AI一本通(从底层到上层)
AI大模型从底层到上层
一、服务器
(一)服务器历史

大型机时代:服务器都是专用系统,兼容性差,可运行的系统少,但其最大优点是稳定。
x86时代:x86计算机的出现将服务器从大型机时代带到了x86时代,此时服务器是通用品,成了普通的硬件盒子。产业链实现了分工,服务器主板、三大件、各种配件灵活搭配,成本一降再降,兼容性特别好,但是稳定差。【此时因为企业的业务丰富了,一两台大型机也搞不定业务需求,因此x86计算机的通用性非常符合当时的业务需要,此时x86一家独大。】
AI时代:x86通用服务器虽然通用性好,但必然会丧失性能和稳定性,于是英伟达公司在做芯片的情况下,走向了整机甚至整柜市场,一个做芯片的公司,把整机厂家的工作都给做了。有人戏称,大型机又回来了。
(二)服务器分类
按形态分类:
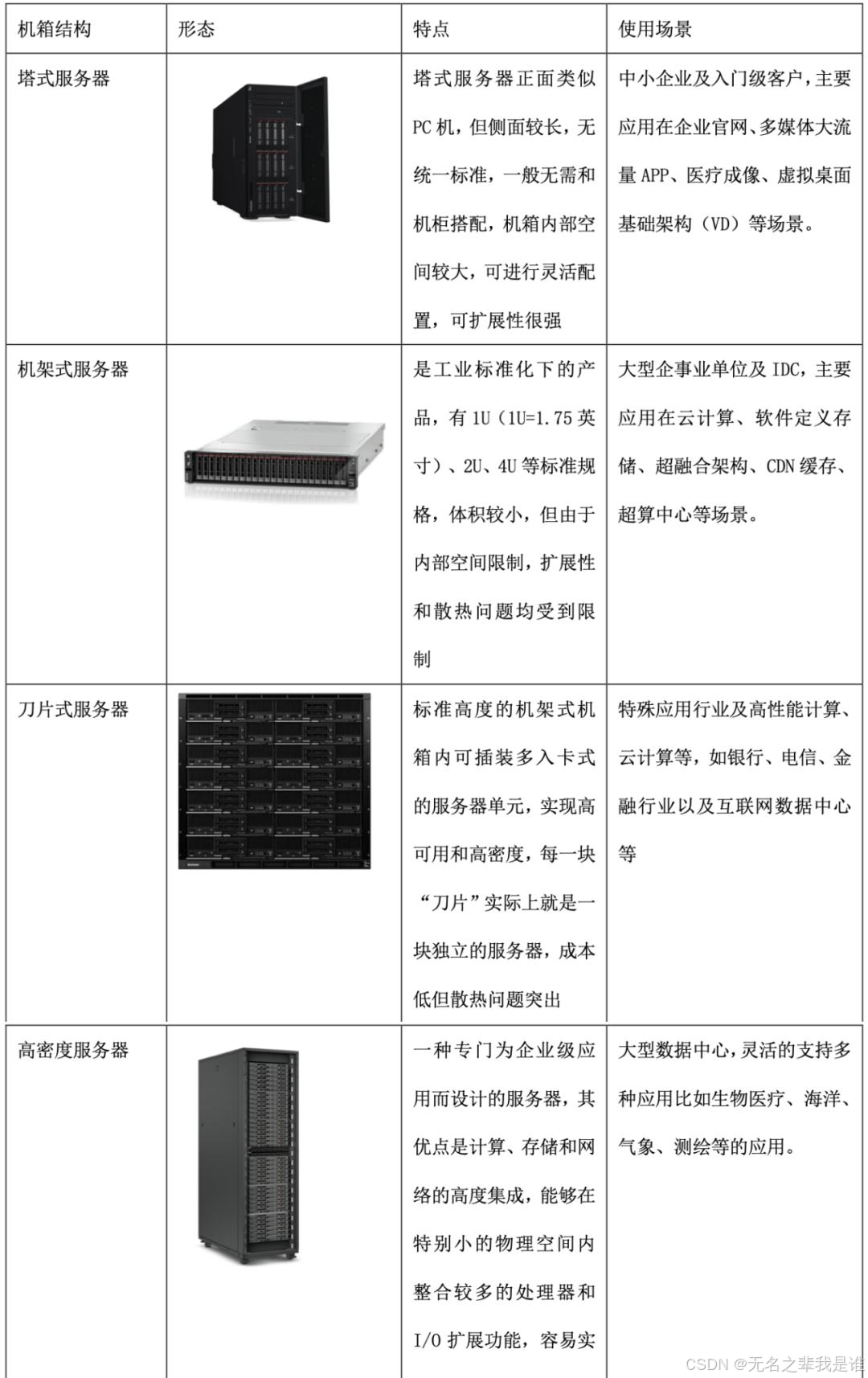
| 存储服务器 |  |
||
| GPU服务器 |  |
从硬件配置的角度来看,GPU服务器和普通服务器有着本质的不同。普通服务器通常配备中央处理器(CPU)、内存、硬盘等基本组件,用于承载和运行各种应用程序和服务。这些服务器通常使用标准的x86架构,硬件配置具有一定的扩展性,可以根据需求扩展存储容量、内存和处理能力等。 GPU服务器则在此基础上增加了高性能的图形处理器(GPU)这一重要组件。GPU是一种专门用于处理图形和并行计算任务的处理器,具有大量的核心和并行计算能力。这使得GPU服务器能够在短时间内完成大量的计算任务,尤其是在处理大规模并行计算和数据处理任务时表现出色。 |
GPU服务器和普通服务器在应用场景方面也存在明显的差异。GPU服务器因其强大的计算能力而被广泛应用于科研和工程领域。例如,在气象预测、石油勘探、基因测序等领域,GPU服务器可以提供高性能的计算支持,帮助科研人员更快地获得准确的结果。此外,GPU服务器还适用于深度学习、人工智能、大规模数据分析、密码学、视频渲染等对计算性能要求较高的应用场景。 |
(三)服务器组成
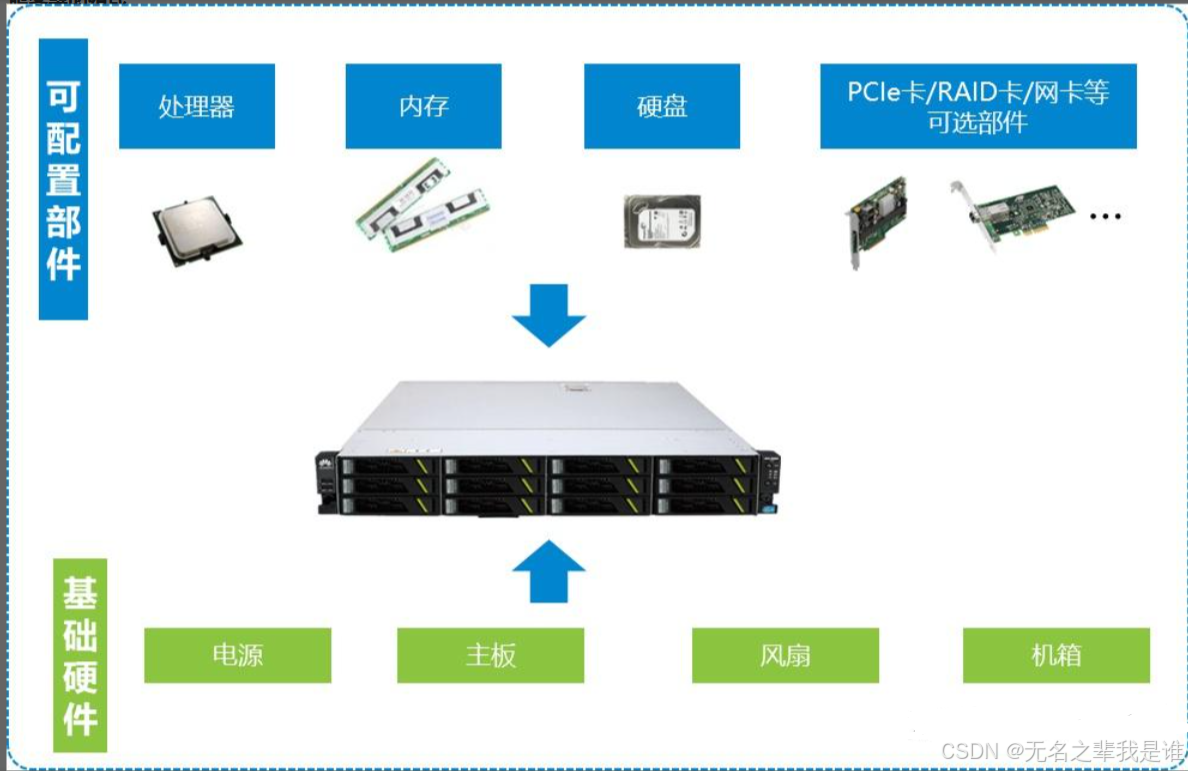
基础硬件:这些东西是服务器整机厂商提供的,包括主板、电源、风扇和机箱。
三大件等扩展配件:三大件指的CPU、内存和硬盘,这三件是服务器最贵的三个部件,现在GPU也是重要的部件了,其他还包括网卡、Raid卡等其他部件。
二、处理器
处理器与服务器的区别与联系:
1、服务器是一种计算机设备,用于管理、存储和处理数据,并为其他设备或用户提供网络服务;处理器是计算机的核心组件,负责执行程序指令和进行数据处理。
2、服务器通常包含一个或多个高性能处理器作为其核心计算单元。
3、处理器的性能和配置直接影响服务器的整体性能和服务质量。
芯片和CPU处理器的关系:
1、芯片:也称为集成电路(Integrated Circuit, IC),是一种将大量晶体管、电阻器、电容器等微型电子元件封装在一个微小的硅片上的技术。2、芯片类型:根据功能和结构的不同,芯片可以分为处理器芯片、存储芯片、信号处理芯片等。
3、CPU处理器:CPU处理器属于处理器芯片的一种,本质上是一种特殊的芯片。它集成了大量的逻辑门、寄存器和控制电路,用于执行指令和处理数据。
4、芯片和CPU处理器的关系:芯片是一个广泛的概念,包括了CPU在内的各种功能芯片。
广义上来说,芯片有处理器芯片,处理器芯片又包含CPU处理器,并且CPU处理器是芯片的核心成员。
5、芯片之间的联系:CPU负责执行操作系统和应用程序的指令,而其他类型的芯片(如内存芯片、显卡芯片等)则提供必要的支持和辅助功能。CPU通过总线与其他芯片进行通信,协调各个部件的工作,确保整个系统的正常运行。
【注:此处以说的处理器仅指CPU处理器,但处理器并不只有CPU,只是处理器从CPU发展,随着大数据AI的崛起,近年来才发展出来GPU、NPU、DPU、LPU等】
(一)处理器分类
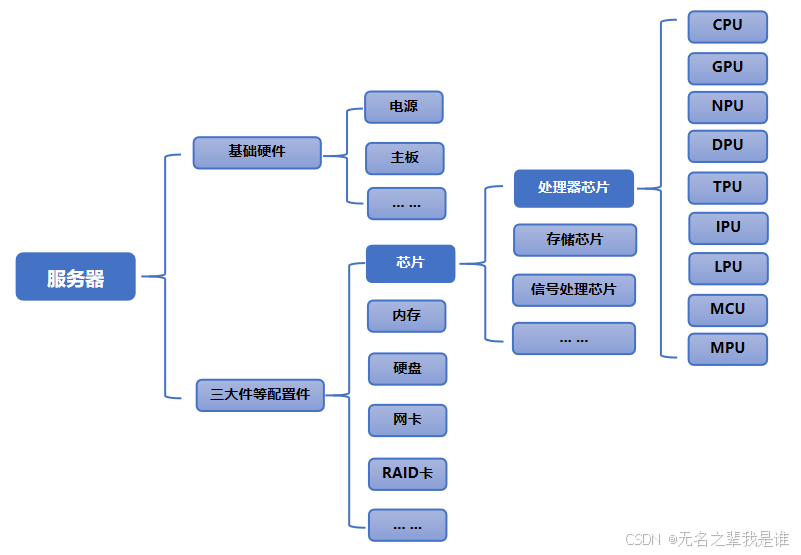
前文已经讲过,处理器和芯片的关系,可以粗泛的认为处理器芯片就是处理器。接下来以CPU、GPU、NPU、DPU、TPU、IPU、LPU、MCU、MPU 这9大主流处理器芯片展开论述。
| 芯片 | 架构设计 | 功能侧重 | 应用场景 |
| CPU | (中央处理器):采用复杂指令集(CISC)或精简指令集(RISC)架构,注重通用性和顺序执行能力,具备丰富的运算逻辑单元和复杂的控制单元,以应对复杂的任务调度和多样化的计算需求。 | 作为计算机的核心,负责整体的系统控制和复杂逻辑运算,能处理各种类型的任务,包括操作系统管理、应用程序运行、数据处理等。 | 广泛应用于各种通用计算机,如个人电脑、服务器、大型机等,是计算机系统不可或缺的核心组件。 |
| GPU |
(图形处理器):拥有大量的计算核心,采用并行计算架构,适合处理大规模的图形数据和并行计算任务,如 3D 渲染、科学计算等。 |
主要用于图形处理,如生成、渲染和显示图像,在 3D 游戏、动画制作、虚拟现实(VR)、增强现实(AR)等领域发挥关键作用,也可用于通用并行计算(GPGPU)。 | 在游戏主机、图形工作站、数据中心的深度学习训练、科学计算等领域应用广泛,是实现高质量图形渲染和大规模并行计算的关键。 |
| NPU |
(神经网络处理器):专为神经网络算法设计,采用独特的架构,包含大量的乘累加单元(MAC)和存储单元,能够高效地执行深度学习算法中的矩阵运算和卷积运算。 |
专注于神经网络计算,能够快速处理深度学习算法中的数据,广泛应用于图像识别、语音识别、自然语言处理等人工智能领域。 | 主要应用于人工智能领域,如智能安防摄像头、智能语音助手、自动驾驶汽车等,实现对图像、语音、文本等数据的智能处理。 |
| DPU |
(数据处理器):强调对数据的快速处理和转发,具备硬件加速引擎,可对网络数据进行高效的解析、过滤和转发,以减轻 CPU 的负担。 |
专注于数据处理,尤其是网络数据的处理,负责网络数据包的解析、过滤、转发等,提高数据传输和处理的效率,常用于数据中心和网络设备中。 | 主要应用于数据中心、网络设备等,用于加速网络数据处理和存储访问,提高数据中心的性能和效率。 |
| TPU |
(张量处理器):为加速深度学习中的张量运算而设计,采用脉动阵列(Systolic Array)架构,能够高效地执行大规模的矩阵乘法和卷积运算,大幅提高深度学习的计算效率。 |
专为深度学习中的张量计算而设计,在训练和推理过程中,能够提供比 CPU 和 GPU 更高的计算效率,加速深度学习模型的运行。 | 主要应用于谷歌的深度学习框架和相关人工智能应用中,为深度学习模型的训练和推理提供高效的计算支持。 |
| IPU |
(智能处理器):基于 MIMD(多指令多数据)架构,拥有独特的环型网络结构和大量的处理单元,能够实现高效的并行计算和数据处理。 |
旨在为人工智能应用提供高效的计算支持,能够同时处理多个任务,在机器学习、数据分析等领域表现出色。 | 适用于各种需要高效处理人工智能任务的场景,如数据分析、机器学习、智能安防等。 |
| LPU | (学习处理器):架构设计侧重于对学习算法的优化,具备可重构的计算单元和存储结构,能够根据不同的学习任务进行灵活调整。 | 主要用于执行学习算法,如机器学习、深度学习算法,能够根据数据进行学习和优化,适用于智能设备和自主学习系统。 | 常用于智能设备和自主学习系统,如智能家居设备、智能机器人等,实现设备的自主学习和智能控制。 |
| MCU |
(微控制器):通常采用哈佛架构或冯・诺依曼架构,集成了处理器内核、存储器、输入输出接口等功能模块,结构相对简单,注重低功耗和低成本。 |
主要用于控制和监测,集成了微处理器、存储器、输入输出接口等,广泛应用于各种嵌入式系统,如智能家居、工业控制、汽车电子等。 | 广泛应用于各类嵌入式系统,如智能家居设备、工业自动化控制系统、汽车电子系统、医疗设备等,负责设备的控制和监测。 |
| MPU |
(微处理器):基于通用的处理器架构,如 ARM 架构等,具备较强的处理能力和丰富的接口,可运行复杂的操作系统和应用程序。 |
强调数据处理能力,可运行复杂的操作系统和应用程序,常用于智能设备、平板电脑、工业计算机等。 | 常用于智能设备、平板电脑、工业计算机、网络设备等,作为核心处理器运行复杂的操作系统和应用程序。 |
(二)CPU处理器
1、CPU十大品牌

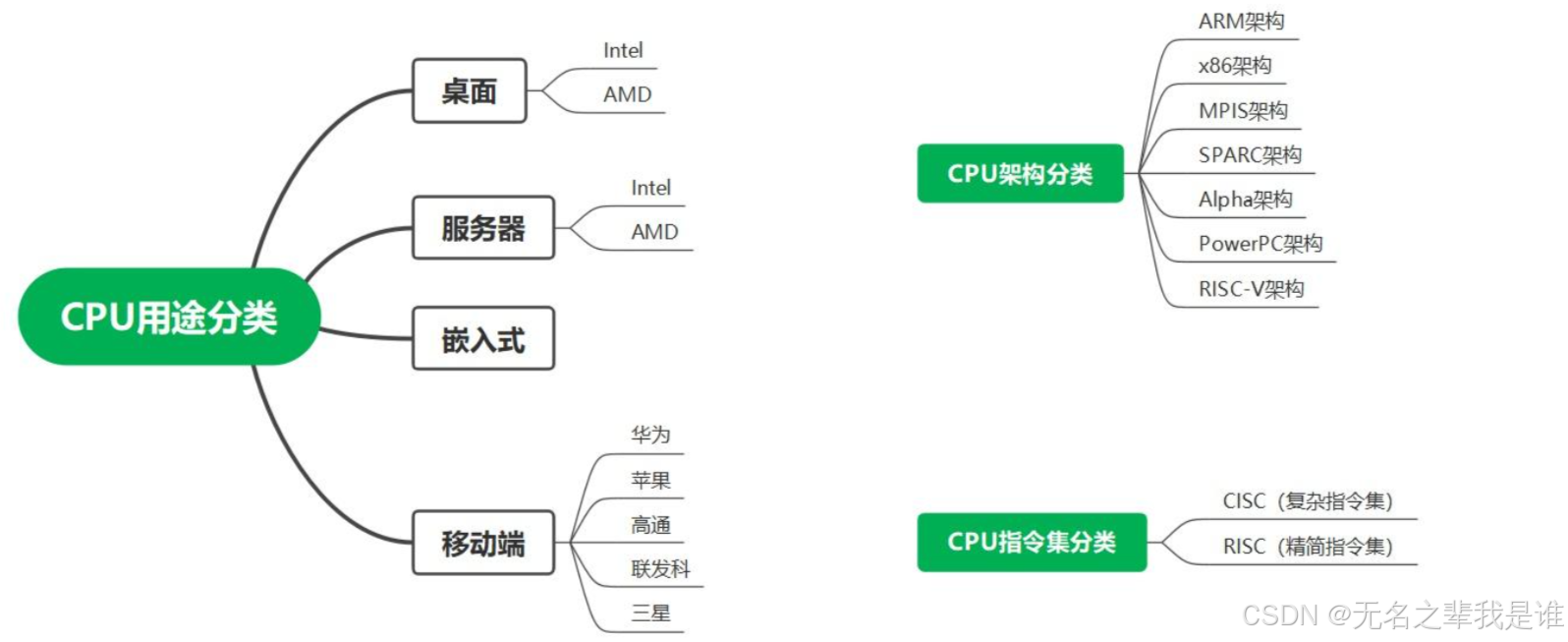
2、CPU分类
3、CPU主要结构
寄存器:是中央处理器内的组成部分。它们可以用来暂存指令、数据和地址。可以将其看作内存的一种。根据种类的不同,一个CPU内部会有20-100个寄存器。
控制器:负责内存上的指令、数据读入寄存器,并根据指令的结果控制计算器。
运算器:负责运算从内存中读入寄存器的数据。
时钟:负责发送CPU开始计时的时钟信号 。
4、CPU架构
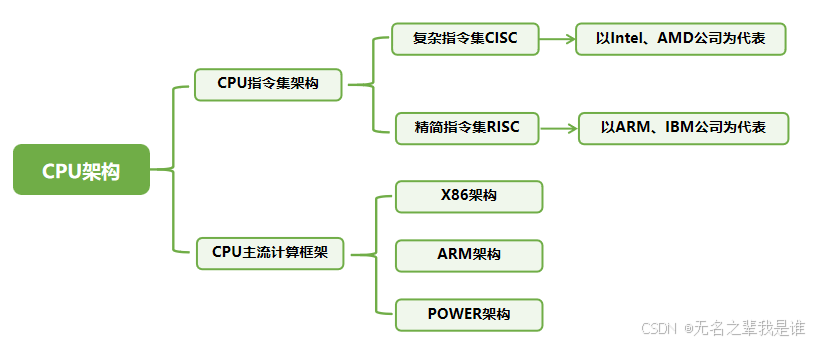
(1)CPU指令集架构
一是以Intel、AMD为代表的复杂指令集(CISC),采用X86架构;
二是ARM、IBM代表的精简指令集(RISC),ARM公司采用ARM架构,IBM采用POWER架构。
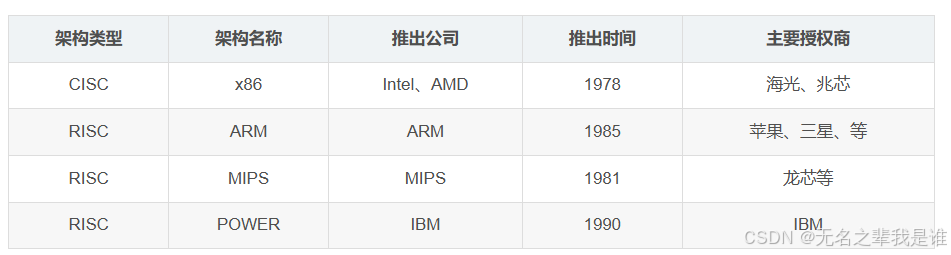 (2)CPU主流计算架构
(2)CPU主流计算架构
主流的计算架构主要有X86、ARM和POWER三种:
X86架构:属于封闭的硬件架构,Intel和AMD对外基本不授权,在技术演进方向、节奏、供应等方面均由个别公司主导和把控,但生态应用已经非常完备。
ARM架构:是开放的硬件架构,ARM公司采取积极的商业策略,向众多合作伙伴授权开发,共同营造ARM端到端生态,这个产业链也趋于完善。
POWER架构:由IBM主导,应用领域主要集中在超算和认知计算领域,存在应用开发者少、生态弱和可持续发展能力不足的短板。
【更多CPU知识可参考:计算机组成原理——CPU的结构和功能_cpu结构图-CSDN博客】
【指令集和架构的参考知识:指令集,架构,都是什么意思? - o蹲蹲o - 博客园】
(三)GPU处理器
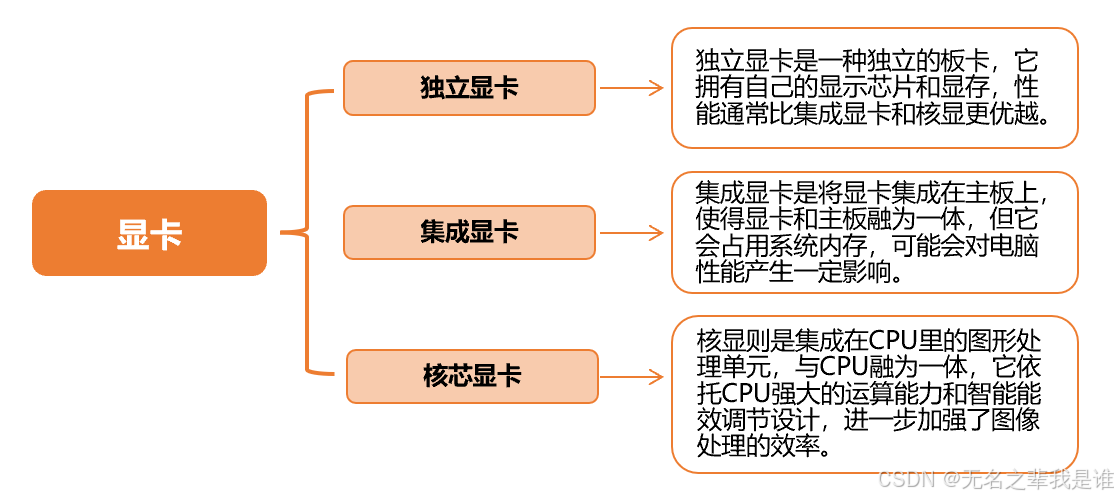
GPU与显卡的区别:
显卡:也被称为显示卡,是计算机中至关重要的组件之一,其主要职责是负责处理和输出显示图形任务。其工作原理涉及对由CPU提供的指令和数据进行相应处理,将其转换成显示器能够接受并展示的文字或图像。【显卡知识补充:百度安全验证】
GPU:即图形处理器,是显卡的核心芯片,专门用于处理图形数据和进行图形运算。GPU 在处理图形渲染、图像视频解码等方面具有强大的并行计算能力,能够快速处理大量的图形数据,生成高质量的图像和视频内容。
显卡不但包含GPU,同时还包含显存、供电电路、散热系统等多个组件的硬件设备,而 GPU 是显卡的核心部件。
显卡和芯片的区别:
显卡包含GPU芯片,但又不包含全部的芯片,所以他俩的关系应该是数学中 ∩ 的关系。协同工作:芯片和显卡在计算机中是协同工作的。CPU负责处理大部分的计算任务,而GPU则专注于图形处理。当需要处理复杂的图形数据时,CPU会将任务分配给GPU,GPU完成处理后再将结果返回给CPU。
性能互补:芯片和显卡的性能是相互补充的。一个高性能的CPU可以更快地处理数据并发送给GPU,而一个高性能的GPU则可以更快地渲染图像。因此,在选择计算机配置时,需要根据使用需求来平衡CPU和GPU的性能。
集成与独立:值得注意的是,有些计算机中的显卡是集成在芯片上的(如集成显卡),这种设计可以降低成本和功耗,但性能可能不如独立显卡。独立显卡则拥有自己独立的GPU和显存,可以提供更好的图形处理性能。
【补充知识:芯片、GPU、CPU、显卡、显存、x86、ARM、AMD等基础知识】
1、GPU十大品牌

2、显卡的分类
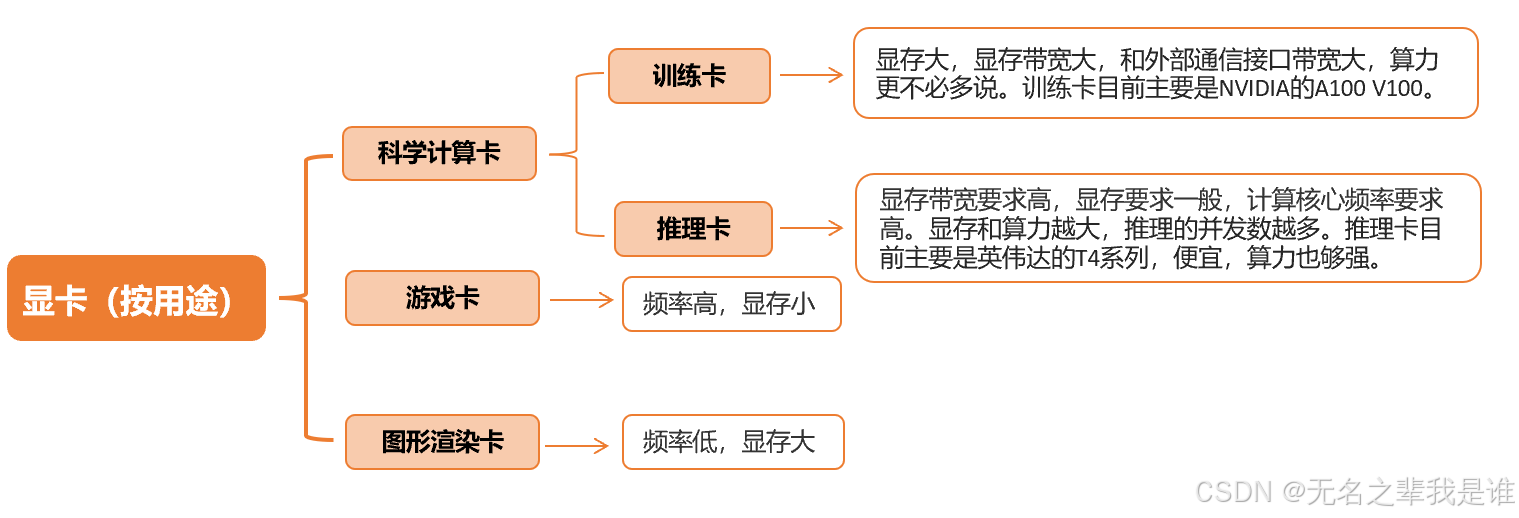
不同用途的显卡性能区别:
- 显存带宽;
- 显存容量;
- 显卡计算核心数量;
- 显卡计算核心频率;
- 显卡高精度计算能力(float64);
- 显卡低精度计算能力(float32/float16/int8);
- 显卡的多卡互联能力;
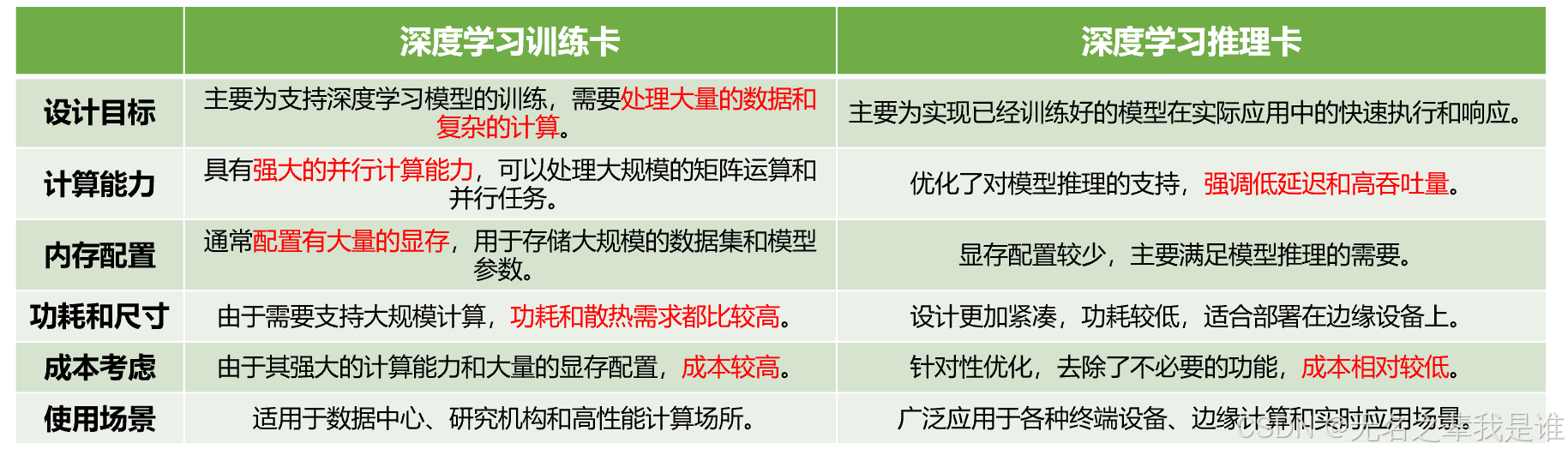
训练卡和推理卡的区别:
明白了神经网络训练和推理时的差别,就知道对GPU的需求的差别了
神经网络训练:通常使用随机梯度下降算法,显存中除了加载模型参数,还需要保存中间状态,主要是梯度信息,相比推理,显存需求要增加几倍,显存要够大才能跑起来;要训练好的模型,需要使用大量数据,大量数据要读入显存,显存带宽要够大;另外对于当前的大数据量,单卡已经无法满足要求,要用多卡集群训练;集群训练要在多机间通信,要交换大量数据,要支持更高的通信带宽;接口一般用NVLINK,通常还要GPU支持RDMA特性,能够直接在显存和通信卡内存间搬数据。
训练卡:要求显存大,显存带宽大,和外部通信接口带宽大,算力就不说了,都不是主要考虑问题了,训练卡目前主要是NVIDIA的A100和V100。
推理卡:算力和显存平衡就可了,模型能装的进去,把算力跑起来,推理卡英伟达的T4便宜,算力也够强。
训练卡 :侧重于高精度、大显存、强算力,满足复杂模型的训练需求。
推理卡 :侧重于低精度、小显存、低延迟,满足高效部署和实时响应的需求。
3、常见显存(GPU)系列
训练卡:
英伟达(NVIDIA)的 H100/H800/A100/A800几种为主,目前国内价格在10-30 万元每张居多。
华为的昇腾910B
推理卡:
英伟达的有 4060/4090/3060/3080/3090 等型号,价格在几千到两万左右不等。
华为的Atlas 300 系列
总的来说:推理可以用训练卡,训练不可以用推理卡。
三、大模型
(一)大模型架构
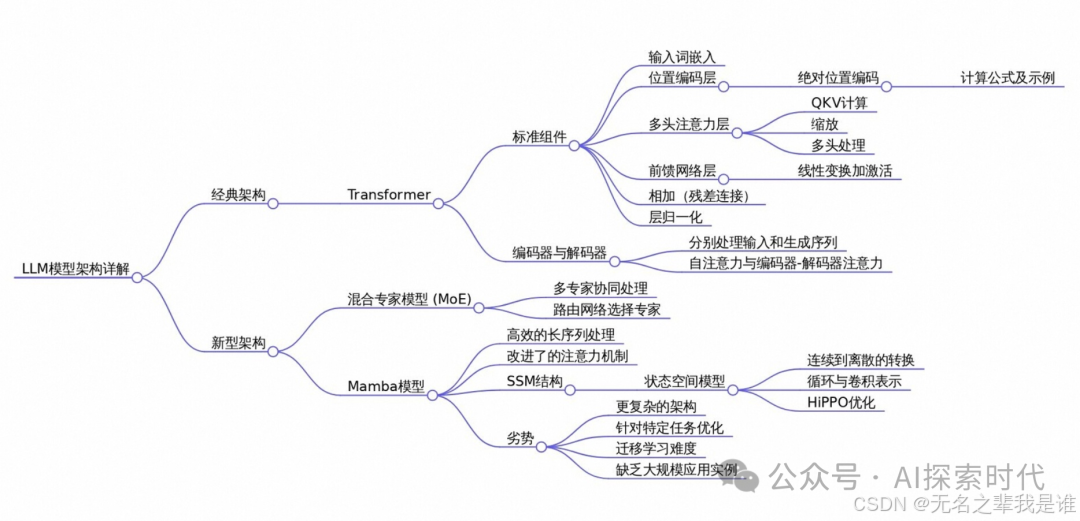
1、核心基础架构
(1)Transformer架构
采用自注意力机制替代传统RNN/LSTM结构,支持并行计算且擅长捕捉长距离依赖关系,是当前大模型的主流基础架构,典型代表包括GPT系列和BERT3。
关键组件包含:多头注意力机制(增强模型表示能力)、位置编码(弥补序列顺序信息缺失)
(2)BERT(双向编码器)
基于Transformer的双向预训练模型,通过遮蔽语言模型任务捕捉上下文语义关系,同时考虑左侧和右侧的上下文,增强了理解能力。适用于文本分类、问答等任务。
优缺点:
优点:双向编码器能够更好的理解上下文,尤其适合理解复杂的语言现象
缺点:生成能力较弱,主要适用于理解认为;模型计算成本较高
(3)GPT(生成式预训练模型)
GPT是一种基于Transformer的自回归模型,通过自回归生成方式处理文本生成类任务,典型代表如GPT-3/4系列模型3。与BERT不同,GPT是单向的,采用单向Transformer解码器结构,即只使用过去的上下文来预测当前的单词。
(4)T5(统一文本转换框架)
将各类NLP任务统一为文本到文本的转换模式,通过前缀标识区分任务类型,实现多任务统一建模。可以将所有任务都转换为文本生成任务;例如翻译任务中的输入是原文,输出是译文;文本分类任务中的输入是句子,输出是类别标签。
优缺点:
优点:统一框架便于跨任务的知识迁移,模型更具有通用性
缺点:对生成任务过于依赖,可能不适合一些特定的理解任务
2、应用架构模式
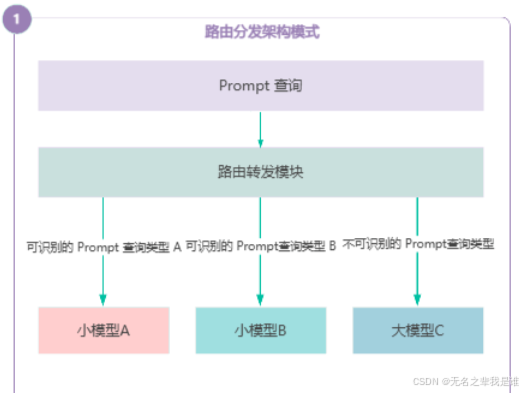
(1)路由分发架构
通过控制中心对用户查询进行分类,将简单任务路由至小模型处理,复杂任务由大模型处理,平衡成本与性能。
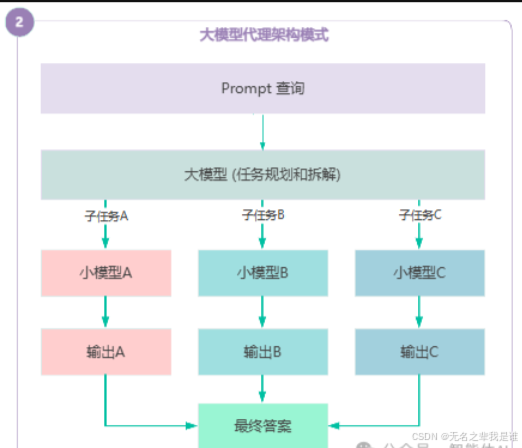
(2)大模型代理架构
大模型作为主代理协调多个专业小模型,分别处理子任务后整合结果,适用于复杂问题拆解场景。
(3)多任务微调架构
对单一模型进行多任务联合微调,增强模型泛化能力,适用于虚拟助手等需多领域处理的应用。
(4)知识蒸馏架构
将大模型知识迁移至轻量小模型,降低部署成本,常用于边缘计算场景。
(5)知识图谱融合架构
结合知识图谱增强大模型的事实准确性,输出内容兼具生成能力与事实依据,适用于医疗、金融等领域。
(6)五层技术架构(系统级设计)
包含应用层(智能文档审核等)、服务开发层(API接口)、推理部署层、模型层(算法优化)及基础设施层(硬件支持),形成端到端技术生态。
【另一种分类:大模型应用架构选择指南:六大模式深度解析】
(二)DeepSeek
参考学习文档:
DeepSeek系统架构的逐层分类拆解分析,从底层基础设施到用户端分发全链路
参考引用:
[1] 链接:https://www.zhihu.com/question/21440463/answer/61043728896
[2] 链接:https://zhuanlan.zhihu.com/p/24732116109
[3] 链接:https://zhuanlan.zhihu.com/p/663771560
[4] 链接:https://blog.csdn.net/m0_73384617/article/details/139887883
[5] 链接:https://blog.csdn.net/weixin_42463871/article/details/105268449
[6] 链接:https://www.cnblogs.com/liqi175/p/17903419.html
[7] 链接:https://blog.csdn.net/hao_wujing/article/details/144820794
[8] 链接:https://www.cnblogs.com/xyz/p/18002495
[9] 链接:https://developer.aliyun.com/article/1259910
[10] 链接:https://zhuanlan.zhihu.com/p/660105712
[11] 链接:https://blog.csdn.net/timonium/article/details/145709918
[12] 链接:https://blog.csdn.net/2401_82505179/article/details/145424651
[13] 链接:https://blog.csdn.net/2401_85373691/article/details/141668748
[14] 链接:https://blog.csdn.net/2401_85325726/article/details/141900154

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)