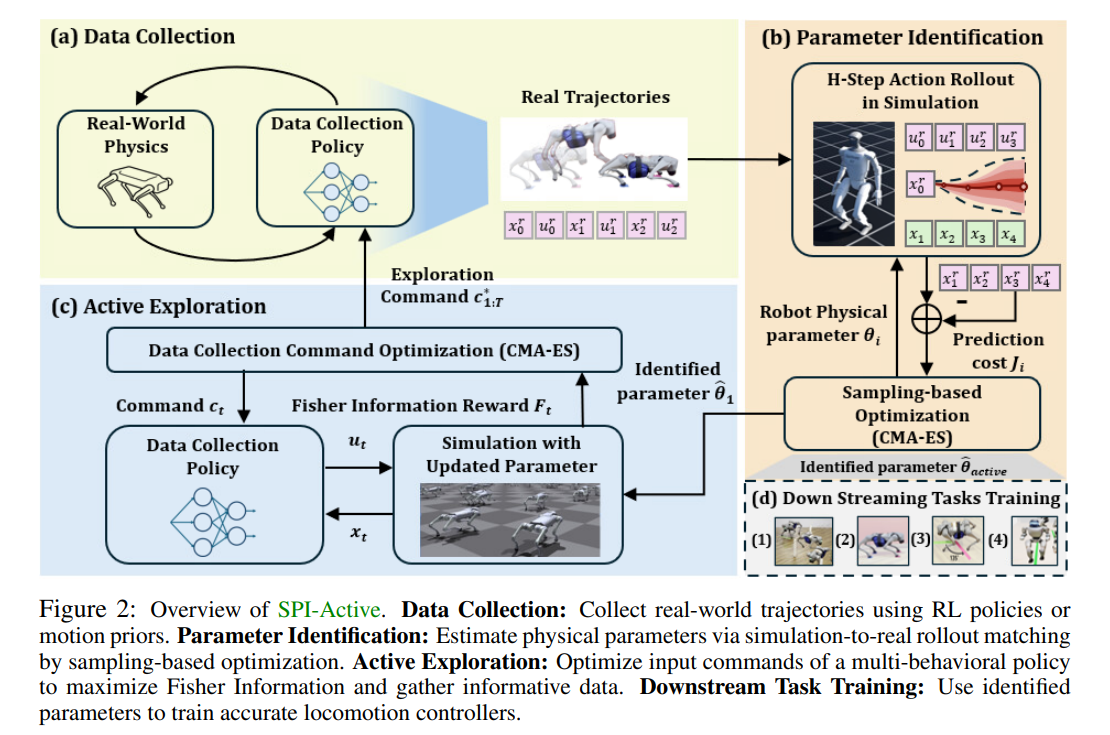
关键词:System Identification(系统识别), Sim2Real(仿真到现实迁移), Legged Robots(腿式机器人)
论文:https://openreview.net/forum?id=UTPBM4dEUS
代码:https://github.com/LeCAR-Lab/SPI-Active
7、X-Sim: Cross-Embodiment Learning via Real-to-Sim-to-Real
作者:Prithwish Dan, Kushal Kedia, Angela Chao, Edward Duan, Maximus Adrian Pace, Wei-Chiu Ma, Sanjiban Choudhury
亮点:以物体运动作为密集可迁移信号,从RGBD人类视频重建照片级真实仿真并跟踪物体轨迹定义物体中心奖励,在仿真中训练RL策略,再通过合成rollout蒸馏为图像条件扩散策略;引入在线域适应技术实现现实迁移,无需机器人遥操作数据,在5个操作任务中比手跟踪和Sim-to-Real基线平均提升30%任务进度。
关键词:Learning from Human Videos(从人类视频学习), Sim-to-Real(仿真到现实迁移), Representation Learning(表示学习)
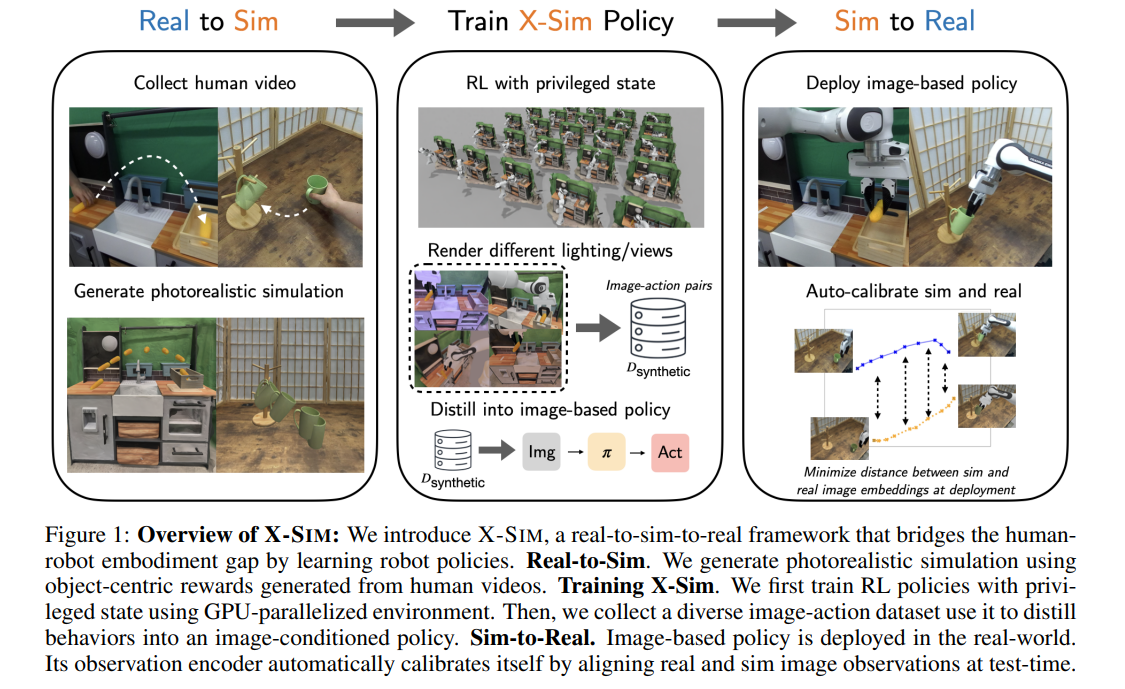
论文:https://openreview.net/forum?id=BO7qo66YJ2
代码:https://portal-cornell.github.io/X-Sim/
五、触觉感知与多模态融合
8、Tactile Beyond Pixels: Multisensory Touch Representations for Robot Manipulation
作者:Carolina Higuera, Akash Sharma, Taosha Fan, Chaithanya Krishna Bodduluri, Byron Boots, Michael Kaess, Mike Lambeta, Tingfan Wu, Zixi Liu, Francois Robert Hogan, Mustafa Mukadam
亮点:提出首个跨四种触觉模态(图像、音频、惯性测量IMU、压力)的自监督通用触觉表示TacX,基于Digit 360传感器的约100万次接触密集交互数据训练;在模仿学习和仿真策略触觉适应任务中,比仅用触觉图像的端到端模型提升63%策略成功率,在物理属性推断任务中比端到端方法提升48%准确率。
关键词:Multi-sensory Touch(多模态触觉), Self-Supervised Learning(自监督学习), Tactile Adaptation(触觉适应)
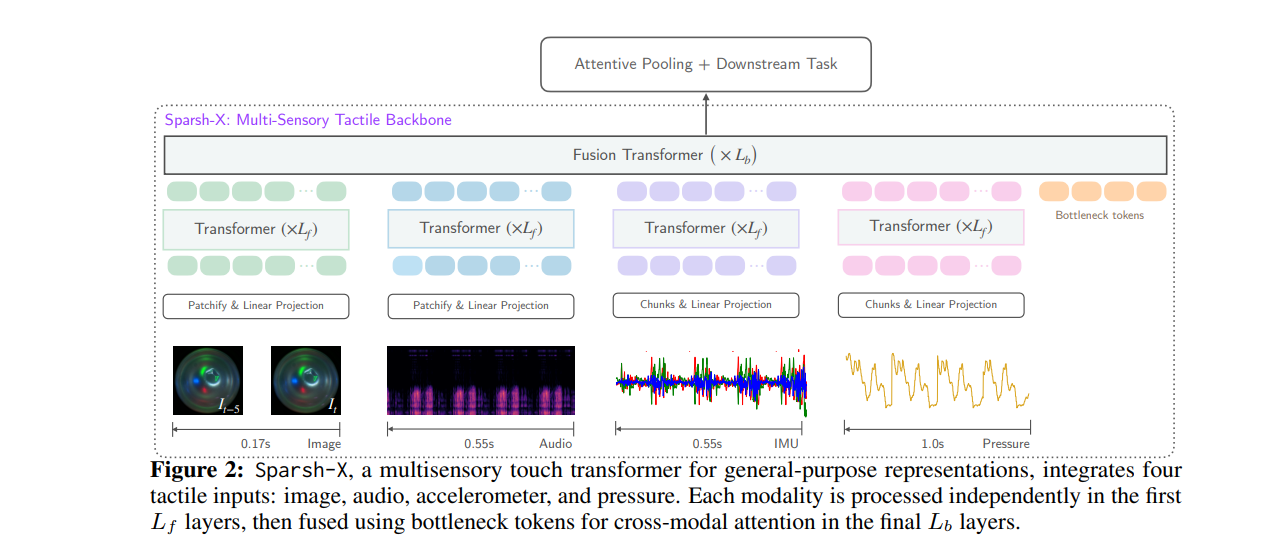
论文:https://openreview.net/forum?id=sMs4pJYhWi
9、DexSkin: High-Coverage Conformable Robotic Skin for Learning Contact-Rich Manipulation
作者:Suzannah Wistreich, Baiyu Shi, Stephen Tian, Samuel Clarke, Michael Nath, Chengyi Xu, Zhenan Bao, Jiajun Wu
亮点:开发柔软、可贴合的电容式电子皮肤DexSkin,实现敏感、局部化、可校准的触觉感知,可适配不同几何形状;将其用于平行颚夹爪手指,覆盖几乎整个手指表面,在“手中物体重定向”“橡皮筋缠绕盒子”等接触密集任务的演示学习中表现优异,且支持传感器间模型迁移与在线RL训练。
关键词:tactile sensing(触觉感知), contact-rich manipulation(接触密集型操作)

论文:https://openreview.net/forum?id=DhjvVzPHiP
10、Cross-Sensor Touch Generation
作者:Samanta Rodriguez, Yiming Dou, Miquel Oller, Andrew Owens, Nima Fazeli
亮点:提出两种跨传感器触觉图像生成模型,Touch2Touch利用配对数据实现端到端跨传感器迁移,T2D2通过中间深度表示实现无配对数据迁移;两种模型均支持特定传感器模型跨多个传感器使用,在杯子堆叠、工具插入等下游任务中,成功将为一种传感器设计的模型迁移到另一种传感器。
关键词:Tactile Sensing(触觉感知), Cross-Modal Generation(跨模态生成), Manipulation(操作), Representation Learning(表示学习)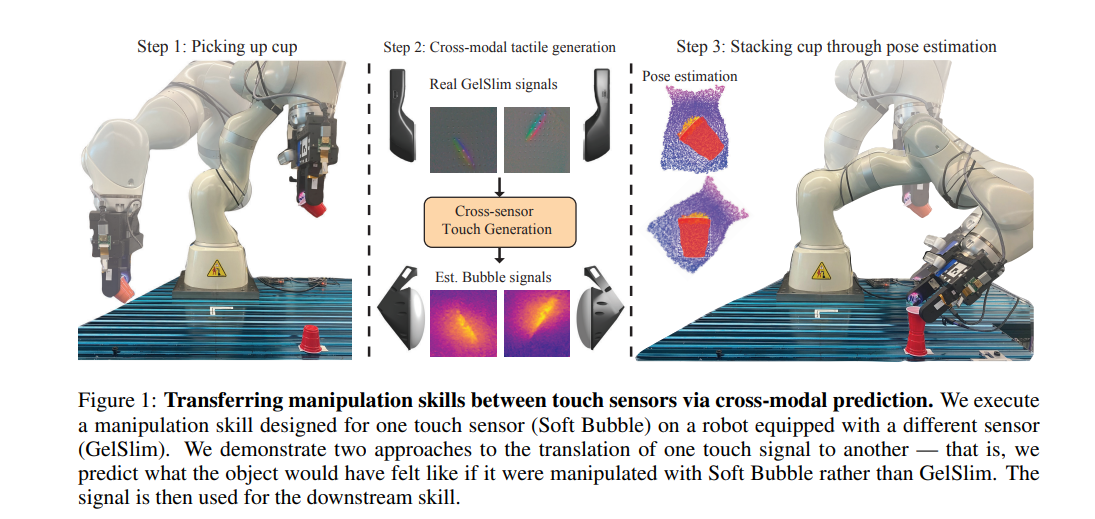
论文:https://openreview.net/forum?id=oGcC8nMOit
代码:https://samantabelen.github.io/cross_sensor_touch_generation
六、模仿学习加速与效率优化
11、DemoSpeedup: Accelerating Visuomotor Policies via Entropy-Guided Demonstration Acceleration
作者:Lingxiao Guo, Zhengrong Xue, Zijing Xu, Huazhe Xu
亮点:提出自监督方法DemoSpeedup,先在正常速度演示上训练生成式策略作为每帧动作熵估计器;根据熵值分割演示数据,高熵帧(非关键步骤)可安全下采样加速,低熵帧(高精度操作步骤)保持原速;训练后的策略执行速度最高提升3倍,且因决策 horizon 缩短,部分任务成功率甚至高于正常速度策略。
关键词:Imitation learning(模仿学习), Manipulation(操作), Demonstration Acceleration(演示加速)
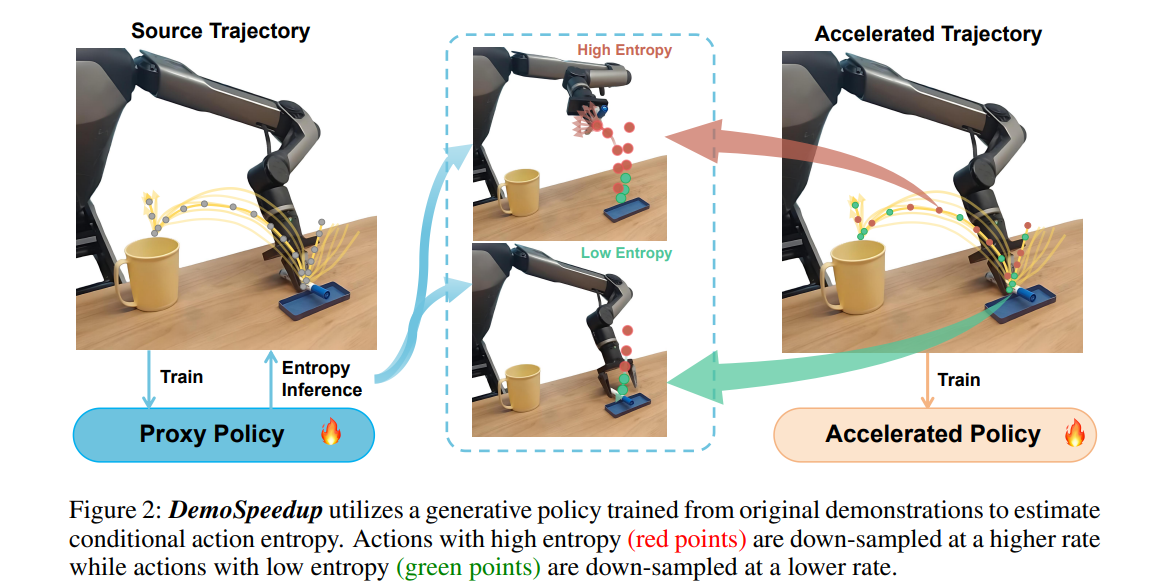
论文:https://openreview.net/forum?id=Tl7girqoLi
12、SAIL: Faster-than-Demonstration Execution of Imitation Learning Policies
作者:Nadun Ranawaka Arachchige, Zhenyang Chen, Wonsuhk Jung, Woo Chul Shin, Rohan Bansal, Pierre Barroso, Yu Hang He, Yingyan Celine Lin, Benjamin Joffe, Shreyas Kousik, Danfei Xu
亮点:首次形式化“模仿学习策略超演示速度执行”问题,提出SAIL全栈系统,包含保一致性动作推理(高速平滑运动)、控制器不变运动目标高保真跟踪、基于运动复杂度的自适应速度调制、系统延迟处理动作调度四大组件;在仿真和两种真实机器人平台的12个任务中,仿真速度提升达4倍,真实场景提升达3.2倍。
关键词:Visuomotor Imitation(视觉运动模仿), Robot Learning Systems(机器人学习系统), Robotic Manipulation(机器人操作), Speed Adaptive Execution(速度自适应执行)
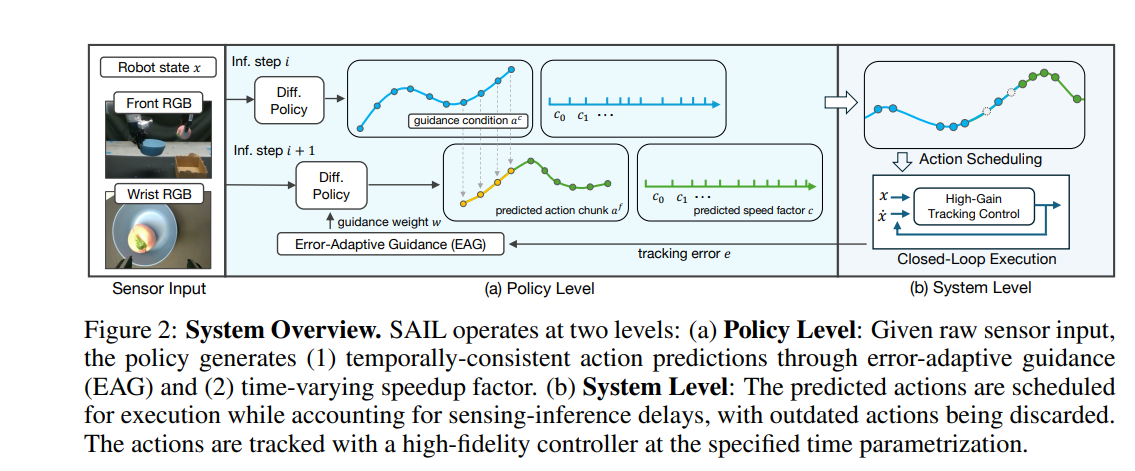
论文:https://openreview.net/forum?id=EGSSHukI05
代码:https://nadunranawaka1.github.io/sail-policy

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)