DINOv3震撼发布!全能视觉大模型:Gram锚定+多模态对齐实现CV任务全碾压【附论文与源码】
DINOv3震撼发布!全能视觉大模型:Gram锚定+多模态对齐实现CV任务全碾压【附论文与源码】
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
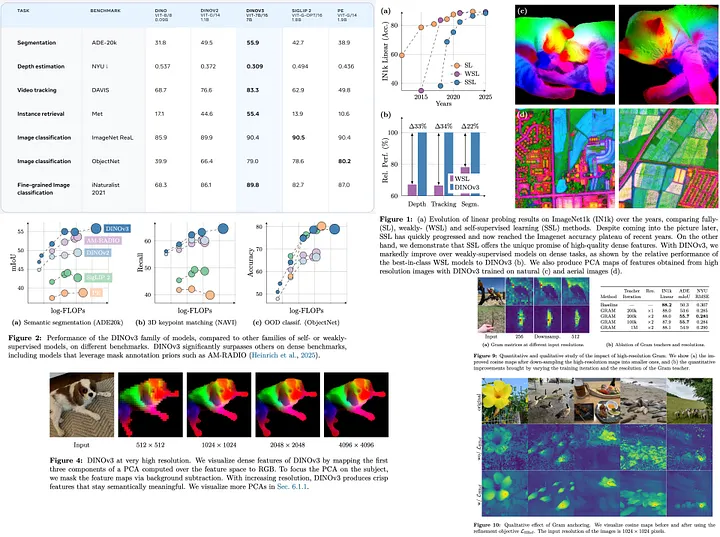
DINOv3是一种自监督视觉模型,能够有效扩展到大型数据集和架构,通过引入Gram锚定防止长时间训练期间密集特征图的退化,并应用事后策略实现跨分辨率、模型规模和文本对齐的灵活性。该模型在无需微调的情况下,在广泛的视觉任务中实现了卓越性能,并提供了一套适用于不同资源和部署场景的可扩展模型。
论文地址:https://arxiv.org/pdf/2508.10104
无监督的大规模训练
数据准备
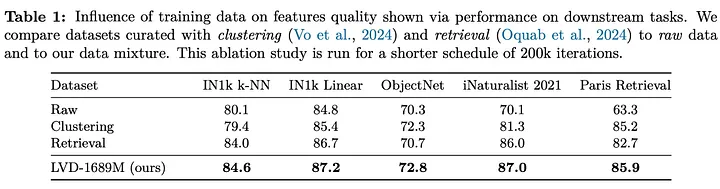
DINOv3在从约170亿张Instagram图像构建的大规模数据集上进行训练,这些数据经过内容审核过滤。为了最大化泛化能力和任务相关性,数据通过三种方式筛选:
- 分层k-means聚类:采用平衡采样确保视觉多样性(产生17亿张图像)
- 基于检索的选择:强调与下游任务相关的概念
- 包含标准数据集:如ImageNet和Mapillary
训练期间,批次采样10%来自ImageNet1k(同质源),90%来自其他所有数据源。消融研究表明,单独使用聚类、检索或原始数据效果不稳定,但组合所有方法能在各项基准测试中获得最佳性能。
自监督的大规模训练
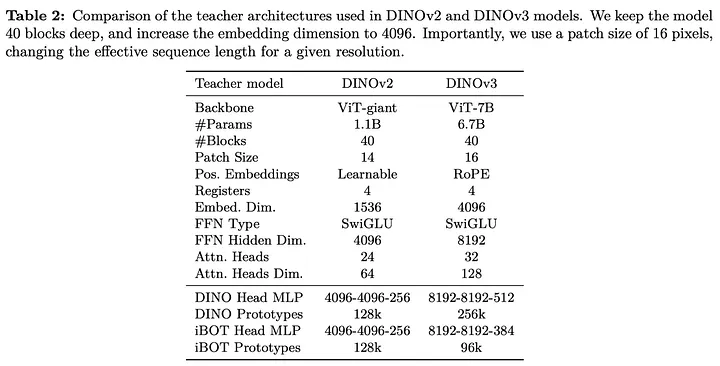
大多数自监督学习方法难以扩展到超大模型,但DINOv3成功扩展到70亿参数,结合了三种自监督目标:
- 图像级损失(LDINO)
- 块级重建损失(LiBOT)
- 均匀性正则化器(LKoleo)
关键改进包括:
- Sinkhorn-Knopp归一化
- 全局和局部裁剪专用头
- 采用自定义RoPE(带框抖动)处理多变分辨率
- 简化优化:恒定学习率/权重衰减,持续训练直至下游性能提升
训练配置:
- 优化器:AdamW
- 批量大小:4096(跨256个GPU)
- 多裁剪策略:2个全局+8个局部裁剪/图像
Gram锚定:密集特征的正则化方法
训练中块级一致性的退化
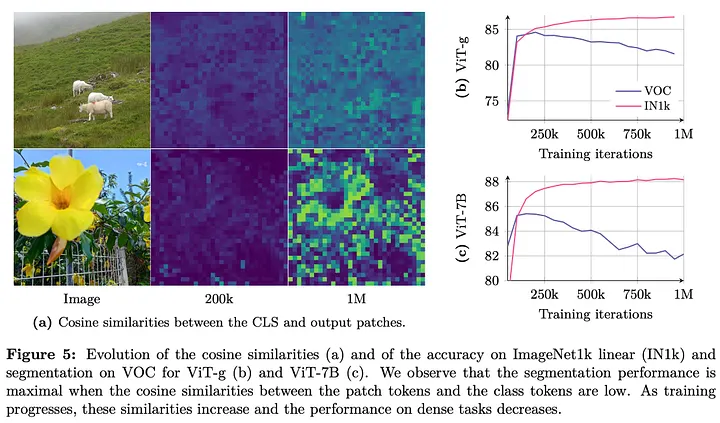
DINOv3的长时间训练会提升全局指标(如图像分类),但导致密集预测任务(如分割)性能下降。分析表明:
- 块级特征逐渐失去局部性
- 相似性图变得嘈杂
- 块输出与CLS令牌过度对齐
- 块范数保持稳定但局部性退化
Gram锚定目标
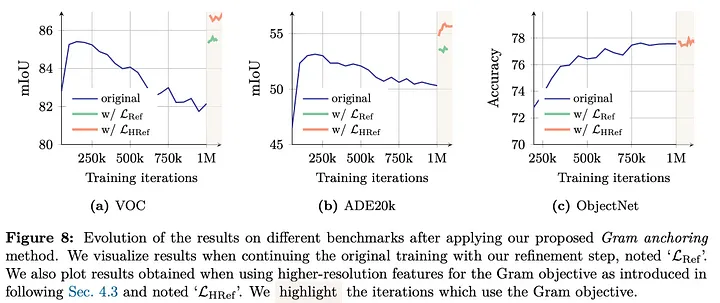
解决方案:
- 通过Gram矩阵对齐学生模型与早期"Gram教师"模型的块相似性
- 在100万次迭代后应用该损失
- 定期更新Gram教师模型
效果:
- 快速恢复退化的局部特征
- 稳定iBOT目标
- ADE20k分割任务显著提升(+2 mIoU)
- 对全局基准影响极小,部分任务(如ObjectNet)还有提升
利用高分辨率特征
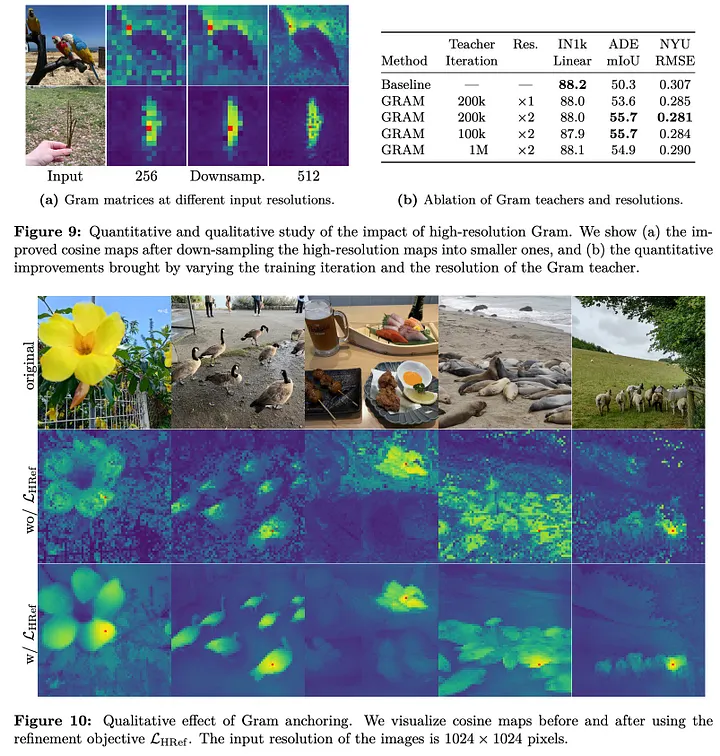
关键技术:
- 对Gram教师使用双分辨率输入
- 特征图下采样匹配学生输出
- 构建新损失LHRef
- 早期Gram教师模型效果最佳
结果:
- ADE20k密集任务显著提升
- 块特征相关性可视化验证改进
训练后处理
分辨率扩展
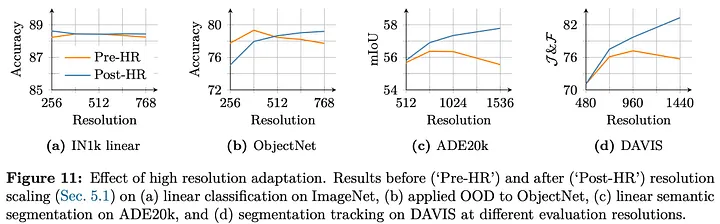
适应方法:
- 基础训练分辨率:256
- 高分辨率精修:混合全局(512,768)+局部(112-336)裁剪
- 10k次迭代
- 使用7B教师模型进行Gram锚定
优势:
- 分类任务小幅提升
- ObjectNet迁移平衡高低分辨率
- 分割/跟踪等密集任务明显改进
- 最高支持4K分辨率
模型蒸馏
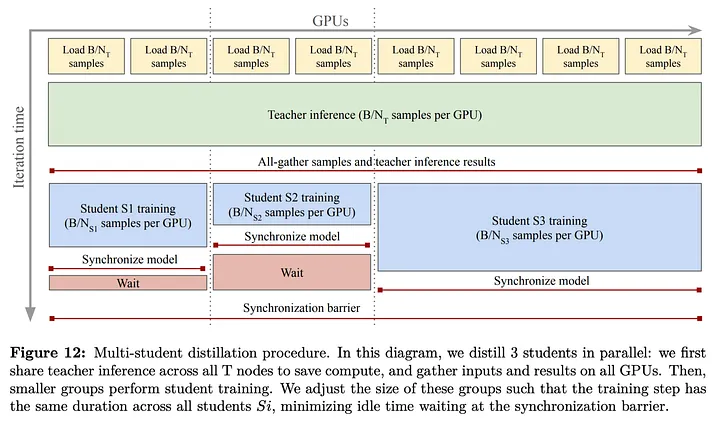
蒸馏策略:
- 目标:保留教师模型表征能力
- 学生模型:ViT-S/B/L及定制S+/H+
- 共享教师推理加速训练
- 并行训练多学生模型
结果:
- 以少量计算成本获得强大性能
- 完整模型家族单次训练完成
文本对齐
创新点:
- 冻结视觉骨干
- 添加两层Transformer
- 联合使用CLS和平均池化块嵌入
- 保持与数据筛选协议一致
优势:
- 提升密集任务表现
- 训练高效
- 支持细粒度多模态理解
性能表现
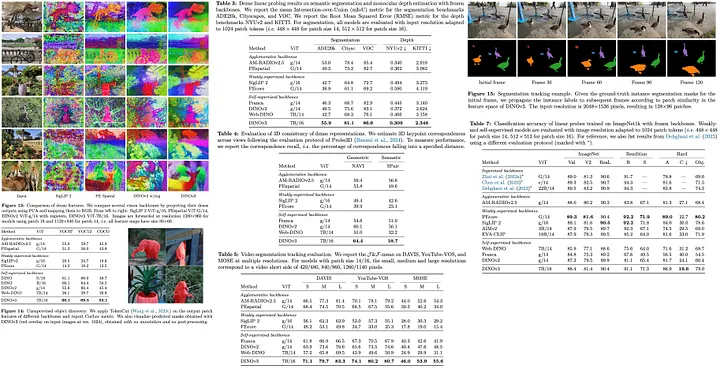
关键成果:
- 无需微调即可获得:
- 卓越密集特征
- 鲁棒全局表征
- 先进系统基础:
- 目标检测
- 语义分割
- 3D视角估计
- 单目深度估计
地理空间数据应用
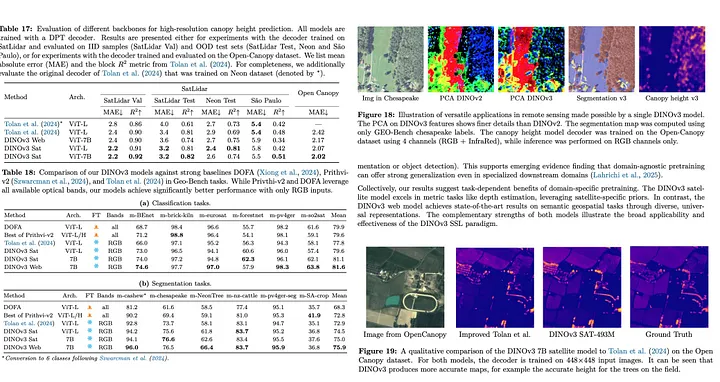
DINOv 3 7 B 卫星模型使用与网络模型相同的训练配方在 493 M 高分辨率卫星图像上进行预训练,然后提炼成更小的变体以提高效率。评估表明,卫星模型在冠层高度估计方面实现了新的 SOTA 结果,降低了 SatLidar 1 M 和 Open-Canopy 基准的 MAE,并在语义和检测任务上表现出色。经过提炼的 ViT-L 卫星模型在某些情况下与 7 B 模型相匹配甚至超过 7 B 模型,突出了效率的提高。比较表明,特定领域的预训练有利于深度估计等度量任务,而一般的 Web 训练的 DINOv 3 在语义分割和对象检测方面取得了上级结果。卫星和 Web 模型共同展示了互补的优势,表明 DINOv 3 的自我监督范式可以有效地推广到特定领域和与领域无关的地理空间任务。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)