如何基于ROCm本地部署开源模型Gemma3
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained(“google/gemma-3-4b”)model = AutoModelForCausalLM.from_pretrained(“google/gemma-3-4b”, device_map=“

一、Gemma3 模型概述
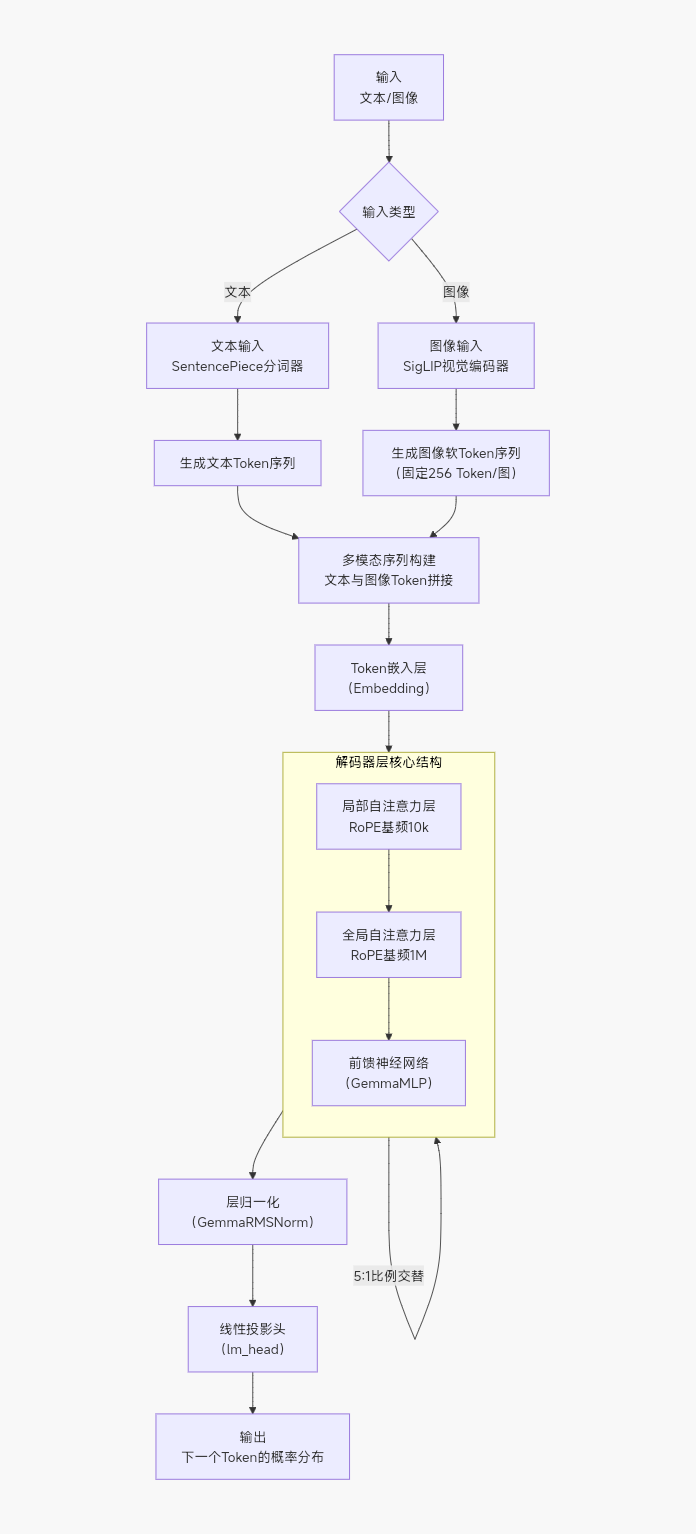
Gemma 3是谷歌2025年3月推出的开源多模态轻量AI模型,基于Gemini技术开发,适配从手机到工作站的多种设备 。它涵盖1B、4B、12B、27B四种参数规模,除1B版仅支持文本外,其余版本均支持图文输入,还具备128K超长上下文、超140种语言支持及函数调用能力,适合多场景开发与部署 。 其模型架构基于解码器-only的Transformer,在继承前代基础上有诸多关键优化,核心细节如下:
- 5:1局部/全局层交错:采用5个局部滑动窗口自注意力层搭配1个全局自注意力层的交替模式,且以局部层为第一层。局部层滑动窗口限定为1024个token,仅处理局部信息,大幅降低KV缓存的内存消耗,全局层则负责处理128K超长上下文的整体关联。
- 注意力与归一化设计:使用分组查询注意力(GQA)提升推理效率,结合RMSNorm归一化方式,并用QK归一化替代前代的软上限设计,优化模型稳定性。
- 多模态适配架构:4B及以上版本搭载400M参数的SigLIP视觉编码器,固定接收896×896分辨率图像输入;通过Pan&Scan算法将非方形、高分辨率图像分割为适配尺寸的裁剪块处理,且编码器训练时保持冻结并在多参数版本间共享。
- 长上下文优化:全局层的RoPE基频从10k提升至1M,局部层维持10k频率,同时通过先32K序列预训练再扩展至128K的方式,保障长上下文场景下的性能稳定。
二、部署Gemma3具体步骤
Gemma 3(Google基于Gemini技术开发的开源轻量模型,且官宣适配AMD ROCm系统) 。其部署优先推荐ROCm优化的vLLM容器(低延迟)或Ollama框架(操作极简),以下是具体步骤: - 部署前置准备 :先确保ROCm版本≥6.1(推荐6.4以适配vLLM对Gemma 3的优化),且GPU为AMD Radeon或Instinct系列。Ubuntu系统可通过命令快速安装ROCm: wget -q -O - https://repo.radeon.com/rocm/rocm.gpg.key | sudo apt-key add -echo ‘deb [arch=amd64] https://repo.radeon.com/rocm/apt/6.4 ubuntu main’ | sudo tee /etc/apt/sources.list.d/rocm.listsudo apt update && sudo apt install -y rocm-hip-sdkrocminfo # 验证安装成功
方法一:vLLM容器部署(推荐用于推理场景) :该方式适配大参数量模型,且有ROCm预优化支持。
- 构建ROCm版vLLM容器,可直接参考vLLM官方ROCm构建文档,核心命令为克隆仓库并通过Docker构建: git clone https://github.com/vllm-project/vllm && cd vllm && docker build -t vllm-rocm -f Dockerfile.rocm . 。
- 从Hugging Face下载Gemma 3模型(需提前登录并同意协议),如1B/4B轻量版或27B完整版。
- 启动vLLM服务调用模型,示例命令: docker run --rm --device=/dev/kfd --device=/dev/dri --group-add video vllm-rocm python -m vllm.entrypoints.openai.api_server --model google/gemma-3-4b-it ,启动后可通过API接口调用模型。
方法二:Ollama快速部署(适合新手本地测试):Ollama已支持ROCm适配,操作极简化。 - 下载对应ROCm版本的Ollama安装包,比如适配ROCm 6.1+的AMD专属版本,解压后替换对应GPU架构的ROCm库文件。
- 启动Ollama服务并拉取模型: ./ollama serve (后台启动服务),再执行 ollama pull gemma3:4b (根据GPU显存选择,8G显存选1B/4B版,16G+可选12B版)。
- 直接在终端交互:输入 ollama run gemma3:4b 即可与模型对话。
方法三:Hugging Face Transformers部署 :适合需二次开发的场景。先安装依赖 pip install transformers accelerate torch rocm-ml ,再通过代码加载模型:
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained(“google/gemma-3-4b”)model = AutoModelForCausalLM.from_pretrained(“google/gemma-3-4b”, device_map=“auto”)# 测试推理inputs = tokenizer(“Hello, Gemma 3!”,
—------------------------------------------
完整部署教程请关注微信公众号:颇锐克科技共享,获取。
更多AI,GPU,Linux,Android,芯片行业技术分享请关注公众号:颇锐克科技共享。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)