RAGFlow、Dify、FastGPT、Cherrystudio、Anythingllm比较及部署教程
以下是 RAGFlow、Dify、FastGPT、Cherry Studio 和 AnythingLLM 五款工具的详细对比,结合核心定位、技术特点、适用场景等维度
1.各大AI平台工具比较
以下是 RAGFlow、Dify、FastGPT、Cherry Studio 和 AnythingLLM 五款工具的详细对比,结合核心定位、技术特点、适用场景等维度,助你快速决策:
📊 核心功能与定位对比
| 工具 | 核心定位 | 核心优势 | 适用场景 |
|---|---|---|---|
| RAGFlow | 企业级复杂文档处理专家 | - 深度文档理解(扫描件/表格/影印件) - 多路召回+重排序优化,高精度检索 - 支持复杂格式解析(OCR/表格识别) |
法律合同审查、医疗报告分析、金融财报解析 |
| Dify | 低代码AI应用工厂 | - 可视化工作流编排(Chatflow/Workflow) - 支持数百种模型(开源/闭源) - 灵活Agent框架与插件扩展 |
智能客服系统、多模型A/B测试、营销内容生成 |
| FastGPT | 轻量级问答部署利器 | - 开箱即用知识库问答 - 预设模板快速配置 - 低资源消耗(2核8G可运行) |
教育FAQ、电商客服、企业内部知识库 |
| Cherry Studio | 轻量原型工具 | - 桌面端零配置运行 - 多模型集成(30+开源模型) - 拖拽式操作 |
小微团队创意验证、个人知识管理 |
| AnythingLLM | 全栈私有化方案 | - 数据100%本地化 - 企业级权限管理(多用户/工作区隔离) - 支持200+文档格式 |
法律案例库、制造业工艺文档管理 |
⚙️ 关键技术能力对比
| 维度 | RAGFlow | Dify | FastGPT | Cherry Studio | AnythingLLM |
|---|---|---|---|---|---|
| 文档处理 | ✅ 复杂格式(扫描件/表格) | ⚠️ 基础文本解析 | ⚠️ 基础文本解析 | ⚠️ 常见格式(PDF/Word) | ✅ 多格式(200+) |
| 检索精度 | ✅ 多路召回+LLM重排序 | ⚠️ 向量检索依赖外部模型 | ⚠️ 基础向量检索 | ⚠️ 基础检索 | ⚠️ 常规向量检索 |
| 模型支持 | ❌ 依赖内置RAG流程 | ✅ 数百种模型自由切换 | ✅ 主流模型(OpenAI/ChatGLM) | ✅ 多API集成(DeepSeek等) | ✅ 本地/云端模型混合部署 |
| 隐私安全 | ✅ 本地部署+数据控制 | ⚠️ 需配置私有化 | ⚠️ 依赖部署方式 | ✅ 完全本地化 | ✅ 全链路数据不离开本地 |
| 部署复杂度 | ⚠️ 高(16G+内存) | ⚠️ 中(Docker/K8s) | ✅ 低(一键Docker) | ✅ 极低(桌面应用) | ✅ 中(桌面/Docker) |
🎯 适用场景与用户推荐
-
选择 RAGFlow 若:
- 需处理法律合同、医疗影像等专业文档,对答案准确性要求严苛;
- 企业有高并发需求且预算充足(适合大型团队)。
- 深度文档解析能力+多路召回策略,答案准确性和可追溯性最佳
-
选择 Dify 若:
- 需快速搭建多模型协作应用(如智能客服、自动化数据分析);
- 开发者需低代码工具实现复杂业务流程。
- 可视化编排+生态整合能力,适合技术团队快速迭代
-
选择 FastGPT 若:
- 追求48小时内上线问答系统(如电商客服);
- 中小项目资源有限,需性价比较高的轻量方案。
-
选择 Cherry Studio 若:
- 个人或5人以下团队快速验证AI创意(如竞品分析库);
- 非技术人员需要零配置桌面工具。
- 中小型知识库优化,需结合特定嵌入模型提升回答质量
- 测试中表现优于AnythingLLM,适合对回答全面性要求较高的场景
-
选择 AnythingLLM 若:
- 数据隐私绝对优先(如政府/金融内部知识库);
- 需多部门工作区隔离与权限管控(50人内团队)。
- 完全本地化部署,开箱即用,适合非技术用户
💎 总结建议
- 企业级复杂文档处理 → RAGFlow(精度碾压);
- 快速开发AI应用 → Dify(生态最灵活);
- 轻量级知识库上线 → FastGPT(部署最快);
- 个人/小微团队原型验证 → Cherry Studio(无需部署);
- 全私有化数据安全 → AnythingLLM(隐私天花板)。
💡 提示:工具选型需综合文档复杂度、开发资源、隐私等级三要素。例如:医疗机构处理扫描报告选RAGFlow,初创公司做智能客服选Dify或FastGPT。
2.RAGFlow部署流程
- Windows系统安装wsl:
- 打开程序和功能中的虚拟机平台和适用于linuxs的window子系统。
- 下载wsl即应用商店下载Ubuntu,打开设置账户密码。
- cmd-----wsl -l -v 用wsl2版本。Win10需要升级为2。
- 设置默认为wsl2版本:wsl --set-default-version 2
- 安装docker desktop设置里的resources里更改镜像存储位置。应用后重启。
- 创建RAGFLOW容器或者叫环境。
- 检查值max_map_count要不小于262144:
- wsl -d docker-desktop -u root
- sysctl vm.max_map_count。
- 小于时要修改,vi /etc/sysctl.conf。修改后保存退出,使用sysctl -p重启服务
- 下载代码https://github.com/infiniflow/ragflow:download.zip,解压编辑/docker/.env,找到RAGFLOW_IMAGE。注释掉RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0-slim。去掉注释的# RAGFLOW_IMAGE=infiniflow/ragflow:v0.18.0。因为带有slim的里边没有嵌入模型,要下带有嵌入模型的。
- 下载嵌入模型。Cmd进入ragflow-main/docker。执行命令:docker compose -f docker-compose.yml up -d(会下载5个服务ragflow-es-01\ragflow-mysql\ragflow-minio\ragflow-redis\ragflow-server).如果下载不下来如下下操作:
- 检查值max_map_count要不小于262144:
在dockers engine中添加镜像源:
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://registry.docker-cn.com",
"https://cr.console.aliyun.com",
"https://mirror.ccs.tencentyun.com",
"https://huecker.io/",
"https://dockerhub.timeweb.cloud",
"https://noohub.ru/",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn",
"https://xx4bwyg2.mirror.aliyuncs.com",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
添加界面如图:
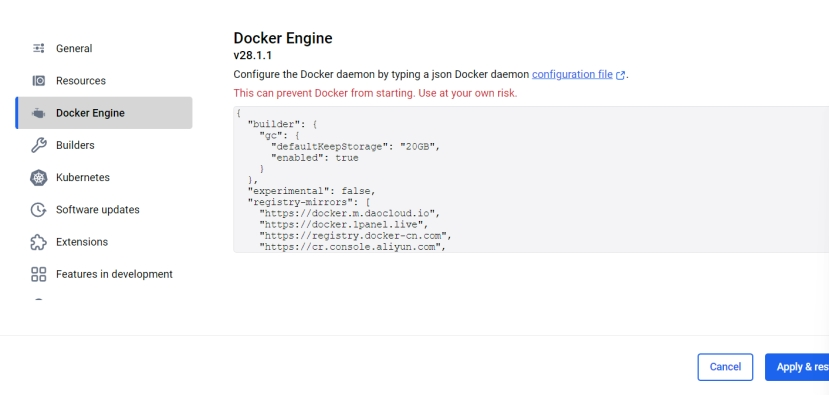
- 修改后,apply&restart,再执行下载命令就可以了。
这样Ragflow就安装完了。Docker上可以看到刚才下的5个服务可以运行了,然后浏览器进入127.0.0.1即可进入。
- 配置模型。浏览器进入127.0.0.1后
- cmd:ollama pull nomic-embed-text 拉取嵌入向量模型
- 配置嵌入向量模型
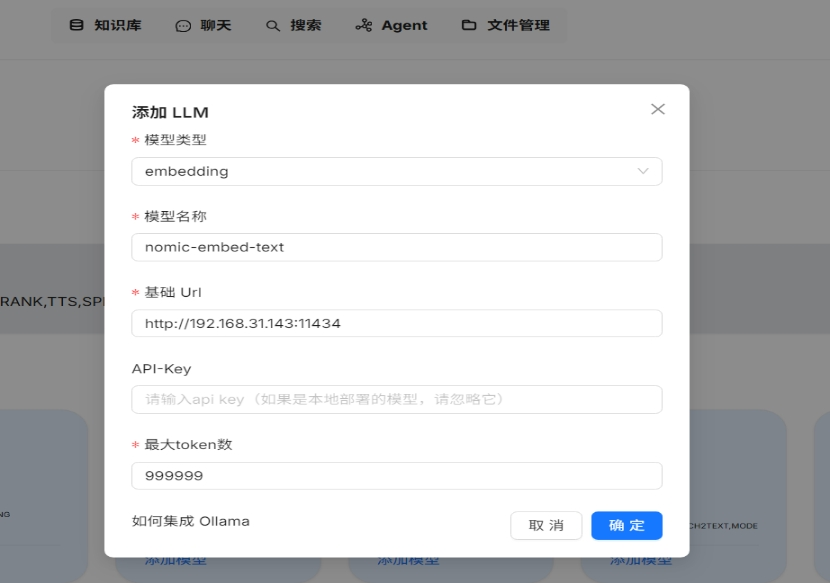
同样道理添加chat模型:deepseek-r1:14b
注意:要把上述添加的模型,添加到默认设置里。
- 创建知识库:然后创建添加文件即可
3. dify 部署流程
-
git clone https://github.com/langgenius/dify.git
或者git clone https://gitee.com/dify_ai/dify.git 下载源码
-
进入到下载的docker文件夹内,把.env.example文件名改为.env
-
在当前目录cmd,执行
docker compose -p <工程命> up -d命令。通过docker compose部署Dify,Docker会自动拉取Dify所需的依赖。 -
在 Dify 里面,上传文件会有 15M 的单个限制,需要改个配置。
-
打开 docker 文件夹里的
.env文件,把下面两条的15改成150即可:
# Upload file size limit, default 15M.
UPLOAD_FILE_SIZE_LIMIT=15
NGINX_CLIENT_MAX_BODY_SIZE=15M
4.Fastgpt部署教程
-
git clone https://gitee.com/mirrors/FastGPT.git 下载源码
-
进入到
files/docker文件夹,使用里面的 Docker 配置。
与 Dify 不同,FastGPT 需要一些额外配置。默认情况下没有 docker-compose.yml 文件,因此启动时需要指定,例如官方推荐的 docker-compose-pgvector.yml。此外,还需要创建一个 config.json 配置文件放在 docker 目录下
-
配置好后,执行以下命令来启动:
docker compose -f docker-compose-pgvector.yml up -d完成后,可以通过浏览器访问
http://localhost:3000来使用 FastGPT。
FastGPT 的配置比 Dify 稍微复杂一些,需要在 http://localhost:3001 配置模型,并修改 config.json 来匹配你的需求。
修改config.json文件中的mcpServerProxyEndpoint值,设置成mcp server的公网可访问地址,yml 文件中默认给出了映射到 3005 端口,如通过 IP 访问,则可能是:120.172.2.10:3005。
- 配置模型
首次登录FastGPT后,系统会提示未配置语言模型和索引模型,并自动跳转模型配置页面。系统必须至少有这两类模型才能正常使用。
FastGPT 模型配置页面地址是 http://localhost:3001,默认账号是 root,密码是 123456。
- 访问Fastgpt
目前可以通过 ip:3000 直接访问(注意开放防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的 DEFAULT_ROOT_PSW。或者密码可以在 config.json 中找到,默认是 1234。
如果需要域名访问,请自行安装并配置 Nginx。
————————————————
其他问题
- 如果系统未正常跳转,可以在
账号-模型提供商页面,进行模型配置。点击查看相关教程 - 目前已知可能问题:首次进入系统后,整个浏览器 tab 无法响应。此时需要删除该tab,重新打开一次即可。
5. Cherrystudio部署教程
安装包直接安装
6. AnythingLLM 部署
直接安装
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献476条内容
已为社区贡献476条内容

所有评论(0)