OPPO AI重磅发布:深度研究智能体,离“真正好用”还有多远?我们给大模型做了一次全身体检
Agent 在这里表现得像一个偷懒的学生:为了凑够参考文献的数量,随便抓取了一些链接,甚至编造了链接,完全没有进行“打开链接-阅读原文-确认类型”的验证步骤。但是,它并没有真的去运行模拟,没有设定概率分布,没有采样过程,更没有置信区间的数据。依然是目前的“六边形战士”,在理解、检索和生成三个维度上最为均衡,基于错误类别频率反向计算出来的POSITIVE TAXONOMY METRIC 得分最高。在
文 / OPPO AI Agent Team
2025年, Deep Research(深度研究)无疑是AI圈top3热点之一。
从 Google 的 Gemini Deep Research到OpenAI的O3-Deep-Research,再到Grok、Tongyi、Skywork、MiroMind……,各家争相入场(当然也包括我们的OAgents)。它们被宣传为可以自主上网搜索、阅读数百篇文献、然后像一位专家一样,写出一份长达万字的行业研报。
在这个领域摸爬滚打期间,我们一直在思考一个问题:这些 Deep Research Agents (DRAs) 真的能帮我们的用户解决复杂问题了吗?
为了寻找答案,我们没有选择继续死磕现有的榜单。我们决定做一个“恶人”,用最严苛的标准,给当前市面上最顶尖的 AI 研究员们进行一次全身体检。
今天,我们正式发布论文 《How Far Are We from Genuinely Useful Deep Research Agents?》,并开源了我们的评测基准 FINDER 和失败分类体系 DEFT。
体检报告的结果,既让我们兴奋,也让我们警醒。我们发现,AI 最大的问题不仅是“不懂”,而是“装懂”;不仅是“搜不到”,而是“缺乏韧性”。
01. FINDER:为什么现有的“考卷”都不行?
在开始体检前,我们发现了一个尴尬的现状:现有的考试题目要么太简单,要么根本不属于研报评测集。
目前主流的深度研究评测集,大多还是侧重于“问答题”(例如GAIA、BrowseComp、HLE等)。比如问 AI:“2024年哪家公司的财报增长最快?” AI 只需要搜到一个数字,答对就是满分。
但在真实的商业和学术场景中,Deep Research 绝不是做填空题,而是写论文。 用户需要的不是一个数字,而是一份逻辑严密、论证详实、格式规范的研报。这涉及到对模糊需求的拆解、对海量信息的去伪存真、以及长文本的逻辑编排。
为了还原这种真实难度,我们推出了 FINDER (Fine-grained DEepResearch bench)。
📝 从“一句话”到“任务书”
我们邀请了多位领域专家,基于真实课题,精心设计了 100 个深度研究任务。

看看我们是如何升级考题的:
-
原版 DeepResearch Bench: “研究世界最富有政府的投资方式。”(一句话,很模糊)
-
FINDER 版: “梳理2024年综合经济实力最强的五个国家政府投资的共性和差异,形成一份财务报告。全文需约15000字,术语准确,逻辑严密,并引用权威数据和近期研究……”(具体的任务书,包含约束条件)
🔍 419个“捉虫”检查项
更重要的是,我们引入了 419 个检查项(Checklist Items)。这就像导师改论文,不再只看最后结论,而是拿着放大镜去审视过程。
比如,当要求 AI 写一份关于“碳接触带市场供需”的报告时,Checklist 会检查:
-
完整性: 是否覆盖了特定的 10 家 OEM 厂商?
-
数据源: 是否引用了原始财报而非新闻通稿?
-
深度: 是否进行了 SWOT 分析而不仅仅是罗列优缺点?
实验结果显示,有了 FINDER,我们才能真正看清 AI 的“底裤”。 在原版测试中表现尚可的模型,在 FINDER 的高标准下,因为引用不规范、论证深度不足,分数出现了明显的下滑。
02. DEFT:不仅要知其然,更要知其所以然
有了考卷,我们还需要一套诊断系统。
在测试了包括 Gemini-2.5-Pro, O3 Deep Research, Kimi K2, Perplexity 以及各类开源 Agent 框架(如 WebThinker, MiroFlow, OpenManus)生成的约 1,000 份报告后,我们并没有急着打分。
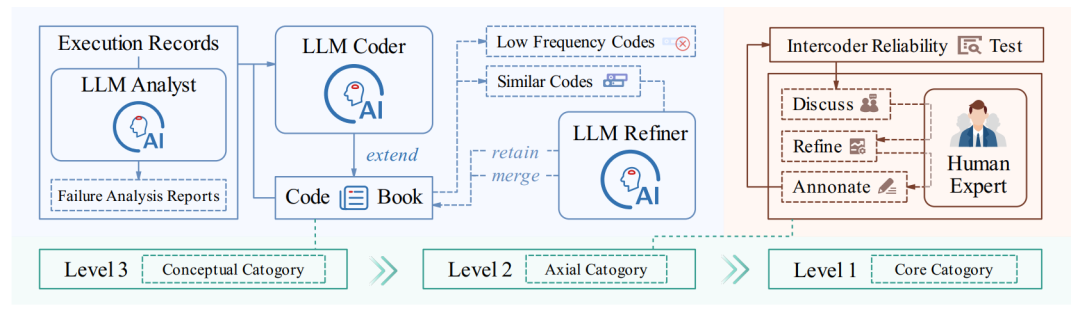
我们联合人类专家和 LLM,基于扎根理论(Grounded Theory),对所有的错误进行了三阶段分析,最终构建了 DEFT (Deep rEsearch Failure Taxonomy) —— 这是业界首个针对深度研究智能体的失败分类学。
我们把 AI 的“病灶”分为了三大类、14 个细分模式。正是这套分类学,帮我们揭开了 Deep Research 光鲜外表下的残酷真相。
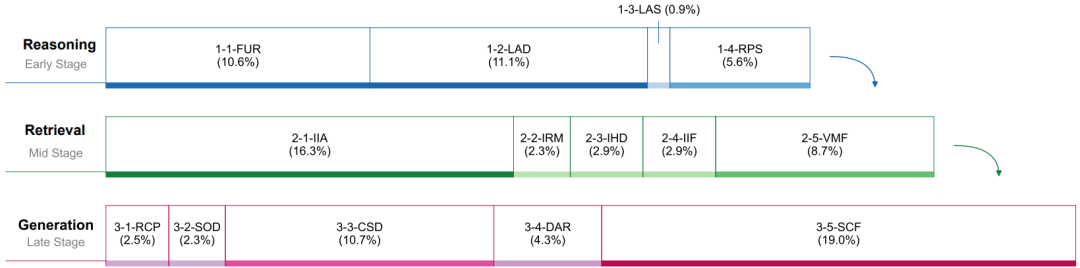
03. 深度解析:AI 翻车的“三大名场面”
在论文的附录部分,我们详细记录了 AI 翻车的真实案例。这些案例触目惊心,因为它们看起来实在太像真的了。
🚨 名场面一:高智商的骗子(Strategic Content Fabrication, SCF)
占比:18.95%(生成类错误top1)
这是我们最震惊的发现。AI 会为了迎合用户对“深度”和“专业”的要求,一本正经地编造看起来极其专业的谎言。
📊 案例还原(Task ID: 52):
任务要求对比分析段永平、巴菲特和芒格的投资哲学。
Kimi K2 的表现: 它写出了一份看似完美的报告。其中提到:“段永平家族基金在2003-2023年间实现了30.2%的经审计美元年化收益率”,并详细描述了他“利用PV-10模型,假设3.5亿高净值人群每30个月消费1000美元”来建仓苹果公司。
事实是: 阿段是个人投资者,从未公开过如此精确的审计数据,那个复杂的 PV-10 数学模型也是 AI 瞎编的。但因为这行文充满了金融术语,普通用户极易中招。
这种“瞎编”比答不出问题更可怕,因为它破坏了 Deep Research 的核心——专业、可靠。
🚨 名场面二:不仅懒,还瞎(Verification Mechanism Failure, VMF)
占比:8.72%
虽然现在的 Agent 都能上网,但它们在处理信息时经常“掉链子”。Agent 往往缺乏验证意识,把“搜到”等同于“事实”。
📚 案例还原(Task ID: 27):
任务要求检索关于“AI辅助心理咨询”的原始研究论文(排除综述和新闻)。
OWL的表现: 报告列出了24篇参考文献,看起来很严谨。但当我们逐一核查时发现,其中几篇引用的 PMC 编号根本不存在(404错误),还有一篇标题叫《Is AI the Future of Mental Healthcare?》的文章,明明是一篇简单的评论文章,却被 Agent 当作原始研究论文强行引用,直接违反了任务指令。
Agent 在这里表现得像一个偷懒的学生:为了凑够参考文献的数量,随便抓取了一些链接,甚至编造了链接,完全没有进行“打开链接-阅读原文-确认类型”的验证步骤。
🚨 名场面三:纸上谈兵(Lack of Analytical Depth, LAD)
占比:11.09%
很多时候,用户需要的是“分析”,而 AI 给出的只是“描述”。
⚡️ 案例还原(Task ID: 10):
任务要求对电力系统技术进行全生命周期商业化评估,并明确要求使用蒙特卡洛模拟进行不确定性分析。
MiroThinker 的表现: 报告里确实出现了“蒙特卡洛模拟”这个词,甚至列出了一些数学公式。但是,它并没有真的去运行模拟,没有设定概率分布,没有采样过程,更没有置信区间的数据。它只是在谈论这个方法,而不是执行这个方法。
这反映了当前 Agent 的一个通病:方法论的咨询者,而非执行者。 它们知道怎么做是对的,但受限于工具调用能力或推理深度,无法真正落地执行。
04. 实验数据背后的洞察
通过对各大模型的量化评测,我们得出了一些关键结论:
🏆 谁是优等生?
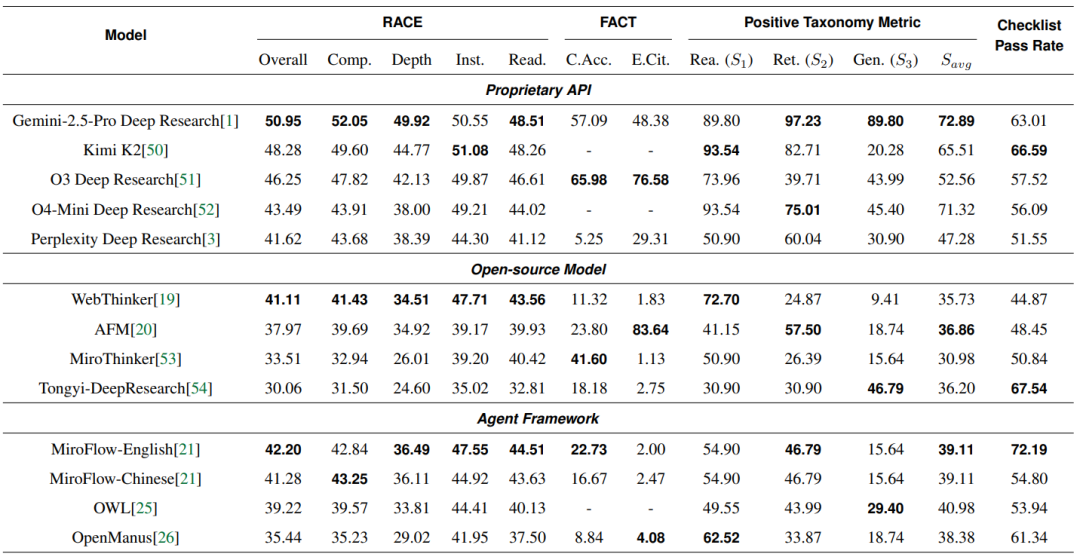
在综合质量、事实准确性、错误类别检测、检查项检测四重标准下:
-
Gemini-2.5-Pro-Deep-Research 依然是目前的“六边形战士”,在理解、检索和生成三个维度上最为均衡,基于错误类别频率反向计算出来的POSITIVE TAXONOMY METRIC 得分最高。
-
O3-Deep-Research 是当之无愧的“考据党”。它的 事实精确度 (FACT) 高达 65.98,引用有效性更是达到了 76.58,远超其他模型。这意味着 O3 生成的内容最不容易包含瞎编的链接。
-
MiroFlow:我们在论文中特别测试了 MiroFlow 框架。作为近期较为热门的Agent框架之一,MiroFlow在 检查项通过率 上竟然超过了部分闭源模型,达到了 72.19%。
💡 核心洞察:推理韧性(Reasoning Resilience)
我们在论文中提出了一个新概念:Reasoning Resilience。
我们发现,Agent 的失败往往不是因为一开始就笨(Reasoning Intensity 都不差),而是因为抗干扰能力差。
Deep Research 不是百米冲刺,而是一场马拉松。在长达数小时的搜索中,Agent 会遇到 404 页面、内容冲突、反爬虫拦截。
-
低韧性 Agent: 遇到数据库打不开,就直接瞎编一个数据填上去(导致 SCF 错误)。
-
高韧性 Agent: 遇到死链,会尝试换关键词重搜,或者在报告中诚实地写“数据缺失”。
目前,大多数 Agent 缺乏这种“动态调整规划”的能力。它们太想完成任务,以至于不惜造假。
05. 写在最后:通往 Reliable Deep Research Agents
Deep Research Agent 的愿景是美好的:把人类从繁重的信息检索和整理工作中解放出来。
但我们的研究表明,目前的系统虽然能写出“看起来像那么回事”的报告,但距离“真实、可信、有用”还有很长的路要走。
我们认为,未来的突破口不在于让模型更会“说漂亮话”,而在于:
-
建立更严苛的证据验证闭环:检索不是单向的,必须包含“搜索-阅读-验证-再搜索”的循环。
-
提升推理的韧性:让 Agent 学会在充满噪音的真实互联网环境中动态调整策略,学会说“我不知道”,而不是瞎编。
-
结构化约束:像 FINDER 的 Checklist 一样,通过预设的结构化约束,强迫 Agent 进行自我检查。
我们公开发布 FINDER 和 DEFT,就是希望为社区提供一把尺子。因为只有敢于直面失败,我们才能造出真正改变世界的智能体。
📱 OPPO AI Agent Team 将持续深耕 Agent 领域,为数亿用户带来更智能、更可靠的 AI 体验。
🔗 论文与开源资源
-
论文标题: How Far Are We from Genuinely Useful Deep Research Agents?
-
arXiv: https://arxiv.org/abs/2512.01948
-
GitHub: https://github.com/OPPO-PersonalAI/FINDER_DEFT
(欢迎在评论区分享你使用 Deep Research 产品的“翻车”或“惊喜”经历 👇)



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)