Mindie LLM模型推理(Qwen)
通过部署昇腾服务化配套包后,以调用终端命令的方式测试llm在不同配置参数下推理性能和精度,通过表格的形式展示模型在各个阶段的推理耗时(例如FirstTokenTime、DecodeTime等),以及对应时延的平均值、最小值、最大值、75分位(P75)和99分位(P99)概率统计值,最后将计算结果保存到本地csv文件中。在输入输出长度不变的情况下,如果batchsize增加,时延增加,同时吞吐量也增
Mindie推理服务化调度方案(服务化性能调优可参考)
mindie实现的continuous batching方案基本原理如下(调度:合理地分配和协调任务或作业的执行顺序,以优化系统的性能、效率和公平性。)
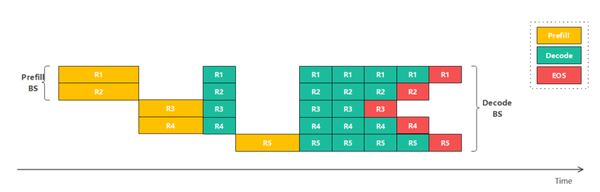
特点:
同一时刻只有prefill或者decode;随推理进行,轮流调度prefill和decode
prefill和decode的bs分开设置
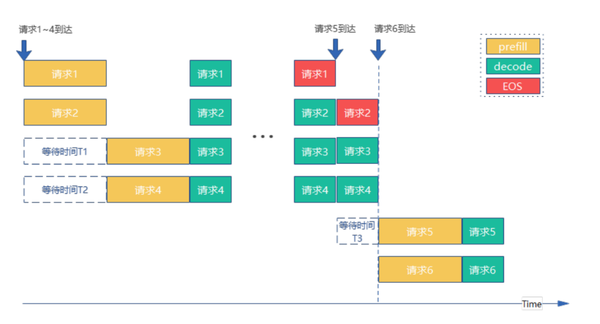
优先prefill or decode:
优先prefill:防止新进入请求在队列等待,降低首token时延
设置support_select_batch = 0
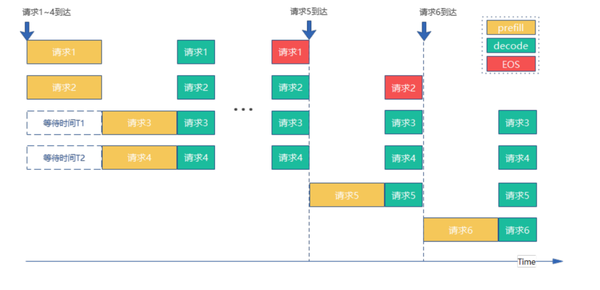
优先decode:降低新进入请求对推理影响,提高吞吐量(吞吐量:时间单位内能完成的任务数量)
设置support_select_batch=1
LLM推理性能指标
首token时延(prefill时延)TTFT:越小越好
非首token时延(decode时延)TPOT(time per output token):越小越好
E2E吞吐:
1. token吞吐:Tokens总数/推理总耗时 or (输入+输出token总数)/推理总耗时:越大越好
2. request吞吐:单位时间内能处理的请求数,越大越好
可用性:一定约束条件(一般是时延)满足推理性能要求的请求总数占总请求数的比例(首token时延<1s,模型推理p99 TTFT = 1s,大约99%请求满足首token时延要求 可用性99%)
不同场景指标叫法不同
静态推理性能测试(纯模型)
固定输入,输出长度,batch size下测试模型推理性能
主要目的:
1. 性能摸底,与版本基线数据对齐,和友商性能数据比对,如果不和预期进一步分析模型本身性能差距和瓶颈
2. 为动态性能测试提供性能参考
3. 通过静态了解prefill时延,decode时延随着bs 序列长度的变化规律
4. 固定输入输出长度下,最大bs和吞吐性能摸高(摸高:通过变化输入输出长度和bs找最大吞吐性)
在输入输出长度不变的情况下,如果batchsize增加,时延增加,同时吞吐量也增加(大batch size需要更多内存,在NPU内存够时候,基本呈线性增长)
batch size改变或者改变输入输出长度,时延,吞吐量变化
动态推理性能测试(服务化)
测试模型在序列长度不同,bs也是动态变化情况下的推理性能,使用continuous batching
测试方法:
1.使用客户提供的压测脚本在贴近客户业务场景的数据集进行,压测脚本内进行请求构造,mindie service restful api调用,推理结果收集,推理性能统计
压测是指通过mindie-service restful API接口向服务端发送请求获取结果,统计输出,本质上客户压测和benchmark压测是基本一致,就是客户压测是客户自己写的,benchmark压测是昇腾写的,还有一个工具evalscope也是可以压测,基本是一样就是输出统计的信息可能有差别,但是核心功能都是发请求、获取结果、统计耗时(首token、非首Token)
2.benchmark:
通过部署昇腾服务化配套包后,以调用终端命令的方式测试llm在不同配置参数下推理性能和精度,通过表格的形式展示模型在各个阶段的推理耗时(例如FirstTokenTime、DecodeTime等),以及对应时延的平均值、最小值、最大值、75分位(P75)和99分位(P99)概率统计值,最后将计算结果保存到本地csv文件中。
两种推理模式
clients
文本模式:输入输出都是文本,支持全量文本和流式文本生成,用的接口分别是MindIE Client的.generate()和.generate_stream()接口对应Mindie server的兼容trition的文本推理接口和trition的流式推理接口
全量文本直接所有一起输出,流式文本一个一个token输出
engine
MindIE Benchmark支持通过直接调用北向接口提供的InferenceEngine Python API进行流式推理。
支持tokenid到tokenid的异步推理和文本到文本的异步推理
从modeltest上面安装数据集:examples/atb_models/tests/modeltest/README_NEW.md · Ascend/MindIE-LLM - 码云 - 开源中国
LLM推理性能测试&调优
模型并行方案确认
llm内存来自两方面:kv cache和模型权重
模型放不下单卡时,就会考虑量化,多卡推理方案
llm涉及并行方案:TP,PP,DP,不同类型不同参数的模型用不同并行方案效果不完全相同
对于稠密LLM模型用tp并行(模型切分)的推理方案:tp size越大,相同bs输入,模型推理时延会下降,但是引入通信开销越大,所以根据模型规模权衡tp size值
启动容器
写在docker_start.sh脚本里:
IMAGES_ID=$1
NAME=$2
if [ $# -ne 2 ]; then
echo "error: need one argument describing your container name."
exit 1
fi
docker run --name ${NAME} -it -d --net=host --shm-size=500g \
--privileged=true \
-w /home \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--entrypoint=bash \
-v /data:/data \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /home:/home \
-v /tmp:/tmp \
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime \
-e http_proxy=$http_proxy \
-e https_proxy=$https_proxy \
${IMAGES_ID}
启动命令:

--privileged=true \ 不需要在写八张卡 因为这里已经有privilege
紫色:挂载驱动固件
-v /home:/home \ 代码挂载
-e http_proxy=$http_proxy \
-e https_proxy=$https_proxy \自动配置proxy环境
Qwen跑推理的权重下载
在宿主机上操作
Qwen2-7B: Mirror of https://huggingface.co/Qwen/Qwen2-7B
1.用git clone下载
export http_proxy="http://141.4.154.206:3128"
export https_proxy="http://141.4.154.206:3128"
export no_proxy=127.0.0.1,*.huawei.com,localhost,local,.local
export GIT_SSL_NO_VERIFY=true
unset HTTP_PROXY
unset HTTPS_PROXY
git config --global http.sslverify false
git config --global https.sslverify false
git config --global --unset http.proxy
git config --global --unset https.proxy
git config --global http.proxy "http://141.4.154.206:3128"
git config --global https.proxy "http://141.4.154.206:3128"
在容器外下载
git lfs pull 因为这里大文件可能会变小 文件不全
2.用scp从别的机器放到自己路径下
scp -r root@141.61.33.111:/home/c00925825/Qwen2-7B /home/c00925825
scp -r root@90.90.81.26:/data/Qwen2-7B /home/c00925825
Qwen中python包版本下载(requirements)
cd /usr/local/Ascend/atb-models/requirements/models/
cd usr/local/Ascend/atb-models/
env | grep ASCEND 这条命令用于查看当前环境中所有与 Ascend 相关的环境变量

需要配置环境变量但是不在里面的从这里看(一般都已经配好环境)
cd ..
ls并且source所有的set_env.sh

source nnal/atb/set_env.sh nnal实在里面atb的set env
driver挂在了不需要
env| grep ATB_SPEED可以看atb-models在什么路径内,如果出容器再进来还是一样有
推理
bash examples/models/qwen/run_pa.sh -m "/home/c00925825/Qwen2-7B/" --trust_remote_code true
这个命令跑模型推理采用qwen2-7b权重
性能测试:
卡的选择
性能测试如果要改使用的卡的位置,可以选择:
export ASCEND_RT_VISIBLE_DEVICES=4,5,6,7
如果要跑的卡是双卡 那就会默认选前两张
跑并发:多个输入一起跑,那多卡就会比单卡运行速度快很多,如果oom就代表没有容量,因为每个输入需要kv cache 多个并发就会需要大的容量 那如果单卡容量小 那速度就会慢
并且并发量越多显存过大会导致报runtime error
batch size不变 输入输出长度改变大小
输入输出长度增加,perfill时延变长,吞吐量减小
Prefill 计算量∝Batch Size×输入长度
batch size变大 输入输出长度不变
时延越长 吞吐量越大
· Prefill 时延增加:更大的 batch size表示一次 需要处理更多的 tokens,Prefill 时延线性增加。
· 吞吐量增加:更大的 batch size 可以更好地利用硬件资源(如 GPU/NPU 的并行计算能力),提高单位时间内处理的 tokens 数量
mindie-service服务化推理
服务化拉起
拉起通过修改conf路径的config.json,按照
配置参数:在mindie-service路径下cd conf/找config。json
设置文件权限和属主的命令:
chmod -R 640 /modelpath
chown -R root:root /modelpath
modelpath是权重路径
出现报错:

权重中:max prefill batch_size是可以和decode部分不一样,max prefill tokens是一共所有batchsize的输入tokens加起来总数最长长度 一般不能超过这两个其中一个(max prefill batch_size和max prefill tokens)
服务化推理
推理过程中出现报错:Wiki: 容器内无法使用curl/yum/dnf
因为进容器一开始是配了代理:
export http_proxy="http://141.4.154.206:3128"
export https_proxy="http://141.4.154.206:3128"
然后在curl这边解决就是 按照上面wiki
后来在服务化过程中因为代理导致报错:
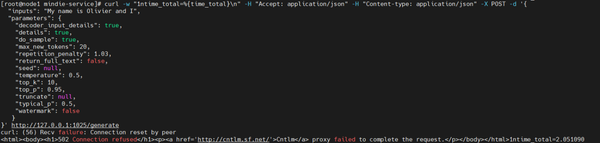
需要unset代理:
unset http_proxy
unset https_proxy
服务化命令从客户端输入 服务端接受命令进行推理任务
大模型在推理过程中top-k和top-p同时设置的时候该怎么采样,详细介绍这个过程 - 知乎
https://blog.csdn.net/qq_35971258/article/details/143753893
1. 客户端封装请求
在这种模式下,客户端负责将用户的命令封装成服务端可以理解的请求格式,然后发送给服务端。服务端直接处理封装好的请求,无需进一步解析。
1.1 流程
· 客户端接收用户输入的命令。
· 客户端将命令封装成标准化的请求(如 JSON、Protobuf 等格式)。
· 客户端将请求发送到服务端。
· 服务端接收请求并直接执行任务。
· 服务端将结果返回给客户端。
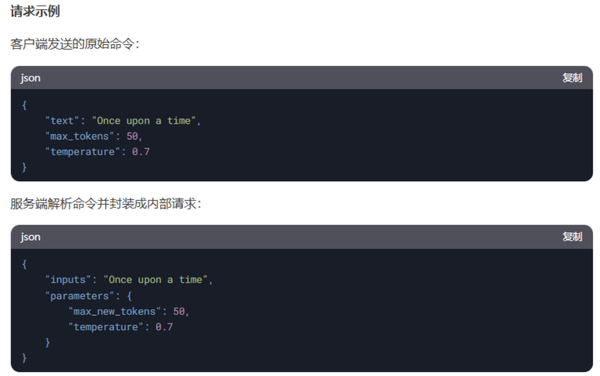
2. 服务端解析命令
在这种模式下,客户端直接将用户的原始命令发送给服务端,服务端负责解析命令并封装成内部请求格式。
2.1 流程
· 客户端接收用户输入的命令。
· 客户端将原始命令发送到服务端。
· 服务端解析命令并封装成内部请求格式。
· 服务端执行任务。
· 服务端将结果返回给客户端。
有代理访问不到这个服务化接口:
unset http_proxy
unset https_proxy
推理接口
· Python API:用于在 Python 中配置和运行模型。
· 配置文件:用于设置模型推理的参数(如 max prefill batch size 和 max prefill tokens)。
· 命令行工具:用于启动和管理推理任务。
接口配置的参数:
文本推理接口-兼容TGI 0.9.4版本接口-EndPoint业务面RESTful接口-服务化接口-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区
接口post
使用兼容TGI 0.9.4版本的接口-接口调用-快速开始-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"inputs": "My name is Olivier and I",
"parameters": {
"details": true,
"do_sample": true,
"max_new_tokens": 30,
"repetition_penalty": 1.03,
"return_full_text": false,
"seed": null,
"temperature": 0.5,
"top_k": 10,
"top_p": 0.95,
"truncate": null,
"typical_p": 0.5,
"watermark": false
}
}' http://127.0.0.1:1025/generate_stream
流式推理:输出结果如下

get接口
参考如下:
健康检查-兼容TGI 0.9.4版本接口-EndPoint业务面RESTful接口-服务化接口-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区
一般正常的话就没有输出
查询TGI Endpoint信息

服务化推理性能测试--client 文字请求
数据集下载:
examples/atb_models/tests/modeltest/README_NEW.md · Ascend/MindIE-LLM - 码云 - 开源中国
下载方法如上
mkdir -p /usr/local/Ascend/atb-models/tests/modeltest/temp_data/humaneval
cp "/home/c00925825/human-eval-v2-20210705.jsonl" /usr/local/Ascend/atb-models/tests/modeltest/temp_data/humaneval/
ls /usr/local/Ascend/atb-models/tests/modeltest/temp_data/humaneval/
python3 scripts/data_prepare.py --dataset_name humaneval #数据集转换格式
跑benchmark里client
SMPL_PARAM="{\"temperature\":0.5,\"top_k\":10,\"top_p\":0.9,\"typical_p\":0.9,\"seed\":1234,\"repetition_penalty\":1,\"watermark\":true,\"truncate\":10}"
benchmark \
--DatasetPath "/usr/local/Ascend/atb-models/tests/modeltest/temp_data/humaneval" \
--DatasetType "humaneval" \
--ModelName "Qwen2-7B" \
--ModelPath "/home/c00925825/Qwen2-7B" \
--TestType client \
--Http https://127.0.0.1:1025 \
--Concurrency 128 \
--TaskKind stream \
--Tokenizer True \
--MaxOutputLen 512 \
--DoSampling True \
--SamplingParams $SMPL_PARAM
会报错:
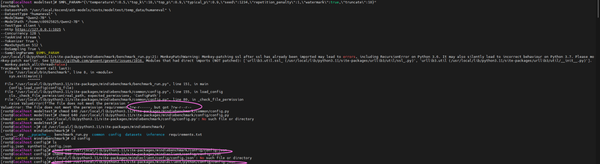
后续继续报错:
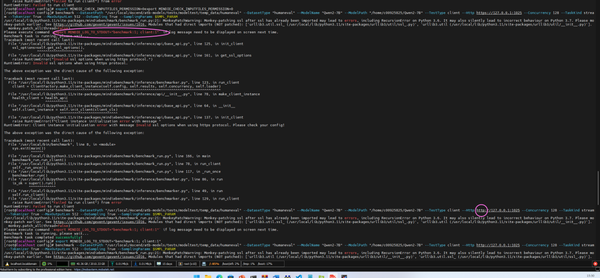
要改成如下:
SMPL_PARAM="{\"temperature\":0.5,\"top_k\":10,\"top_p\":0.9,\"typical_p\":0.9,\"seed\":1234,\"repetition_penalty\":1,\"watermark\":true,\"truncate\":10}"
benchmark \
--DatasetPath "/usr/local/Ascend/atb-models/tests/modeltest/temp_data/humaneval" \
--DatasetType "humaneval" \
--ModelName "Qwen2-7B" \
--ModelPath "/home/c00925825/Qwen2-7B" \
--TestType client \
--Http http://127.0.0.1:1025 \
--Concurrency 128 \
--TaskKind stream \
--Tokenizer True \
--MaxOutputLen 512 \
--DoSampling True \
--SamplingParams $SMPL_PARAM
并且:
export MINDIE_LOG_TO_STDOUT="benchmark:1; client:1"
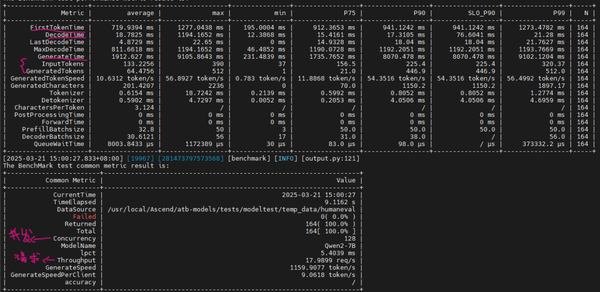
first token time:perfill时延
decode time:decode时延
generate time平均一条请求输出的时延(总时延)
input tokens和generate tokens:一句话的输入输出token数量
throughput:请求的吞吐量
generatespeed:生成token吞吐量
p99:生成的百分之99都是小于某个值
服务化推理性能测试--client tokenid请求
通过:数据集使用-附录-MindIE Service开发指南-服务化集成部署-MindIE1.0.0开发文档-昇腾社区
和上面的数据集下载
可以把数据转成token id,然后后处理测试样例
同样的:
SMPL_PARAM='{"temperature":0.5,"top_k":10,"top_p":0.9,"seed":1234,"repetition_penalty":1}'
benchmark \
--DatasetPath "/usr/local/Ascend/atb-models/tests/modeltest/temp_data/gsm8k/token_gsm8k_model.csv" \
--DatasetType gsm8k \
--ModelName "Qwen2-7B" \
--ModelPath "/home/c00925825/Qwen2-7B" \
--TestType client \
--Http http://127.0.0.1:1025 \
--ManagementHttp http://127.0.0.2:1026 \
--Concurrency 128 \
--TaskKind stream_token \
--Tokenizer False \
--MaxOutputLen 512 \
--DoSampling True \
--SamplingParams $SMPL_PARAM
这里报了一个错:
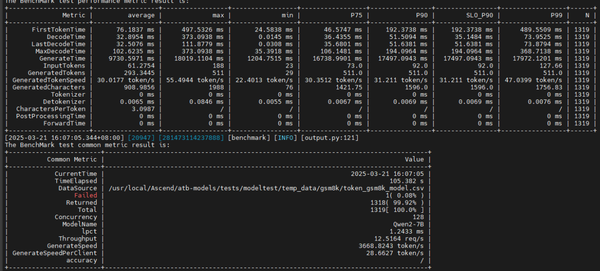
这一行数据单独去纯模型推理看看问题:
在atb-models路径下看:
examples/run_pa.py
找到input
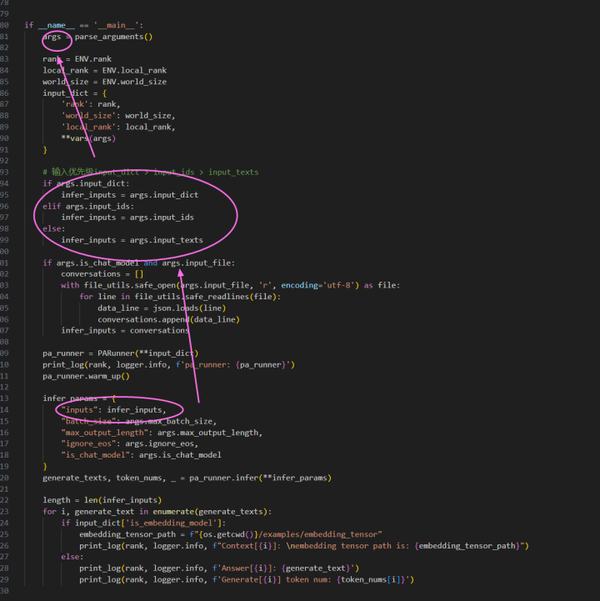
接着找到parse_argument
因为是id所以在这里加上一行数据
bash examples/models/qwen/run_pa.sh -m "/home/c00925825/Qwen2-7B/" --trust_remote_code true
没问题
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"id": "42",
"inputs": [{
"name": "input0",
"shape": [
1,
75
],
"datatype": "UINT32",
"data": [
25300,482,21051,1059,6930,2205,23971,2326,3039,264,1042,13,576,2783,315,825,3947,374,400,17,13,4636,220,20,1635,11,279,2783,315,825,3947,702,7172,553,220,16,20,15,13384,714,6898,482,6635,537,311,2968,705,894,3947,323,8570,311,728,311,279,23971,369,220,18,803,1635,13,2585,1753,1521,6898,482,8329,389,678,21051,311,279,23971,30
]
}],
"outputs": [{
"name": "output0"
}],
"parameters": {
"temperature":0.5,"top_k":10,"top_p":0.9,"seed":1234,"repetition_penalty":1, "max_new_tokens": 20
}
}' http://127.0.0.1:1025/v2/models/Qwen2-7B/infer
也没问题
LLM推理PD分离
在 PD 分离式架构中:
· Prefill Instance 专注于 Prefill 阶段的计算。
· Decode Instance 专注于 Decode 阶段的生成任务。
当 Prefill Instance 完成 KV Cache 的计算后,会将其传输给 Decode Instance,后者接续生成结果。这种架构独立优化了两个阶段的性能,因此又被简称为 PD 分离。
为什么需要 Prefill-Decode 分离?
在大模型推理中,常用以下两项指标评估性能:
· TTFT(Time-To-First-Token):首 token 的生成时间,主要衡量 Prefill 阶段性能。
· TPOT(Time-Per-Output-Token):生成每个 token 的时间,主要衡量 Decode 阶段性能。
当 Prefill 和 Decode 在同一块 GPU 上运行时,由于两阶段的计算特性差异(Prefill 是计算密集型,而 Decode 是存储密集型),资源争抢会导致 TTFT 和 TPOT 之间的权衡。例如:
· 若优先处理 Prefill 阶段以降低 TTFT,Decode 阶段的性能(TPOT)可能下降。
· 若尽量提升 TPOT,则会增加 Prefill 请求的等待时间,导致 TTFT 上升。
PD 分离式架构的提出正是为了打破这一矛盾。通过将 Prefill 和 Decode 分离运行,可以针对不同阶段的特性独立优化资源分配,从而在降低首 token 延迟的同时提高整体吞吐量。
分离式推理架构的优化方向
1. 算力与存储的独立优化
在 PD 分离架构中,Prefill 和 Decode 阶段的资源需求不同,分别体现为:
· Prefill 阶段:计算密集型(compute-bound)。在流量较大或用户提示长度较长时,Prefill 的计算压力更大。完成 KV Cache 的生成后,Prefill 阶段本身无需继续保留这些缓存。
· Decode 阶段:存储密集型(memory-bound)。由于逐 token 生成的特性,Decode 阶段需频繁访问 KV Cache,因此需要尽可能多地保留缓存数据以保障推理效率。
因此,在 PD 分离架构下,可以分别针对计算和存储瓶颈进行优化。
2. Batching 策略的独立优化
在 DistServe 的实验中,Batching 策略对两阶段的性能影响显著,但趋势相反:
· Prefill 阶段:吞吐量随 batch size 增加逐渐趋于平稳。这是因为 Prefill 的计算受限特性(compute-bound),当 batch 中的总 token 数超过某个阈值时,计算资源成为瓶颈。
· Decode 阶段:吞吐量随 batch size 增加显著提升。由于 Decode 阶段的存储受限特性(memory-bound),增大 batch size 可提高计算效率,从而显著增加吞吐量。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)