深度强化学习调参技巧:以D3QN、TD3、PPO、SAC算法为例
深度强化学习 Deep Reinforcement Learning 简称为DRL运行DRL算法代码(实际使用+调整参数),需要更多DL基础阅读DRL算法论文(理解原理+改进算法),需要更多RL基础深度强化学习算法能训练能智能体: 机械臂取物、飞行器避障、控制交通灯、机器人移动、交易股票、训练基站波束成形选择合适的权重超越传统算法。一开始会问:算法那么多,要选哪个?训练环境怎么写?算法怎么调参?收

刚入门深度强化学习的人会问「DDPG算法参数如何调节? (或其他算法如何调参)」「DRL算法那么多,我该选哪个算法?」为了帮助更多的人,我把这些总结发到网上。本文整理自QQ群深度强化学习ElegantRL 1163106809的聊天记录。
写在前面
- 深度强化学习 Deep Reinforcement Learning 简称为DRL
- 运行DRL算法代码(实际使用+调整参数),需要更多DL基础
- 阅读DRL算法论文(理解原理+改进算法),需要更多RL基础
深度强化学习算法能训练能智能体: 机械臂取物、飞行器避障、控制交通灯、机器人移动、交易股票、训练基站波束成形选择合适的权重超越传统算法。实际使用时,问题却很多:
- 一开始会问:算法那么多,要选哪个?训练环境怎么写?
- 选完后会问:算法怎么调参?收益函数 reward function 要怎么改?(看的人多,有空再写,太长了)
第一个问题 请看姊妹篇 ↓ 你可以根据目录引导,只看与你任务相关的算法。
如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等(2021-04)2337 赞同 · 156 评论文章编辑
后一个问题,就是当前这篇文章 深度强化学习调参技巧:以D3QN、TD3、PPO、SAC算法为例,我没有看到满意的文章,所以才自己写。第一版 2021-01-24,第二版 2021-01-28,第三版 2021-02-21,第四部 2021-03-08
目录
- 训练环境怎么写?循序渐进,三个阶段
- 算法怎么调参?
- ------------------------------------
- 在off-policy算法中常见的超参数
- 在on-policy算法中常见的超参数
- 与离散动作探索有关的超参数
- 与连续动作探索有关的超参数
- 探索衰减、退火
- ------------------------------------
- D3QN特有的超参数
- TD3特有的超参数
- PPO+GAE特有的超参数
- SAC特有的超参数
- ------------------------------------
- 为什么我的算法越训练越差?
- 备用层,用于回复评论
- 对知乎上“DRL超参数调优”的一些观点进行点评
训练环境怎么写?
强化学习里的 env.reset() env.step() 就是训练环境。其编写流程如下:
初始阶段:
- 不要一步到位,先写一个简化版的训练环境。把任务难度降到最低,确保一定能正常训练。
- 记下这个正常训练的智能体的分数,与随机动作、传统算法得到的分数做比较。DRL算法的分数应该明显高于随机动作(随机执行动作)。DRL算法不应该低于传统算法的分数。如果没有传统算法,那么也需要自己写一个局部最优的算法(就算只比随机动作的算法高一点点都可以,有能力的情况下,要尽量写好)。
- 评估策略的性能: 大部分情况下,可以直接是对Reward Function 给出的reward 进行求和得到的每轮收益episode return作为策略评分。有时候可以需要直接拿策略的实际分数作为评分(移动速度/股票收益/目标完成情况 等)。
- 需要保证这个简化版的代码:高效、简洁、可拓展
改进阶段:
- 让任务难度逐步提高,对训练环境env 进行缓慢的修改,时刻保存旧版本的代码
- 同步微调 Reward Function,可以直接代入自己的人类视角,为某些行为添加正负奖励。注意奖励的平衡(有正有负)。注意不要为Reward Function 添加太多额外规则,时常回过头取消一些规则,避免过度矫正。
- 同步微调 DRL算法,只建议微调超参数,但不建议对算法核心进行修改。因为任务变困难了,所以需要调整超参数让训练变快。同时摸清楚在这个训练环境下,算法对哪几个超参数是敏感的。有时候为了节省时间,甚至可以为 off-policy 算法保存一些典型的 trajectory(不建议在最终验证阶段使用)。
- 每一次修改,都需要跑一下记录不同方法的分数,确保:随机动作 < 传统方法 < DRL算法。这样才能及时发现代码逻辑上的错误。要极力避免代码中出现复数个的错误,因为极难排查。
收尾阶段:
- 尝试慢慢删掉Reward Function 中一些比较复杂的东西,删不掉就算了。
- 选择高低两组超参数再跑一次,确认没有优化空间。
下面是我在网上搜索到的相关文章,尽管它们标题在说“强化学习调参”技巧,但文不对题,他们讨论的都是:如何写一个训练环境。写得不错,真的做过项目的人才写得出来。我不反对去看这两篇。经过评论区 的提醒 :“网上有篇讲义"The Nuts and Bolts of Deep RL Research, John Schulman, OpenAI, Dec 9th 2016",下面都是翻译的”
深度强化学习有哪些调参技巧? - 何之源 - 2020-02 (翻译的)
银河中的太阳系:强化学习RL调参技巧 2020-11 (翻译的)
我更多时候是看到网上写得不好、没有,我才写。即便是翻译引用,我都会注明来源。
算法怎么调参?
知乎有人提问:DDPG算法参数如何调节? (或其他算法如何调参),我下面的内容也是对这个问题的回答:
这个问题非常不好。很多DRL库会把算法也当成一个超参数,那么我为DDPG调参的时候,第一步就是换掉这个老旧的DDPG. 2016算法。然后为自己的任务选择一个合适的算法。请看 曾伊言:如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等(已完成) ,里面解释了: 为何DDPG DQN算法只适合入门而不适合使用。
无论是什么任务,你选择的算法必定与DQN变体、TD3、PPO、SAC这四种算法有关,它们占据不同的生态位,请根据实际任务需要去选择他们,在强化学习的子领域(多智能体、分层强化学习、逆向强化学习也会以它们为基础开发新的算法):
- 离散动作空间推荐:Dueling DoubleQN(D3QN)
- 连续动作空间推荐:擅长调参就用TD3,不擅长调参就用PPO或SAC,如果训练环境 Reward function 都是初学者写的,那就用PPO
所以下面我以这四种算法为例,讲这四种算法的调参技巧。我当然可以直接跟你说遇到什么state,正确的action 是什么,但是我希望多写一些推理过程。
我小时候,我身边的人说“不能在昏暗环境下看书,对眼睛不好”。后来我经常在昏暗的环境下看书,而视力却一直是顶级的——我开始怀疑这句话的正确性。经过思考,这句话其实是“在昏暗环境下看书,普通人类需要更靠近纸张以获取更大进光量,眼睛长时间看近处的东西,最终导致疲劳,长此以往导致视力下降”。不开灯的昏暗情况下,如果夜视力正常,且眼睛与书本保持合适距离,别看太久,那么完全可以正常看书。(不接受任何看不到视力表最下一行的人的反驳)
在DRL中也一样,我如果直接告诉你某种情况下 折扣因子 gamma 就该选 0.95 0.99 0.999,而不说推理过程,那么不懂的人照样不懂。我也希望各位 抱着怀疑眼光来看我接下来的所有推理。
DRL超参数的默认值无法给出,但是我可以给出不同任务下的超参数推荐组合,见「强化学习库:小雅 AgentRun.py」文件的 类 class Arguments 以及 函数 train__demo( )。
写在前面:我极力反对过度调参:在实验室中人肉搜索找出一组能刷出虚高分数的超参数并没有用。请不要沉迷调参。
在off-policy算法中常见的超参数
- 网络宽度:network dimension number。DRL 全连接层的宽度(特征数量)
- 网络层数:network layer number。一个输入张量到输出需要乘上w的次数
- 随机失活:dropout
- 批归一化:batch normalization
- 记忆容量:经验回放缓存 experimence replay buffer 的最大容量 max capacity
- 批次大小:batch size。使用优化器更新时,每次更新使用的数据数量
- 更新次数:update times。使用梯度下降更新网络的次数
- 折扣因子:discount factor、gamma
【网络宽度、网络层数】越复杂的函数就需要越大容量的神经网络去拟合。在需要训练1e6步的任务中,我一般选择 宽度128、256,层数小于8的网络(请注意,乘以一个w算一层,一层LSTM等于2层,详见曾伊言:LSTM入门例子)。使用ResNet等结构会有很小的提升。一般选择一个略微冗余的网络容量即可,把调整超参数的精力用在这上面不划算,我建议这些超参数都粗略地选择2的N次方,因为:
- 防止过度调参,超参数选择x+1 与 x-1并没有什么区别,但是 x与2x一定会有显著区别
- 2的N次方大小的数据,刚好能完整地放进CPU或GPU的硬件中进行计算,如Tensor Core
过大、过深的神经网络不适合DRL,因为:
- 深度学习可以在整个训练结束后再使用训练好的模型。而强化学习需要在几秒钟的训练后马上使用刚训好的模型。这导致DRL只能用比较浅的网络来保证快速拟合(10层以下)
- 并且强化学习的训练数据不如有监督学习那么稳定,无法划分出训练集测试集去避免过拟合,因此DRL也不能用太宽的网络(超过1024),避免参数过度冗余导致过拟合。
参考论文:Can Increasing Input Dimensionality Improve Deep Reinforcement Learning? ICML 2020 ,模仿DL的思路,直接在RL用大和深的神经网络效果不好,论文推荐用 OFENet (其实就是 DenseNet)
【dropout、批归一化】她们在DL中得到广泛地使用,可惜不适合DRL。如果非要用,那么也要选择非常小的 dropout rate(0~0.2),而且要注意在使用的时候关掉dropout。我不用dropout。
- 好处:在数据不足的情况下缓解过拟合;像Noisy DQN那样去促进策略网络探索
- 坏处:影响DRL快速拟合的能力;略微增加训练时间
【批归一化】经过大量实验,DRL绝对不能直接使用批归一化,如果非要用,那么就要修改Batch Normalization的动量项超参数。详见 曾伊言:强化学习需要批归一化(Batch Norm)吗?
【记忆容量】经验回放缓存 experimence replay buffer 的最大容量 max capacity,如果超过容量限制,它就会删掉最早的记忆。在简单的任务中(训练步数小于1e6),对于探索能力强的DRL算法,通常在缓存被放满前就训练到收敛了,不需要删除任何记忆。然而,过大的记忆也会拖慢训练速度,我一般会先从默认值 2 ** 17 ~ 2 ** 20 开始尝试,如果环境的随机因素大,我会同步增加记忆容量 与 batch size、网络更新次数,直到逼近服务器的内存、显存上限(放在显存训练更快)
当然,我不反对你探索新的记忆删除机制,我试过将“删除最早的数据”改成“越早的数据”或“和其他记忆重复的数据”有更大概率被删除。只能消耗一点CPU资源,在特定任务上得到比较好的效果,而且实现很复杂。如果你们探索出更好的方法记得告诉学界,先谢过了。
【批次大小、更新次数】一般我会选择与网络宽度相同、或略大的批次大小batch size。我一般从128、256 开始尝试这些2的N次方。在off-policy中,每往Replay 更新几个数据,就对应地更新几次网络,这样做简单,但效果一般。(深度学习里)更优秀的更新方法是:根据Replay中数据数量,成比例地修改更新次数。Don't Decay the Learning Rate, Increase the Batch Size. ICLR. 2018 。,经过验证,DRL也适用。我根据Replay中数据个数来调整 batch size 和 update times:
replay_max = 'the maximum capacity of replay buffer'
replay_len = len(ReplayBuffer)
k = 1 + replay_len / replay_max
batch_size = int(k * basic_batch_size)
update_times = int(k * basic_update_times)
for _ in range(update_times):
data = ReplayBuffer.random_sample(batch_size)
...【折扣因子】discount factor、discount-rate parameter 或者叫 gamma 。这个值很容易确定,请回答“你希望你的智能体每做出一步,至少需要考虑接下来多少步的reward?”如果我希望考虑接下来的t 步,那么我让第t步的reward占现在这一步的Q值的 0.1,即公式 0.1≈γt ,变换后得到 γ≈0.11/t :
gamma ** t = 0.1 # 0.1 对于当前这一步来说,t步后的reward的权重
gamma = 0.1 ** (1/t)
t = np.log(0.1) / np.log(gamma)
0.9 ~= 0.1 ** (1/ 22)
0.96 ~= 0.1 ** (1/ 56)
0.98 ~= 0.1 ** (1/ 114)
0.99 ~= 0.1 ** (1/ 229)
0.995 ~= 0.1 ** (1/ 459)
0.999 ~= 0.1 ** (1/2301) # 没必要,DRL目前无法预测这么长的MDPs过程
可以看到 0.96, 0.98, 0.99, 0.995 的gamma值
分别对应 56, 114, 229, 459 的步数gamma绝对不能选择1.0。尽管有时候在入门DRl任务选择gamma=1.0 甚至能训练得更快,但是gamma等于或过于接近1会有“Q值过大”的风险。一般选择0.99,在某些任务上需要调整。详见《Reinforcement Learning An Introduction - Richard S. Sutton》的 Chapter 12 Eligibility Traces。下图讲的是 lambda,它和 gamma 起作用的原理差不多。这本书的pdf版可以在斯坦福网站下载到, 强化学习群ElegantRL 1163106809 的群文件也可以有这个pdf以及其他DRL算法的公开论文。
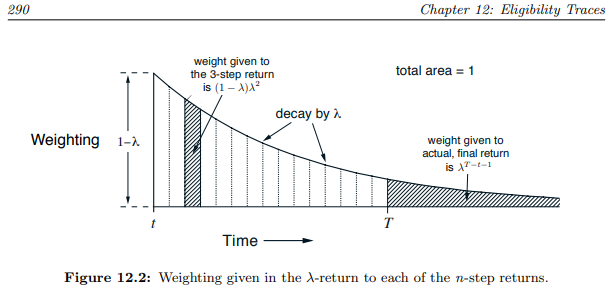
图片来自 《Reinforcement Learning An Introduction》 Chapter 12 Eligibility Traces
我上面使用折扣因子协助确定公式 γ≈0.11/t 中的 0.1 是什么来头?(2021-03-08 根据评论新增)
评论: 讲义"The Nuts and Bolts of Deep RL Research, John Schulman, OpenAI, Dec 9th 2016"提到,调节折扣因子可利用一个effective time horizon公式:1/(1-γ),即γ=0.99相当于往后考虑100时间步。折扣因子那部分所给公式里的0.01是有什么来头吗?

动图是 LunarLander任务,悬空状态下它会得到一些很小的 reward,黄色曲线与浅蓝色曲线显示它们一般在 ±5之间。降落后会一次性得到 +100的reward(下图(a)、(b)的黄色曲线 Reward Success)或者坠毁一次性扣-100(下图(b)的淡蓝色曲线 Reward Failure)。你希望智能体预见到多少步之后的 降落、坠毁事件?
下图(a) 展示了一次成功降落的结果在不同 gamma值下的表现。横坐标是第t步,纵坐标是第t步的Q值。我把贝尔曼公式 Qt=rt+γQt+1 写成求和的形式 Qt=∑tγt−1rt 。当 γ→1 时,有偏红曲线 Qt→∑trt 。当 γ→0 时,有偏黄曲线 Qt→rt 。
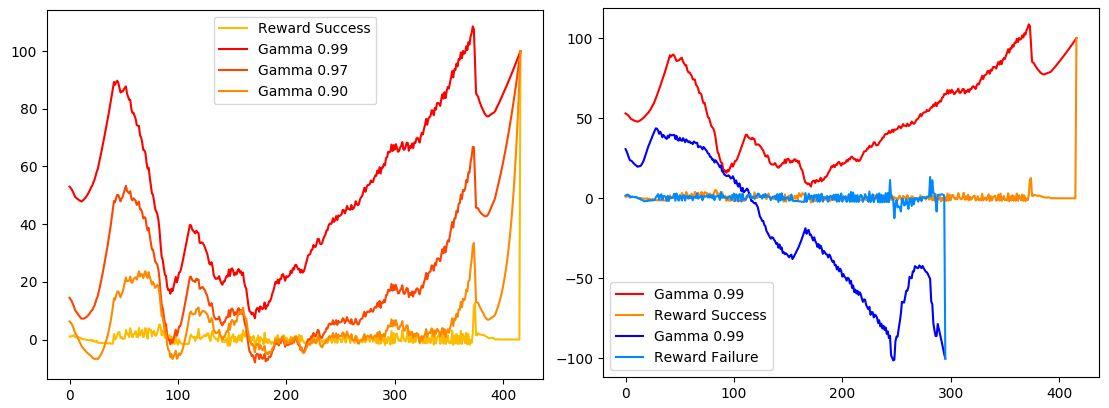
暂且将左图称为(a),右图称为(b)。这幅图是我以前画的,刚好可以拿来讲 gamma。
从(a)观察到,红色曲线可以提前200步“预测”到安全降落的事件,因此gamma=0.99比较合适。令gamma=0.99 画出右图(b),我们看到,深蓝线在第150步预测到的Q值已经很小,预示着约150步后会坠毁。深红线在第350步预测到Q值已经很大,预示着约150步后能平稳降落。所以在这个环境,把gamma定为0.99 可以让智能体预见到 150步以后的事件。事件发生后会得到一个比 日常reward 大得多的 结算reward,在这里 日常reward 是结算reward的0.05倍。游戏结束在第t 步结束时,结算reward rt 可能是±100。
我们来算算这个结算reward的设计是否正确:结算reward 在 Q1 里面会占多少会由 gamma值调整,展开贝尔曼公式有 Q1=γ0r1+γ1r2+⋯+γt−1rt , 游戏结束在第t 步结束。由于神经网络拟合Q值总有误差,因此智能体的结算reward的0.1倍一定要大于日常reward才能避免被稀释。此时算出最小结算reward的绝对值 5/0.1=50<100 。因此他们设计正确.
练习题:我训练一个机器人跑1米的距离,每一个step 消耗的最大电能是10,摔倒了就重新开始,我估计它50个 step 就能跑到终点,我应该如何设置它的 日常reward、结算reward、gamma值?(日常reward 和 结算reward 是我随便起的名字)
普通答案:
- 日常reward:每一个step得到的日常reward为消耗的电能的负数,它在 -10 到0 之间
- 结算reward:到达终点、或者摔倒,得到结算reward为 ±100分。
合理答案:
- 日常reward:消耗的电能在0~10之间,如果设置成 -10到0,那么一动就扣分会让机器人不喜欢动。如果设置成 0 到+10,那么机器人可能喜欢动来动去刷分,但是不一定会去终点。于是让机器人越靠近终点得分越高。我希望它每个step“因靠近终点而得到的reward” 刚好补偿 “电能消耗的负reward”。因此让日常rewad 为 (与终点的距离*(10/50) - 消耗的电能),日常reward的范围是 ±10。
- 结算reward:日常rewad变化范围是 ±10,如果我希望gamma设置为0.99,那么50个step后, 0.9950≈0.6 , 10/0.6≈17 。因此让结算reward 至少要大于17,可以设为±30分。
进阶答案:
- 日常reward:为了让Q值不要过大或者过小以妨碍Critic对它的拟合,日常reward在-10到+10之间太大了,在清楚每个step的reward均值时, 能写出等比数列求和公式Qt=∑tγt−1rt≈r¯∑tγt−1=r¯1−γt1−γ≈r¯11−γ (当t足够大,且gamma足够接近1的时候),这样就得到了 提到的 effective time horizon公式: 1/(1-γ)。经过计算,只要gamma值在0.95~0.995之间,我们调整日常reward 到 -1 到+1 附近就比较合适了。那么它的日常rewad 为 (与终点的距离*(1/50) - 消耗的电能) * (1/10)
- 结算reward:gamma值其实应该尽可能小一点比较好,如果让智能体预测太多步之后的事件会增长训练时间。于是我选择gamma**值为0.95 比较合适,有0.9950≈0.08 , 1/0.08≈12 ,结算reward的绝对值应该大于12。那么结算reward为±20分。
其实也不用算得那么麻烦,只要我们根据同类任务的reward function模板稍微改一下就行。50个step是步数比较少的例子,导致结算reward算出来比较小。按照这个模板得到的Q值会处于合理范围,用于拟合它的Critic也不用特地去调整学习率(默认 0.001~0.0001)。
在on-policy算法中常见的超参数
同策略(A3C、PPO、PPO+GAE)与异策略(DQN、DDPG、TD3、SAC)的主要差异是:
- 异策略off-policy:ReplayBuffer内可以存放“由不同策略”收集得到的数据用于更新网络
- 同策略on-policy:ReplayBuffer内只能存放“由相同策略”收集得到的数据用于更新网络
因此以下超参数有不同的选择方法:
- 记忆容量:经验回放缓存 experimence replay buffer 的最大容量 max capacity
- 批次大小:batch size。使用优化器更新时,每次更新使用的数据数量
- 更新次数:update times。使用梯度下降更新网络的次数
【记忆容量】on-policy 算法每轮更新后都需要删除“用过的数据”,所以on-policy的记忆容量应该大于等于【单轮更新的采样步数】,随机因素更多的任务需要更大的单层采样步数才能获得更多的 轨迹 trajectory,才能有足够的数据去表达环境与策略的互动关系。详见下面PPO算法的【单轮更新的采样步数】
【批次大小】on-policy 算法比off-policy更像深度学习,它可以采用稍大一点的学习率(2e-4)。因为【单轮更新的采样步数】更大,所以它也需要搭配更大的batch size(2**9 ~ 2**12)。如果内存显存足够,我建议使用更大的batch size,我发现一些很难调的任务,在很大的batch size(2 ** 14) 面前更容易获得单调上升的学习曲线(训练慢但是及其稳定,多GPU分布式)。请自行取舍。
【更新次数】一般我们不直接设置更新次数,而是通过【单轮更新的采样步数】、【批次大小】和【数据重用次数】一同算出【更新次数】,详见下面PPO算法的【数据重用次数】
update_times = steps * reuse_times / batch_size与离散动作探索有关的超参数
离散动作的探索就是要如何选择Q值最大以外的动作。
【epslion-Greedy 策略】按照贪婪策略探索离散动作:每次都从 已经被强化学习算法加强过的Q值中,选择Q值最大的那个动作去执行。为了探索,有很小的概率 epslion 随机地执行某个动作。Q Network(Critic) 的更新需要采集所有离散动作的样本,epslion-Greedy保证了Replay可以收集到足够丰富的训练数据。超参数 执行随机动作的概率 epslion我一般选择 0.1,然后根据任务需要什么程度的探索强度再修改。如果离散动作很多,我会尽可能选择大一点的 epslion。
【Noisy DQN 的探索策略】在网络中间添加噪声,得到带噪声的Q值,接着沿用贪婪策略,智能体会选择Q值最高的动作去执行。这种模式比起 epslion-Greedy的好处是:能保证多探索Q值高的动作,增加探索效率。坏处是Q值过低的动作可能很难被覆盖到(所幸Q Network 输出的Q值一般比较接近)。超参数就是噪声大小,一般我从方差0.2开始调起,然后print出不同动作Q值们的方差辅助我调参。
【输出离散动作的执行概率】在MuZero 算法中,让预测器(大号的 Q Network)额外输出动作的执行概率(使用softmax),详见 曾伊言:如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN/等(已完成) (搜索 MuZero),这种增加计算量的方法效果会更好。SAC for Discrete Action Space 也有类似的思想。这种方法不需要调参,智能体会自己决定自己的探索方式。
与连续动作探索有关的超参数
连续动作的探索几乎都通过加噪声完成。区别在于噪声的大小要如何决定。当你的任务困难到一加噪声就影响智能体的探索,那么加噪声也可以与epsilon-Greedy 同时使用:你可以选择合适加噪声,何时不加。
【OU-noise】普通的噪声是独立的高斯分布,有小概率会一直出现相同符号的噪声。OU-noise产出的噪声更为平缓,适用于惯性系统的任务。详见 强化学习中Ornstein-Uhlenbeck噪声是鸡肋吗? 我个人认为是鸡肋,DDPG作为一个早期的不成熟算法,探索能力弱,因此很需要OU-noise。然而,TD3算法明确在论文中写明“TD3不用OU-noise”,PPO SAC算法也没用它,我也不用。它给DRL引入了更多超参数,导致它经常能在实验室内调出自欺欺人的虚胖成绩,不适合实际使用
【TD3的探索方式】动作过激活函数tanh后,加上clip过的噪声,然后再clip一次,详见下方的【TD3的探索方式】
【SAC的探索方式】动作加上噪声后,经过激活函数,详见下方【SAC的探索方式】
请注意,当你使用任何连续动作空间的DRL算法,请让它输出的动作空间规范为(-1,+1),不需要为了物理含义而选择其他区间,因为任何区间都能通过线性变换获得(如0~1, -2~+2等)。选择不规范的空间百害而无一利:计算策略熵困难,神经网络拟合起来不舒服,clip不方便代,码实现不方便,不方便print出某个值与其他算法比较、等等。
探索衰减、退火
与探索有关的超参数都可以使用 衰减、退火。在离散动作中,探索衰减表现为逐步减小执行随机动作的概率 在连续动作中,探索衰减表现为逐步减小探索噪声的方差,退火同理。
- 衰减就是单调地减小(固定、不固定,比例、定值 ),直至某个限度后停止。在比较简单的环境里,算法可以在前期加强探索,后期减少探索强度,例如在训练前期使用一个比较大的 epslion,多执行随机动作,收集训练数据;训练中期让epslion逐步减小,可以线性减小 或者 乘以衰减系数,完成平缓过渡;训练后期干脆让epslion变为一个极小的数,以方便收敛。我建议适度地使用探索衰减,能不用尽量不用。(我不建议0,这会降低RelapyBuffer中数据的多样性,加大过拟合风险)
- 退火就是减小后,(缓慢、突然)增大,周期循环。比衰减拥有更多的超参数。我不推荐使用,除非万不得已。
探索衰减一定会有很好的效果,但这种“效果好”建立在人肉搜索出衰减超参数的基础之上。成熟的DRL算法会自己去调整自己的探索强度。比较两者的调参总时间,依然是使用成熟的DRL算法耗时更短。
D3QN特有的超参数
D3QN即 Dueling DoubleDQN。先按上面的提示,选择一个略微冗余的Q Netwrok,详见上面的【在off-policy算法中常见的超参数】,然后从默认值0.1 开始调整 epsilon-Greedy的探索概率 epsilon,详见上面的【epslion-Greedy 策略】
TD3特有的超参数
- 探索噪声方差 exploration noise std
- 策略噪声方差 policy noise std
- 延迟更新频率 delay update frequency
同样作为确定策略梯度算法,不存在某个任务DDPG会表现得比TD3好。除了教学,没有理由使用DDPG。如果你擅长调参,那么可以可以考虑TD3算法。如果你的算法的最优策略通常是边界值,那么你首选的算法就是TD3(例如:不需要考虑能耗,只关心机器人的移动速度;将最大交易金额设计得很小的金融任务)
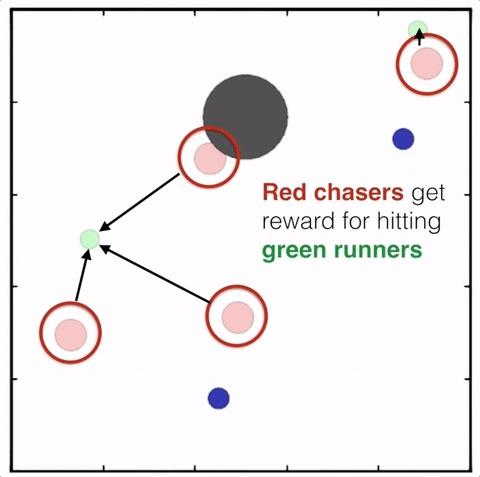
MADDPG 使用的 捕食者-被捕食者 环境,multiagent-particle-envs 最佳策略总在动作边界
【TD3的探索方式】让她很容易在探索「边界动作」:
- 策略网络输出张量,经过激活函数 tanh 调整到 (-1, +1)
- 为动作添加一个clip过的高斯噪声,噪声大小由人类指定
- 对动作再进行一次clip操作,调整到 (-1, +1)
好处:一些任务的最优策略本就存在存在大量边界动作,TD3可以很快学得很快。坏处:边界动作都是 -1或 +1,这会降低策略的多样性,网络需要在多样性好数据上训练才不容易过拟合。对于clip 到正负1之间的action,过大的噪声方差会产生大量边界动作
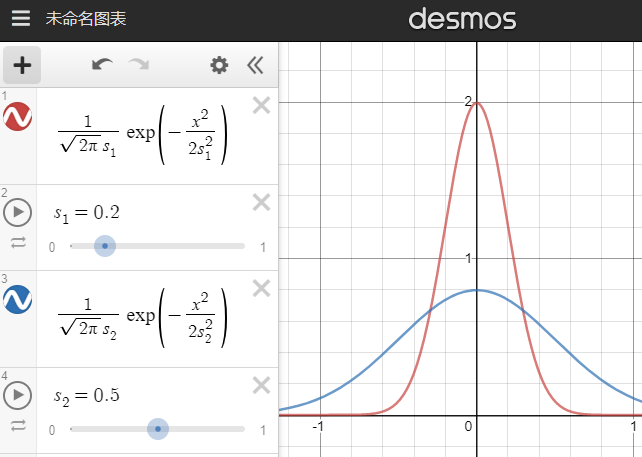
不同标准差的正态分布,红线std2=0.2,蓝线std2=0.5
【探索噪声方差 exploration noise std】就是上图中的s。我们需要先尝试小的噪声方差(如0.05),然后逐渐加大。大的噪声方差刻意多探索边界值,特定任务下能让探索更快。且高噪声下训练出来的智能体更robust(稳健、耐操)。请注意:过大的噪声方差(大于上图蓝线的0.5)并不会让探索动作接近随机动作,而是让探索动作更接近单一的边界动作。此外,过大的噪声会影响智能体性能,导致她不容易探索到某些state。
因此,合适的探索噪声方差只能慢慢试出来,TD3适合愿意调参的人使用。在做出错误动作后容易挽回的环境,可以直接尝试较大的噪声。我们也可以模仿 epslion-Greedy,设置一个使用随机动作的概率,或者每间隔几步探索就不添加噪声,甚至也在TD3中使用探索衰减。这些操作都会增加超参数的数量,慎用。
【策略噪声方差 policy noise std】确定了探索噪声后,策略噪声只需要比探索噪声稍大(1~2倍)。TD3对策略噪声的解释是“计算Q值时,因为相似的动作的Q值也是相似的,所以TD3也为动作加一个噪声,这能使Q值函数更加光滑,提高训练稳定性 qt=rt+γQ(st,at+ϵ) 。见论文的 Target Policy Smoothing Regularization”。详见 曾伊言:强化学习算法TD3论文的翻译与解读 。我们还能多使用几个添加噪声的动作,甚至使用加权重要性采样去算出更稳定的Q值期望。在确定策略梯度算法里的这种“在计算Q值时,为动作加noise的操作”,让TD3变得有点像随机策略梯度。无论这里的 at+ϵ 是否有clip,策略噪声方差最大也不该超过0.5。
【延迟更新频率 delay update frequency】TD3认为:引入目标网络进行 soft update 就是为了提高训练稳定性,那么既然 network 不够稳定,那么我们应该延迟更新目标网络 target network,即多更新几次 network,然后再更新一次target network。从这个想法再拓展出去,我们甚至可以模仿TTUR的思想做得更细致一点,针对双层优化问题我们能做:
- 环境随机因素多,则需要尝试更大的延迟更新频率,可尝试的值有 1~8
- 提供策略梯度的critic可以多更新几次,再更新一次actor,可尝试的值有 1~4
- 提供策略梯度的critic可以设计更大的学习率,例如让actor的学习率是critic 的 0.1~1倍
- 由于critic 需要处理比 actor 更多的数据,因此建议让critic网络的宽度略大于actor
TTUR的思想,详见 曾伊言:从双层优化视角理解对抗网络GAN 的 TTUR (Two Time-Scale Update Rule)
对于一个n维度的连续动作,我们将一个常数设为动作方差过于朴素,为了刷榜(这不道德),我甚至可以使用PPO、SAC搜索出来的探索噪声方差(也是n维的向量)给TD3使用。甚至在PPO搜出来的噪声方差的基础上,根据物理意义对方差进行微调。其实这相当于在SAC这种使用了从TD3学来TwinCritic结构的算法,在训练后期固定噪声方差进行训练。
PPO+GAE特有的超参数
PPO比其他算法更robust(稳健),这与她使用了 Minorize-Maximization (MM algorithm)有很大关联,这保证了PPO每次更新策略 总能让性能获得单调的提升,详见RL — Proximal Policy Optimization (PPO) Explained - 2018-07 - Jonathan Hui 这是介绍PPO算法极好的文章,写在版权保护意识很强的 Medium网站,大陆不能正常访问。
PPO调参非常简单,因为她对超参数变化不敏感。
- 【单轮更新的采样步数】sample_step
- 【数据复用次数】reuse_times
- 【限制新旧策略总体差异的系数】lambda_entropy
- 【对估计优势的函数进行裁剪】clip epsilon ,让策略的更新保持在信任域内
- 【GAE调整方差与偏差的系数】lambda_advantage(与gamma相似,但不同)
【单轮更新的采样步数】sample_step。我们先删掉旧的数据,然后让智能体与环境交互,交互完成后,我们使用刚刚采集到的数据去训练网络,这是一轮更新。交互时,actor就会rollout 出一条 收集记录了做出某个动作下状态转移的轨迹 trajectory。为了尽可能准确地用多条轨迹 去描述环境与策略的关系,在随机因素大的环境中,我们需要加大采样步数。这个受环境影响很大,无法给出默认值(我一般定 2**12)。所幸过大的采样步数只是会降低数据利用效率,让训练变慢而已。尝试的时候,先在显存可承受的范围内尽可能尝试一个偏大的数值,确保训练正常之后(学习曲线能缓慢地上涨,且不会突然下降),再逐步地减小采样步数,用于加快训练速度。
许多环境有终止状态(done=True)。因此我们不会在达到规定采样步数后马上退出采样,而是继续采样,直至遇到终止状态。这保证了每一段轨迹 trajectory 的完整。
许多环境有终止状态(done=True),甚至有时候会故意设置一个终止状态,用于阶段性地结算 reward,或者利用终止状态的固定reward降低估值函数收敛难度,或者只是想要更简单地使用GAE这类算法。
【数据复用次数】reuse_times。RelayBuffer内的每个样本要用几次,主要看看学习率、批次大小和拟合难度。深度强化学习会使用比深度学习更小的学习率(1e-3 → 1e-4),我在多种类型的任务下尝试,在batch size 为512的情况下,默认值会设为8,然后再去调整。建议先尝试偏小的数值,以避免过拟合。
replay_len = len(ReplayBuffer)
assert replay_len >= sample_step
for _ in range(int(replay_len / batch_size)):
data = RelplayBuffer.random_sample(batch_size)
...PPO使用Adam还是 SGD+动量?都可以,PPO论文建议用Adam,我也建议用Adam,理由是快,它的自适应只需要很短的预热时间。SGD+动量建议在算力充足的情况下,显存和采样允许较大batch size时,搭配更大的 复用次数去使用,它虽然慢,但不易过拟合。
在on-policy算法中出现repeat_times 是一个很奇怪的事情。因为只要对策略网络进行更新,就意味着策略已经发生了改变,而on-policy算法只能使用同策略的数据进行更新,因此理论上repeat_times只能是1。然而,PPO算法就是能复用训练数据,这是因为PPO算法只在 trust region 内更新,这让它的新旧策略差异一直被限制在某个范围内,只要新旧策略差异不太大,那么作为on-policy算法的它,就能重复使用训练数据 。on-policy算法PPO因为PPO对数据进行了复用,导致它变得很像一个off-policy,详见 深度解读:Policy Gradient,PPO及PPG 6.1 importance sampling 的使用。
因此当我们放宽对新旧策略的限制(如,把clip改大),鼓励探索(如,把 lambda_entropy 调大),那么我们就一定需要减少 repeat_times,防止过度更新导致新旧策略差异过大。
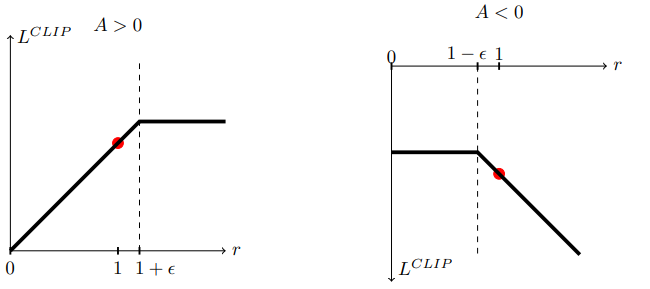
【限制新旧策略总体差异的系数】lambda_entropy 我推荐的默认值是 0.01(可选 0.005 ~ 0.05) 它越大,会让新旧策略越不同。它是下面公式中的 β 。如果想要使用默认值,那么我们最好对下面公式中的前一项 A^ 做正则化,以平衡两个优化目标的权重。
Lt(θ)=rt(θ)A^−β KL(πθold,πθnew)
随机策略梯度算法,不仅会鼓励Agent获得更高的reward,也会鼓励Agent探索,探索力度过强会导致Agent搜索出来的策略一直在最优策略附近“徘徊”,如下图右,曲线上升到最高点后,持续训练会让learning curve 略微下降。( 如PPO的 entropy loss 的 lambda过大,SAC算法的 reward scale 过小)。
然而,在下图左,持续训练让learning curve 明显下降则是因为:网络训练过度导致过拟合(对于RL来说,一般在训练后期过拟合是因为 “replay buffer 内部因为探索过弱而充满重复的数据”、或者是“actor网络使用了累计过多错误的critic网络提供的梯度”)。请注意区分。
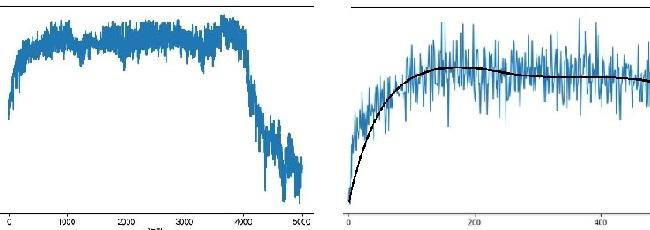
QQ群深度强化学习ElegantRL 1163106809 群友提供的图片:左,成都-小飞侠,右,深圳-David
此外,上面的学习曲线的波动太大了,有一些解决方案,详见本页面【减小学习曲线的波动】
【对估计优势的函数进行裁剪】clip epsilon。默认值是 0.2 (可选 0.1 ~ 0.3)。在代码中经常是 ratio = ratio.clamp(1-clip, 1+clip)。ratio调整了每个采样更新的步长。它越小,表示信任域越窄,策略更新越谨慎,从避免让新旧策略差异过大,它是下图中的 ϵ 。
PPO论文图1, clip epsilon
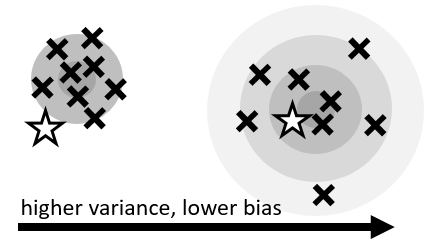
【GAE调整方差与偏差的系数】lambda_advantage,或者说它是GAE的折扣因子,默认值是 0.98 (可选0.96 ~ 0.99),在GAE论文 section 3 Advantage Function Estimation 解释了这个 lambda 值的选取。我们需要做的,就是调整这个值,让我们的样本的范围(同心圆)刚好把目标(星星)圈住,如下图。
方差variance 与偏差bias
lambda值与gamma值不同(尽管它们很像)。增加训练样本能让它更详细地描述环境与策略,得到更小的方差与偏差。然而训练样本是有限的,这就逼迫我们在 方差和偏差之间做一个取舍。GAE 的lambda值给我我们这种选择的余地,lambda越小:方差越小但偏差越大。我们要做的就是调整lambda,让上面图中的渐变同心圆尽可能地覆盖我们的目标星星。推荐尝试的lambda 值有 0.95~0.999。我一般设置默认值为0.98。想了解更多,看 小错:强化学习中值函数与优势函数的估计方法 - 2021-01 ,介绍全面。
SAC特有的超参数
尽管下面列举了4个超参数,但是后三个超参数可以直接使用默认值(默认值只会有限地影响训练速度),第一个超参数甚至可以直接通过计算选择出来,不需要调整。
- reward scale 按比例调整奖励
- alpha 温度系数 或 target entropy 目标 策略熵
- learning rate of alpha 温度系数 alpha 的学习率
- initialization of alpha 温度系数 alpha 的初始值
SAC有极少的超参数,甚至这些超参数可以在训练开始前就凭经验确定。
【奖励比例】reward scale SAC最大熵算法 策略网络的目标函数是 V(st)=Eat∼π[Q(st,at)−αlog(at∣st)] ,按有监督深度学习的写法,有 Lactor=λ1Lreward+λ2Lentropy :
- Lreward=Q(st,at) 让actor 输出的策略在critic处获得更高的累计回报
- Lentropy=−log(at∣st) 尽可能让actor 输出的策略有更高的策略熵
任何存在多个loss相加的目标函数,一定需要调整系数 lambda,例如SAC算法、共享了actor critic 网络的A3C或PPO,使用了辅助任务的PPG。我们需要确定好各个 lambda 的比例。SAC的第二篇论文加入了自动调整 温度系数 alpha 的机制,处于lambda2位置的温度alpha 已经用于自动调整策略熵了,所以我们只能修改lambda1。
reward scaling 是指直接让reward 乘以一个常数k (reward scale),在不破坏reward function 的前提下调整reward值,从而间接调整Q值到合适的大小。 ∑kri=k∑ri=kQt (累计收益Q)。修改reward scale,相当于修改lambda1,从而让可以让 reward项 和 entropy项 它们传递的梯度大小接近。与其他超参数不同,只要我们知晓训练环境的累计收益范围,我们就能在训练前,直接随意地选定一个reward scaling的值,让累计收益的范围落在 -1000~1000以内即可,不需要精细调整:
Environment Episode return Reward scale (gamma=0.99)
--------------------|( min, target, max)---|--------------
Ant (PyBullet) ( -50, 2500, 3500) 2 **-3
LunarLander (-800, 200, 300) 2 **-2
BipdealWalker (-200, 200, 340) 2 ** 0
Minitaur (PyBullet) ( -2, 15, 30) 2 ** 3我还建议:为了让神经网络Critic拟合Q值的时候舒服一点,调整reward scale时也要照顾到Q值,让它的绝对值小于256。请注意:
- 调整gamma值也会影响累计折扣回报 ∑γt−1rt (Critic网络需要拟合的Q值),它的绝对值在100以内时,能方便神经网络去拟合它。这对于所有DRL算法都有用,只是在SAC算法中效果最好。SAC论文作者自己也在github讨论过reward scaling,但是解释太少了。
【温度系数、目标策略熵】 Temperature parameters (alpha)、target 'policy entropy'。SAC的第二篇论文加入了自动调整 温度系数 alpha 的机制:通过自动调整温度系数,做到让策略的熵维持在目标熵的附近(不让alpha过大而影响优化,也不让alpha过小而影响探索)
策略熵的默认值是 动作的个数 的负log,详见SAC的第二篇论文 section 5 Automating Entropy Adjustment for Maximum Entropy 。SAC对这个超参数不敏感,一般不需要修改。有时候策略的熵太大将导致智能体无法探索到某些有优势的state,此时需要将目标熵调小。
策略熵是负log形式 policy_entropy = log_prob = -log(sum(...))
目标熵也是负log形式 target_entropy = -log(action.shape)【温度系数 alpha 的学习率】learning rate of alpha 温度系数alpha 最好使用 log 形式进行优化,因为alpha是表示倍数的正数。一般地,温度系数的学习率和网络参数的学习率保持一致(一般都是1e-4)。当环境随机因素过大,导致每个batch 算出来的策略熵 log_prob 不够稳定时,我们需要调小温度系数的学习率。
【温度系数 alpha 的初始值】initialization of alpha 温度系数的初始值可以随便设置,只要初始值不过于离奇,它都可以被自动调整为合适的值。一般偷懒地将初始值设置为 log(0) 其实过大了,这会延长SAC的预热时间,我一般设置成更小的数值,详见 The alpha loss calculating of SAC is different from other repo · Issue #10 · Yonv1943/ElegantRL 。
为什么我的算法越训练越差?
这是很常见,你可以看看诚实的 Learning Curve 长什么样子,详见曾伊言:如何选择深度强化学习算法?结尾的【学习曲线怎么看?】,看的人多再写。
大部分情况下,算法越训练越差能避免,但也可以不理会。因为DRL只需要根据学习曲线保存性能最好的策略即可(前提是对每个策略的实际性能评估足够准确)。
备用层,用于回复评论
评论区好的交流过程会被直接加到正文
对知乎上“DRL超参数调优”的一些观点进行点评
在知乎搜索“强化学习 调参”,第一页的搜索结果有如下(写于2021-1-19):
DDPG算法参数如何调节? 我对其他回答都不满意,因此才写了这篇文章。
强化学习:DDPG算法详解及调参记录 - 1335 - 2020-03 打台球。反面例子,完成于2020年的作品竟然使用DDPG. 2016 以及 DQN. 2014 这些旧算法。
强化学习过程中为什么action最后总会收敛到设定的行为空间的边界处? 我会回答这个问题
启人zhr:强化学习中的调参经验与编程技巧(on policy 篇) 可以看,但不够总结,像实验报告
Infinity:强化学习调参心得 2018-03 ,我反对里面的很多观点,那些观点像刚入门的人写出来的。我会给出赞同、反对的理由,逐一讨论。这篇文章可能因为写的早而帮助(误导)了很多人,里面的错误一定要指出。我推测:他的很多错误结论是在简单的任务(训练1分钟就通关的任务)中得出来的,这些“错误改进方法”可以在简单任务中“有效”,但这不是我们该学的。
(第一点)数据预处理:进行resize和变成灰度图,。。,至于要不要变成灰度图,。。
(最后一点)skip frame:针对视频的应用,计算量太大,所以一般使用skip frame
说的有道理,但是这可以总结为:在不影响性能的情况下,尽可能降低state的数据量,以减少DRL算法需要搜索的state space,用于加快训练速度。
weight初始化:采用随机或者normal distribution
完全错误,应该交给深度学习框架(PyTorch TensorFlow 等)自己去调节。若调节,在DRL中建议使用正交初始化,详细解释去查PyTorch官方文档,如下:
def _layer_norm(layer, std=1.0, bias_const=1e-6):
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)activation function:ReLU
讲得不清楚,应说:对于初学者,中间层的激活函数只推荐用 ReLU,不建议耗费精力去尝试别的。输出action 的那一层,该用 tanh softmax 还是继续用。
Optimizer的选择:一般使用Adam效果会比较好,也不需要自己设置参数。RMSProp和Adam效果差不多,不过收敛速度慢一些。
完全错误,Adam效果会比较好,但是在RL里,需要自己手动把默认的学习率调地比DL低一个数量级。RMSProp比Adam慢很多,在RL、GAN这种双层优化问题中,Adam需要将动量调小一点(调到0就近似RMSProp了),RMSProp+动量=Adam,因此没有任何理由用RMSprop了。
experience sample:自己模拟几个到达山顶的Sample,可以大大加快收敛
这个建议太局限了,只是一些萌芽状态的想法,在其他任务中没有用。想要了解更多应该去看模仿学习、以及稀疏收益 sparse reward 的那些强化学习论文。
训练过程:把episode的reward打出来看,要是很久都没有改进,基本上可以停了,马上开始跑新的。
这个建议很对,现在训练DRL对需要把 学习曲线 learning curve 画出来。但是reward 不上升,可能是运气不好,但是更大概率是算法不好,应该换更好的DRL算法,或者针对性地修改 Reward function。更换 random seed 重跑 是刻舟求剑。
exploration decay:一般是从1 decay到0.1,但是如果一开始就有不错的效果,可以从0.5,0.6开始,效果也是很不错的。
这非常局限。探索衰减是以前DRL算法发展不健全的时候,迫不得已使用的方法。以前的DRL算法(DDPG)的探索能力不足,因此需要手动修改动作噪声,帮助算法完成早期探索过程,并且要在训练后期将噪声降下来,帮助算法完成后期的收敛过程。因此才强行增加了很多调参的工作在“探索衰减”上。我很不建议滥用这种方法,尽管它能在实验室跑出令人咋舌的极好result,但这事实上是人工梯度下降。如果任务不是特别简单 就根本用不了这些方法。
gamma:如果reward延时特别严重,可以提高gamma,设置成1都可以。如果reward的实时性比较好,可以设置得小一点。
完全错误。gamma绝对不可以是1,在每轮步数很长甚至没有终止状态的任务里,这会导致不收敛。gamma的选取是可计算的,这会影响智能体做出动作要考虑多少步的收益。
target stable:Double network
这里讲的是 soft update 时用到的 target network,这样软更新目标网络,会让网络变稳定,详细请看论文 Taming the Noise in Reinforcement Learning via Soft Updates 。以及Double DQN、TD3算法的 Double Q Network、Twin Critics。因为低估误差不会传播,因此在DRL里,我们要降低高估误差,而min(Q1, Q2) 能降低Q值的高估误差,详细请看原论文,或者看 曾伊言:强化学习算法TD3论文的翻译与解读
减小学习曲线的波动
如下图,波动过大的曲线,不利于我们评估DRL算法。
QQ群深度强化学习ElegantRL 1163106809 群友提供的图片:左,成都-小飞侠,右,深圳-David
先弄清楚造成波动的原因,然后采用对应的解决方案:
- 如果在策略网络没有更新的情况下,Agent在环境中得到的分数差异过大。那么这是环境发生改变造成的:1. 每一轮训练都需要 env.reset(),然而,有时候重置环境会改变难度,这种情况下造成的波动无法消除。2. 有时候是因为DRL算法的泛化性不够好。此时我们需要调大相关参数增加探索,以训练出泛化性更好的策略。
- 如果在策略网络没有更新的情况下,Agent在环境中得到的分数差异较小。等到更新后,相邻两次的分数差异很大。那么这是环境发生改变造成的: 1. 把 learning rate 调小一点。2. 有时候是因为算法过度鼓励探索而导致的,调小相关参数即可。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)