comfyui下使用GPU加速insightface工作流常见故障排查
comfyui下使用GPU加速insightface工作流常见故障排查
Comfyui中为什么要使用CUDA加速insightface
因为使用后,人脸识别、迁移速度更快,精度更高
insightface、onnxruntime、CUDA、cuDNN之间的使用逻辑是什么?
当你运行 insightface(ONNX 格式模型)时:onnxruntime-GPU 解析你的 insightface 模型,拆分出卷积、特征提取等计算任务;onnxruntime-GPU 调用 cuDNN,将这些计算任务交给 cuDNN 的优化函数;cuDNN 通过 CUDA 接口,把计算任务分配到 GPU 的并行计算核心上执行;最终 GPU 完成计算,将结果返回给 onnxruntime-GPU,再输出到 ComfyUI 中。
即 底层是CUDA——GPU 的 “并行计算接口” ,中间层是cuDNN—— 基于 CUDA 的 “深度学习专用优化库”,上层是onnxruntime-GPU——“ONNX 模型的推理引擎”
那么就需要安装CUDA、cudnn、onnxruntime,他们之间互相依赖,非常容易出现问题。
安装环节问题归纳
1.版本兼容问题
首先查阅onnxruntime的官方网站有兼容详解,一定要兼容,否则无法正常运行
https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements
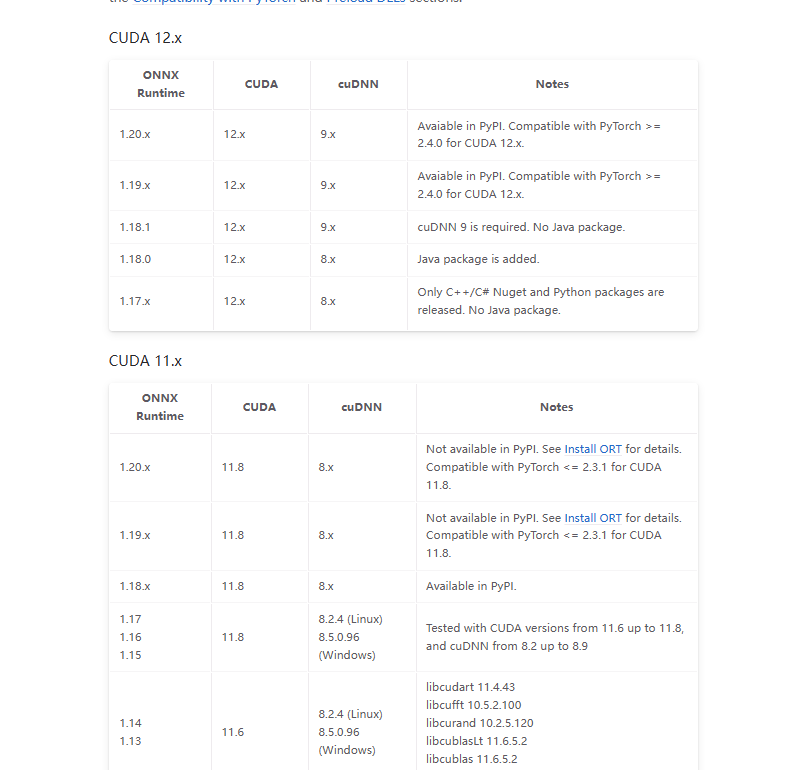
确定好版本后挨个下载,一定不要安装错误版本。
2.环境变量问题
系统变量CUDA_PATH_V12_4:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4
注意:这个路径打开后一定要包含bin及其他文件
Path变量C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin
只需配置这两个环境变量即可。
配置环境变量的目的是让系统找到 cuDNN 和 CUDA 的库文件。
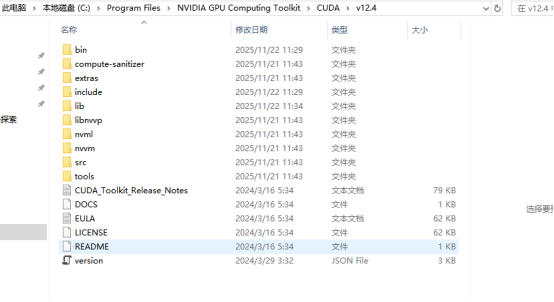
3.CUDA加载cuDNN库,
需要将cuDNN路径下的bin、include、lib下的文件复制进CUDA路径下的对应文件夹中去(注意不要挪错位置、少挪文件),如下图所示。
bin下的文件结构
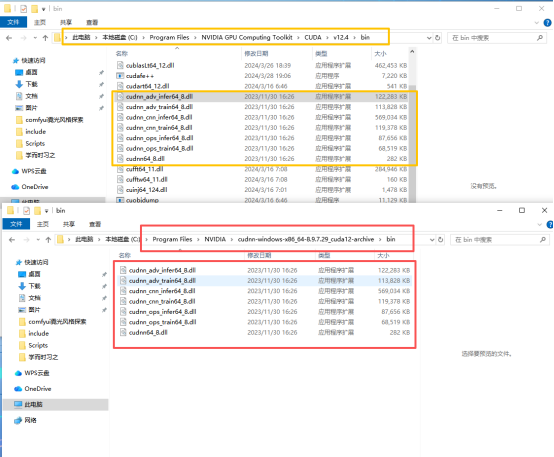
include下的文件结构
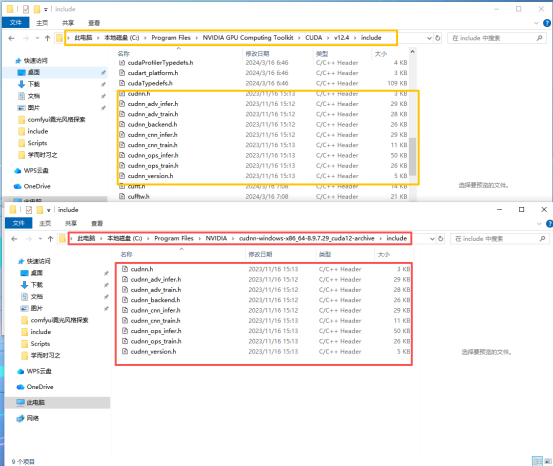
lib下的文件结构
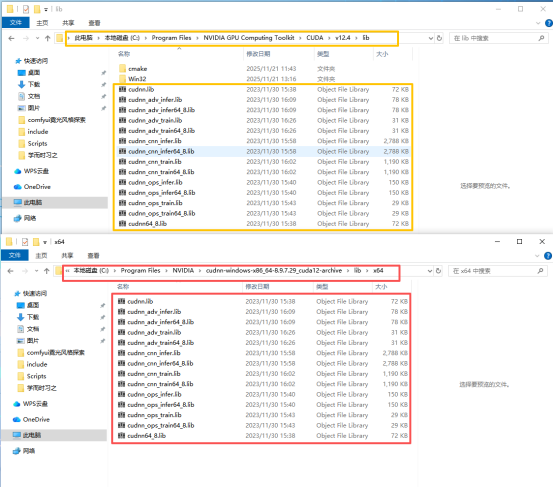
4.一定要删除onnxruntime CPU版本,只留下GPU版本
执行命令,查看目前有几个onnxruntime的版本,pip list | findstr "onnxruntime"
正确结果示例:onnxruntime-gpu 1.18.0(以你的版本号为准)
若仍显示onnxruntime(无-gpu后缀),说明 CPU 版未删干净,需重新执行卸载命令。
进入python环境,执行卸载命令 pip uninstall onnxruntime -y ,
然后再下载GPU版本的,命令pip install onnxruntime-gpu==1.18.0(以你的兼容版本号为准)
5.验证环节
1.验证onnxruntime加载CUDA是否成功
进入你的python环境,
import onnxruntime as ort
# 检查是否识别到CUDA执行提供者(依赖cuDNN)
print("是否加载CUDA+cuDNN:", "CUDAExecutionProvider" in ort.get_available_providers())
成功结果:输出True,说明 onnxruntime 已成功加载 CUDA 和 cuDNN。

2.验证insightface
启动comfyui使用Face Analysis Models、IPAdapter Unified Loader faceID这两个节点并开启provider:CUDA,可明显看到运行速度变快,且人脸识别迁移精度更高。
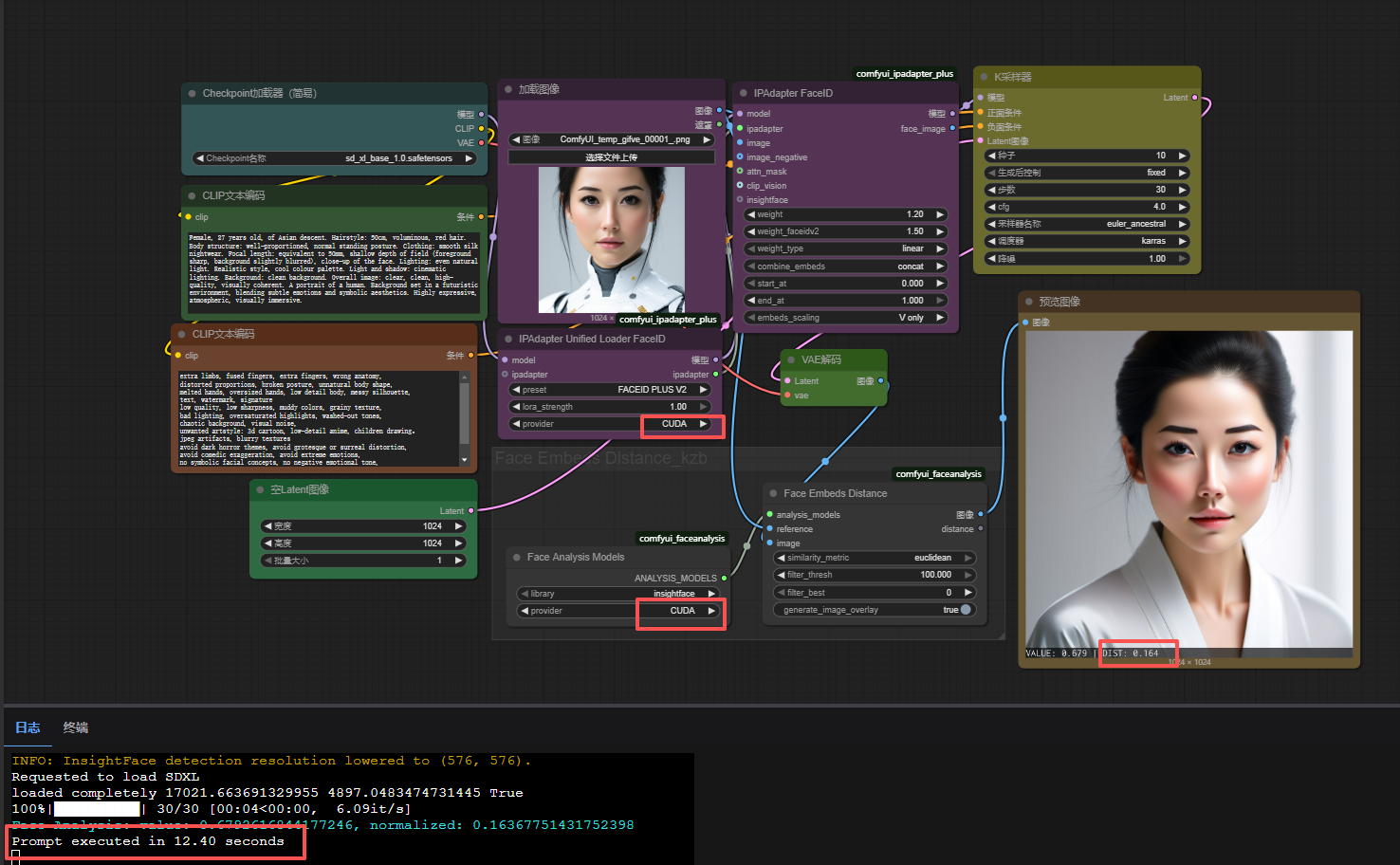
在不是CUDA之前,速度为100多秒(本环境为4090显卡)。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)