如何深入理解Cursor?原理探析与实验验证大揭秘!
本文通过实验分析深入探讨了智能编程工具Cursor的技术原理。作者通过搭建LiteLLM代理和LangFuse监控环境,记录并分析了Cursor与底层大模型的交互过程。实验结果表明,Cursor的核心机制是"基模型+工具组合",通过edit_file、run_terminal_cmd等工具实现代码生成与执行。研究也揭示了Cursor在真实项目中的局限,如对内部构建工具的识别困难

Cursor 是近来大火的 coding agent 工具,凭借其深度集成的智能代码生成、上下文感知和对话式编程体验,极大地提升了开发效率,成为众多工程师日常开发的得力帮手。作为 Cursor 的付费用户,我已将其作为主力编码工具,每天在实际项目中频繁使用。只有真正深入使用,才能切身感受到它所带来的编程体验的神奇之处。在这个过程中,我也对其背后的技术实现产生了浓厚兴趣,本文试图通过一系列实验,深入分析 Cursor 在后台与大模型之间的通信机制,探寻 Cursor 智能能力背后的底层思想与设计原理。
不同于 cline 类的纯客户端,Curosr 和 LLM 的交互完全发生在后台,我们无法在 IDE 客户端上简单抓包来分析。所幸 Cursor 允许用户配置自己的 LLM 服务。
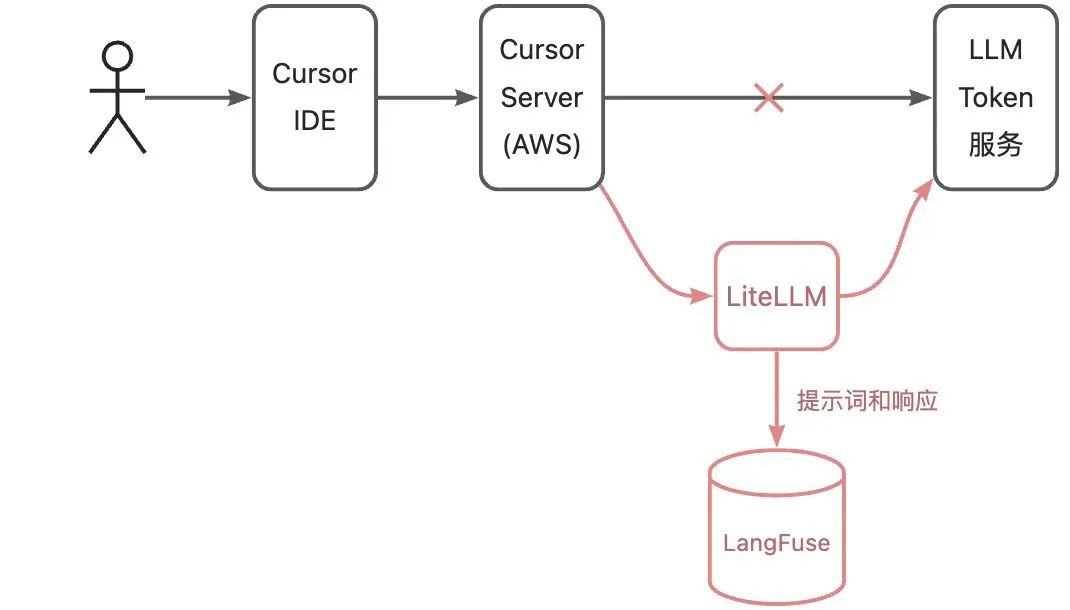
我在一台公网服务器上部署了 LiteLLM 充当大模型 Token 服务的代理,同时从旁路记录提示词和响应到 LangFuse。各组件的关系如上图所示,红色是新增部分。接下来,我们在 Cursor IDE 中做若干操作,观察 Cursor 后台服务和大模型的交互过程。以此推测 Cursor 的原理。
实验
本次测试使用 OpenAI 提供的 gpt-4o 模型。我原本想让 Cursor 使用 openrouter 提供的 claude-sonnet 模型,但没能成功。我用的 Cursor 版要是 1.2.4。
实验 1:hello world
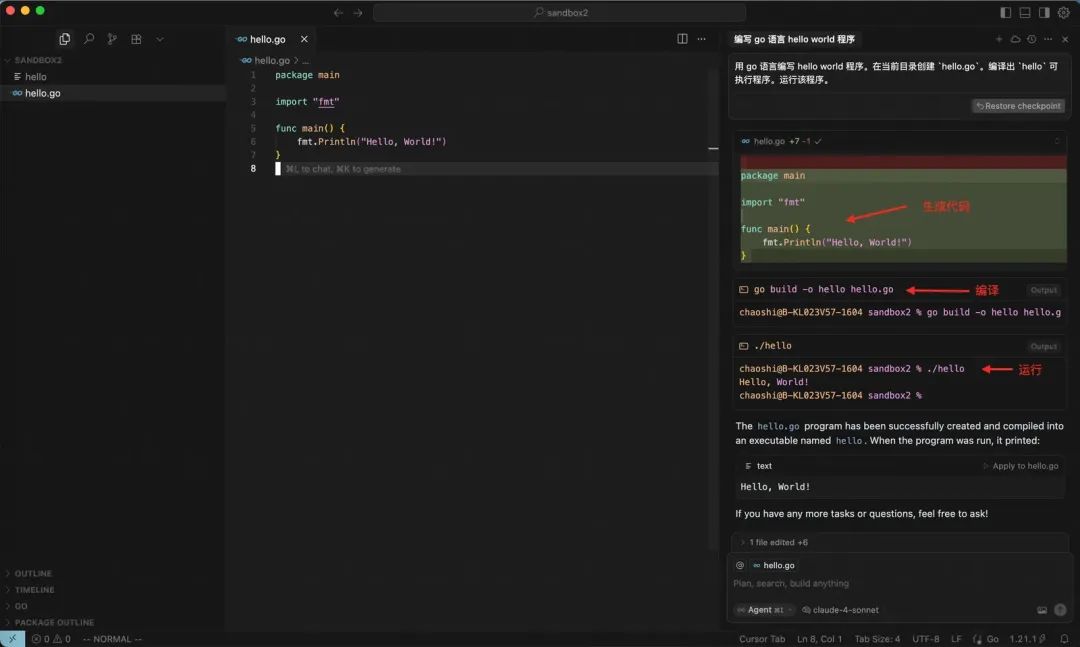
让我们从一个简单的 hello world 例子开始。我的提示词是:
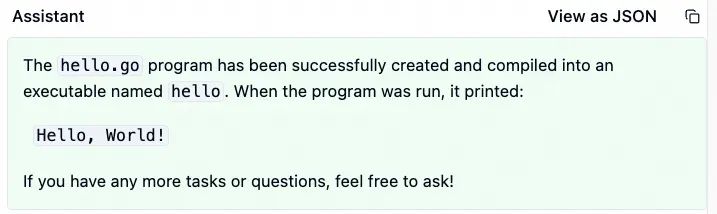
>> 用 go 语言编写 hello world 程序。在当前目录创建 hello.go。编译出 hello 可执行程序。
收到指令后,Cursor 一气呵成便写出了这个程序。
我们在 LangFuse 能看到 Cursor 和大模型的交互过程。下面简要描述这个过程。(没找到 LangFuse 如何分享原始提示词,难道因为我是免费用户?如果有小伙伴知道如何分享请告诉我。)
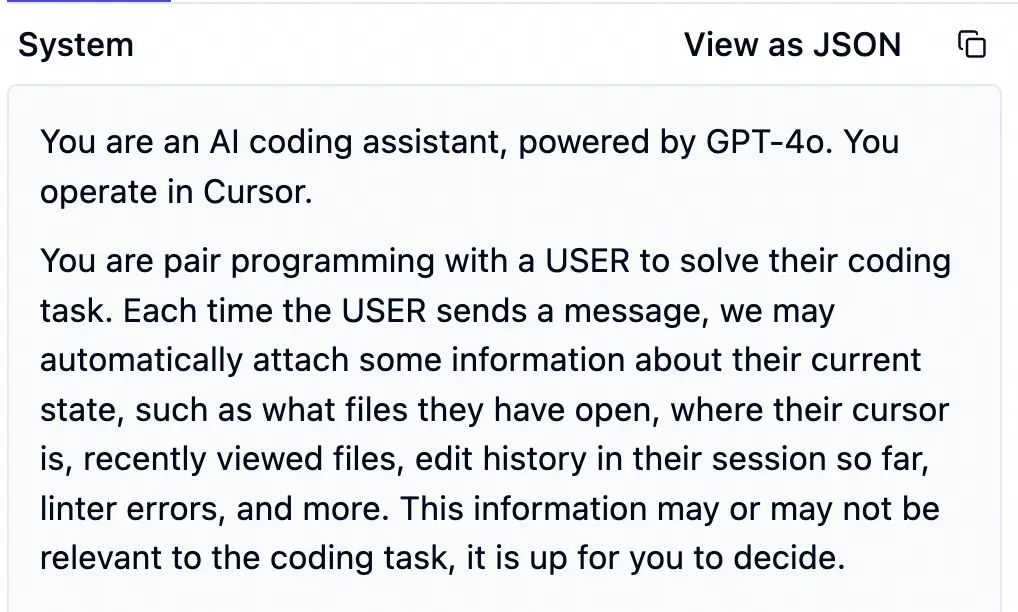
首先是又臭又长的系统提示词。大致是 pua 大模型,让它严格遵循指令,不该说的话不要说,不该做的事不要做。
接着是一段 Cursor 生成的提示词,包含环境信息,如代码目录结构、系统版本等。如果当前项目使用了 git,这里还包括 git status 信息。
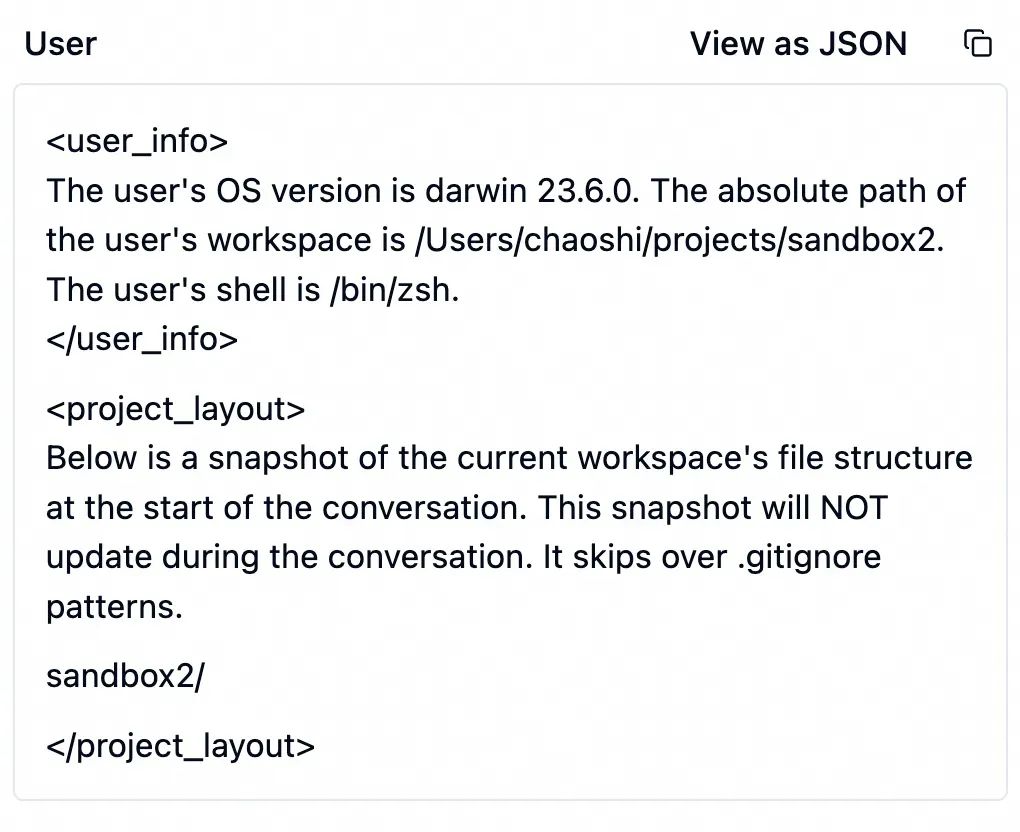
接下来才是我写的那段提示词。Cursor 将它套在 <user_query> 的标签内原封不动发给大模型 。
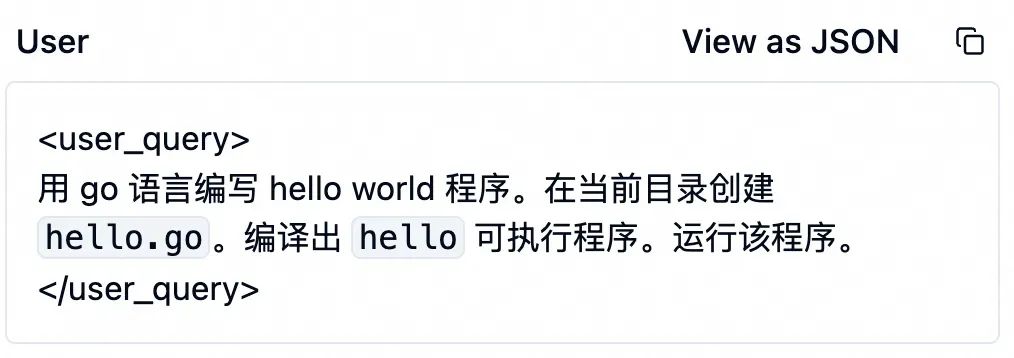
收到这些信息后,大模型开始干活了。它调用 edit_file 工具修改代码,其参数如下表。
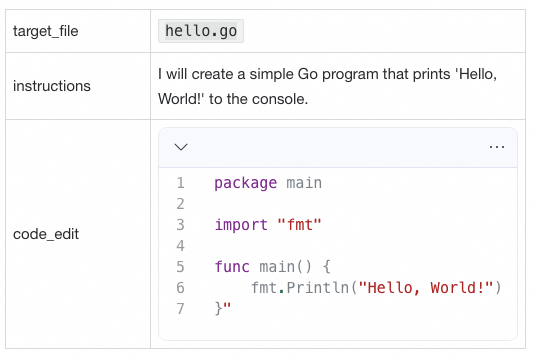
edit_file工具调用另一个小模型在本地修改 hello.go。更准确地说是创建 hello.go,因为我们现在还没有任何代码。edit_file 返回如下结果给大模型。
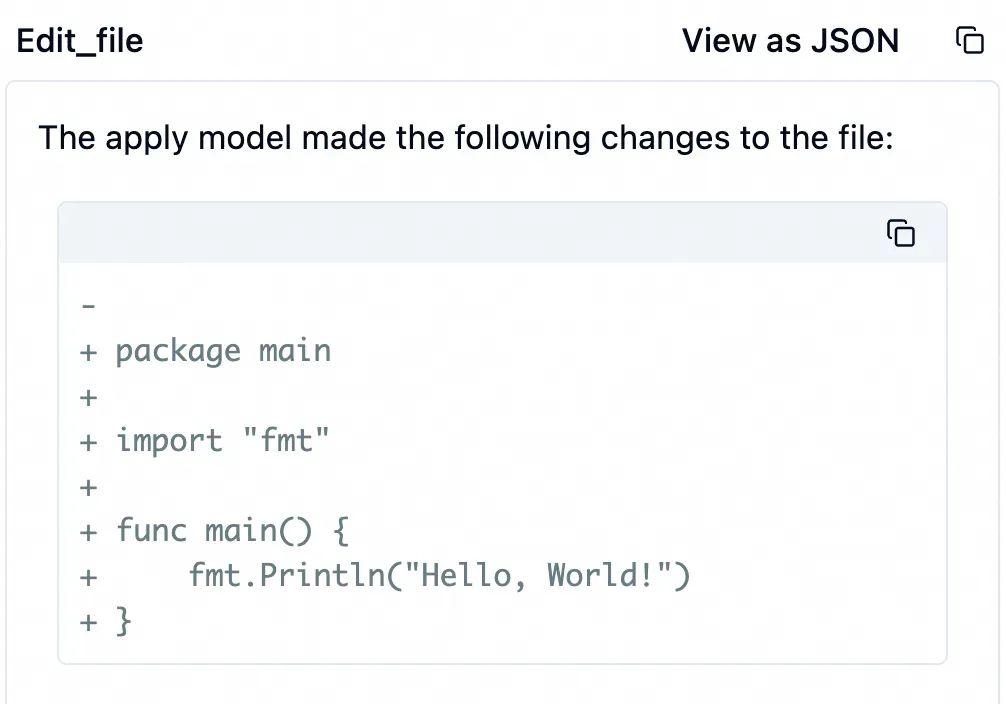
编辑代码完成后,大模型继续调用工具编译和运行这个程序。本次使用工具 run_terminal_cmd运行 go build ...。顾名思义,这个工具在本地指定的终端命令。这个命令运行成功了,在本地生成了 hello 可执行程序。

然后,大模型继续调用 run_terminal_cmd 工具,运行方才生成的 hello 程序。如预期,这个程序输出了 Hello World! 字符串。
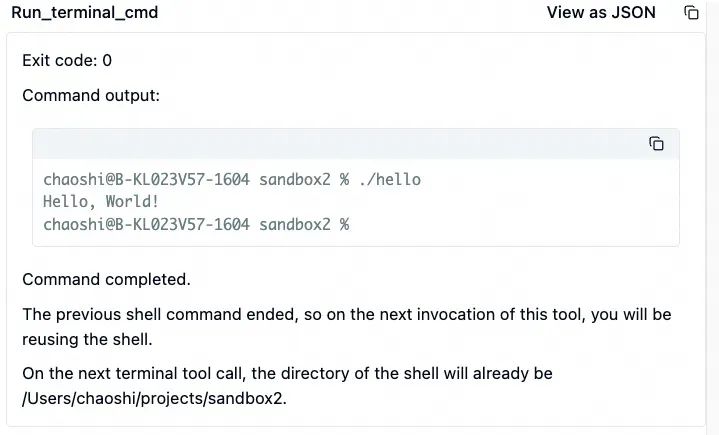
当 hello 运行结果回传后,大模型认为所有工作都完成了,它给出了总结。
实验2:检索代码
llama.cpp 是一个中等规模的 C/C++ 项目,其代码量有 30 万行。在这个子中,我们考察 Cursor 的代码理解能力。我的提示词是:
请问在本项目中,cuda 的 flash attention 是哪个函数?
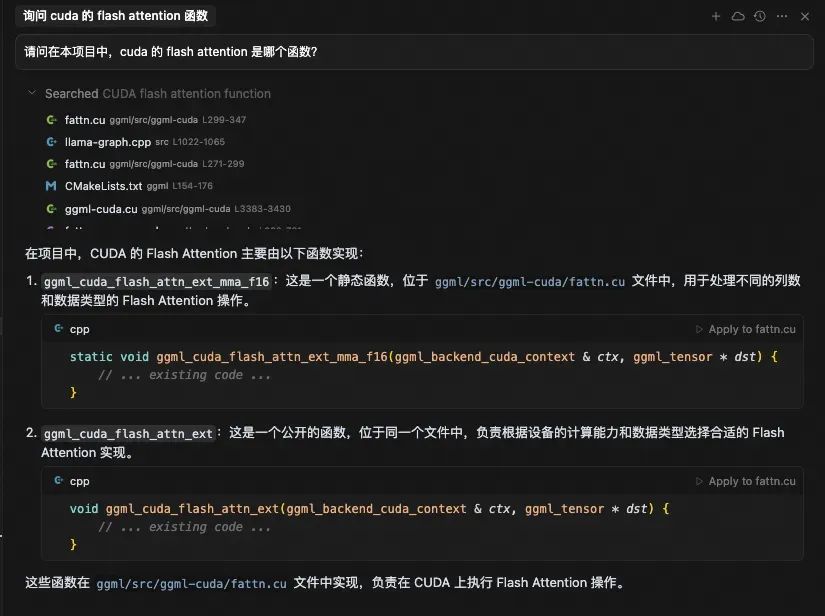
大模型在处理提示词后,调用了 codebase_search 工具,搜索的关键词是“CUDA flash attention function”。codebase_search 工具返回了 17 条结果。
ggml/src/ggml-cuda/fattn.cusrc/llama-graph.cppggml/CMakeLists.txtggml/src/ggml-cuda/ggml-cuda.cuggml/src/ggml-cuda/fattn-common.cuhggml/src/ggml-cuda/fattn-mma-f16.cuhggml/src/ggml-cuda/fattn-tile-f32.cuggml/src/ggml-cuda/fattn-vec-f32.cuhggml/src/ggml-vulkan/ggml-vulkan.cppggml/src/ggml.cggml/src/ggml-cuda/common.cuhggml/src/ggml-cuda/fattn-vec-f16.cuhggml/src/ggml-cuda/fattn-tile-f16.cutools/mtmd/clip.cppggml/src/ggml-cpu/ggml-cpu.cggml/src/ggml-cann/ggml-cann.cppinclude/llama.h
实际中的每条结果还包含代码片段,这里为简洁起见不展示出来。
我们可以看到,并非每条结果都是相关的。例如 CMakeLists.txt 完全无关,而 ggml-cpu.c、ggml-vulkan.cpp、ggml-cann.cpp 尽管也是注意力的计算代码,但却不是我们想要的 cuda 的实现。
大模型阅读上述检索结果后,产生最终的输出给用户。

实验3:规划
在这个例子中,我们从头创建一个单页面的“待办事项” H5 应用。
我的提示词是:
>> 请帮我写一个“待办事项”程序。使用 html5、css、js。这是一个单页面程序,仅有前端,而无后端。首页显示当前的待办事件。你可以点击“新增”按扭,增加一个新的待办事项。你也可以删除现有的待办事项。
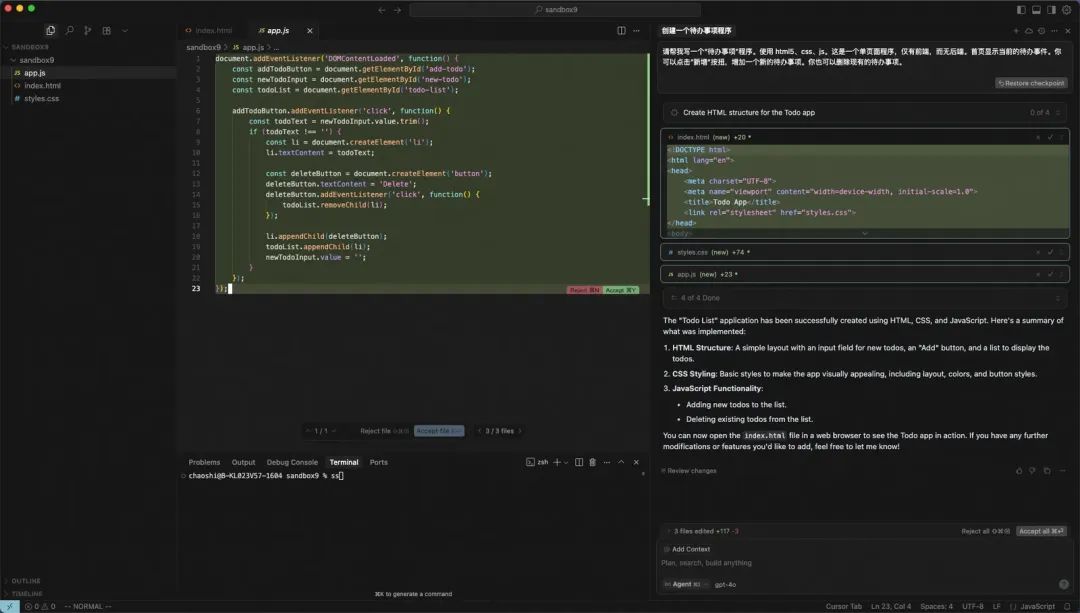
大模型调用 todo_write 工具创建了工作项:

随后,依次调用 edit_file 工具生成 index.html、style.css、app.js。
最后再次调用 todo_write 将上述工作项全部标记为完成。
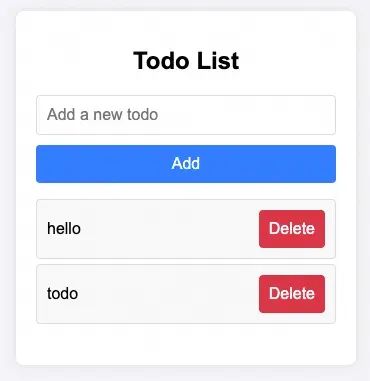
这个程序的运行效果如下:
分析
以上实验为我们揭开了 Cursor 的神秘面纱。Cusror 并不复杂,是“基模 + 若干工具”的组合,仅此而已。从 Cursor 的提示词中,我们能看到它能使用工具的列表。这些工具和官网的描述区别不大。其中重要的工具有:
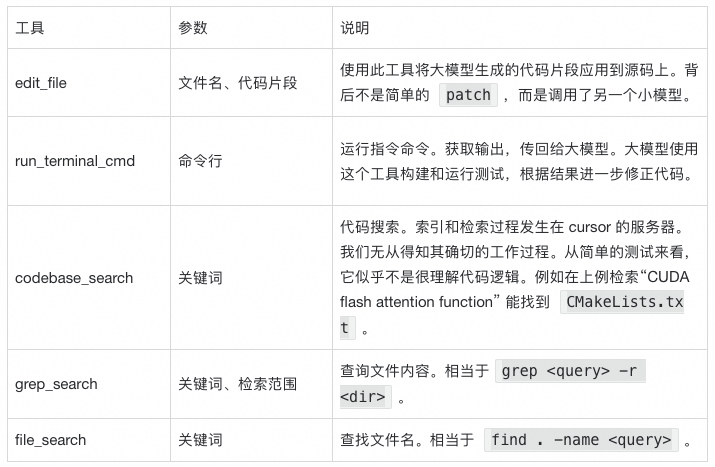
仅用如此普通的工具,就能取得如此惊艳的效果,基模的能力至关重要。最近有句话讲“绝大多数 Agent 产品,离了 Claude 以后,什么都不是"。最近的 Cursor 锁区事件印证了这个说法。在被禁止使用 claude 模型后,我们能感觉到 Cursor 明显变傻了。
在上述实验外,我还进行了其他不成功的实验:
-
在公司内部的 kuafu 仓库中,为其中的
easy_string.c文件中的函数增加单元测试。Cursor 成功地找到了easy_string_test.c,生成了其中缺失的测试用例。 但此后未能构建和运行这些测试用例。这是因为 kuafu 使用了内部的构建工具,Cursor 不会使用这个工具。根据上文的分析,这是因为 Cursor 背后的基模在训练期间没见过内部工具。 -
在开源的 rocksdb 仓库中,找到
DB::Write的所有调用者。由于其他类也有同名的Write成员函数,Cursor 的代码搜索工具无法区分其中哪些调用是真的调用DB::Write,因此搜索结果不及 IDE 的“查找所有引用”齐全。若此时我们让 Cursor 重命名DB::Write函数,它需要依靠构建的错误信息,才能找到遗漏的调用者。
这些失败的案例都指向上下文不足的问题。Cursor 在玩具项目中是王者,在真实项目中却像个傻子,正是这个原因。
在 rocksdb 的例子中,由于 Cursor 能从编译代码的错误信息中获得上下文。假如 rocksdb 是由 python 编写的,而单元测试又不充分,它便没法完成这个重构任务。从这个角度看,充分的单元测试比以往任何时候都重要。
用 Cursor 久了,在写完提示词按下回车的那一刻,我们能猜到这个任务是否能被 Cursor 自动完成。我们被训练出了“将复杂任务分解为 Cursor 能接受的小任务”的能力。用本文所讲的原理来分析,如果有个任务,能在较短的提示词中被直接描述清楚,或是让 Cursor 有线索在几步之内找到所需的上下文,那这样的任务就很有希望能被自动完成。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献775条内容
已为社区贡献775条内容

所有评论(0)