讯飞方言识别大模型python调用
摘要:本文介绍了如何使用讯飞方言大模型进行方言识别,针对官方Python接口存在的问题进行了改进。作者通过将音频分段处理,先检测静音片段,再合并非静音部分进行识别,提升了识别效率。代码实现了音频分割、静音检测、片段合并功能,并展示了与讯飞WebSocket API的交互方法,包括鉴权参数生成和消息处理。改进后的方案优化了长音频处理流程,减少了无效识别,提高了整体识别速度。
·
最近接触到方言识别的业务,查询一番资料后最终选择使用讯飞的方言大模型: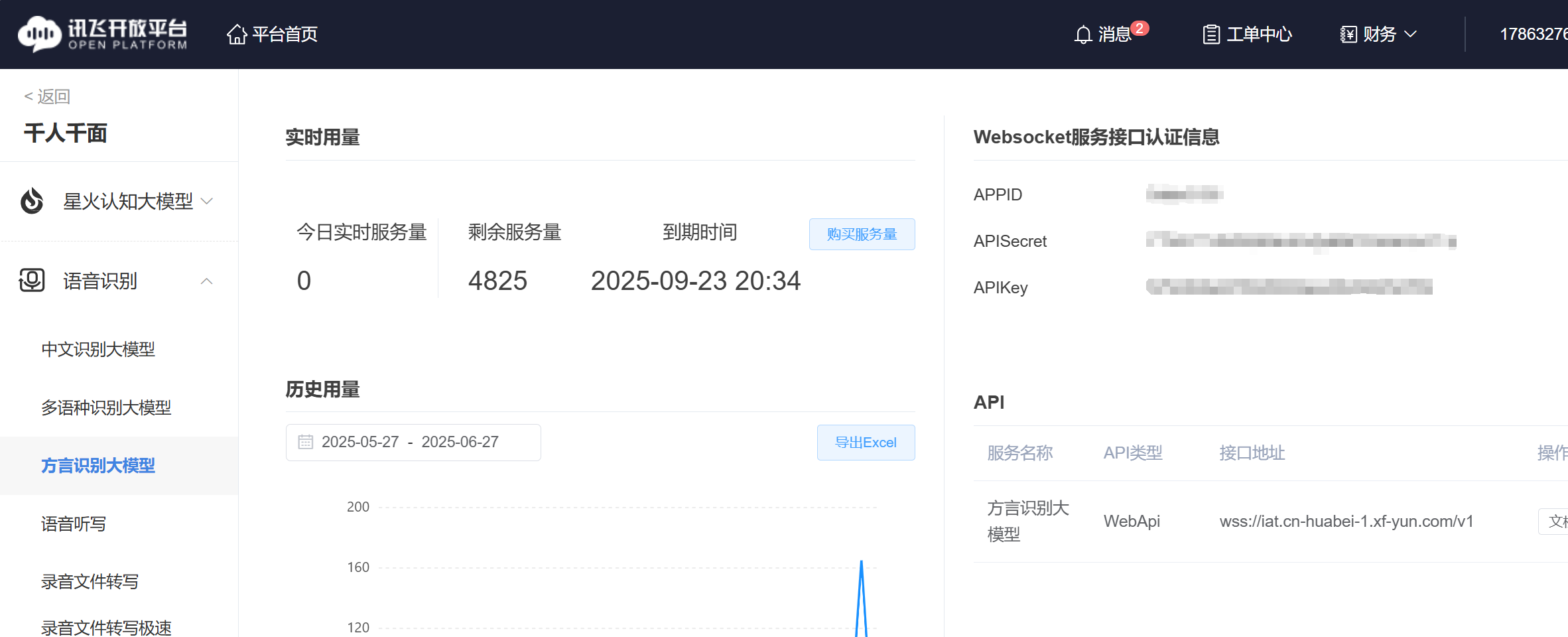
官方给出了Java与Python两种版本的语言识别调用接口,这里博主使用的是python版本的
分段处理识别
官方给出的代码中似乎存在问题,此外,博主为提升识别速度,首先将音频窃取多段,随后判断其是否有音频信息,最后再将音频信息合并进行识别,以下是改进后的代码:
import _thread as thread
import time
from time import mktime
import numpy as np
import websocket
import base64
import datetime
import hashlib
import hmac
import json
import ssl
from datetime import datetime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
from pydub import AudioSegment
import os
def split_audio(file_path, segment_duration_ms=20000, output_dir="segments"):
"""
将音频文件切分为多个片段
:param file_path: 原始音频路径
:param segment_duration_ms: 每段持续时间(毫秒)
:param output_dir: 输出目录
:return: 切片路径列表 [(index, path), ...]
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
audio = AudioSegment.from_file(file_path)
segments = []
for i in range(0, len(audio), segment_duration_ms):
segment = audio[i:i + segment_duration_ms]
segment_path = os.path.join(output_dir, f"segment_{len(segments)}.wav")
segment.export(segment_path, format="wav")
segments.append((len(segments), segment_path))
return segments
def is_silence(path, threshold=-50.0):
"""
判断音频是否为静音(基于 RMS 能量)
"""
try:
audio = AudioSegment.from_file(path)
audio = audio.set_channels(1) # 转为单声道
rms = audio.rms
if rms == 0:
return True
dbfs = 20 * np.log10(rms / (audio.max_possible_amplitude))
print(f"[{os.path.basename(path)}] 音频能量: {dbfs:.2f} dBFS")
return dbfs < threshold
except Exception as e:
print(f"无法读取音频文件: {path}, 错误: {str(e)}")
return True
def merge_non_silent(segments, output_path="non_silent.wav"):
"""
合并非静音音频段
"""
combined = AudioSegment.empty()
for idx, path in segments:
if not is_silence(path):
segment = AudioSegment.from_file(path)
combined += segment
combined.export(output_path, format="wav")
print(f"合并完成,输出文件: {output_path}")
return output_path
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
self.iat_params = {
"domain": "slm", "language": "zh_cn", "accent": "mulacc","result":
{
"encoding": "utf8",
"compress": "raw",
"format": "json"
}
}
# 生成url
def create_url(self):
url = 'wss://iat.cn-huabei-1.xf-yun.com/v1'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "iat.cn-huabei-1.xf-yun.com" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v1 " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "iat.cn-huabei-1.xf-yun.com"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
print('websocket url :', url)
return url
# 收到websocket消息的处理
def on_message(ws, message):
print("【收到 WebSocket 消息】")
print(message) # 👈 调试用:打印原始消息
try:
msg = json.loads(message)
code = msg["header"]["code"]
status = msg["header"]["status"]
if code != 0:
print(f"请求错误:{code}")
ws.close()
else:
payload = msg.get("payload")
if payload and "result" in payload:
result_base64 = payload["result"]["text"]
result_str = base64.b64decode(result_base64).decode("utf-8")
result_json = json.loads(result_str)
# 提取文本内容
text = ""
for ws_item in result_json.get("ws", []):
for cw in ws_item.get("cw", []):
text += cw.get("w", "")
print("识别结果:", text)
if status == 2: # 最后一帧
print("🔚 最终识别结果已接收完毕,准备关闭连接...")
ws.close()
except Exception as e:
print("⚠️ 解析消息失败:", str(e))
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws, close_status_code, close_msg):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
def run(*args):
frameSize = 1280 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔(单位:s)
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
with open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.read(frameSize)
audio = str(base64.b64encode(buf), 'utf-8')
# 文件结束
if not audio:
status = STATUS_LAST_FRAME
# 第一帧处理
if status == STATUS_FIRST_FRAME:
d = {"header":
{
"status": 0,
"app_id": wsParam.APPID
},
"parameter": {
"iat": wsParam.iat_params
},
"payload": {
"audio":
{
"audio": audio, "sample_rate": 16000, "encoding": "raw"
}
}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d = {"header": {"status": 1,
"app_id": wsParam.APPID},
"payload": {
"audio":
{
"audio": audio, "sample_rate": 16000, "encoding": "raw"
}}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d = {"header": {"status": 2,
"app_id": wsParam.APPID
},
"payload": {
"audio":
{
"audio": audio, "sample_rate": 16000, "encoding": "raw"
}}}
ws.send(json.dumps(d))
break
# 模拟音频采样间隔
time.sleep(intervel)
thread.start_new_thread(run, ())
if __name__ == "__main__":
original_audio = r"D:\workspace\qianren\onnx_inference\uploads\output_audio.wav"
# 1. 音频切片
segments = split_audio(original_audio, segment_duration_ms=10000)
# 2. 合并非静音段
merged_audio = "segments/non_silent.wav"
merged_audio_path = merge_non_silent(segments, merged_audio)
# 3. 构造参数
wsParam = Ws_Param(
APPID='',
APIKey='',
APISecret='',
AudioFile=merged_audio_path
)
# 4. WebSocket 连接识别
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
多线程并发请求
在分割为多段音频的基础上,采用多线程并发处理的方式,进行音频识别,再将最终的识别结果输出,代码如下:
import os
import json
import base64
import hashlib
import hmac
import ssl
import threading
import time
from datetime import datetime
from wsgiref.handlers import format_date_time
from urllib.parse import urlencode
from time import mktime
import numpy as np
import websocket
from pydub import AudioSegment
# 状态标识
STATUS_FIRST_FRAME = 0
STATUS_CONTINUE_FRAME = 1
STATUS_LAST_FRAME = 2
def is_silence(segment_path, threshold=-45.0):
"""
判断音频文件是否为静音
:param segment_path: 音频路径
:param threshold: 静音能量阈值(单位 dBFS)
:return: True 表示静音,False 表示有声音
"""
try:
audio = AudioSegment.from_file(segment_path)
# 转换为单声道(避免立体声干扰)
audio = audio.set_channels(1)
# 获取 RMS 能量(转换为 dBFS)
rms = audio.rms
if rms == 0:
return True
dbfs = 20 * np.log10(rms / (audio.max_possible_amplitude))
print(f"[{os.path.basename(segment_path)}] 音频能量: {dbfs:.2f} dBFS")
return dbfs < threshold
except Exception as e:
print(f"无法读取音频文件: {segment_path}, 错误: {str(e)}")
return True # 出错时默认认为是静音
class Ws_Param:
def __init__(self, APPID, APIKey, APISecret):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.iat_params = {
"domain": "slm",
"language": "zh_cn",
"accent": "mulacc",
"result": {"encoding": "utf8", "compress": "raw", "format": "json"}
}
def create_url(self):
url = 'wss://iat.cn-huabei-1.xf-yun.com/v1'
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
signature_origin = f"host: iat.cn-huabei-1.xf-yun.com\n" \
f"date: {date}\n" \
f"GET /v1 HTTP/1.1"
signature_sha = hmac.new(
self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256
).digest()
signature_sha = base64.b64encode(signature_sha).decode('utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode('utf-8')
v = {"authorization": authorization, "date": date, "host": "iat.cn-huabei-1.xf-yun.com"}
return url + '?' + urlencode(v)
def split_audio(file_path, segment_duration_ms=10000, output_dir="segments"):
"""将音频切分为指定长度的小段"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
audio = AudioSegment.from_wav(file_path)
segments = []
for i, start in enumerate(range(0, len(audio), segment_duration_ms)):
segment = audio[start:start + segment_duration_ms]
segment_path = os.path.join(output_dir, f"segment_{i}.wav")
segment.export(segment_path, format="wav")
segments.append((i, segment_path))
print(f"音频已分割为 {len(segments)} 段")
return segments
results = {}
lock = threading.Lock()
def recognize_segment(wsParam, file_path, index):
"""识别一个音频片段"""
def on_message(ws, message):
try:
msg = json.loads(message)
code = msg["header"]["code"]
status = msg["header"]["status"]
if code != 0:
print(f"[段 {index}] 请求错误:{code}")
ws.close()
return
payload = msg.get("payload")
if payload and "result" in payload:
result_base64 = payload["result"]["text"]
result_str = base64.b64decode(result_base64).decode("utf-8")
result_json = json.loads(result_str)
text = "".join(cw["w"] for ws_item in result_json.get("ws", []) for cw in ws_item.get("cw", []))
with lock:
results[index] = text
print(f"[段 {index}] 识别结果: {text}")
if status == 2:
ws.close()
except Exception as e:
print(f"[段 {index}] 解析失败: {str(e)}")
def on_error(ws, error):
print(f"[段 {index}] 错误: {error}")
def on_close(ws, *args):
print(f"[段 {index}] 连接关闭")
def on_open(ws):
def run(*args):
frameSize = 1280
intervel = 0.08
status = STATUS_FIRST_FRAME
with open(file_path, "rb") as fp:
while True:
buf = fp.read(frameSize)
if not buf:
status = STATUS_LAST_FRAME
audio = str(base64.b64encode(buf), 'utf-8')
if status == STATUS_FIRST_FRAME:
d = {
"header": {"status": 0, "app_id": wsParam.APPID},
"parameter": {"iat": wsParam.iat_params},
"payload": {"audio": {"audio": audio, "sample_rate": 16000, "encoding": "raw"}}
}
ws.send(json.dumps(d))
status = STATUS_CONTINUE_FRAME
elif status == STATUS_CONTINUE_FRAME:
d = {
"header": {"status": 1, "app_id": wsParam.APPID},
"payload": {"audio": {"audio": audio, "sample_rate": 16000, "encoding": "raw"}}
}
ws.send(json.dumps(d))
elif status == STATUS_LAST_FRAME:
d = {
"header": {"status": 2, "app_id": wsParam.APPID},
"payload": {"audio": {"audio": audio, "sample_rate": 16000, "encoding": "raw"}}
}
ws.send(json.dumps(d))
break
time.sleep(intervel)
threading.Thread(target=run).start()
# 建立连接
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
if __name__ == "__main__":
# 初始化参数
wsParam = Ws_Param(
APPID='',
APIKey='',
APISecret=''
)
# 设置原始音频路径
original_audio_path = r"D:\workspace\qianren\onnx_inference\uploads\output_audio.wav"
# 分割音频
segments = split_audio(original_audio_path, segment_duration_ms=5000)
non_silent_segments = []
for idx, path in segments:
if not is_silence(path):
non_silent_segments.append((idx, path))
else:
print(f"[段 {idx}] 被跳过(静音)")
print(f"共 {len(segments)} 段音频,其中 {len(non_silent_segments)} 段有声音,将被识别")
# 然后只对 non_silent_segments 进行识别
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for idx, path in non_silent_segments:
future = executor.submit(recognize_segment, wsParam, path, idx)
futures.append(future)
wait(futures, return_when=ALL_COMPLETED)
# 合并结果(注意跳过的段不参与合并)
final_text = ""
for i in sorted(results.keys()):
final_text += results[i]
print("\n最终识别结果:\n", final_text)
由于我们是免费用户,最多只能支持2路并发,如果想要提示并发数,你懂的!
实时识别
刚刚我们都是采用音频文件进行识别,那么能否实现实时识别呢,当然可以,但这个效果似乎并不太理想:
这里我们设定如果8秒内检测不到声音,则关闭请求,但博主在测试时发现,采用这种方式的识别效果很差。
import threading
import time
import numpy as np
import websocket
import base64
import json
import ssl
import pyaudio
from datetime import datetime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import hashlib
import hmac
# 状态常量
STATUS_FIRST_FRAME = 0
STATUS_CONTINUE_FRAME = 1
STATUS_LAST_FRAME = 2
SILENCE_THRESHOLD = 500 # 静音阈值(根据麦克风调整)
MAX_SILENCE_DURATION = 8 # 最大允许静音时间(秒)
class Ws_Param:
def __init__(self, APPID, APIKey, APISecret):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.iat_params = {
"domain": "slm",
"language": "zh_cn",
"accent": "mulacc",
"result": {"encoding": "utf8", "compress": "raw", "format": "json"}
}
def create_url(self):
url = 'wss://iat.cn-huabei-1.xf-yun.com/v1'
now = datetime.now()
date = format_date_time(time.mktime(now.timetuple()))
signature_origin = f"host: iat.cn-huabei-1.xf-yun.com\ndate: {date}\nGET /v1 HTTP/1.1"
signature_sha = hmac.new(
self.APISecret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256
).digest()
signature_sha = base64.b64encode(signature_sha).decode('utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode('utf-8')
v = {"authorization": authorization, "date": date, "host": "iat.cn-huabei-1.xf-yun.com"}
return url + '?' + urlencode(v)
def is_silence(data, threshold=SILENCE_THRESHOLD):
"""VAD静音检测"""
audio_data = np.frombuffer(data, dtype=np.int16)
return np.abs(audio_data).mean() < threshold
# WebSocket回调函数(保持不变)
def on_message(ws, message):
try:
msg = json.loads(message)
code = msg["header"]["code"]
if code != 0:
print(f"错误码: {code}, 消息: {msg.get('message', '未知错误')}")
ws.close()
else:
payload = msg.get("payload", {})
if "result" in payload:
result_base64 = payload["result"]["text"]
result_str = base64.b64decode(result_base64).decode("utf-8")
result_json = json.loads(result_str)
text = "".join(cw["w"] for ws_item in result_json.get("ws", []) for cw in ws_item.get("cw", []))
print(f"实时识别: {text}")
if msg["header"]["status"] == 2:
print("识别结束")
except Exception as e:
print(f"解析失败: {str(e)}")
def on_error(ws, error):
print(f"### 连接错误: {error}")
def on_close(ws, close_status_code, close_msg):
print("### 连接关闭 ###")
def on_open(ws):
def audio_capture_thread():
p = pyaudio.PyAudio()
stream = p.open(
format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=1280
)
# 发送头部包(必须)
header_frame = {
"header": {"status": STATUS_FIRST_FRAME, "app_id": wsParam.APPID},
"parameter": {"iat": wsParam.iat_params},
"payload": {"audio": {"sample_rate": 16000, "encoding": "raw"}}
}
ws.send(json.dumps(header_frame))
print("开始录音... (按Ctrl+C停止)")
silence_start = None
try:
while True:
data = stream.read(1280)
# 静音检测
if is_silence(data):
if silence_start is None:
silence_start = time.time()
elif time.time() - silence_start > MAX_SILENCE_DURATION:
print("检测到长时间静音,停止发送")
break
continue
else:
silence_start = None
# 发送数据包(关键修复)
audio_base64 = base64.b64encode(data).decode('utf-8')
data_frame = {
"header": {"status": STATUS_CONTINUE_FRAME, "app_id": wsParam.APPID},
"payload": {"audio": {"audio": audio_base64}}
}
ws.send(json.dumps(data_frame))
except KeyboardInterrupt:
print("用户停止录音")
except Exception as e:
print(f"捕获异常: {str(e)}")
finally:
# 确保发送尾部包
trailer_frame = {
"header": {"status": STATUS_LAST_FRAME, "app_id": wsParam.APPID},
"payload": {"audio": {"status": 2}}
}
ws.send(json.dumps(trailer_frame))
# 安全关闭音频流
if stream.is_active():
stream.stop_stream()
stream.close()
p.terminate()
print("音频设备已释放")
# 启动音频线程
threading.Thread(target=audio_capture_thread, daemon=True).start()
if __name__ == "__main__":
# 配置参数(替换为你的凭证)
wsParam = Ws_Param(
APPID='',
APIKey='',
APISecret=''
)
# 建立WebSocket连接
ws_url = wsParam.create_url()
ws = websocket.WebSocketApp(
ws_url,
on_message=on_message,
on_error=on_error,
on_close=on_close
)
ws.on_open = on_open
print("连接语音识别服务...")
# 关键修复:添加心跳维持连接
ws.run_forever(
sslopt={"cert_reqs": ssl.CERT_NONE},
ping_interval=25, # 25秒发送一次ping
ping_timeout=10, # 10秒未响应视为超时
ping_payload="\x09" # WebSocket ping操作码
)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)