

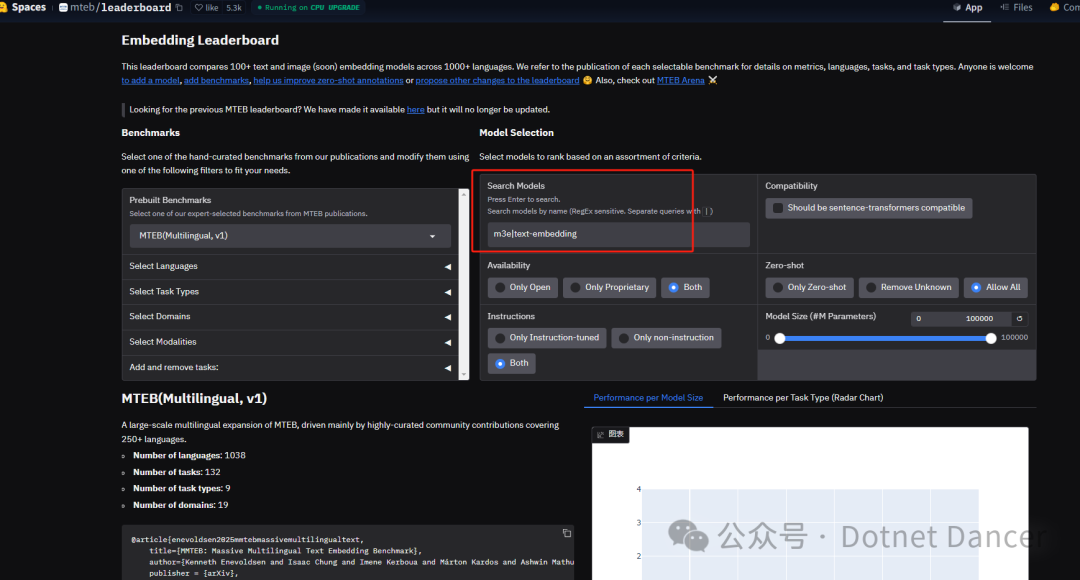
前言:嵌入向量模型排行榜,可以在这个网站上进行查看。可以手动选择不同的模型进行横向对比:
https://huggingface.co/spaces/mteb/leaderboard
例如可以输入需要对比的模型,下方会实时提供不同模型的测试评分
作者:Wesky
公众号快捷关注:

接下来开始爬坑,需要你的系统环境有conda,安装minianaconda或者anaconda都可以自带conda环境。这个步骤省略,如果感兴趣可以看我历史文章,有写过类似的。
conda下面安装python环境和huggingface_hub,此处py环境设定为3.10

创建完毕,进入到conda环境

设置huggingface的镜像地址环境变量,用于方便快捷下载使用。设置镜像地址:
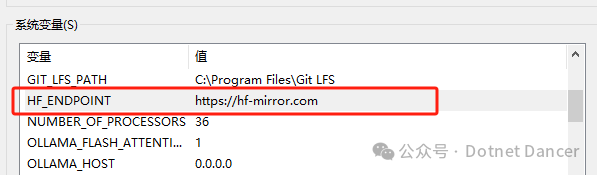
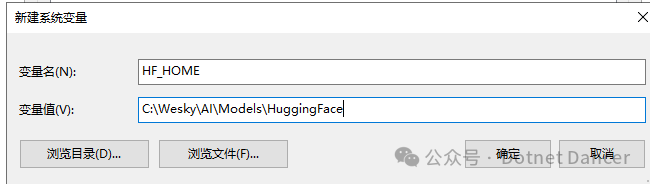
设置HF的环境变量,以及缓存的环境变量。
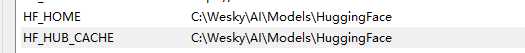
然后重新开启一个控制台,开始下载嵌入向量模型,我这儿使用
m3e-large这个向量模型。模型可以自己喜欢哪款用哪款,此处的教程我以这个向量模型为例展开。
使用hf的cli命令进行下载:
huggingface-cli download moka-ai/m3e-large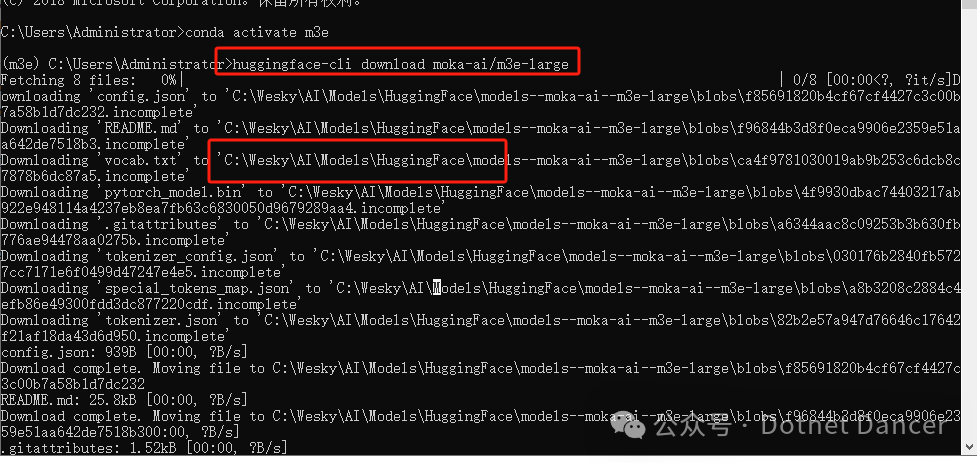
下载到本地的效果
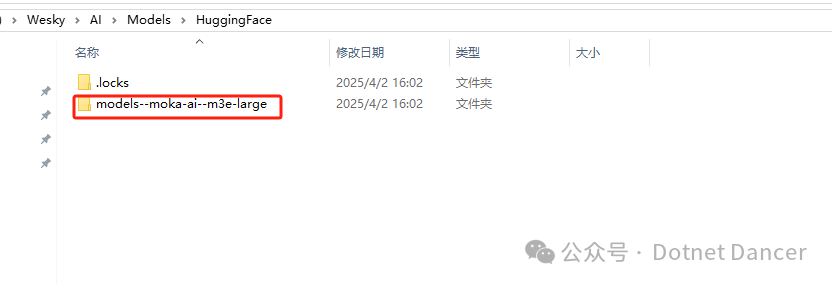
接下来编写有关服务,开放给外部平台使用。
安装一些依赖环境,用于开启webapi服务和一些基本处理:
pip install fastapi uvicorn transformers torch requests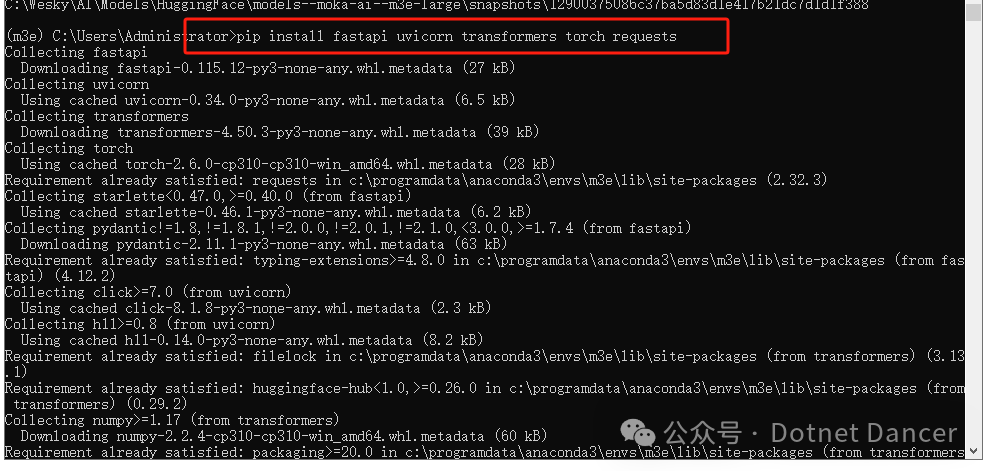
编写运行脚本代码
from fastapi import FastAPIfrom pydantic import BaseModelfrom transformers import AutoModel, AutoTokenizerimport torchapp = FastAPI()model_path = "C:\Wesky\AI\Models\HuggingFace\models--moka-ai--m3e-large\snapshots\\12900375086c37ba5d83d1e417b21dc7d1d1f388"tokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModel.from_pretrained(model_path)class RequestData(BaseModel): text: str@app.post("/embed")async def get_embedding(data: RequestData): inputs = tokenizer(data.text, return_tensors="pt", padding=True, truncation=True) with torch.no_grad(): outputs = model(**inputs) embedding = outputs.last_hidden_state.mean(dim=1).squeeze().tolist() return {"embedding": embedding}if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=12580)在conda环境下运行脚本

运行成功,在AI知识库前端应用上面添加向量模型的时候,发现请求错误 404错误,说明脚本使用方式可能不对
换一种方式,使用openai风格的形式来实现,先安装一些依赖包
pip install fastapi uvicorn sentence-transformers编写服务代码:
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom sentence_transformers import SentenceTransformerimport numpy as npfrom fastapi.middleware.cors import CORSMiddleware # 解决跨域问题app = FastAPI()model = SentenceTransformer('C:\Wesky\AI\Models\HuggingFace\models--moka-ai--m3e-large\snapshots\\12900375086c37ba5d83d1e417b21dc7d1d1f388')# 允许跨域请求(关键!)app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_methods=["*"], allow_headers=["*"],)class OpenAIRequest(BaseModel): input: str | list[str] model: str = "m3e-large"@app.post("/v1/embeddings")async def embeddings(request: OpenAIRequest): try: print("Received request:", request.dict()) # 打印请求内容 if isinstance(request.input, str): texts = [request.input] else: texts = request.input embeddings = model.encode(texts).tolist() return { "object": "list", "data": [ { "object": "embedding", "embedding": emb, "index": idx } for idx, emb in enumerate(embeddings) ], "model": request.model } except Exception as e: print("Error details:", str(e)) # 输出详细错误 raise HTTPException(status_code=500, detail=str(e))if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=12580)运行程序,在知识库前端重新添加,发现遇到新的错误:

经过分析,错误原因是某知识库工具在调用嵌入模型前对文本进行了分词(Tokenization)并传递了Token ID列表,而非原始文本。所以程序里面需要同时也做个Token ID列表的处理,使用openai的一个分词库来实现。
安装openai分词库:
pip install tiktoken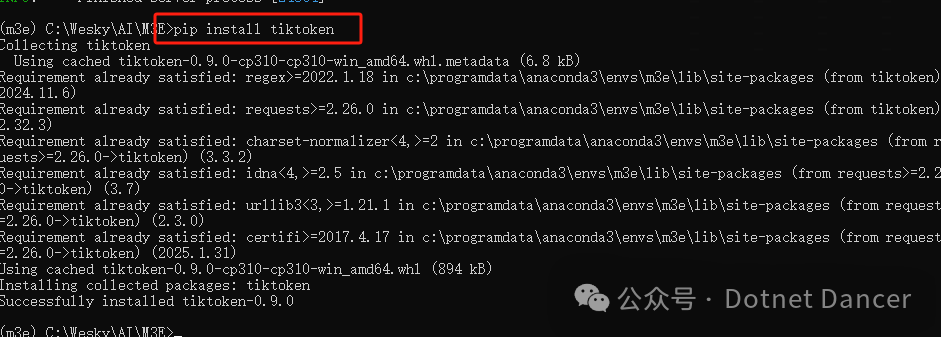
修改代码,当前的向量处理服务端代码如下:
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom sentence_transformers import SentenceTransformerimport numpy as npfrom fastapi.middleware.cors import CORSMiddleware # 解决跨域问题import tiktoken # 新增依赖from typing import Unionapp = FastAPI()model = SentenceTransformer('C:\Wesky\AI\Models\HuggingFace\models--moka-ai--m3e-large\snapshots\\12900375086c37ba5d83d1e417b21dc7d1d1f388')encoder = tiktoken.get_encoding("cl100k_base") # 加载OpenAI分词器# 允许跨域请求(关键!)app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_methods=["*"], allow_headers=["*"],)class OpenAIRequest(BaseModel): input: Union[str, list[Union[str, int]], list[list[int]]] # 允许多种输入类型 model: str = "m3e-large"def decode_tokens(token_ids: list[int]) -> str: """将Token ID列表解码为文本""" try: return encoder.decode(token_ids) except Exception as e: raise ValueError(f"Token解码失败: {str(e)}")@app.post("/v1/embeddings")async def embeddings(request: OpenAIRequest): try: print("[Debug] 原始请求input:", request.input) # 解析input参数 texts = [] if isinstance(request.input, str): texts = [request.input] elif isinstance(request.input, list): # 处理嵌套列表(如[[57668, 53901]]) if isinstance(request.input[0], list): token_ids = request.input[0] texts = [decode_tokens(token_ids)] # 处理单层列表(如[57668, 53901]) elif isinstance(request.input[0], int): texts = [decode_tokens(request.input)] else: texts = request.input # 假设是字符串列表 else: raise ValueError("不支持的input类型") print("[Debug] 解码后文本:", texts) embeddings = model.encode(texts).tolist() return { "object": "list", "data": [{"object": "embedding", "embedding": emb, "index": idx} for idx, emb in enumerate(embeddings)], "model": request.model } except Exception as e: print("[Error]", str(e)) raise HTTPException(status_code=400, detail=str(e))if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=12580)重新添加,提示成功
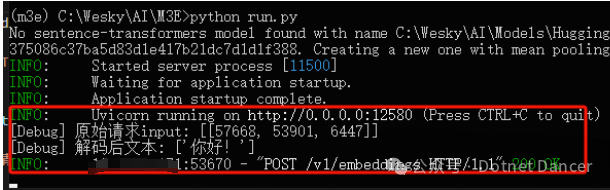
知识库应用端上面的配置如下:
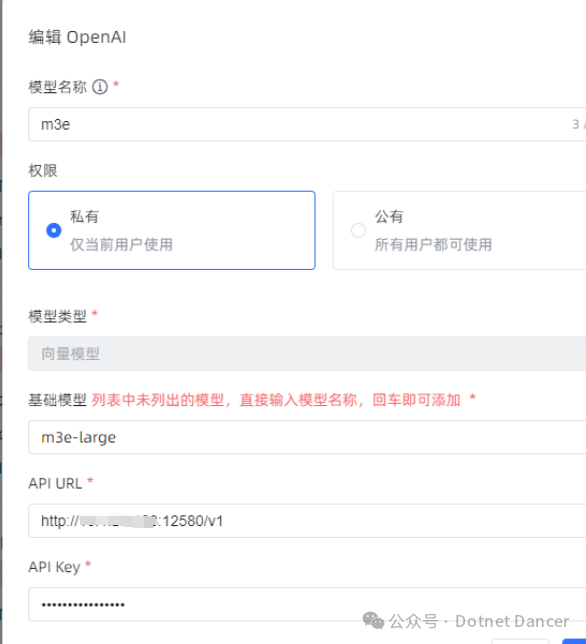
现在上传知识库文档,处理过程中,也可以看到m3e服务脚本的输出
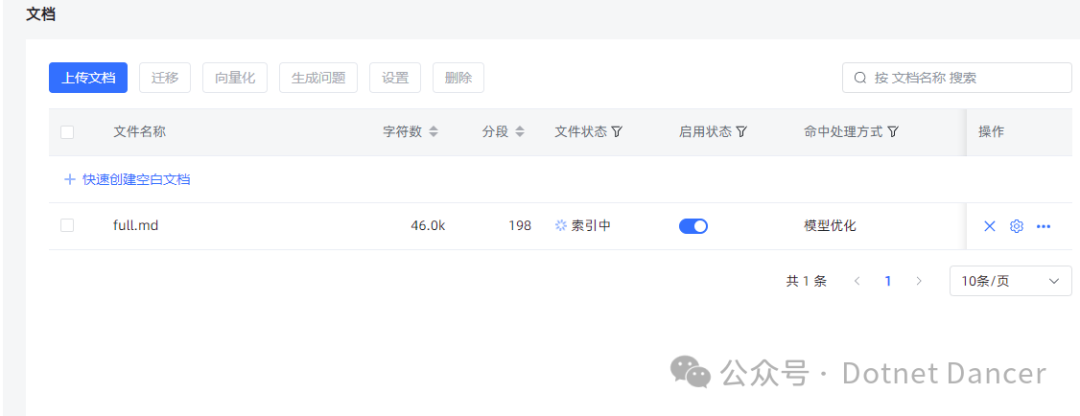
看到文档信息以及被向量化的数据流
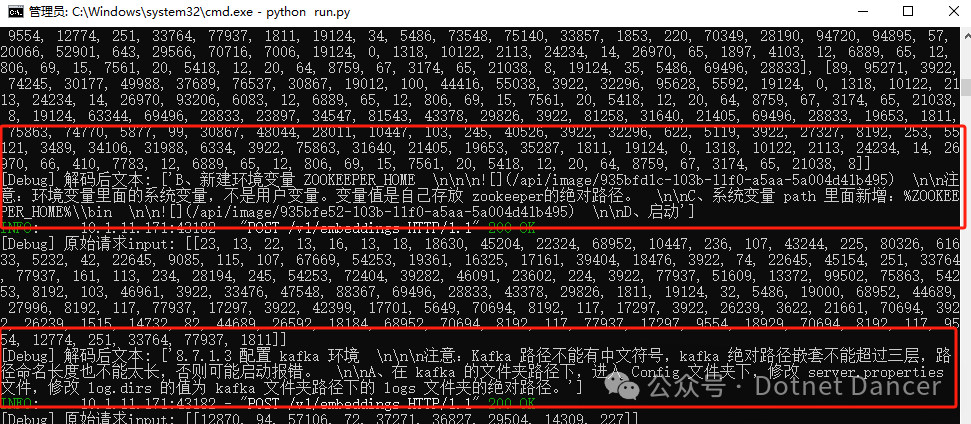
以上向量处理虽然能成功,但是偶尔还是会发生向量化中途失败的情况,可能是服务不够完善。继续完善向量模型推理框架,用于支持更好的数据处理。
安装有关依赖:
pip install numpy scipy scikit-learn torchvision torchaudio torch
重写推理框架来实现,除了完善向量化处理以外,修复了遇到的部分问题此处就不展开了,这儿也额外新增提供API Key的支持,用于授权使用:
from fastapi import FastAPI, Depends, HTTPException, status, Requestfrom fastapi.security import HTTPBearer, HTTPAuthorizationCredentialsfrom sentence_transformers import SentenceTransformerfrom pydantic import BaseModel, Field, Extrafrom fastapi.middleware.cors import CORSMiddlewareimport uvicornimport tiktokenimport numpy as npfrom scipy.interpolate import interp1dfrom typing import List, Literal, Optional, Unionimport torchimport osimport timeimport logging# 配置日志logging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)# 环境变量传入密钥sk_key = os.environ.get('sk-key', 'sk-abcd234567890efg987654321xyzabc')# 创建FastAPI实例app = FastAPI(title="M3E Embedding API")# CORS配置app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"],)# 设备检测device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')logger.info(f'本次加载模型的设备为 {"GPU: " + torch.cuda.get_device_name(0) if torch.cuda.is_available() else "CPU"}')# 加载模型(使用HuggingFace标准名称)model = SentenceTransformer('moka-ai/m3e-large', device=device)# 认证模块security = HTTPBearer()# ===== 数据模型定义 =====class ChatMessage(BaseModel): role: Literal["user", "assistant", "system"] content: strclass EmbeddingRequest(BaseModel): input: Union[str, List[str], List[List[int]]] # 支持字符串、字符串列表或token ID列表 model: str encoding_format: Optional[str] = "float" user: Optional[str] = None class Config: extra = Extra.ignore # 忽略未识别字段class EmbeddingObject(BaseModel): object: str = "embedding" embedding: List[float] index: intclass EmbeddingResponse(BaseModel): object: str = "list" data: List[EmbeddingObject] model: str usage: dict = Field(..., example={"prompt_tokens": 8, "total_tokens": 8})# ===== 工具函数 =====def num_tokens_from_string(text: str) -> int: """使用与OpenAI一致的token计数方式""" encoding = tiktoken.encoding_for_model("text-embedding-3-large") return len(encoding.encode(text))def decode_tokens(token_ids: List[int]) -> str: """将token ID列表解码为字符串""" encoding = tiktoken.encoding_for_model("text-embedding-3-large") try: return encoding.decode(token_ids) except Exception as e: logger.error(f"Token decoding failed: {e}") raise HTTPException( status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail=f"Invalid token IDs: {e}" )def expand_features(embedding: np.ndarray, target_length: int = 1536) -> np.ndarray: """维度扩展函数(1024 -> 1536)""" if len(embedding) == target_length: return embedding # 线性插值 x_original = np.linspace(0, 1, len(embedding)) x_target = np.linspace(0, 1, target_length) interpolator = interp1d(x_original, embedding, kind='linear') return interpolator(x_target)# ===== 中间件 =====@app.middleware("http")async def log_requests(request: Request, call_next): """请求日志中间件""" start_time = time.time() response = await call_next(request) process_time = (time.time() - start_time) * 1000 logger.info( f"Request: {request.method} {request.url} " f"- Status: {response.status_code} " f"- Time: {process_time:.2f}ms" ) return response# ===== 路由处理 =====@app.post("/v1/embeddings", response_model=EmbeddingResponse)async def get_embeddings( request: EmbeddingRequest, credentials: HTTPAuthorizationCredentials = Depends(security)): # 认证验证 if credentials.credentials != sk_key: raise HTTPException( status_code=status.HTTP_401_UNAUTHORIZED, detail="Invalid authorization code", ) # 处理输入(统一转换为字符串列表) try: if isinstance(request.input, str): inputs = [request.input] elif isinstance(request.input, list) and all(isinstance(i, str) for i in request.input): inputs = request.input elif isinstance(request.input, list) and all(isinstance(i, list) and all(isinstance(t, int) for t in i) for i in request.input): inputs = [decode_tokens(token_ids) for token_ids in request.input] else: raise HTTPException( status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail="Input must be a string, list of strings, or list of token ID lists" ) except Exception as e: logger.error(f"Input processing failed: {e}") raise HTTPException( status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail=str(e) ) logger.info(f"Processed inputs: {inputs}") # 生成嵌入向量 try: embeddings = [model.encode(text) for text in inputs] except Exception as e: logger.error(f"Embedding generation failed: {e}") raise HTTPException( status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail="Failed to generate embeddings" ) # 维度处理 processed_embeddings = [expand_features(embedding) for embedding in embeddings] # 归一化处理 normalized_embeddings = [embedding / np.linalg.norm(embedding) for embedding in processed_embeddings] # 转换为列表格式 embeddings_list = [embedding.tolist() for embedding in normalized_embeddings] # 计算token用量 total_tokens = sum(num_tokens_from_string(text) for text in inputs) return { "object": "list", "data": [ { "object": "embedding", "embedding": emb, "index": idx } for idx, emb in enumerate(embeddings_list) ], "model": request.model, "usage": { "prompt_tokens": total_tokens, "total_tokens": total_tokens } }if __name__ == "__main__": # 启动服务 uvicorn.run( app, host="0.0.0.0", port=12580, log_level="info", timeout_keep_alive=300 )在知识库应用前端,更新有关配置,在服务端可以监测到知识库前端进行连接请求时候发送的消息。第一次随便写key,提示401权限错误,根据代码写的key写入,就可以正常使用了。
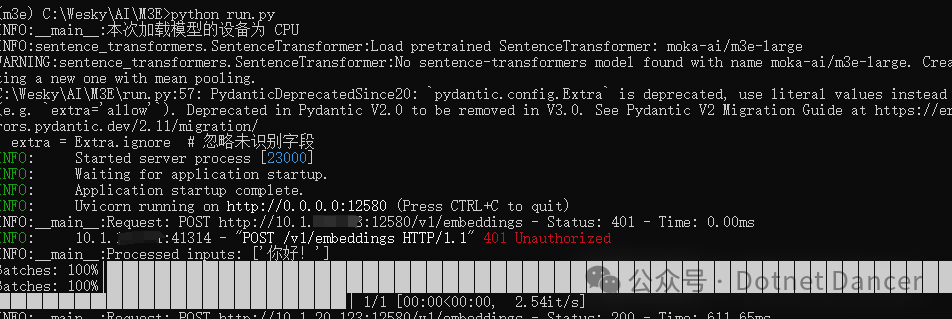
最后上传文档到maxkb进行向量化操作处理,能够成功处理,说明向量模型应用成功了。
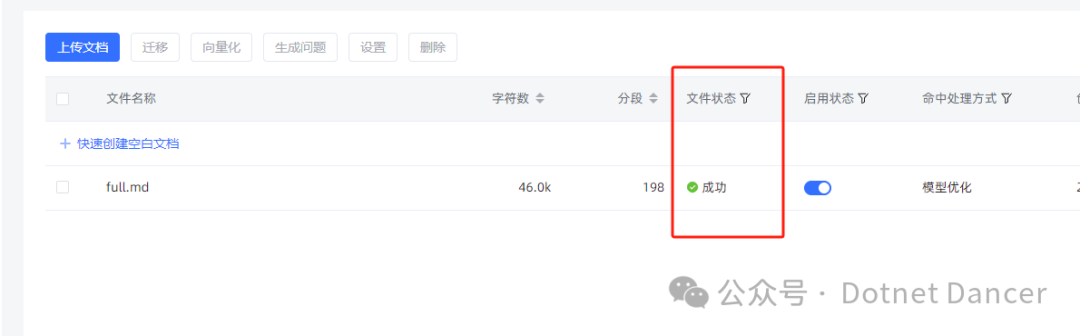
接下来创建一个知识库对话助手进行进一步测试,能够正确命中和输出对应的答案,说明向量化处理成功。
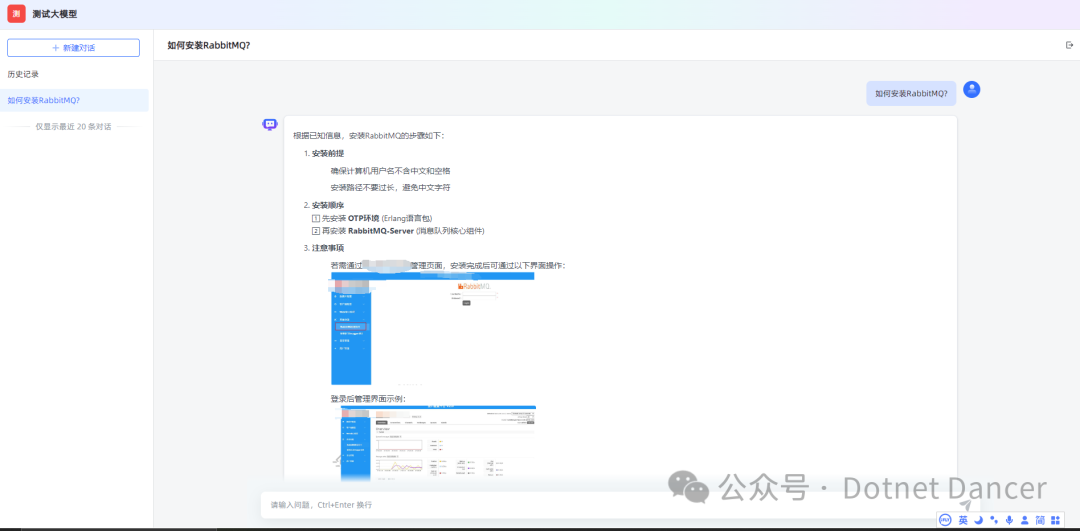
每次对话的时候,知识库客户端也会自动请求一次向量模型,对提问的问题进行向量化操作,在服务端也可以看到请求向量化操作记录:





 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)