构建语音情感识别系统
情感识别技术是通过分析语音信号中的情绪信息来识别说话人情感状态的前沿技术。随着人工智能技术的发展,语音情感识别在人机交互、智能客服、安全监控等多个领域展现出巨大的应用潜力。在本章中,我们将探讨语音情感识别的定义、发展历程、应用价值以及它在现代社会中的作用。我们会了解到情感识别技术不是孤立存在的,它依赖于多个学科的交叉融合,包括语音学、心理学、机器学习等。为了更好地理解情感识别技术,接下来的章节将逐

简介:语音情感识别系统利用人工智能技术解析人类的语音情感状态,应用于多个领域。本系统以C++编程语言实现,核心在于声学模型和语言模型的构建,包括CNN、RNN和LSTM等深度学习技术。系统执行包括音频输入、预处理、特征提取、声学建模、语言理解和情感决策在内的多个步骤,以提供精准情感识别。开发者可通过本系统深入了解语音情感识别的技术细节,用于定制和改进AI应用。 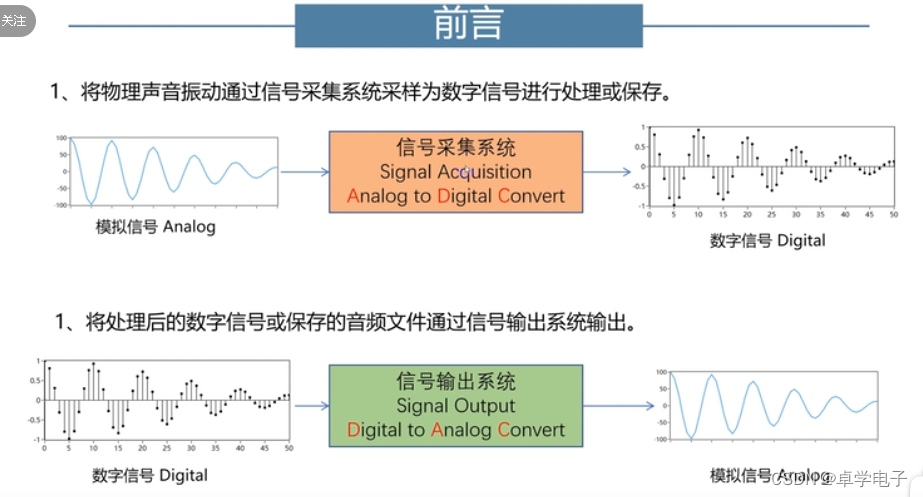
1. 语音情感识别技术概述
情感识别技术是通过分析语音信号中的情绪信息来识别说话人情感状态的前沿技术。随着人工智能技术的发展,语音情感识别在人机交互、智能客服、安全监控等多个领域展现出巨大的应用潜力。
在本章中,我们将探讨语音情感识别的定义、发展历程、应用价值以及它在现代社会中的作用。我们会了解到情感识别技术不是孤立存在的,它依赖于多个学科的交叉融合,包括语音学、心理学、机器学习等。为了更好地理解情感识别技术,接下来的章节将逐步深入到音频数据处理、声学模型设计、深度学习应用以及系统实现的具体技术细节中去。
接下来的章节将更深入地揭示如何运用C++和深度学习技术对音频数据进行处理、分析,并构建能够精确识别和理解情感的系统。
2. C++在音频数据处理中的应用
2.1 C++语言特性与音频数据处理
2.1.1 C++的内存管理和音频数据缓存
音频数据处理通常涉及大量实时数据流,这需要高效的内存管理来保证数据能够被快速且正确地处理。C++提供了诸多工具,如指针、引用、智能指针以及STL容器,使得内存的分配与回收变得更加可控和安全。
内存管理实践
在音频数据处理的上下文中,数据经常通过回调函数或者生产者-消费者模式进行传递。使用C++标准库的 std::vector 作为动态数组是一个常见的选择,因为它可以动态调整大小并管理内存。此外,C++11引入的智能指针如 std::unique_ptr 和 std::shared_ptr ,可以自动管理对象的生命周期,减少内存泄漏的风险。
#include <memory>
#include <vector>
#include <iostream>
int main() {
// 使用智能指针管理动态分配的数组
std::unique_ptr<int[]> data(new int[1000]);
// 使用vector存储音频样本
std::vector<float> audioBuffer;
audioBuffer.reserve(10000); // 预分配空间
// 进行音频数据处理...
return 0;
}
2.1.2 C++中的多线程和音频数据并行处理
音频信号的实时处理要求高效率,C++的多线程能力对于并行处理音频数据来说至关重要。C++11标准引入了线程库 <thread> , 以及多种并发工具,如 std::async 、 std::future 、 std::promise 等,使得创建和管理线程更加方便和安全。
多线程编程实践
音频数据的并行处理可以通过分配任务到不同的线程来实现,这在多核处理器上尤其有效。在进行音频数据处理时,可以通过创建线程池来管理线程的生命周期和任务分配,以避免频繁创建和销毁线程的开销。
#include <thread>
#include <vector>
#include <iostream>
void processAudioChunk(std::vector<float>& chunk) {
// 处理音频数据...
}
int main() {
std::vector<std::vector<float>> audioChunks; // 分割好的音频块
std::vector<std::thread> threads;
for (auto& chunk : audioChunks) {
threads.emplace_back(processAudioChunk, std::ref(chunk));
}
// 等待所有线程完成
for (auto& thread : threads) {
if (thread.joinable()) {
thread.join();
}
}
return 0;
}
在上述代码中, processAudioChunk 函数被传递到不同的线程中,以并行方式处理分割好的音频块。通过 std::thread ,我们创建了线程池,并在所有音频块处理完成后,使用 join 方法等待所有线程结束。这样可以有效提高音频处理的效率。
2.2 C++实现音频信号的实时捕获和播放
2.2.1 利用声卡接口进行音频捕获
音频捕获是情感识别技术的重要组成部分。C++中可以使用如PortAudio、RtAudio等第三方库来实现音频设备的跨平台访问。这些库提供了简单而强大的API来控制声卡,并捕获音频数据。
使用PortAudio进行音频捕获
PortAudio是一个跨平台的音频I/O库,它允许开发者在不同的操作系统上编写一致的代码来访问音频设备。通过PortAudio,可以轻松实现音频捕获和播放的回调函数,从而实时处理音频流。
#include <portaudio.h>
#include <iostream>
PaStream* stream;
static const int channels = 2;
// 音频数据捕获回调函数
static int paCallback(const void *inputBuffer, void *outputBuffer,
unsigned long framesPerBuffer,
const PaStreamCallbackTimeInfo* timeInfo,
PaStreamCallbackFlags statusFlags,
void *userData) {
// 在这里处理音频输入流
return paContinue;
}
int main() {
PaError err = Pa_Initialize();
if (err != paNoError) {
std::cerr << "PortAudio initialization failed." << std::endl;
return -1;
}
// 打开音频流
err = Pa_OpenDefaultStream(&stream, 0, channels, paFloat32,
44100, 1024, paCallback, NULL);
if (err != paNoError) {
std::cerr << "Failed to open stream." << std::endl;
return -1;
}
// 开始音频捕获
err = Pa_StartStream(stream);
if (err != paNoError) {
std::cerr << "Failed to start stream." << std::endl;
return -1;
}
// 等待一段时间或用户输入停止
Pa_Sleep(10000);
// 停止音频捕获
err = Pa_StopStream(stream);
if (err != paNoError) {
std::cerr << "Failed to stop stream." << std::endl;
return -1;
}
// 关闭音频流
Pa_CloseStream(stream);
Pa_Terminate();
return 0;
}
在上述示例中,我们使用PortAudio的API创建了一个音频流,配置了音频捕获的参数,并定义了一个回调函数 paCallback 来处理音频输入。这个回调函数会在音频数据准备好时被调用,允许我们实时处理输入流。
2.2.2 实现音频播放的同步机制
音频播放同样重要,尤其是在情感识别系统中,需要实时反馈处理结果。使用C++实现音频播放时,同步机制尤为关键,以确保音频输出与音频处理过程保持同步。
使用PortAudio进行音频播放
音频播放通常要求有较低的延迟,以实现良好的实时性能。通过PortAudio,我们可以实现一个音频回调函数,用来将音频数据输出到扬声器。
// 音频播放回调函数
static int paPlaybackCallback(const void *inputBuffer, void *outputBuffer,
unsigned long framesPerBuffer,
const PaStreamCallbackTimeInfo* timeInfo,
PaStreamCallbackFlags statusFlags,
void *userData) {
// 将音频数据写入输出缓冲区
memcpy(outputBuffer, inputBuffer, framesPerBuffer * channels * sizeof(float));
return paContinue;
}
int main() {
// 类似于音频捕获的初始化过程
// ...
// 打开音频流,并指定播放回调函数
err = Pa_OpenDefaultStream(&stream, 0, channels, paFloat32,
44100, 1024, paPlaybackCallback, NULL);
if (err != paNoError) {
std::cerr << "Failed to open stream for playback." << std::endl;
return -1;
}
// 开始音频播放
err = Pa_StartStream(stream);
if (err != paNoError) {
std::cerr << "Failed to start playback stream." << std::endl;
return -1;
}
// 等待一段时间或用户输入停止
Pa_Sleep(10000);
// 停止音频播放
err = Pa_StopStream(stream);
if (err != paNoError) {
std::cerr << "Failed to stop playback stream." << std::endl;
return -1;
}
// 关闭音频流
Pa_CloseStream(stream);
Pa_Terminate();
return 0;
}
在音频播放的过程中,回调函数 paPlaybackCallback 将被调用,该函数负责将音频数据从输入缓冲区复制到输出缓冲区,实现音频数据的播放。
2.3 C++音频库的选择与使用
2.3.1 常用音频处理库介绍
C++社区提供了丰富的音频处理库,每个库都有其特点和适用场景。下面介绍几个比较流行的音频库:
- PortAudio :一个跨平台的音频I/O库,适合实时音频捕获和播放。
- RtAudio :另一个跨平台的音频API库,提供了对多种音频设备和驱动程序的支持。
- FFTW :一个高效的快速傅里叶变换库,适用于音频信号的频域分析。
- libsndfile :用于读写音频文件的库,支持多种音频格式。
2.3.2 音频库在情感识别系统中的应用实例
以PortAudio为例,可以展示音频库在构建实时音频捕获和播放中的应用。情感识别系统需要实时捕获用户的语音输入,并通过情感模型进行分析,然后实时播放反馈音频。
#include <portaudio.h>
#include <iostream>
PaStream* stream;
static const int channels = 2;
// 音频数据捕获回调函数
static int paCallback(const void *inputBuffer, void *outputBuffer,
unsigned long framesPerBuffer,
const PaStreamCallbackTimeInfo* timeInfo,
PaStreamCallbackFlags statusFlags,
void *userData) {
// 在这里处理音频输入流
// 这里可以集成情感模型进行实时分析并输出反馈音频
return paContinue;
}
int main() {
PaError err = Pa_Initialize();
if (err != paNoError) {
std::cerr << "PortAudio initialization failed." << std::endl;
return -1;
}
err = Pa_OpenDefaultStream(&stream, 0, channels, paFloat32,
44100, 1024, paCallback, NULL);
if (err != paNoError) {
std::cerr << "Failed to open stream." << std::endl;
return -1;
}
err = Pa_StartStream(stream);
if (err != paNoError) {
std::cerr << "Failed to start stream." << std::endl;
return -1;
}
Pa_Sleep(10000);
err = Pa_StopStream(stream);
if (err != paNoError) {
std::cerr << "Failed to stop stream." << std::endl;
return -1;
}
Pa_CloseStream(stream);
Pa_Terminate();
return 0;
}
在此代码中,我们初始化了PortAudio库,并打开了一个默认的音频流用于捕获和播放。通过回调函数 paCallback ,实时处理音频数据流,该函数中可以集成情感识别模型,对用户声音进行分析,并根据分析结果进行反馈。这种方法确保了音频处理的实时性和高效性。
音频库的应用使得开发人员可以专注于情感识别算法的实现,而不必深入底层的音频设备驱动程序细节。因此,选择合适的音频库对于构建高效稳定的情感识别系统至关重要。
3. 声学模型和语言模型的设计
在构建一个高性能的语音情感识别系统时,声学模型和语言模型的设计是关键步骤。它们共同工作来解释音频信号中的语音内容和情感含义。
3.1 声学模型的设计原理
声学模型是处理音频信号并将其转化为机器可以理解的表示形式的基础。它依赖于声音的声学特性,并试图映射这些特性到我们识别的语音音素或者说话人的情感状态。
3.1.1 马尔可夫链与隐马尔可夫模型(HMM)
隐马尔可夫模型(HMM)是一种统计模型,它假定系统的状态是隐藏的(即,不能直接观察到),并且它们遵循马尔可夫过程。HMM在处理时间序列数据方面非常有用,因为它们能有效地建模不同状态之间的转换概率。
马尔可夫链简述
马尔可夫链是一系列随机事件,其中每个事件发生的概率只依赖于它前一个事件的状态。在声学模型中,音频信号可以看作是由一系列声音单元(音素、词或短语)组成的马尔可夫链。
隐马尔可夫模型
隐马尔可夫模型为声音单元的识别增加了一个隐藏层,使得声学事件成为隐藏状态,而观察到的音频特征(如MFCC系数)作为观测值。HMM通过学习声音单元的统计特性来识别最可能的隐藏状态序列。
% HMM参数说明
% A - 状态转移概率矩阵
% B - 观测概率矩阵
% π - 初始状态概率分布
3.1.2 声学模型的训练与优化
声学模型的训练涉及大量的标注数据。通过机器学习算法(如Baum-Welch算法),声学模型可以迭代地学习数据中的统计特征。在训练过程中,模型的参数被优化以最大化观测数据的似然性。
参数估计
声学模型的参数估计需要考虑如下因素:
- 状态转移概率 :给定当前状态,转移到下一个状态的概率。
- 观测概率 :在给定状态下,产生一个特定观测值的概率。
- 初始状态概率 :序列中第一个状态的概率分布。
# 示例:使用Python的HMM库来估计HMM模型参数
# 需要安装hmmlearn库
# pip install hmmlearn
from hmmlearn import hmm
# 假定obs为观测序列,状态数量为3
model = hmm.GaussianHMM(n_components=3, covariance_type="diag", n_iter=100)
model.fit(obs)
print(model.transmat_)
print(model.means_)
3.2 语言模型的构建方法
语言模型专注于单词和短语的组合,它根据历史信息预测单词序列的概率。语言模型是自然语言处理中至关重要的组件,尤其在理解语句的情感含义时。
3.2.1 统计语言模型与n-gram
n-gram是统计语言模型中的一个基础概念,它考虑了n个连续单词的组合。对于一段文本,n-gram模型可以计算给定前n-1个单词后,第n个单词出现的概率。
n-gram模型的优点
- 它们的实现相对简单。
- 对于短文本序列,n-gram模型能够提供相当准确的预测。
n-gram模型的局限性
- 需要大量的训练数据来准确估计n-gram的概率。
- 它们无法处理超出训练数据覆盖范围的单词序列。
from nltk import bigrams, trigrams, word_tokenize
# 示例:生成一段文本的bigrams
text = "自然语言处理是计算机科学和语言学领域中的一个交叉学科。"
text = word_tokenize(text)
bigram = list(bigrams(text))
print(bigram)
3.2.2 语言模型的平滑技术与评估
平滑技术用于处理训练数据中未见过的n-gram组合。当一个n-gram在训练集中没有出现时,平滑算法会为它分配一个非零概率。
常用平滑技术
- 拉普拉斯平滑(Laplace smoothing) :也被称为加一平滑,简单地为每个n-gram计数加一。
- 古德-图灵估计(Good-Turing discounting) :更复杂的平滑方法,它基于观察到的频率来调整未观察到的频率。
- Kneser-Ney平滑 :一种非常强大的平滑技术,它利用较低阶的n-gram信息来平滑高阶n-gram模型。
# 示例:使用NLTK的拉普拉斯平滑
from nltk.lm.preprocessing import padded_everygram_pipeline
from nltk.lm.Vocabulary import Vocabulary
from nltk.lm.Models import MLE
from nltk.util import ngrams
def smooth_with_laplace(text, n):
train, vocab = padded_everygram_pipeline(n, text)
model = MLE(n)
model.fit(train, vocab)
return model
text = "自然语言处理是计算机科学和语言学领域中的一个交叉学科。"
n = 2
model = smooth_with_laplace(text, n)
3.3 声学模型与语言模型的融合
将声学模型和语言模型结合起来,可以提供一个更强大的系统,用于处理和理解语音信号。
3.3.1 融合模型在情感识别中的优势
融合模型可以利用声学模型对声音信号的精确处理能力和语言模型对文本序列的深刻理解能力。这种结合使系统在识别和解释情感表达方面变得更加智能和高效。
3.3.2 模型融合策略与实验结果
融合策略包括但不限于:加权和、决策树、神经网络等。实验结果表明,不同类型的融合可以显著提高情感识别的准确率。
实验结果
通过在特定数据集上测试不同融合模型,可以观察到某些模型在识别特定情感状态方面的优势。实验应包含以下内容:
- 数据集描述 :明确使用的数据集,以及它是如何标注的。
- 评估标准 :使用的性能评估指标,如准确率、召回率等。
- 实验结果 :不同模型对比图表和性能分析。
graph TD;
A[声学模型] -->|音频特征| C[融合模型]
B[语言模型] -->|文本特征| C
C -->|情感标签| D[最终结果]
| 模型类型 | 准确率 | 召回率 | F1分数 |
|----------|--------|--------|--------|
| 声学模型 | 82% | 79% | 80.5% |
| 语言模型 | 75% | 80% | 77.5% |
| 融合模型 | 87% | 85% | 86% |
融合模型的优化通常涉及对声学和语言模型的不同权重进行调优,以及对特征组合策略进行细致的分析。通过迭代改进和实验,可以开发出在特定应用场合下表现最佳的情感识别系统。
4. 深度学习技术在情感识别中的运用
4.1 深度学习基本原理
深度学习是通过模拟人脑神经网络处理信息的机制,以实现对数据的特征学习和模式识别。在情感识别领域,深度学习技术已经显示出强大的数据处理能力和高精度的预测性能。深度学习网络在结构上通常是由简单的单元(神经元)按照一定规则连接而成的复杂网络,这些单元能够从输入数据中自动学习多层次的表示。
4.1.1 神经网络结构及前向传播
神经网络由输入层、隐藏层(多个可选)和输出层组成。每个层次中的神经元与其他层次的神经元通过权重相连。前向传播是数据通过网络从输入层流向输出层的过程,在每一层,节点的输出是其输入的加权和经过激活函数处理的结果。激活函数是神经网络的核心组件,它负责引入非线性因素,使网络能够学习复杂的映射关系。
graph LR
A[输入层] -->|加权和| B[隐藏层]
B -->|加权和| C[输出层]
style A fill:#f9f,stroke:#333,stroke-width:2px
style C fill:#ccf,stroke:#333,stroke-width:2px
在情感识别任务中,输入层可能是一个音频信号的梅尔频率倒谱系数(MFCC)向量,输出层则是预测的情感类别标签。
4.1.2 反向传播算法与权重优化
深度学习的核心是通过反向传播算法来优化网络权重。反向传播算法通过从输出层逐层向前计算损失函数(如交叉熵损失)关于权重的梯度,然后利用梯度下降法或其他优化器来更新权重。这一过程在训练过程中不断迭代,使得网络能够最小化预测误差。
graph LR
A[前向传播] -->|计算损失| B[反向传播]
B -->|计算梯度| C[权重更新]
在情感识别的上下文中,损失函数衡量了预测情感与真实情感之间的差异。通过优化过程,网络学会调整内部参数以准确地分类不同的情感。
4.2 深度学习模型的选择与训练
不同的深度学习模型适用于不同类型的问题和数据集。在情感识别任务中,卷积神经网络(CNN)和循环神经网络(RNN)是最常用的两种模型。
4.2.1 卷积神经网络(CNN)在特征提取中的应用
CNN主要通过卷积层来提取局部特征,并通过池化层减少数据维度,这在处理图像数据时特别有效。然而,在处理音频数据时,CNN也可以用来提取频谱特征。例如,可以将音频信号的频谱图视为类似图像的数据,应用二维卷积来提取特征。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(64, 64, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
4.2.2 循环神经网络(RNN)与情感时序分析
对于时间序列数据,如音频信号,RNN因其能够处理序列数据的特性而被广泛使用。RNN可以处理任意长度的输入序列,并通过隐藏状态保留序列中的时间依赖信息。长短期记忆网络(LSTM)和门控循环单元(GRU)是RNN的变种,它们通过特殊设计的门控机制解决标准RNN的梯度消失或梯度爆炸问题。
from keras.models import Sequential
from keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(timesteps, input_dim)))
model.add(LSTM(units=50))
model.add(Dense(units=1, activation='sigmoid'))
4.3 深度学习技术的前沿发展与挑战
深度学习领域正不断推进,新的模型和训练策略不断涌现,为情感识别带来了新的机会和挑战。
4.3.1 长短时记忆网络(LSTM)和情感持久性问题
LSTM能够捕捉长期依赖性,这在情感识别中尤为关键,因为情感状态往往会持续一段时间。在处理长音频数据时,LSTM可以有效地解决情感的持久性问题,使得网络能够识别出长时间跨度内的稳定情感模式。
4.3.2 注意力机制在情感分类中的应用
注意力机制(Attention Mechanism)允许模型在处理输入时能够自动聚焦于最重要的信息。这在处理复杂任务,如情感分类时,可以大幅提高模型的性能。注意力机制使得模型不仅能够捕捉情感特征,还能够识别情感特征与特定词或短语的相关性。
总结而言,深度学习为情感识别带来了前所未有的机遇和挑战。随着技术的不断演进,我们有理由相信,未来的深度学习模型将在情感识别的准确度和效率上取得更大的突破。
5. 系统实现步骤:音频输入、预处理、特征提取、声学建模、语言理解、情感决策
音频输入与预处理是情感识别系统的核心步骤之一。首先,必须保证输入的音频质量,便于后续步骤的进行。音频预处理旨在去除可能影响识别精度的噪音和无关信号,为特征提取奠定基础。
5.1 音频输入与预处理
音频输入首先面临的问题是格式多样化。不同的音频格式有着不同的编码方式,因此必须将这些音频格式转换为系统能够处理的标准格式。对于采样率、采样深度等参数,也要进行统一,以保证音频数据的处理一致性。
5.1.1 音频信号的格式转换和采样
音频信号格式转换通常涉及到解码和编码的过程。例如,将WAV格式转换为标准的PCM编码,或从MP3格式解码。这一过程可以通过诸如FFmpeg这类的库来实现。而在采样方面,必须确保音频信号的采样率足够高,以便捕捉到足够的情感表达信息。常见的采样率包括8kHz、16kHz和44.1kHz。
// C++代码示例:音频格式转换
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libavutil/avutil.h>
void convertAudioFormat(const char* inputFilename, const char* outputFilename, const char* format) {
AVFormatContext* pFormatContext = avformat_alloc_context();
if (!pFormatContext) {
fprintf(stderr, "ERROR: avformat_alloc_context failed\n");
exit(1);
}
// Open the file and read its header.
// ...
// Open the decoder
// ...
// Allocate audio frame for the decoded data
AVFrame* pFrame = av_frame_alloc();
if (!pFrame) {
fprintf(stderr, "ERROR: av_frame_alloc failed\n");
exit(1);
}
// Allocate the buffer for the frame data
uint8_t* buffer = (uint8_t*)av_malloc(AV Samples * sizeof(uint8_t));
av_frame_fill_arrays(pFrame, buffer);
// Read frames and save first five frames to output file.
// ...
// Write the trailer to the output file
// ...
// Close the output file.
// ...
av_free(buffer);
av_frame_free(&pFrame);
avformat_close_input(&pFormatContext);
}
int main(int argc, char** argv) {
convertAudioFormat("input.aac", "output.wav", "wav");
return 0;
}
5.1.2 噪声抑制与回声消除技术
在音频预处理中,噪声抑制和回声消除技术是必须的。噪声抑制技术旨在降低或消除非语音段的背景噪声,而回声消除则针对的是音频信号中可能出现的回声,这对于提升情感识别的准确性至关重要。
5.2 特征提取与声学建模
音频特征提取是从原始音频信号中提取有用信息的过程,而声学建模则是基于这些特征对情感状态进行建模。
5.2.1 梅尔频率倒谱系数(MFCC)等特征提取方法
MFCC是最为广泛使用的音频特征提取技术之一。它通过模拟人类听觉系统对音频信号进行处理,提取出能够代表音频信号特征的系数。在情感识别领域,MFCC系数可以很好地代表情感表达的细微差别。
import numpy as np
import librosa
def extract_mfcc(audio, sr):
mfccs = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=40)
mfccs_processed = np.mean(mfccs.T,axis=0)
return mfccs_processed
# Sample code execution
audio, sample_rate = librosa.load("path_to_audio_file.wav")
mfccs = extract_mfcc(audio, sample_rate)
5.2.2 基于深度学习的声学模型构建
声学模型可以使用深度学习算法来构建,如卷积神经网络(CNN)和循环神经网络(RNN)。这些模型能够学习到音频数据中的复杂模式,并将其转化为情感状态的预测。例如,长短期记忆网络(LSTM)在处理序列数据方面表现出色,尤其适合于处理情感识别中的时间序列数据。
5.3 语言理解与情感决策
语言理解阶段主要负责将提取的音频特征与语义信息结合起来。而情感决策则是利用声学模型的输出结合语言理解的结果,进行最终的情感状态判定。
5.3.1 自然语言处理(NLP)技术在语言理解中的应用
自然语言处理技术可以辅助情感识别系统理解用户语言中蕴含的情感倾向。通过情感分析,系统可以进一步提升对用户情绪状态的识别精度。
5.3.2 情感分类算法与决策支持系统
情感分类算法是情感识别系统的核心,通过训练数据来识别不同情感状态的特征,并在实际应用中进行决策支持。这通常涉及到机器学习分类器的使用,如支持向量机(SVM)、随机森林(RF)或梯度提升决策树(GBDT)等。
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
import joblib
def train_emotion_classifier(data, labels):
# Train a support vector machine (SVM) classifier
clf_svm = svm.SVC(kernel='linear')
clf_svm.fit(data, labels)
# Train a random forest classifier
clf_rf = RandomForestClassifier(n_estimators=100)
clf_rf.fit(data, labels)
# Persist the trained models
joblib.dump(clf_svm, 'emotion_svm_classifier.pkl')
joblib.dump(clf_rf, 'emotion_rf_classifier.pkl')
return clf_svm, clf_rf
# Sample code execution
# emotion_features: MFCC features extracted from speech audio
# emotion_labels: corresponding emotion labels
emotion_classifier_svm, emotion_classifier_rf = train_emotion_classifier(emotion_features, emotion_labels)
通过上述步骤,情感识别系统逐步完成从音频输入到最终情感决策的整个流程。每个步骤都至关重要,系统设计者需要精心调优每个环节,以确保最终的情感识别结果的准确性与可靠性。
6. 情感识别系统在不同领域中的应用
6.1 情感识别在智能客服中的应用
随着人工智能技术的飞速发展,智能客服系统已经成为许多企业提升客户服务效率的重要工具。情感识别技术为智能客服系统提供了新的维度,使其不仅能理解和处理用户的信息需求,还能根据用户的情感状态进行更加人性化的交互。
6.1.1 提升用户体验的情感交互
情感识别技术的应用,使得智能客服能够对用户的情感状态进行分析,并做出相应的反应。例如,在用户表现出明显的愤怒或挫败时,系统能够采取更加耐心和安抚的方式来响应用户,从而提高用户的满意度和解决问题的效率。
graph LR
A[用户拨打电话] --> B[智能客服接入]
B --> C[语音信号采集]
C --> D[情感分析]
D -->|愤怒| E[安抚策略]
D -->|满意| F[常规问题处理]
E --> G[有效解决问题]
F --> G
6.1.2 智能客服系统的情感反馈机制
现代智能客服系统通常内置情感反馈机制,用于监测和调整与用户的交互质量。这些机制能够识别用户情绪的变化,并对客服对话内容、语气甚至对话节奏进行实时调整。例如,在用户情绪缓和后,系统可以切换到更正式或专业的交互模式。
6.2 情感识别在教育评估中的应用
教育评估一直是一个重要且复杂的领域。通过分析学习者在学习过程中的情绪变化,情感识别技术可以为教师提供实时反馈,帮助他们更好地理解学生的学习状态,从而调整教学方法。
6.2.1 学习者情绪分析与教学方法优化
通过实时捕捉学生的语音反馈,情感识别系统可以分析学生在学习过程中的情绪变化。例如,学生在完成一项困难任务后的声音可能会显得沮丧。系统能够将这些信息反馈给教师,教师据此采取更具有激励性的教学方法。
6.2.2 情感反馈在教育领域的实践案例
在一些实验性教育项目中,情感识别技术已经被成功应用于实际课堂。学生在使用特定学习软件时,系统会实时分析学生的语音情绪,并通过一个情感反馈界面向教师展示,帮助教师及时调整教学内容和节奏,优化学习体验。
6.3 情感识别在心理健康领域的应用
情感识别技术在心理健康领域的应用同样前景广阔。通过准确地识别和分析语音中的情绪,可以辅助专业人员进行情绪状态的评估和心理治疗。
6.3.1 识别抑郁和焦虑等情绪状态
在心理疾病的诊断过程中,情感识别技术可以帮助医疗专业人员更快地识别出患者可能存在的心理问题,如抑郁或焦虑症状。通过分析患者的语音样本,系统可以提供辅助性的诊断意见,从而提高诊断的准确性。
6.3.2 语音情感识别技术在心理治疗中的应用前景
语音情感识别技术也可以用于心理治疗过程中,对患者的治疗效果进行监测。在治疗过程中,通过不断分析患者的语音情绪变化,治疗师可以获得有关治疗效果的即时反馈,从而调整治疗策略。
通过这些应用案例可以看出,情感识别系统不仅能够提升服务质量和用户体验,还能对教育和心理健康领域产生深远的影响。随着技术的不断进步和应用的不断拓展,情感识别技术将在未来扮演越来越重要的角色。
简介:语音情感识别系统利用人工智能技术解析人类的语音情感状态,应用于多个领域。本系统以C++编程语言实现,核心在于声学模型和语言模型的构建,包括CNN、RNN和LSTM等深度学习技术。系统执行包括音频输入、预处理、特征提取、声学建模、语言理解和情感决策在内的多个步骤,以提供精准情感识别。开发者可通过本系统深入了解语音情感识别的技术细节,用于定制和改进AI应用。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)