分享本周所学——混合专家模型(MoE)详解
本文介绍了混合专家模型(MoE)的基本原理及其在DeepSeek-V3中的应用。MoE通过将Transformer中的前馈网络拆分为多个专家模块,每次只激活少量专家来处理输入,从而节省计算资源并提高性能。文章详细解释了MoE的工作原理,包括门控网络如何选择专家、专家过度使用和专业性不足等问题及其解决方案。特别介绍了DeepSeek-V3的MoE架构:包含257个专家(1个共享专家+256个专业专家
大家好,欢迎来到《分享本周所学》第十三期。本人是一名人工智能初学者,即将本科毕业(7月9号)。最近混合专家模型(MoE)自从DeepSeek-V3推出以来一直非常火,所以我也写篇文章蹭下热度。当然蹭热度只是目的之一,更重要的目的还是希望通过这篇文章让所有人都弄明白MoE到底是怎么回事。因此,我不会假设你有任何机器学习或者数学的基础知识,即使你只是刚刚接触人工智能领域的小白,我也会让你看懂。如果你觉得我有任何一个地方(即使只是一个标点符号)写的不对、不好或者不清楚,麻烦你在评论区指出来,这会对我有极大的帮助。
这里先贴一下DeepSeek-V3的原论文。至于为什么没有提到DeepSeek-R1,是因为R1的模型结构和V3没啥区别,只是在微调上多下了点功夫。可见,模型结构固然重要,但精妙的微调方法可以让本身就强悍的基模更上一层楼。
DeepSeek-V3 Technical Report![]() https://arxiv.org/pdf/2412.19437
https://arxiv.org/pdf/2412.19437
目录
上期文章链接:
突然想起来有好多人让我写3DGS的代码复现,至于为什么没写呢,不是因为我没复现出来,也不是没时间写,主要还是我这人比较懒(再加上炉石传说和守望先锋国服双双回归),现在基本上是一年一更了。那既然我现在又要写一篇,为什么不写3DGS的代码复现呢?不是因为我没复现出来,也不是没时间写,主要还是我最近换电脑,COLMAP的环境还没配(说白了还是懒)。总之如果写了会第一时间把链接更新在这里和上篇文章里面。我会尽快写的!我保证!
一、啥是MoE啊?
要想知道啥是MoE,还得先知道啥是Transformer。那至于啥是Transformer呢,可以去看看我之前写的关于Transformer的文章。
不过我当然知道有相当一部分人懒得去看,而且我也承诺过让所有人不需要任何机器学习基础就看懂这篇文章,所以我在这里简单介绍一下。如果你已经懂了Transformer,可以直接跳到本章第二节。
1. 简单回顾Transformer
这里先贴一张最经典的Transformer结构图:
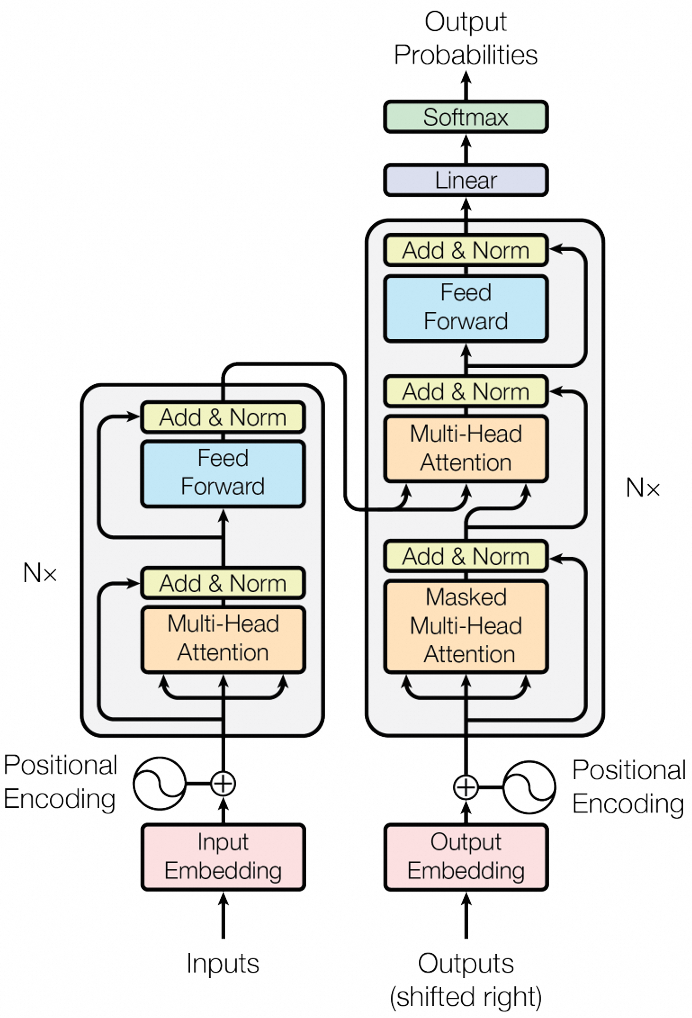
什么是Transformer呢?简单来说,Transformer是神经网络结构的一种。它主要由两部分组成,分别是编码器(上图左侧)和解码器(上图右侧)。目前主流的大语言模型都是只有解码器,没有编码器的架构,因此我们着重来看上图右侧的结构。
右侧总共包含9个框框,其中,Output Embedding、Linear和Softmax三个框框并不是Transformer的一部分,它们主要用来处理输入和输出,因此Transformer解码器只有6个模块,分别是两个Multi-Head Attention、一个Feed Forward和三个Add & Norm。
我们分别来看一下这三种模块。什么是Multi-Head Attention呢?Multi-Head Attention就是多头注意力。要想了解多头注意力,先得了解普通的注意力。那什么是注意力呢?顾名思义,这个模块的目的就是让模型把更多的注意力放在关键的信息上。比如我们让模型处理“我今天早上吃的面包”这句话。这句话里最有信息含量的肯定是“面包”这两个字。因此,我们希望模型把更多的注意力放在这两个字上。但是我们会发现,“我”、“今天”、“早上”、“吃”这几个词虽然没有“面包”那么关键,但也包含了一定的信息量。我们希望模型也把一定的注意力放在这几个词上。因此,就引入了“多头注意力”这个概念,相当于有很多个注意力模块,每个注意力能让模型注意到不同类型的词。
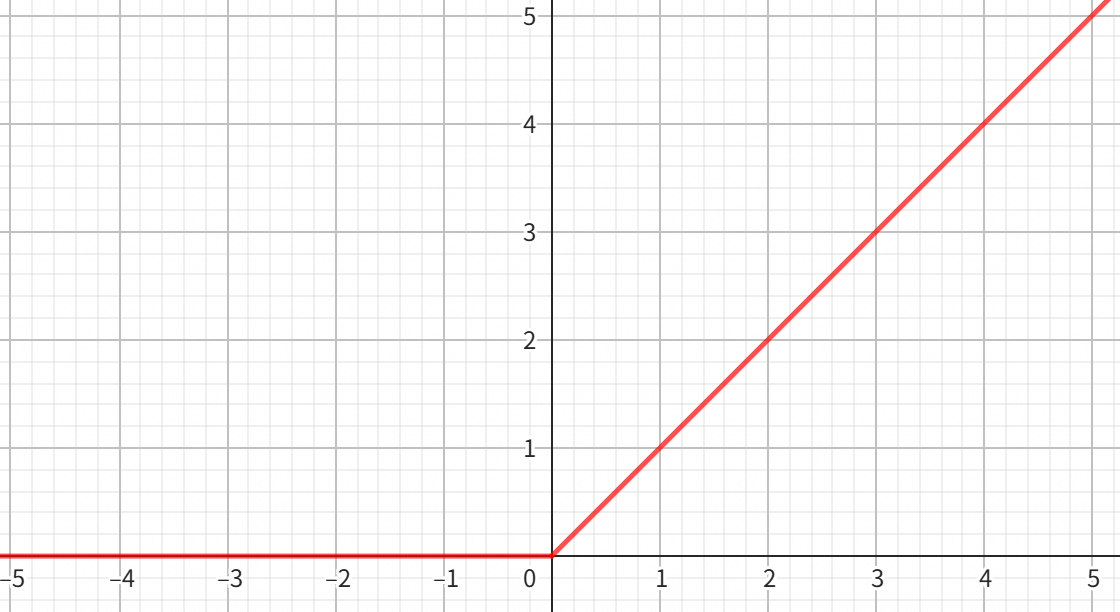
那什么是Feed Forward呢?Feed Forward模块通常包含几个全连接层和几个ReLU层。其中,全连接层是神经网络最基本的结构,它对输入的向量进行一个线性的变换。而ReLU是一种“激活函数”,它将输入中小于0的部分变成0,保留大于0的部分。说白了就是下面这个简单的分段函数。Feed Forward模块的作用是将输入的向量转换为包含更多信息量且更容易被模型理解的向量。
那什么是Add & Norm呢?Add就是加,把输入多头注意力(或者Feed Forward)的向量和多头注意力输出的向量加起来。Norm就是归一化。这两个操作的目的就是防止神经网络中的数值变得过大或者过小,让所有数值处于一个可控的范围内。
2. MoE与一般Transformer的区别
说完了Transformer,我们就来说一说MoE和Transformer有什么区别。我在这先放一个一般的Transformer和MoE的对比图:
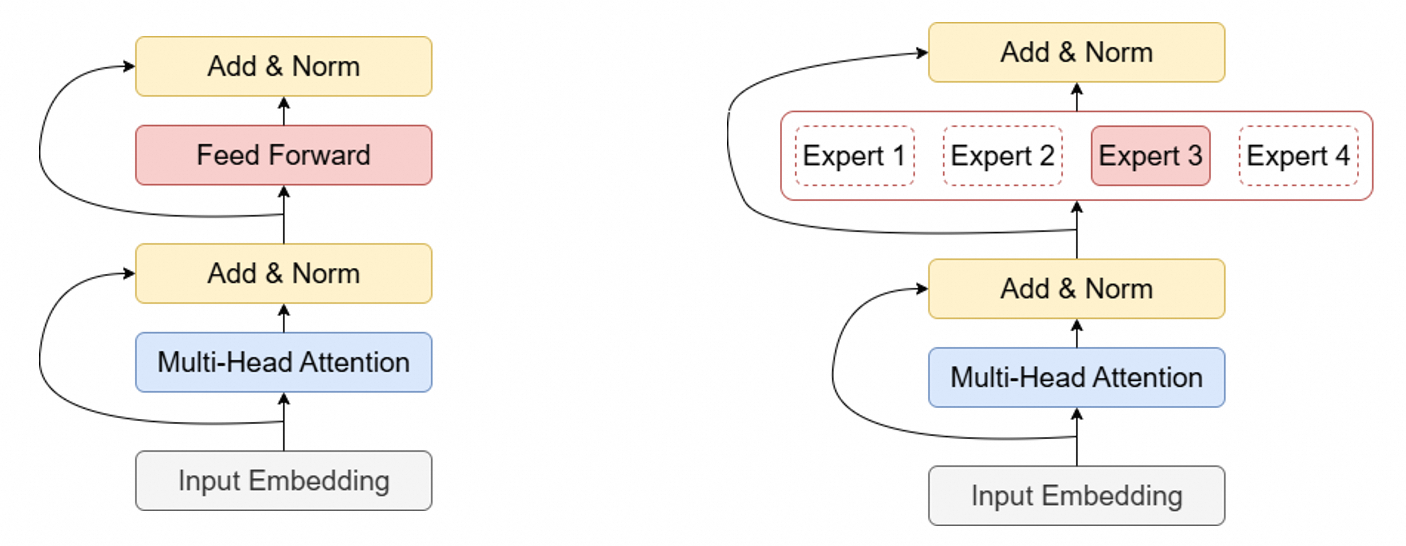
可以看到,MoE和一般的Transformer是没什么区别的,唯一的区别在于Feed Forward层,相当于MoE把Transformer的Feed Forward层拆成了好多块,每一块称为一个“专家”。在处理一个输入时,只有一个专家或几个专家被激活,被激活的专家在所有专家中的占比应该是比较小的。不激活的专家不会参与计算。也就是说,每个输入只由少量被激活的专家进行处理,大部分专家都与这个输入完全无关。这些被激活的专家的计算结果最后会被求和或求平均,得到专家层的最终输出。这个输出就相当于一般的Transformer中Feed Forward层的输出。随后,这个输出继续被Add & Norm层处理,并传入后续的层中,就像一般的Transformer一样。在更新参数时,只有被激活的专家的参数会更新,其余的专家参数保持不变。
3. MoE的目的与优势
那么为什么要把一个简简单单的Feed Forward层拆成这么多专家,搞得这么麻烦呢?我们可以从MoE这个名字入手来分析这个问题。MoE,也就是混合专家模型,顾名思义就是一大堆专家混在一块。设计MoE的目的就是希望每一个专家能够拥有一个领域的专业知识。假设总共有4个专家,可能第一个专家擅长处理物理领域的问题,那么在模型遇到涉及到物理知识的问题时,就会激活第一个专家,让它来处理。同理,可能第二个专家负责处理数学问题,第三个专家负责处理AI相关的问题,第四个专家负责处理生物问题。这样的好处是,由于专家的知识与用户输入的问题非常匹配,因此可以给出更好的回答,而且由于大部分模型都不参与计算,因此可以节省大量的计算资源。综上,可以把MoE的优势总结为:用更少的计算资源产出更精确的结果。
4. 门控网络
现在还有另外一个问题,那就是MoE模型是如何知道一个输入应该交给哪个模型来处理呢?这就是门控网络(也称为路由)的任务。门控网络是一个专门用来判断一个输入该由哪个专家处理的模块。它包含一个全连接层和一个Softmax层。全连接层的输入是就是注意力层的输出,而它的输出是一个向量,这个向量的维度数量和专家数量是相等的。而Softmax层会将全连接层的输出转换为一个概率分布,表示每个专家被激活的概率。
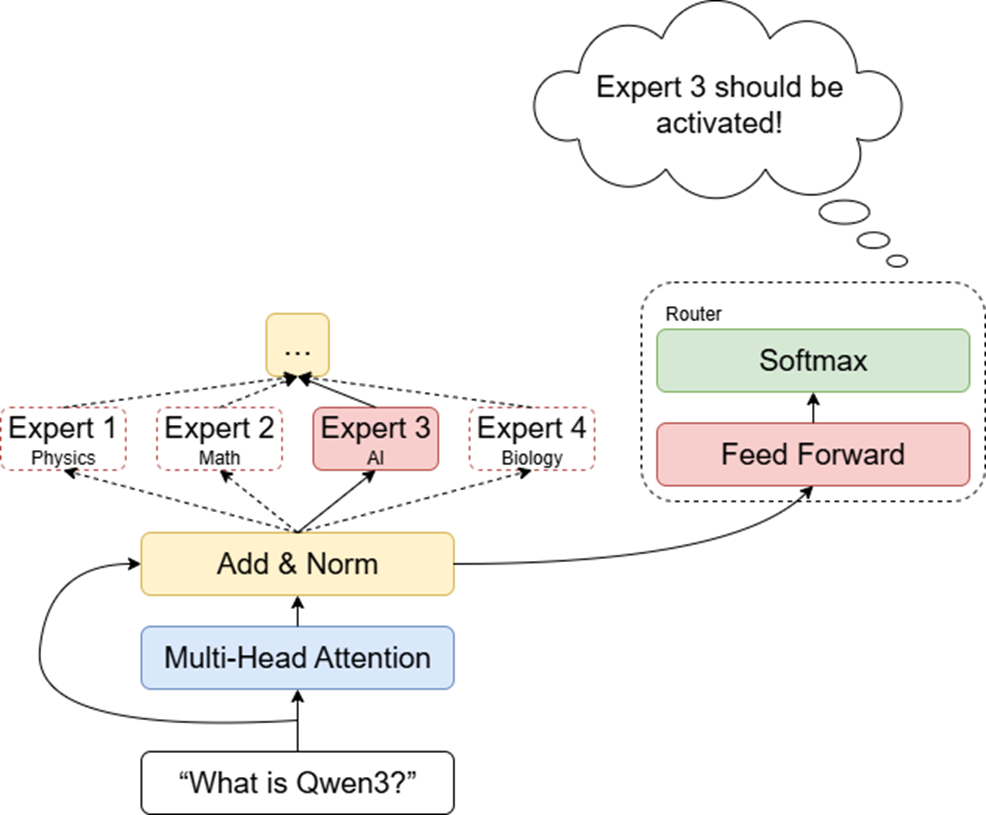
这么干说可能说不太明白,我们来举个例子。假设我们有四个专家,那么全连接层就会输出一个四维的向量,比如。而Softmax层会将这个向量的每一维转换成一个概率,越大的数值转换成的概率就越高。比如说,93589是向量中最大的数,因此它会被转换成一个非常高的、接近100%的概率;而-810975是一个非常小的数,因此它会被转换为一个接近0的概率。
这个概率就代表了每个专家被激活的概率。因此在上面这个例子中,我们会选择激活第三个专家。在模型更新参数的过程中,门控网络中的参数也会被更新,这使得门控网络会逐渐学会将每个输入交给最匹配的专家来处理。
二、MoE有啥毛病没有?
MoE的设想是美好的,但是在实际实现的过程中,难免会出现各种各样的问题,其中有两个问题是非常重大且致命的。不过值得庆幸的是,这两个问题都有不错的解决方案。
1. 专家知识专业性
我们设计MoE的初衷是想让每个专家分别掌握一个专业领域的知识,从而有针对性地处理用户的问题。但是实际情况中,很可能会出现专家的知识过度重合的情况。比如,在模型训练的初期,门控网络并不知道每个问题具体该交给哪个专家处理,因此它可能将所有输入随机分配给每个专家。这就导致每个专家并不能固定处理某一个领域的知识,而是需要处理所有问题。因此在更新参数的过程中,这些专家就会倾向于能够处理所有领域的问题。这并不是一件好事,因为掌握更多领域的知识就意味着对每个领域的专业性会下降,这样一来MoE相比一般Transformer的优势就完全丧失了。
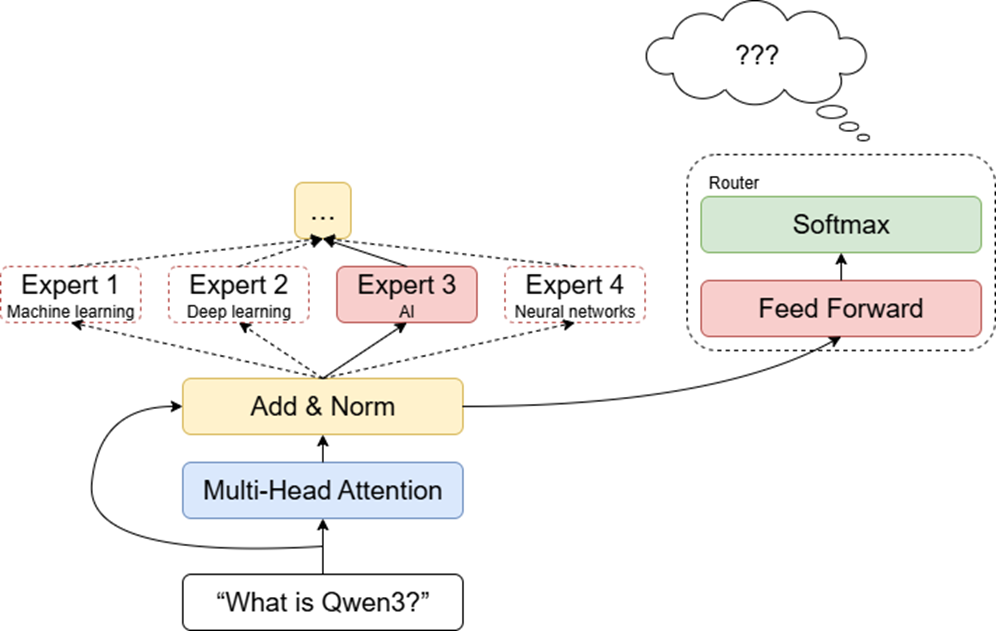
而另外一种情况是,每个专家的知识过度专业化了,而缺乏一些比较通用的常识。比如,一个负责物理的专家可能只知道物理相关的知识,而缺乏一些基本的语言能力,导致输出的内容可读性很差。另外,这种情况也会导致模型高度依赖门控网络的路由能力,一旦门控网络激活了不那么匹配的专家,输出质量就会大打折扣,导致模型的稳定性很差。这同样是我们不想要的。
DeepSeek对于这个问题给出了一个很好的解决方案——“共享专家”。无论输入内容是什么,共享专家都必定被激活,而其他专家由门控网络决定是否激活。这种设计可以使共享专家掌握一些比较通用的知识,而鼓励其他的专家高度专业化。
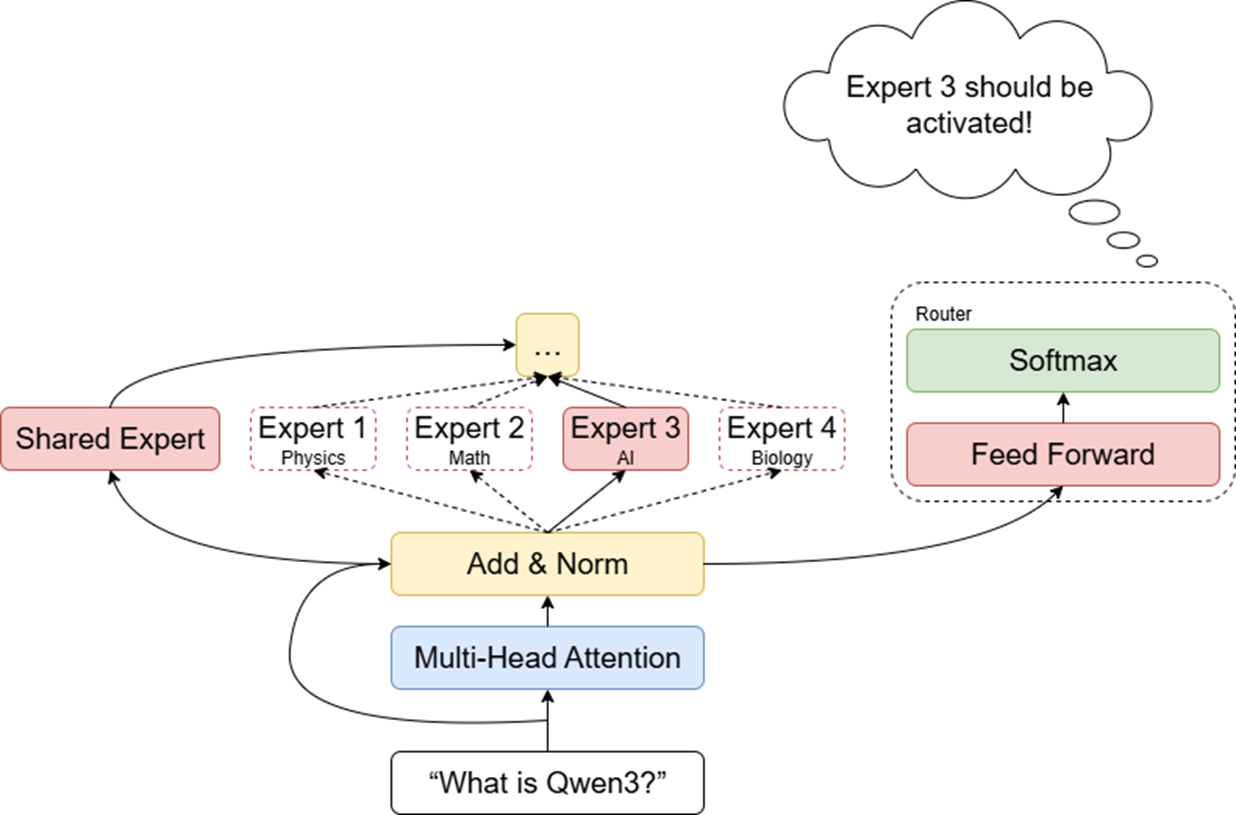
2. 部分专家过度使用
另一个MoE可能出现的问题就是,在训练的初期,专家还没有掌握多少知识时,某一个专家被门控网络多次激活。这就导致这个专家得到的训练比其他专家更多,性能也就更强。这时,门控网络可能会想,既然这个专家这么厉害,干脆把所有问题都交给它处理好了。这样一来,这个专家就会越来越强,而其他专家几乎完全得不到训练,也就使得专家的利用率非常底下,很多专家都被完全浪费了。
解决方法也很简单,我们在训练一个epoch后,统计门控网络的Softmax层输出的每个专家被激活的平均概率。我们希望所有专家能够较为平均地被激活,因此可以引入一个新的损失项,这个损失项是门控网络的输出的变异系数,也就是标准差与平均值的比值。我们希望门控网络的输出尽可能平均,因此较高的变异系数会被惩罚。
不过,DeepSeek并没有采用这个策略,因为更复杂的损失函数会提高训练难度。因此他们的解决方案是,在门控网络的输出的基础上额外为每个专家加上一个偏置项,频繁被激活的专家会得到较低(可能为负)的偏置项,而不常被激活的专家会得到较高的偏置项。我们还举刚才那个四个专家的模型的例子。假设门控网络的输出是,此时我们按理说应该激活第三个专家,但是,假设第三个专家由于频繁被激活获得了-0.3的偏置项,而第一个专家因为较少被激活获得了0.3的偏置项,那么实际每个专家被激活的概率就变为了
,最终第一个专家被激活。
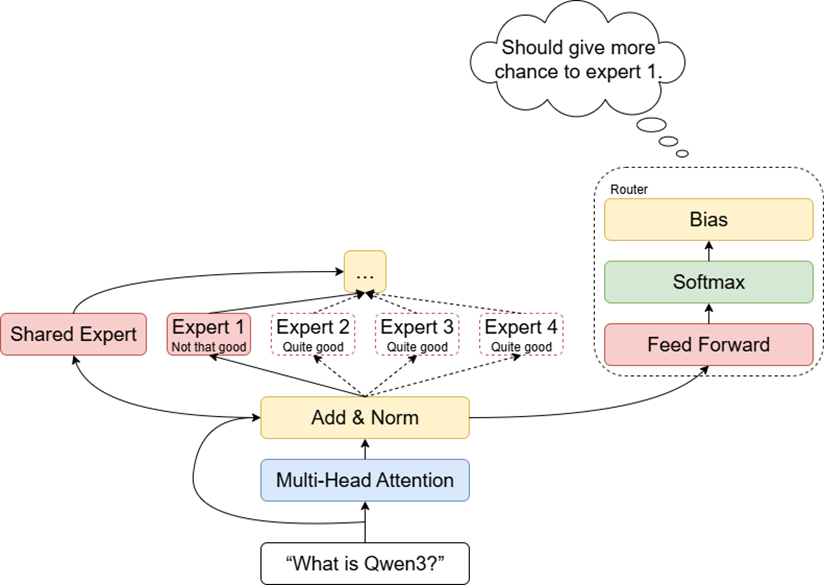
在每一个epoch训练结束后,我们会统计每个专家被激活了多少次,并以此来更新所有专家的偏置项的数值。通过这种方式,我们可以在不修改损失函数的情况下尽量保证每个专家更为平均地被激活。
三、DeepSeek-V3中的MoE架构
这一章中,我们来看看MoE在最近非常火的DeepSeek-V3(和R1)中具体是如何应用的。
1. DeepSeek-V3的模型架构
首先,DeepSeek-V3总共有61层,其中有3个全连接层和58个Transformer层。每个Transfomer层的结构如下:
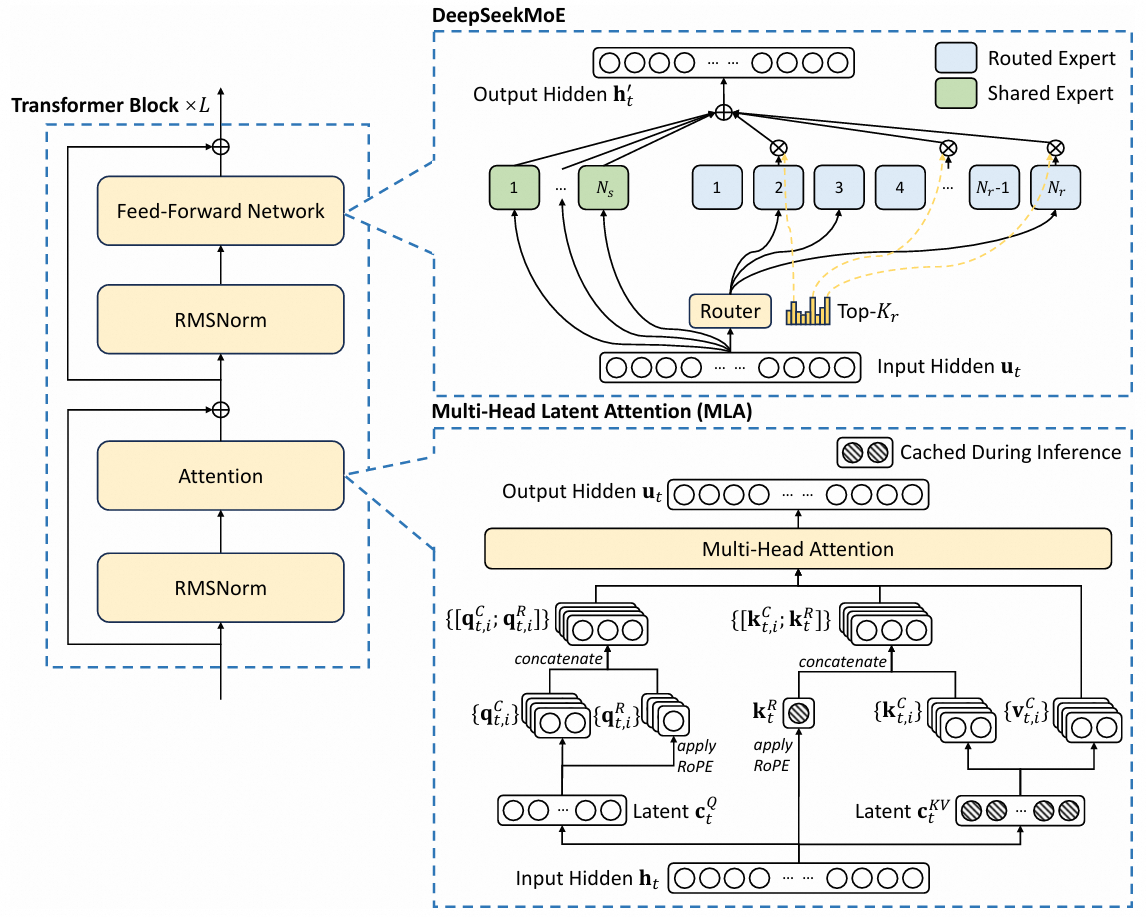
可以看到,和普通的Transformer一样,DeepSeek-V3也使用了Multi-Head Attention、Feed Forward和Add & Norm三种结构。只不过,DeepSeek-V3中使用的这三种结构都与普通的Transformer有所不同。首先,DeepSeek-V3中使用的不是一般的多头注意力,而是多头潜在注意力,它主要解决了KV缓存占用过多显存空间的问题。至于什么是KV缓存和潜在注意力,一句两句讲不完,以后可以专门写一篇文章来详细讲讲。Feed Forward使用的就是我们刚才讲的MoE结构。而Add & Norm被拆成了两部分,其中Norm在注意力层之前完成,并且使用的是RMSNorm而不是普通的Transformer中使用的Layer Norm。不过这些并不是这篇文章的重点,我们还是主要来关注一下MoE模块。
在DeepSeek-V3中,每一个MoE层总共有257个专家,其中一个是共享专家,剩余256个专家中每次会激活8个,相当于在257个专家中每次只使用了9个。由于MoE架构中模型绝大多数的参数都在专家中,因此每次只有大约3.5%的参数参与计算。由此我们大致可以看出MoE架构对于计算量的节省是相当可观的。
2. DeepSeek-V3的专家结构
那么每个专家内部具体是什么样的呢?下图中给出了DeepSeek-V3中每个专家的结构:
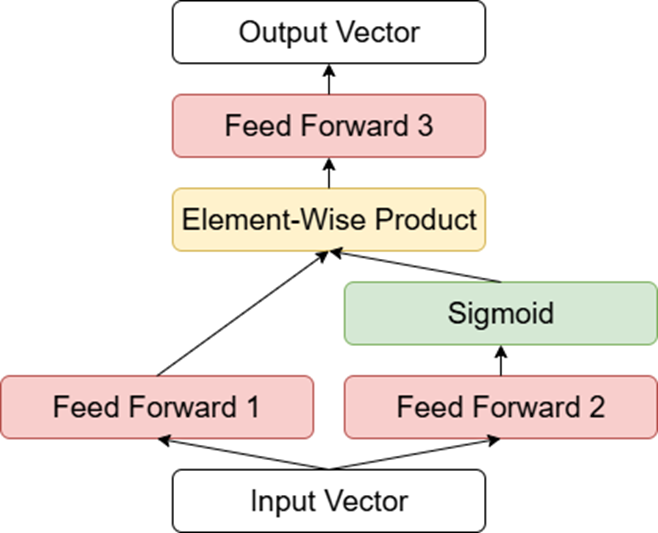
可以看到,每个专家内部有三个全连接层。先用第一个全连接层的输出乘以第二个全连接层经过Sigmoid函数的结果,再通过第三个全连接层,就得到了一个专家的最终输出。
至于什么是Sigmoid,它和ReLU一样,也是激活函数的一种,具体的公式是。它可以将输入转化为一个0~1之间的数,如下图所示:
![]()
全文5722字,码字不易,如果帮助到你的话,希望你能留个赞,谢谢。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)