ASR+TTS实现AI大模型双向语音(大模型多模态开发)
摘要 本文探讨大模型多模态开发的技术路线,重点聚焦语音处理方向。整体采用模块化架构,将不同能力侧重的模型组合使用,如语音识别(ASR)和语音合成(TTS)模型。以豆包AI大模型为例,详细介绍了端到端语音处理流程:通过base64编码转换音频格式,使用AUC bigmodel API进行语音解析,并实现临时文件上传和URL获取功能。技术实现包含音频格式转换、API调用配置等关键环节,展示了多模态系统
·
概要
浅谈对于大模型多模态开发的技术线路(语音)。
整体架构流程
目前的大模型多模态技术实现路径基本上是使用不同能力侧重的模型进行统合开发.
例如,某个模型侧重有很强的语音生成能力,但是对于文本理解效果不佳。那么我们可以将其作为大模型多模态中的TTS部分进行使用。
这里基于豆包AI大模型语音进行端到端全链路架构设计。
技术名词解释
- ASR:语音识别,将语音精准转换为文字
- TTS:语音合成,将文字生成为语音
- 豆包AI:火山引擎旗下的旗舰大模型
- 多模态:利用多种不同形式或感知渠道的信息进行表达、交流和理解的方式,通常包括视觉、听觉、文本、触觉等多种感官输入和输出方式。
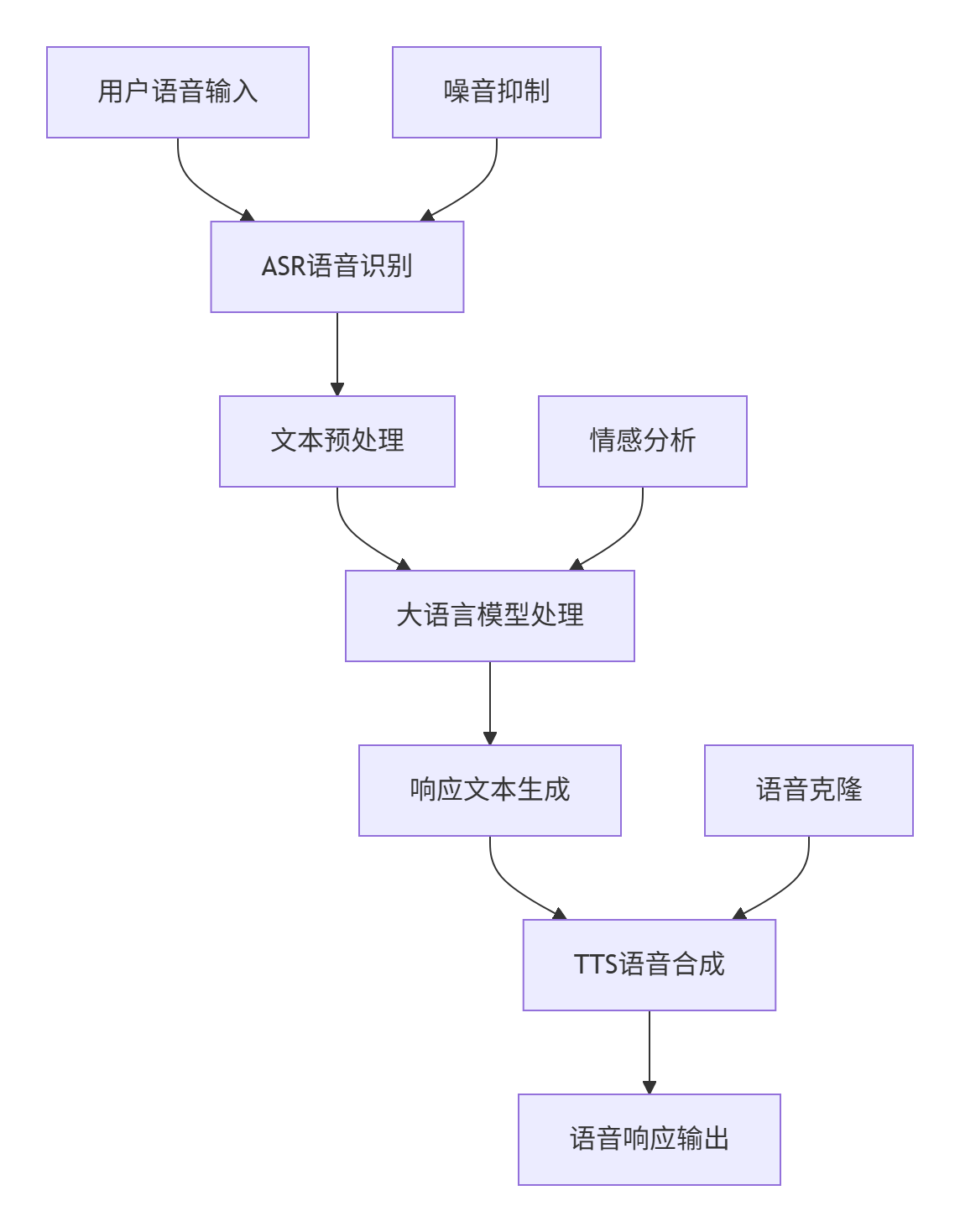
技术细节
ASR流程,这里可以使用多种技术,我们本次以豆包为例
#首先将传入的语音转为base64编码
def _ensure_wav_base64(pcm_b64: str, sample_rate: int, channels: int = 1, bits_per_sample: int = 16) -> str:
try:
raw = base64.b64decode(pcm_b64)
except Exception:
return pcm_b64
if len(raw) >= 12 and raw[0:4] == b'RIFF' and raw[8:12] == b'WAVE':
return pcm_b64 # 已是 WAV
data = raw
subchunk2_size = len(data)
audio_format = 1 # PCM
byte_rate = sample_rate * channels * bits_per_sample // 8
block_align = channels * bits_per_sample // 8
chunk_size = 36 + subchunk2_size
header = b''.join([
b'RIFF', struct.pack('<I', chunk_size), b'WAVE',
b'fmt ', struct.pack('<I', 16), struct.pack('<H', audio_format), struct.pack('<H', channels),
struct.pack('<I', sample_rate), struct.pack('<I', byte_rate), struct.pack('<H', block_align), struct.pack('<H', bits_per_sample),
b'data', struct.pack('<I', subchunk2_size)
])
wav_bytes = header + data
return base64.b64encode(wav_bytes).decode('utf-8')
#这里以豆包seed模型为例,使用其AUC bigmodel大模型api进行语音解析
def transcribe():
"""使用 AUC bigmodel submit/query 方式转写。
"""
body = request.get_json(silent=True) or {}
# 1. 与 transcribe copy 相同的接收方式 (multipart 或 JSON base64),并支持裸 PCM -> WAV
sample_rate = body.get('sampleRate') or body.get('sample_rate') or 16000
try:
sample_rate = int(sample_rate)
except Exception:
sample_rate = 16000
if sample_rate not in (8000, 16000, 44100, 48000):
sample_rate = 16000
audio_b64 = None
upload_filename_ext = '.wav'
if body:
audio_obj = body.get('audio') or {}
audio_b64 = audio_obj.get('data') or body.get('audio_base64') or body.get('base64') or body.get('pcm_base64')
if not audio_b64 and request.files:
for k in ('file','audio','upload','data'):
if k in request.files:
f = request.files[k]
raw = f.read()
if not raw:
return jsonify({'error':'empty_file'}), 400
if len(raw) > 10 * 1024 * 1024:
return jsonify({'error':'file_too_large','limit_mb':10}), 400
audio_b64 = base64.b64encode(raw).decode('utf-8')
# 推测扩展名
fn = f.filename or ''
if '.' in fn:
ext = '.' + fn.rsplit('.',1)[-1].lower()
if len(ext) <= 6:
upload_filename_ext = ext
break
if not audio_b64:
return jsonify({'error':'missing_base64'}), 400
# 裸 PCM 转 wav base64
wrapped_b64 = _ensure_wav_base64(audio_b64, sample_rate, channels=1, bits_per_sample=16)
try:
audio_bytes = base64.b64decode(wrapped_b64)
except Exception:
return jsonify({'error':'decode_failed'}), 400
# 2. 写入临时文件并上传到 SAS 获得可访问 URL
try:
with tempfile.NamedTemporaryFile(delete=False, suffix=upload_filename_ext) as tmpf:
tmpf.write(audio_bytes)
tmp_path = tmpf.name
up_res = upload_audio_to_sas(tmp_path, prefix='asr/uploads')
finally:
try:
if 'tmp_path' in locals() and os.path.isfile(tmp_path):
os.remove(tmp_path)
except Exception:
pass
if not up_res.get('ok'):
return jsonify({'error':'upload_failed','detail': up_res}), 500
audio_url = up_res.get('url')
#这里的配置替换为真实的字节key
cfg = get_settings()
appid = cfg.get('VOLCANO_O_SAUC_APP_ID') or cfg.get('VOLCANO_O_SAUC_APP_KEY')
token = cfg.get('VOLCANO_O_SAUC_ACCESS_KEY')
resource_id = cfg.get('VOLCANO_ASR_RESOURCE_ID') or 'volc.bigasr.auc'
submit_url = cfg.get('VOLCANO_ASR_SUBMIT_URL') or cfg.get('VOLCANO_ASR_ENDPOINT')
query_url = cfg.get('VOLCANO_ASR_QUERY_URL')
if not appid or not token:
return jsonify({'error': 'missing_asr_keys'}), 500
model_name = body.get('model_name') or 'bigmodel'
return_raw = body.get('return_raw') or False
# 尝试推断格式 (基于 URL 扩展名)
ext_lower = audio_url.split('?')[0].split('.')[-1].lower() if '.' in audio_url else ''
audio_format = ext_lower if ext_lower in ('wav','mp3','m4a','aac','flac','ogg') else None
task_id = str(uuid.uuid4())
submit_headers = {
'X-Api-App-Key': appid,
'X-Api-Access-Key': token,
'X-Api-Resource-Id': resource_id,
'X-Api-Request-Id': task_id,
'X-Api-Sequence': '-1',
'Content-Type': 'application/json'
}
submit_body = {
'user': {'uid': 'fake_uid'},
'audio': ({'url': audio_url, 'format': audio_format} if audio_format else {'url': audio_url}),
'request': {
'model_name': model_name,
'enable_channel_split': True,
'enable_ddc': True,
'enable_speaker_info': True,
'enable_punc': True,
'enable_itn': True,
'corpus': {
'correct_table_name': '',
'context': ''
}
}
}
submit_start = time.time()
try:
submit_resp = requests.post(submit_url, data=json.dumps(submit_body), headers=submit_headers, timeout=20)
except requests.RequestException as e:
return jsonify({'error': 'submit_request_error', 'detail': str(e)}), 500
submit_code = submit_resp.headers.get('X-Api-Status-Code') or submit_resp.headers.get('x-api-status-code')
submit_msg = submit_resp.headers.get('X-Api-Message') or submit_resp.headers.get('x-api-message')
logid = submit_resp.headers.get('X-Tt-Logid') or submit_resp.headers.get('x-tt-logid')
if submit_code != '20000000':
fail_payload = {
'error': 'submit_failed',
'status': submit_code,
'apiMessage': submit_msg,
'requestId': task_id,
'logid': logid
}
if return_raw:
try:
fail_payload['raw'] = submit_resp.json()
except Exception:
pass
fail_payload['timings'] = timings
return jsonify(fail_payload), 502
# 轮询查询
attempts = 0
last_raw = None
query_headers = {
'X-Api-App-Key': appid,
'X-Api-Access-Key': token,
'X-Api-Resource-Id': resource_id,
'X-Api-Request-Id': task_id,
'X-Tt-Logid': logid or ''
}
deadline = time.time() + (poll_timeout_ms / 1000.0)
while True:
attempts += 1
try:
q_resp = requests.post(query_url, json.dumps({}), headers=query_headers, timeout=15)
except requests.RequestException as e:
return jsonify({'error': 'query_request_error', 'detail': str(e), 'requestId': task_id, 'logid': logid}), 500
code = q_resp.headers.get('X-Api-Status-Code') or q_resp.headers.get('x-api-status-code')
try:
last_raw = q_resp.json()
except Exception:
last_raw = None
if code == '20000000':
# 成功
result_text = (last_raw or {}).get('result', {}).get('text') or (last_raw or {}).get('data', {}).get('result', {}).get('text', '')
elapsed = int((time.time() - start) * 1000)
payload = {
'text': result_text,
'status': 'ok',
'requestId': task_id,
'logid': logid,
'elapsed': elapsed,
'attempts': attempts,
'audioUrl': audio_url
}
payload['timings'] = timings
if return_raw and last_raw is not None:
payload['raw'] = last_raw
return jsonify(payload)
# 处理中
if code in ('20000001', '20000002', '55000001'):
if time.time() > deadline:
break
time.sleep(poll_interval_ms / 1000.0)
continue
# 失败
elapsed_fail = int((time.time() - start) * 1000)
fail_payload = {
'error': 'task_failed',
'status': code,
'requestId': task_id,
'logid': logid,
'elapsed': elapsed_fail,
'attempts': attempts
}
if return_raw and last_raw is not None:
fail_payload['raw'] = last_raw
fail_payload['timings'] = timings
return jsonify(fail_payload), 502
# 超时
elapsed_timeout = int((time.time() - start) * 1000)
timeout_payload = {
'error': 'timeout',
'requestId': task_id,
'logid': logid,
'elapsed': elapsed_timeout,
'attempts': attempts
}
if return_raw and last_raw is not None:
timeout_payload['raw'] = last_raw
timeout_payload['timings'] = timings
return jsonify(timeout_payload), 504
NLP流程 ,同样以豆包为例
import os
from volcenginesdkarkruntime import Ark
def AI_Chat(ASR_res,AI_prompt)
#AI_prompt是你需要增强AI的提示词
#ASR_res是ASR流程返回的文本
client = Ark(
base_url="https://ark.cn-beijing.volces.com/api/v3",
api_key=os.environ.get("ARK_API_KEY"),
)
completion = client.chat.completions.create(
model="doubao-seed-1-6-251015",
messages=[
{"role": "system", "content": AI_prompt},
{"role": "user", "content": ASR_res},
]
)
return completion.choices[0].message.content
TTS流程
def tts_route():
cfg = get_settings();
body = request.get_json(force=True);
text = (body.get('text') or '').strip()
if not text:
return jsonify({'error':'text_required','timings': phases}), 400
speaker = body.get('speaker') or 'zh_female_cancan_mars_bigtts'
fmt = body.get('format') or 'mp3'
sample_rate = int(body.get('sample_rate') or 16000 )
additions = body.get('additions') or {
'disable_markdown_filter': True,
'enable_language_detector': True,
'enable_latex_tn': True,
'disable_default_bit_rate': True,
'max_length_to_filter_parenthesis': 0,
'cache_config': { 'text_type': 1, 'use_cache': True }
}
if isinstance(additions, dict):
additions_json = json.dumps(additions, ensure_ascii=False)
else:
additions_json = str(additions)
payload = {
'user': {'uid': 'smart-order-tts'},
'req_params': {
'text': text,
'speaker': speaker,
'additions': additions_json,
'audio_params': {
'format': fmt,
'speech_rate': 0,
'sample_rate': sample_rate
},
'model': 'seed-tts-1.1'
}
}
headers = _build_headers(cfg)
if not headers['X-Api-App-Id'] or not headers['X-Api-Access-Key'] or not headers['X-Api-Resource-Id']:
return jsonify({'error':'missing_tts_keys','timings': phases}), 500
api_url = ''
try:
resp = requests.post(api_url, headers=headers, json=payload, stream=True, timeout=60)
audio_bytes = bytearray()
status = None; err=None
first_chunk_recorded = False
for line in resp.iter_lines(decode_unicode=True):
if not line: continue
try:
obj = json.loads(line)
except Exception:
err = 'invalid_json_line'; break
code = obj.get('code',0)
if code == 0 and obj.get('data'):
try:
audio_bytes.extend(base64.b64decode(obj['data']))
except Exception:
err='chunk_decode_fail'; breakfirst_chunk_recorded = True
elif code == 20000000:
status='ok'; break
elif code != 0:
err = obj.get('message') or f'code_{code}'
break
if err:
logger.warning(f"/api/tts fail detail={err} timings={phases}")
return jsonify({'error':'tts_failed','detail': err,'timings': phases}), 500
if status!='ok':
logger.warning(f"/api/tts incomplete timings={phases}")
return jsonify({'error':'tts_incomplete','timings': phases}), 500
result = {'ok': True, 'format': fmt, 'sample_rate': sample_rate, 'length_bytes': len(audio_bytes)}
# Upload then generate ONE 24h read-only SAS URL
try:
ext = 'mp3' if fmt.lower() == 'mp3' else ('wav' if fmt.lower() == 'wav' else 'bin')
blob_name = f"tts/{int(time.time())}_{len(audio_bytes)}.{ext}"
# short write SAS just for upload (5 min)
upload_sas = generate_blob_sas_url(blob_name, expiry_minutes=5, read=True, write=True)
content_type = 'audio/mpeg' if ext == 'mp3' else ('audio/wav' if ext == 'wav' else 'application/octet-stream')
put_headers = {
'x-ms-blob-type': 'BlockBlob',
'Content-Type': content_type,
'Content-Length': str(len(audio_bytes))
}
put_resp = requests.put(upload_sas, data=bytes(audio_bytes), headers=put_headers, timeout=60)
if put_resp.status_code not in (200, 201):
raise RuntimeError(f"upload_status_{put_resp.status_code}")
# 24h read-only SAS (1440 minutes)
readonly_sas = generate_blob_sas_url(blob_name, expiry_minutes=1440, read=True, write=False)
result['url'] = readonly_sas
result['expires_in_minutes'] = 1440
except Exception as up_e:
result['error'] = 'upload_or_sas_failed'
result['detail'] = str(up_e)
if result.get('error'):
logger.error(f"/api/tts error={result.get('error')} detail={result.get('detail')} timings={phases}")
return jsonify(result)
except requests.RequestException as e:
logger.exception(f"/api/tts request_exception timings={phases}")
return jsonify({'error':'tts_request_error','detail': str(e),'timings': phases}), 500
小结
ASR + TTS + 大模型的结合为人工智能交互打开了新的可能性。随着技术的不断成熟,双向语音交互将成为下一代人机交互的标准范式。开发者需要掌握多模态融合的技术栈,才能在AI应用开发中保持竞争优势。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)